







Understanding the Robustness of 3D Object Detection with Bird’s-Eye-View Representations in Autonomous Driving
这篇文章是发表在CVPR上的一篇文章,针对基于BEV的目标检测算法进行了两类可靠性分析,即恶劣自然条件以及敌对攻击。同时也提出了一种进行仿真实验的方法-3D相关贴图攻击。
Natural Robustness
自然条件方面,作者进行了三组测试。首先是最简单的噪声、模糊以及数字干扰。在这组测试中,基于BEV的目标检测有着更好的抗干扰能力。其次是天气和光照条件,作者使用白天、晚上、晴天、雨天四种条件进行测试,结果证明弱光条件几乎对所有的目标检测算法都产生了严重影响,虽然整体都产生了下降,但是基于BEV的方法依然表现较好。最后作者测试了部分相机失效的情况,所有算法都产生了不同程度的下降,但是由于BEV全局感知的特点,下降的幅度还要比其它算法稍微好一点点。
Adversarial Robustness
敌对攻击方面,作者也进行了三组测试。首先是对图像增加扰动,这里对应的是那种完全无法在现实中进行部署的对整个图像的扰动,作者使用FGSM和PGD两种方法进行扰动。结果来看,扰动对于不同模型有着不同程度的影响,对BEVFusion这种多传感器融合的方法影响较小,对基于BEV的方法有着很严重的干扰,作者进一步验证了为什么会出现这个现象,原因在于BEV的投影过程出现了问题,多个视角下的扰动会在BEV中进行更加复杂的叠加,从而大幅度干扰模型的效果。这部分,作者对多传感器融合的方法进行了额外验证,发现只有点云被攻击时,BEVFusion的效果也是较好的,因为图像部分被用于补充点云,一定程度上增加了抗干扰能力。
在使用攻击贴图的实验中,作者没有直接在2d图像上贴图,而是先在3d包围框中确定贴图位置,之后利用相机的内外参,将端点投影在不同视角下的图像上,从而得到更加准确的贴图位置。通过不断调整贴图的比例,作者发现基于BEV的方法性能下降更多。最后作者也验证了特定类别攻击,即不同类别的攻击对应不同的贴图,结果也是相同的,多传感器融合的方法更加稳定,基于BEV的方法更容易被干扰。
3D Consistent Patch Attack
为了设计一个更加准确的贴图方法,作者提供了这个3d一致性贴图攻击。简单来说就是利用bounding box的真值,在3d的包围框中确定贴图的位置,之后根据相机参数和位置关系,计算贴图的端点会被投影在不同视角下的哪个位置,之后再进行贴图就能让贴的位置更加准确。基于这种方法,作者设计了多相机攻击和时序攻击,也就是在连续的帧中都利用这个真值信息进行3d-2d的贴图计算,结果发现依然是多传感器融合的方法更加稳定。
老实说这篇文章真没干啥,可能是作者背景太厉害才能中CVPR,反正就是证明了BEVFormer虽然效果好,但是也容易受干扰。多传感器融合的方法要比纯相机的方法稳定。比较有价值的是计算贴图位置的这个方法。
Physically Realizable Adversarial Creating Attack Against Vision-Based BEV Space 3D Object Detection
这篇文章是发在CV顶刊TIP的一篇文章,主要是利用一种放在地面上的贴片,来让基于BEV的目标检测算法产生前面有物体的错觉。对于3d目标检测的攻击,根据目标其实可以分为两类:创造一个假的物体(FP)和隐藏一个真实物体(FN),这篇文章对应的就是FP。现有的攻击有两方面不足,一方面是贴图无法模拟十分复杂的场景,另一方面是贴图的深度信息不好在仿真中调整。所以作者提出了一种针对BEV目标检测的攻击方法,主要针对如何准确地贴图以及如何有效地调整参数进行了设计。

作者提出的攻击具有三个优势:在不同场景下都有效果,在不同视角下都有效果,对不同模型都有效果。为了准确地计算贴图的位置,作者采用了和前面文章相同的方法,在3d场景中贴图,然后根据投影关系转换到2d图像上。由于文章的贴图是放在地面上的,所以在确定攻击贴图的包围框时,作者进行了一系列的约束。贴图被放置在前后两个镜头的范围内,只在地面放置,包围框的底部以周围其它物体中最低点为标准,最后可以得到参数化的攻击贴图的包围框的位置,利用这个位置,可以结合相机的内外参进行投影,得到更加准确的2d攻击图像位置,确定端点位置后,可以根据2d的位置反投影回原本的3d贴图,利用插值就可以确定2d平面上这个位置的像素该显示什么内容。
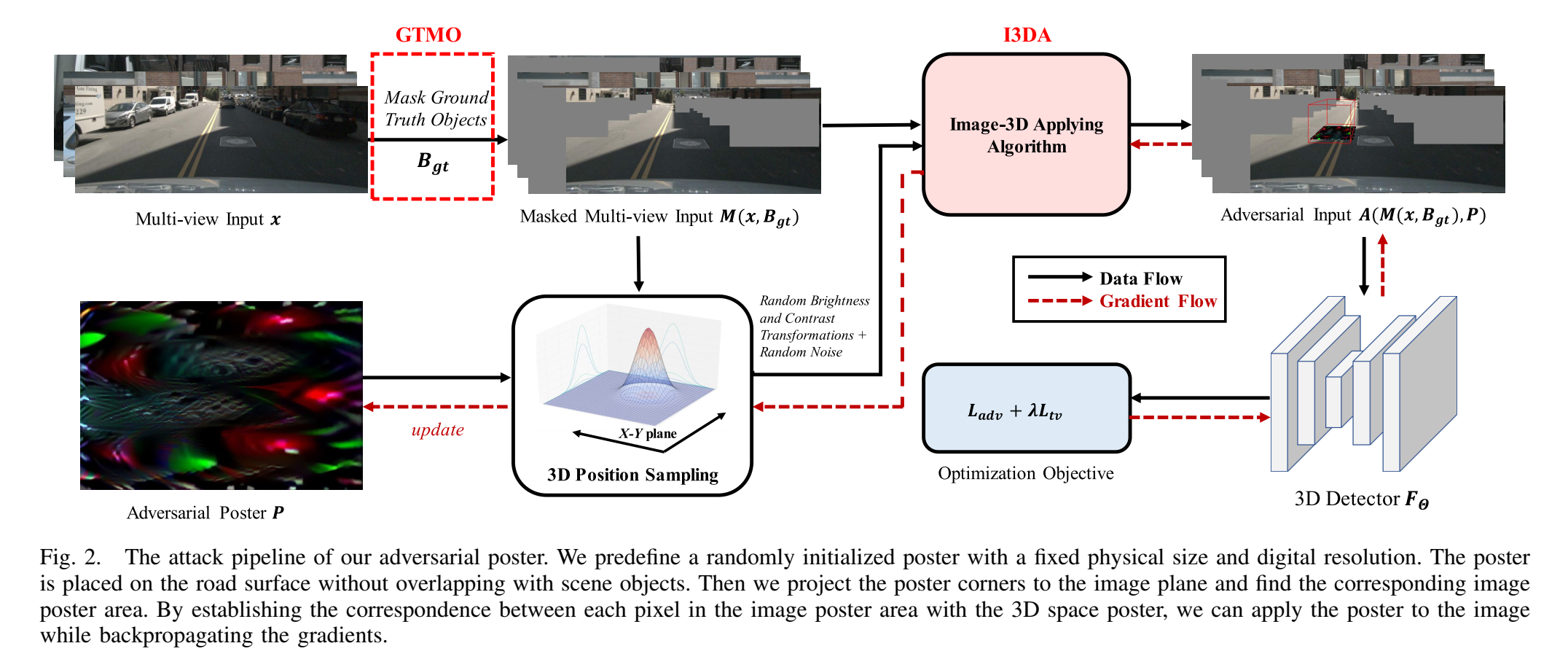
为了更加高效地调整贴图的内容,作者设计了真值掩码优化。我们的目标是注入一个原本不存在的物体,从模型准确度的角度来看,场景中原来就存在一些物体,这些物体本身的正确估计会让我们的攻击不明显,为了让贴图能够被更加准确地优化,作者训练时利用包围框真值去掉了场景中的其它物体,让模型能够直接对贴图产生反应。整体的优化过程依然是老一套,最大化攻击效果以及附加的一些平滑度损失。为了提高攻击的普适性,作者同样调整了贴图的角度、光照、对比度等外界条件,从而使最终产生的贴图有更优的效果。
文章依然属于“调整参数化贴图让目标模型性能下降”的研究,其中比较有意思的是GTMO的部分,相当于扩大了贴图对目标检测性能的干扰。采用的贴图方法和前面文章的贴图方法一样,也是先利用3d确定位置之后再转换到2d平面上。
A Unified Framework for Adversarial Patch Attacks Against Visual 3D Object Detection in Autonomous Driving
与上一篇论文同样的作者,不光是一作一样,貌似是三个作者都一样,内容也很像,让人有一稿多投的嫌疑。
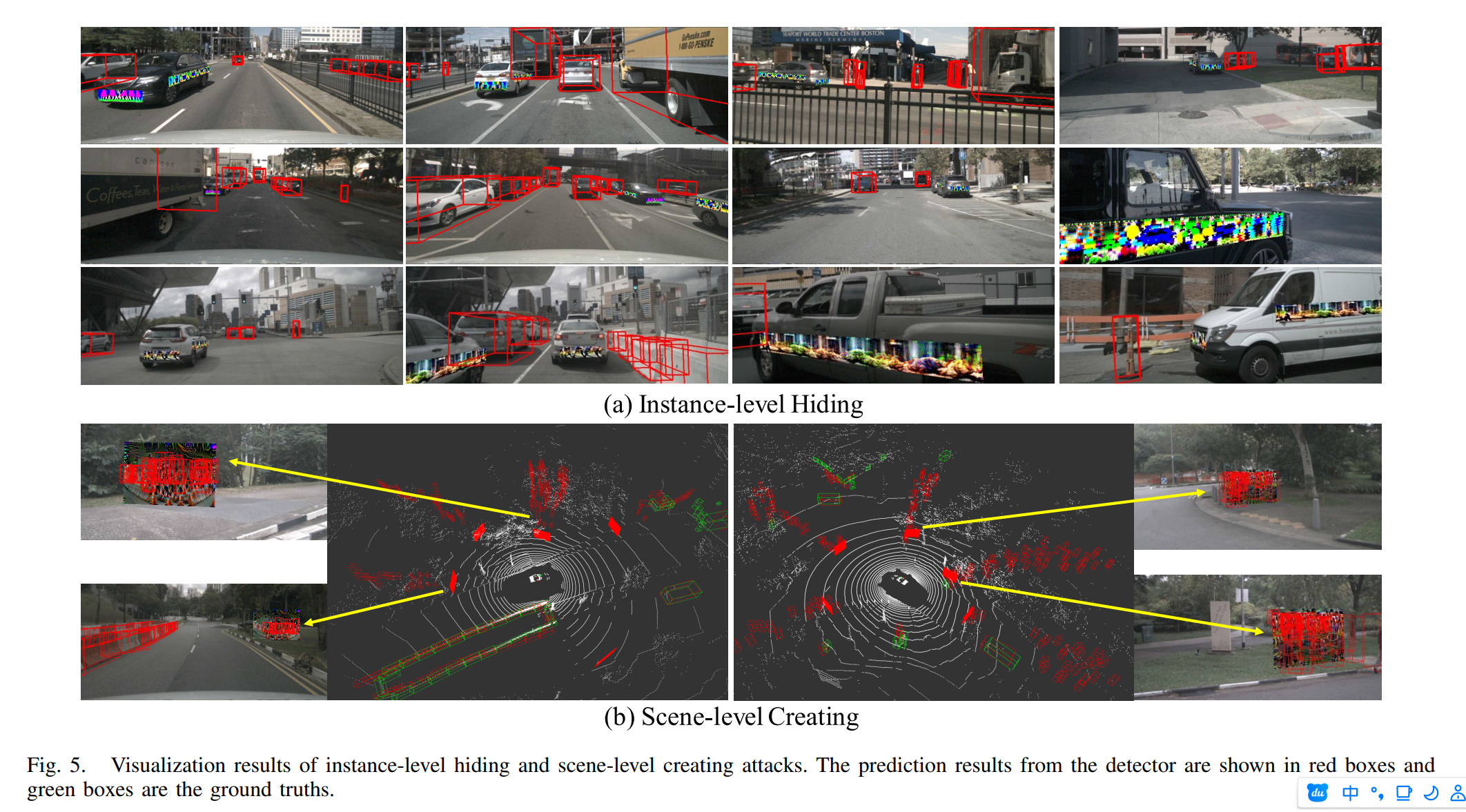
这篇文章主要的目标是让基于BEV的目标检测算法产生错觉,认为一个物体消失了(前面的那一篇文章是在路面上贴图让目标检测检测算法误以为有物体)。相同地,作者也使用了3d贴图的方法,首先将贴图贴在3d的包围框上,之后利用内外参计算出观测结果,之后反向计算像素对应的贴图的内容。作者认为,不同于2d目标检测中的稠密贴图的方法,3d目标检测由于存在前后景的遮挡问题,所以不能够采用这种密集贴图的策略,这会导致贴图不能被稳定观测,从而降低贴图的内容调整。所以作者提出了SOSS策略,每个时刻的多个视角下的图像中,每个图像中只选择一个最接近自车的目标对象,在该对象表面稀疏地渲染补丁,用于训练隐藏攻击的对抗补丁。同时作者也使用距离进行了过滤,只将敌对贴图贴在较近的物体上,从而保证贴图能够被稳定优化。
针对不同的任务,作者提出了两种损失函数。一种是实例级的隐藏贴图,就是希望目标检测算法检测不到被贴图的物体,为了突出贴图带来的影响,作者提出了POAO策略,其实就是上一篇文章中GTMO,通过对其它物体进行遮挡,从而提高patch对最终结果的影响,进而让patch的优化更加有效。通过调整参数化的贴图内容,让模型的输出检测出空物体的概率最大化。
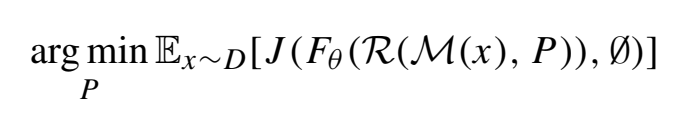
另一种损失函数是场景级的贴图创建,它的目标是让目标检测算法误认为场景中存在有大量的物体,本质上是让目标检测算法在贴图区域检测出尽可能多的物体。
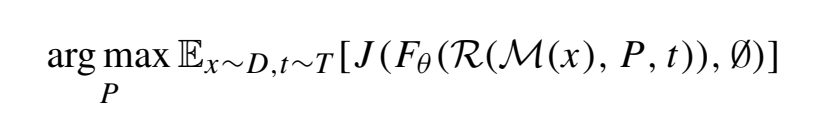
带有贴图的物体会被放置在场景中,从实验中的插图来看,攻击的效果是在贴图的区域产生检测到了多个物体,这些物体都是在贴图的区域内,而不是在场景中有均匀分布的物体。
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF
和前面的文章不太一样,这篇文章使用了一个叫做神经辐射场NeRF的技术,简单来说,NeRF就是利用多个图像输入,转换为一个3d的模型,有点像视觉重建的意思,这篇文章依然是通过调整参数化的攻击来让目标模型最差,但是很大的一个区别在于,他使用了NeRF来生成一个带有攻击的车辆。
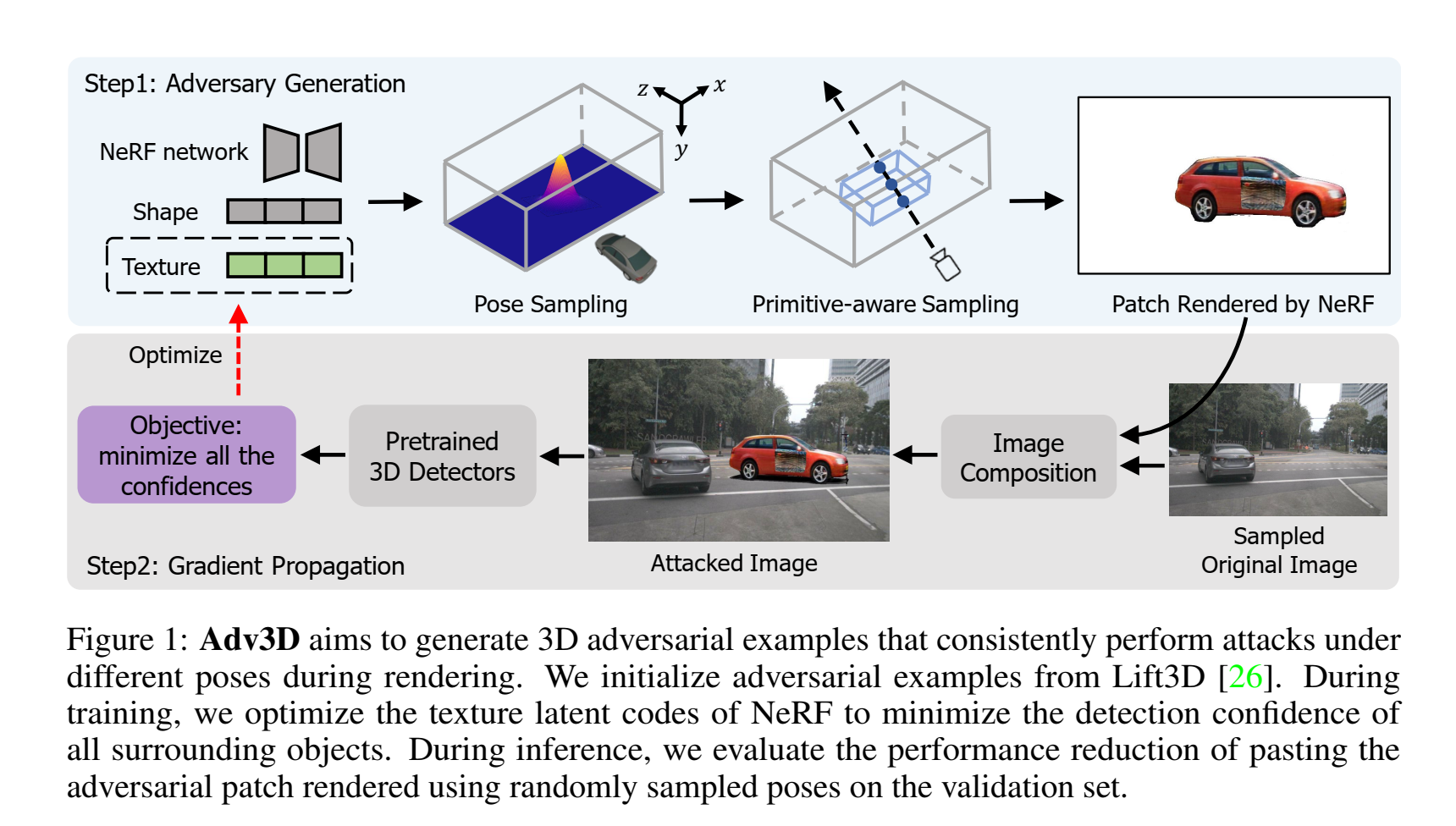
NeRF中,对于一张图像的每个像素,我们首先以光心为原点,做一条射线穿过这个像素,在一定范围内,均匀地提取k个点,这k个点的坐标会被作为输入送入NeRF模型中,输出的是该点的色彩c和密度𝜏,之后对其积分,就可以得到该像素最终的颜色。在攻击的过程中,首先我们有许多已经训练好的NeRF对象,我们可以将其视为许多个3d物体,之后我们需要先确定物体的位姿,这会影响到我们的车辆会观测到哪个角度下的攻击车辆,之后根据这个位姿,生成该视角下我们能观测到的这个车的图像,在生成的过程中,NeRF会有纹理、形状两个参数,这里我们固定形状只调整纹理,这样做是为了保证不改变车辆的形状,只调整车辆贴图的纹理。为了让贴图的位置更加可靠,作者引入了一定的语义约束,简单来说就是只选择标记为车窗的点进行纹理的改变,这样子可以实现更加可行的贴图位置。最终得到的带有攻击的观测图像会被叠加在原图上,之后送入被攻击模型得到一个结果,通过不断调整参数化的攻击(在这里是NeRF的纹理参数)从而实现攻击效果的最大化。
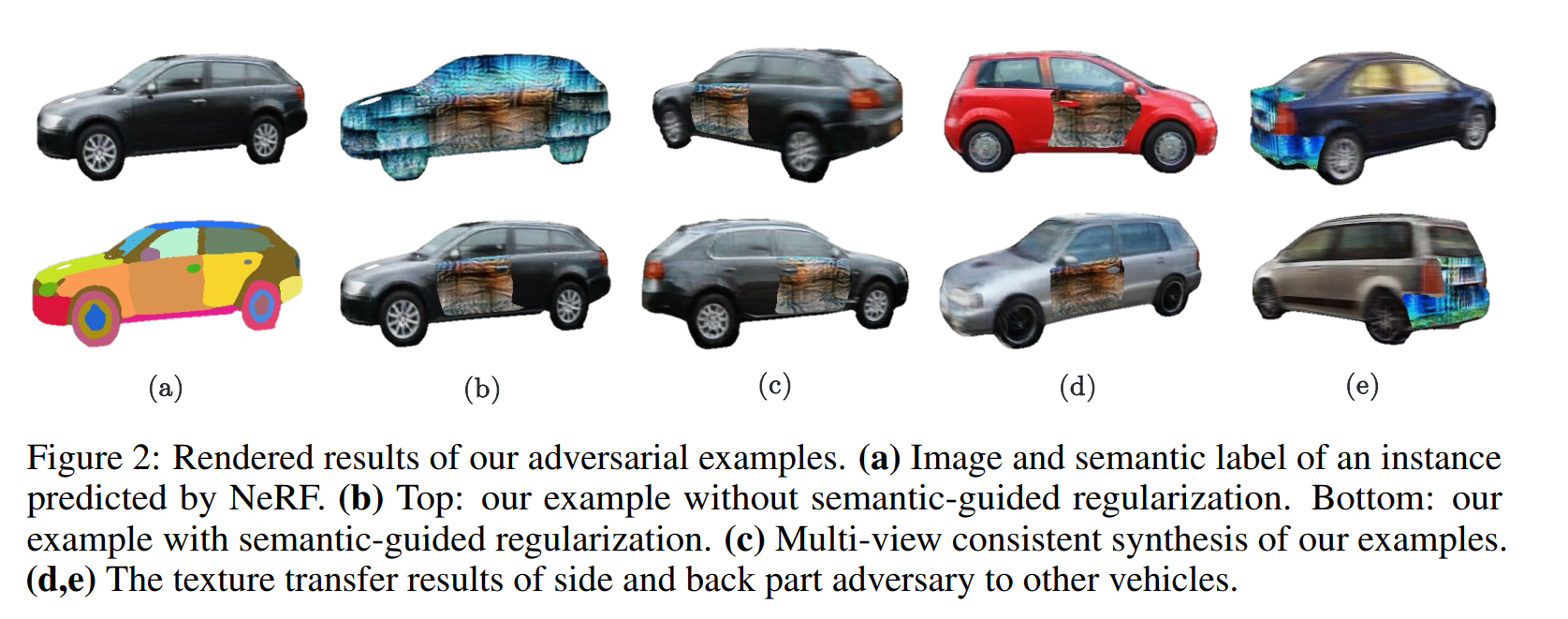
虽然使用NeRF能够提供一个多角度下的攻击注入,但是本质上注入的攻击依然无法反应采集图像时场景中的光照的特点,依然属于贴图的范围。但是总的来说,引入NeRF技术确实是一个很好的方法。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











