







Heterogeneous Environment Aware Streaming Graph Partitioning–异构环境感知流图分区
基于完成时间最早的异构感知流式图划分
对象:(非动态)流式大图
划分方式:以顶点为中心
缺点:仅考虑了图处理系统,没有考虑应用在其上的图算法对图划分的影响
摘要
随着图数据可用性的提高和云计算范式的广泛采用,图分区已经成为一种有效的预处理技术,可以平衡计算工作量和应对大量输入数据。由于对整个图进行分区的成本是昂贵的,因此最近有一些针对流图分区的尝试性工作,这些工作运行速度更快,易于并行化,并且可以增量更新。大多数现有的流分区工作都假设集群内的工作节点本质上是同质的。不幸的是,这个假设并不总是成立。实验表明,这些同构算法在异构环境中运行时性能会显着下降。在本文中,我们提出了一种新颖的自适应流图分区方法来应对异构环境。我们首先考虑每个节点的计算能力(例如CPU频率)和通信能力(例如网络带宽)的不平衡,对异构计算环境进行形式化建模。基于该模型,我们提出了一种新的图划分目标函数,旨在最小化图处理作业的总执行时间。然后,我们针对该目标函数探索一些简单而有效的流算法,可以实现平衡且高效的划分结果。在具有真实世界网络和社交网络图的中等规模计算集群上进行了大量实验。结果表明,与最先进的解决方案相比,所提出的方法取得了显着的改进。
引言
近年来,图数据规模变大并持续快速增长[11],[9]。图数据前所未有的激增需要高效的处理机制和方法来处理不同的工作负载。
事实证明,传统的 MapReduce 框架对于图上的迭代计算工作负载效率低下 [12]。因此,最近提出了许多基于图的并行框架。例如,Pregel、GraphLab [18]、[16]被提出来利用不同的并行图处理方法。作为最近新兴的并行图计算系统的代表,Pregel基于BSP(批量同步并行)模型[30],并采用以顶点为中心的模型,其中每个顶点以一系列超级步骤执行用户定义的函数。默认情况下,Pregel使用哈希函数来划分顶点,这对于机器之间的大量通信是低效的。需要一个有效的图形分区来最大限度地减少应用程序的整体运行时间。然而,平衡图划分问题具有挑战性,并且已知是 NP 完全问题 [17]。

大多数 Pregel 类系统上最先进的分区工作都是基于 k 平衡图分区 [5],其目的是最小化机器之间的总通信成本并平衡每个部分的顶点数量。k 平衡图划分问题已被证明是 NP 难问题[5],并提出了几种有效的算法。然而,随着图的尺寸变大,近似算法甚至广泛使用的多级启发式算法都会遭受划分时间的显着增加。正如[29]中所示的实验,多级方法需要超过 8.5 小时来从 Twitter 上划分图,这有时比处理工作负载所花费的时间还要长。
影响并行图计算性能的另一个显着因素是异构计算环境。当前大多数图划分策略都假设集群中的节点本质上是同构的。不幸的是,这些同质性假设并不总是成立,特别是当图系统设置在公共云环境中[10]、[33](例如,Amazon Elastic Compute Cloud、EC2 [1])或公司私有数据中心[22]。例如,[10]测量了128个EC2实例的网络带宽,并发现了明显的网络带宽不均匀性。一些成对带宽达到500MB/s以上,而最低仅为37.5MB/s。在私有云中,通常存在多代硬件,并且具有不同的计算和通信能力。
事实上,当集群与异构硬件混合时,经典的 k 平衡算法使用与同构集群中相同的策略。所有节点都被分配相同的工作负载,因此较快的节点通常会等待较慢的节点,从而无法充分利用设施。图 1 显示了 10 个节点的私有云示例。我们使用最先进的多级图分区工具 METIS [14] 来分区图并在其上处理 Pagerank 工作负载。图 1(a) 显示了原始集群中的作业执行时间,图 1(b) 显示了 5 个节点升级为更快的 CPU 和网络后的结果。正如我们所看到的,尽管升级了一半的硬件,但作业的运行时间几乎没有改善(红线,即从 277 秒到 259 秒)。
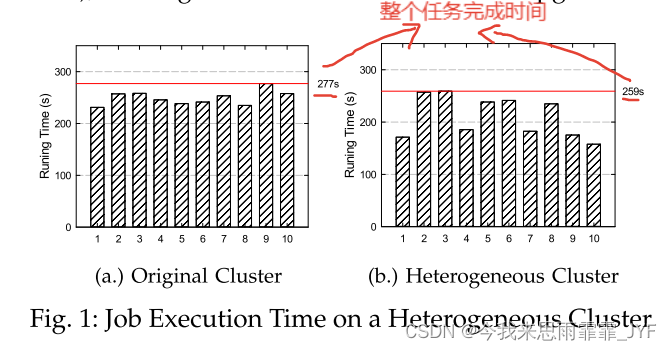
虽然[10]提出了考虑云环境中网络带宽差异的多级图划分框架,但这项工作没有考虑计算异构性。此外,如上所述,由于划分时间成本巨大,这种多级方法不适合大规模图。
最近新兴的图分区方法是流分区,其中在不知道整个图数据的情况下处理输入图。流式图分区使用轻量级启发式算法,提供更快的速度、可比较的分区性能和增量更新[27]、[29]。
在本文中,为了缓解异构环境中遇到的图划分挑战,我们提出了一种新颖的异构环境感知图划分方法。我们对异构环境进行形式化建模,考虑到分布式集群中节点的计算能力和通信能力的不平衡。具体来说,除了 k 平衡图分区之外,我们还提出了一种新的图分区目标函数,旨在最大限度地减少图处理应用程序的运行时间。基于目标函数,我们进一步设计了几种能够充分利用异构环境的新颖的流图分区启发式方法。
为了评估我们提出的异构感知流算法,我们构建了一个名为 HeAPS 的原型系统,遵循 Google 的 Pregel 范式 [18],并实现了我们新的流图分区启发式算法以及其他最先进的算法。我们使用现实世界的社交网络图数据集和分别具有 26 和 28 个节点的两个测试集群上的几个代表性工作负载来评估 HeAPS 中的图分区方法。此外,我们还研究了云中常见的几种异构环境。评估证实,我们的异构环境感知图分区方法可以显着提高作业执行时间,并平衡集群节点之间的工作负载。
相关工作
大规模图计算:为了满足当前处理大规模图的要求,许多分布式方法和框架被提出并变得有吸引力。Pregel [18] 和 GraphLab [16] 都使用以顶点为中心的计算模型,并在每个工作节点并行运行用户定义的程序。Giraph[2]是一个开源项目,采用Pregel的编程模型,并针对HDFS进行了调整。在这些并行图处理系统中,将大图划分为多个平衡的子图非常重要,以便并行工作人员可以协调处理它们。然而,目前大多数系统通常选择简单的哈希方法。
图分区:图划分是一个组合优化问题,已经研究了几十年并广泛应用于许多领域,例如并行子图列表[24]。广泛使用的目标函数 k 平衡图分区旨在最小化分区之间切割的边数,同时平衡顶点数量。尽管 k 平衡图划分问题是一个 NP 完全问题 [17],但已经提出了几种解决方案来应对这一挑战。
Andreev等人[5]提出了一种双标准近似算法,该算法保证多项式运行时间,近似比为 O(logn)。Even等人提出了另一种解决方案。除了近似解之外,Karypis 等人 [15]提出了一种并行多级图划分算法,以最小化每个级别上的二分。有一些启发式实现,例如 METIS [14]、METIS [23] 的并行和多约束版本,广泛应用于许多现有系统中。Pellegrini 和 Roman 提出了 Scotch [21]、[20],其中考虑了网络拓扑。尽管它们不能提供精确的性能保证,但这些启发式方法非常有效。[3] 中总结了更多启发式方法。
流式分区算法:上述方法都是离线的,需要昂贵的时间成本来处理。最近,Stanton 和 Kliot [27] 提出了一系列使用启发式的在线流分区方法。Fennel [29] 通过提出结合其他启发式方法的流分区框架扩展了这项工作。Charalampos E. Tsourakakis [28] 使用更长长度的游走来提高图划分的质量。Nishimura、Joel 和 Ugander、Johan [19] 进一步提出了 Restreaming LDG 和 Restreaming Fennel,它们使用最后的流分区结果生成初始图分区。LogGP [32]使用超图来优化初始划分结果。尽管没有数学证明,但实验表明这些单遍流式分区算法具有与短分区时间的多级流分区算法相当的性能。此外,它们适应动态图,在重新分区图时,离线方法由于昂贵的计算成本而变得低效。
异构环境计算:然而,上述这些实现并不能充分利用聚类信息来指导分区策略。最近,有一些工作侧重于考虑异构环境的处理作业。[33]研究了MapReduce框架中的异构性以改进Hadoop上的应用程序,但没有考虑图分区的异构性。[10]更接近我们的设置,提出了一种新颖的图划分框架,考虑到云环境上的网络带宽差异,使用多级算法。然而这项工作是基于云中的树形拓扑网络结构,缺乏一般性考虑。此外,它基于多级算法,对于当前的大规模图场景来说速度不够快。
背景和问题定义
在本节中,我们首先讨论异构环境的属性及其对当前并行图处理系统的影响。然后我们分析工作负载对图查询处理性能的影响。最后,我们正式定义了本文将研究的划分问题。
异构计算环境
当前云中异构环境普遍存在,其原因有以下三个。
1、自然异质性:尽管硬件相同,但在公共云上运行的应用程序通常会承受不可控的性能变化。这是由网络拓扑和个体差异引起的[10],[33]。虚拟机运行在不同物理主机上或运行在同一物理主机上可能会导致网络异构性。运行在不同物理节点上的虚拟机可能具有不同的CPU或CPU工作负载,从而导致计算异构性。在私有云中也可以观察到同样的现象,图2显示了由26个物理节点组成的数据中心的带宽和计算能力差异。从图2(a)可以看出,网络带宽变化很大。26 个实例每对的平均带宽为 105 MB/s。最高速度达到214MB/s,最低速度仅为10.4MB/s。图2(b)显示了单处理器计算100万位PI的运行时间。与网络带宽类似,计算能力也存在异构性。
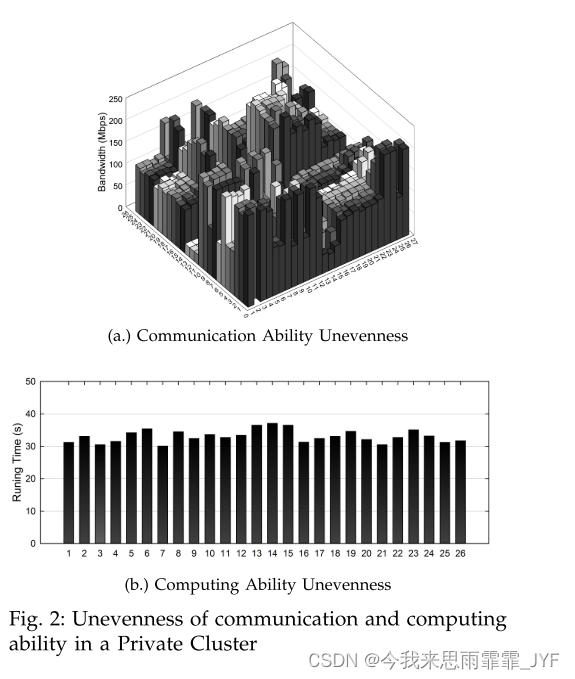
2、硬件异构性:通常,在私有云中,组织通常拥有多代硬件。新硬件可能配备比上一代更快的网络适配器和CPU,这导致计算和通信异构性[33]。
3、虚拟化:事实上,很多云系统都使用虚拟机来充分利用资源。一对节点之间的带宽可能取决于实例的分配方式。当两个实例分配到同一个物理节点时,它们之间的数据传输可以高速,而当两个实例分配到不同的节点甚至跨不同路由器的节点时,它们之间的数据传输会慢很多。因此,虚拟化影响计算和通信能力[31]。
异构环境通常具有两个特征。首先,不同对节点之间的网络带宽(指:两个计算节点之间传输数据的能力)可能会有很大差异。在两个不同的节点对之间传输相同量的数据将花费不同的时间。其次,节点的计算能力也有很大差异。
事实上,如果使用传统的图划分算法,就无法充分利用异构环境集群。这里我们再举一个例子来揭示传统图划分算法在异构环境中的问题。图 3 说明了在上述具有 METIS 分区图的集群中运行的 PageRank 算法的性能结果。浅色条显示 26 个节点的集群中每个节点的运行时间。总执行时间由最慢的节点决定。显然,与其他节点相比,节点 13、14 和 15 是集群的瓶颈,严重增加了执行时间(上方红线)。然后,我们删除这些速度较慢的节点,并在 23 个节点上重新运行相同的工作负载。如深色条所示,即使节点较少,该实验的运行时间(较低的红线)也优于前一个实验。
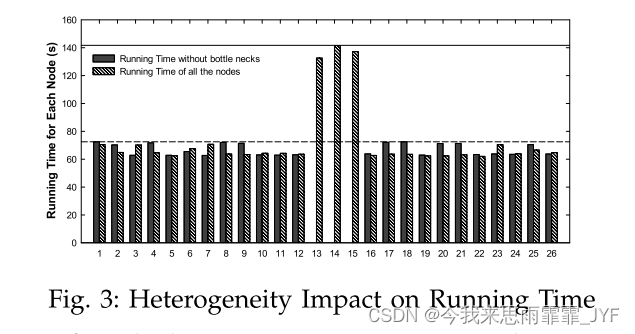
该实验表明,传统的同构图划分无法感知物理节点的性能。事实上,为节点分配相同的工作负载会导致性能较弱的节点成为系统的瓶颈。
工作负载分析
除了异构环境之外,图分区还应该考虑工作负载。但之前这个问题并没有引起足够的重视。查询工作负载影响计算和通信之间的时间比率。
图 4(a) 显示了两个工作负载统计推断 [6] 和两跳好友列表的实验。统计推理工作负载通常包含复杂的SVM计算,并且两跳好友列表需要在分区之间传输巨大的中间结果。我们记录在 HeAPS 中执行 UDF 函数和发送/接收数据时所用的平均时间百分比。我们可以看到,统计推断的运行时间以计算作业为主,而两跳好友列表的运行时间以 I/O 数据传输为主。
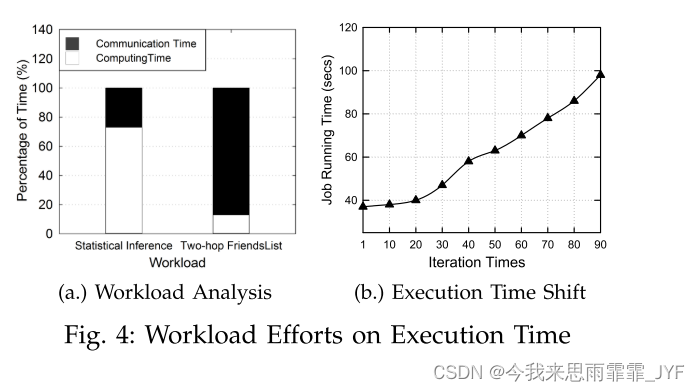
为了更好地理解并行图处理系统中通信成本和计算成本之间的转变,我们模拟了一系列任务。我们通过添加对邻域节点的 PR 值求和的附加迭代来重写 PageRank [7] 的 UDF 函数。我们使用不同的迭代时间来改变计算和通信比率。更长的迭代次数意味着更多的计算,而通信变得不那么重要。原始 PageRank 工作负载可以视为迭代时间等于 1。图4(b)显示,当迭代次数小于20时,作业执行时间主要由通信部分主导,因为运行时间仍然与原始PageRank相同。当迭代次数大于20时,执行时间与迭代次数成正比,计算部分在总体时间中占主导地位。
因此,为了平衡每个worker的执行时间,我们应该考虑工作负载。对于运行时间以计算为主的计算密集型工作负载,我们应该根据计算作业来平衡工作负载,而通信密集型工作负载则相反。传统的图划分框架缺乏对工作负载的分析,因此很难平衡每个worker的运行时间。
问题定义
在本文中,我们专注于减轻并行图处理系统在异构环境中的图划分挑战。
我们首先正式描述一般图划分问题。我们用 G = (V, E) 来表示要分区的图数据。V 是图中的一组顶点,E 是一组边。该图可以是有向的,也可以是无向的。令 Pk = {V1,…,Vk} 为 V 的 k 个子集的集合。如果满足以下条件,则称 Pk 是 G 的一个划分:Vi ≠ ∅,Vi ∩ Vj = ∅,且 ∪Vi = V ,对于 i, j = 1, …, k, i ≠ j。在本文中,我们将 Pk 的元素 Vi 称为分区的部分。数字 k 称为分区的基数。图划分问题是基于目标函数寻找最优划分Pk的组合优化问题。下面,我们给出一个正式的定义:
图划分问题可以定义为一个三元组 (S, p, f),使得:S 是 G 的所有分区的离散集。p 是 S 上的谓词,它创建 S 的子集,称为容许解集 Sp。f 是图划分目标函数。图划分问题的目标是找到一个划分
P
ˉ
\bar P
Pˉ ,其中
P
ˉ
\bar P
Pˉ ∈ Sp 并最小化 f(
P
P
P):
f ( P ˉ ) = M i n P ∈ S p f ( P ) f(\bar P) = Mi{n_{P \in {S_p}}}f(P) f(Pˉ)=MinP∈Spf(P)
特别是,如果图的顶点与其邻居集合按某种顺序到达,并且我们基于顶点流对图进行分区,则称为流图分区。令
P
k
t
=
V
1
t
,
.
.
.
,
V
k
t
P_k^t = V_1^t,...,V_k^t
Pkt=V1t,...,Vkt 为时间t的划分结果,其中
V
i
t
V_i^t
Vit 为时间t的划分 i 中的顶点集合。流图分区顺序地呈现一个顶点 v 及其邻居 N(v),并且它必须仅利用当前分区
P
t
{P^t}
Pt 中包含的信息将 v 分配给分区 i。顶点一旦放置,就不会被删除。
最近的大多数工作都将 k 平衡图分区用于并行图处理系统 [29]、[27]。k 平衡图分区问题的目标是最小化每个部分中具有相同数量顶点的分区之间的边切。它平衡了每个worker的计算成本并最小化了总的通信成本。然而,在并行图处理系统中,特别是在异构环境中,平衡顶点数量和最小化通信成本并不能最小化作业运行时间。3.2节和[25]中的实验表明,worker的运行时间由计算/通信作业共同决定,k 平衡图划分无法平衡每个节点的运行时间。
除了 k 平衡目标函数之外,本文还考虑到计算环境的异构性,提出了一种更合适的图划分目标函数。此外,我们的目标函数分析工作负载的通信和计算比率,以准确平衡每个节点的执行时间。
在此目标函数的基础上,我们探索了几种基于流模式的快速、高质量的异构感知分区算法。我们使用流分区模型进行异构感知分区。一方面,现有的近似方法或多级方法无法扩展到大数据,因为它们需要完整的图信息并且需要较长的运行时间。另一方面,流模型效率很高,无需完全访问所有图数据,并提供更快的速度、可比较的分区性能和增量更新[27]、[29]。
异构感知流图分区方法
在本节中,我们首先对异构环境进行建模并介绍本文中使用的符号。接下来,我们提出新的异构感知图分区问题定义和一些基于新目标函数的流启发式方法。
异构环境建模
为了更好地基于物理计算环境的异构性来划分图,我们首先对异构环境进行形式化建模。
我们引入物理图来对异构物理环境进行建模。物理图表示为带权无向图PG=(PV,PE)。PV 是图顶点的集合。每个顶点对应系统中的一个物理工作节点。我们使用 PVi 来表示集群中的物理节点 i。PE 是图中的边集。每条边代表一对物理节点之间的通信链路。请注意,实际上每个物理节点可以处理数据图的多个顶点分区。不失一般性,我们假设每个物理节点只处理一个分区。给定分区 Pk = {V1,…,Vk},我们使用 Vi 表示分配给 PVi 的顶点,使用 Edge(Vi, Vj) 表示 Vi 和 Vj 之间的边。另外,假设每个物理节点的内存容量为 Mi,我们确保 Mi 大于分配给 PVi 的数据。
接下来,我们揭示如何量化分布式环境的异构性,即数据处理速度和网络带宽方面。计算密集型应用高度依赖数据处理速度,而通信密集型应用则关注网络带宽。因此,环境的异构性测量应同时考虑数据处理速度和网络带宽。我们使用两个异构性指标:每个物理节点的计算能力和每对节点之间的通信能力。我们定义和收集这两个指标:
计算能力:它以某个物理节点在单位时间内可以执行的计算量来衡量。本文采用浮点运算作为计算单元,并用 Ci 来表示 PVi 的计算能力。可以通过运行某个基准测试来确定,该基准随机生成两个浮点数并在 PVi 上计算 1,000,000 次乘法结果。我们记录响应时间并计算一个操作所用的时间,表示为 TcTime i(结束时间 - 开始时间)。事实上,我们使用 TcTime i 作为实验值。然而,TcTime i 是一个小浮点数,为了便于阅读,我们使用 Ci 表示标准化的 TcTimei。如果这些节点的最大运行时间为 PVm,运行时间为TcTime max,那么我们可以使用以下公式得到 Ci。
C i = T c T i m e max T c T i m e i {C_i} = \frac{{TcTim{e_{\max }}}}{{TcTim{e_i}}} Ci=TcTimeiTcTimemax
通信能力:每对物理节点*(i,j)*之间的通信能力以单位时间内可以通过其链路的数据量来衡量;在本文中,我们使用64位数据作为通信单元。我们用 L(i,j) 来表示物理节点 PVi 和 PVj 之间的通信能力。我们假设给定物理对的任一方向上的通信能力是相同的,即 L(i, j) = L(j, i)。我们让 L(i, i) = 0,这意味着我们忽略物理节点内部通信的成本。我们通过从节点 i 到 j 发送数据块来测量通信能力。我们记录从 Mi 到 Mj 的传输时间为 TsTime(i,j)。我们在实验中假设全双工通信。与计算能力类似,令 TsTime max 为所有节点对中最大的时间,L(i, j) 可以通过以下方式归一化:
L ( i , j ) = T s T i m e max T s T i m e ( i , j ) L(i,j) = \frac{{TsTim{e_{\max }}}}{{TsTime(i,j)}} L(i,j)=TsTime(i,j)TsTimemax
目标函数
在对异构环境进行建模之后,我们现在分析分区目标函数。在BSP模型中,一个作业被划分为一系列超级步骤。在图 5 所示的每个超级步骤中,每个物理节点针对分配给它的所有顶点,计算用户定义的函数,并向其邻居发送/接收消息。每个物理节点的进程是并行的。每个超级步骤中有一个同步步骤,以确保所有节点完成其工作负载。因此,每个超级步的运行时间由最慢的节点决定。
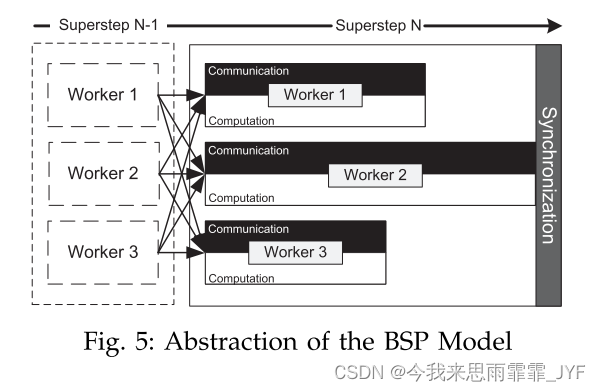
这里我们用
τ
n
{\tau ^n}
τn 表示第 n 个超级步骤的运行时间,用
τ
i
n
\tau _i^n
τin 表示 PVi 在第 n 个超级步骤所花费的时间。
τ
n
{\tau ^n}
τn 等于
τ
i
n
\tau _i^n
τin 的最大值。我们使用 JobTime 来表示图处理作业的总运行时间,它是每个超级步骤中最慢的节点的运行时间之和,如公式 4 所示。
J o b T i m e = ∑ ( τ n ) = ∑ ( M a x ( τ i n ) ) \begin{array}{c} JobTime = \sum {({\tau ^n})} \\ = \sum {(Max(\tau _i^n))} \end{array} JobTime=∑(τn)=∑(Max(τin)) (4)
为简单起见,我们假设数据图中的每个顶点都是活动的,并向其所有邻居发送消息。对其他模型的讨论超出了本文的范围。在此假设下,对于节点 PVi,每个超步的运行时间是稳定的,记为 τ ˉ i {\bar \tau _i} τˉi。如果我们总共有 t 个超级步骤,则作业的执行时间等于:
J o b T i m e = t × M a x ( τ ˉ i ) JobTime = t \times Max({\bar \tau _i}) JobTime=t×Max(τˉi) (5)
事实上,图分区的目的是最小化JobTime。当然,我们的目标函数可以表示为公式6。
Min(JobTime) = Min(Max( τ ˉ i {\bar \tau _i} τˉi)) (6)
正如第 3 节中提到的, τ ˉ i {\bar \tau _i} τˉi 由通信时间和计算时间共同决定:
τ ˉ i = f s ( t i c o m p , t i c o m m ) {\bar \tau _i} = {f_s}(t_i^{comp},t_i^{comm}) τˉi=fs(ticomp,ticomm) (7)
函数 fs 由系统实现决定。如果系统采用CPU和I/O串行操作的I/O阻塞模式,
那么, τ ˉ i = t i c o m p + t i c o m m {\bar \tau _i} = t_i^{comp} + t_i^{comm} τˉi=ticomp+ticomm (8)
如果系统并行处理 I/O 操作,
那么, τ ˉ i = M a x ( t i c o m p , t i c o m m ) {\bar \tau _i} = Max(t_i^{comp},t_i^{comm}) τˉi=Max(ticomp,ticomm) (9)
计算时间
t
i
c
o
m
p
t_i^{comp}
ticomp 由 PVi 中的计算工作量和 PVi 的计算能力决定。通信时间
t
i
c
o
m
m
t_i^{comm}
ticomm 由 PVi 中的通信工作量和 PVi 的通信能力决定。
现在我们可以基于最小化作业执行时间来定义图分区问题的新目标函数,我们称之为时间最小化图分区。给定数据图 G = (V, E) 和物理图 PG = (PV, PE)。使得:
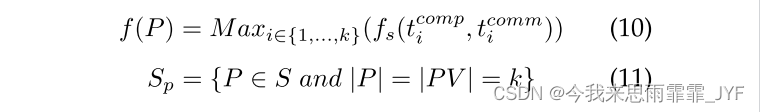
时间最小化图划分的目的是找到最小化 f 的划分
P
ˉ
∈
S
p
\bar P \in {S_p}
Pˉ∈Sp:
f ( P ˉ ) = M i n P ∈ S p f ( P ) f(\bar P) = Mi{n_{P \in {S_p}}}f(P) f(Pˉ)=MinP∈Spf(P) (12)
在 BSP 模型中,我们的时间平衡目标函数比 k 平衡目标函数更合适。正如3.3中提到的,K平衡图分区旨在平衡每个worker的计算成本并最小化总通信成本。而不同节点上可能存在通信偏差并增加作业运行时间。除了包含 K 平衡图分区的约束之外,我们的新目标函数侧重于最小化应用程序的总运行时间。
流式启发法
NP-hardness:与传统图划分问题的目标函数不同,时间最小化图划分是组合优化问题的 Min-Max 版本。现在我们证明时间最小化图划分问题是 NP 困难的。我们使用另一个最小-最大组合优化问题,最小完工计划(MMS)并将我们的问题简化为它。给定 n 个作业 p1、p2、…、pn 和整数 m 的处理时间,找到将作业分配给 m 个相同机器的方法,以使完成时间最小化,称为最小完工时间调度问题。[8]证明当 m ≥ 2 时,MMS 问题是 NP 困难的。
定理 1:当分区基数 k ≥ 2 时,时间最小化图分区问题是 NP 难问题。
证明:。。。
为了解决时间最小化的图分区,如上所述,我们更喜欢使用单通流而不是其他方法来获得快速的处理速度和可接受的结果[27],[29]。我们使用流式加载器读取数据图中的顶点并按一定顺序序列化它们。流式加载器生成的顶点顺序有多种变化,即随机、从起始顶点开始的 BFS/DFS 或对抗顺序。[27]证明了BFS和DFS方法产生的结果与随机方法几乎相同。同时,随机方式避免了对抗性排序。因此,在这项工作中,我们使用随机顺序作为流加载器的输出顺序。
然后,加载器将顶点及其邻居集发送到分区程序,该分区程序执行流图分区,如算法 1 所示。启发式函数根据当前分区状态、顶点信息和物理图确定传入顶点的分配。

事实上,启发式函数决定了划分的质量。在介绍启发式之前,我们首先讨论如何在流模型中估计
t
i
c
o
m
p
t_i^{comp}
ticomp 和
t
i
c
o
m
m
t_i^{comm}
ticomm。在BSP模型中,计算工作量是由顶点在每个超步中执行的UDF函数引起的。通信工作负载是由向/从其他顶点发送/接收消息以执行分布式计算引起的。通常,顶点生成本地消息与同一分区中的其他顶点交换消息,并生成远程消息与另一个分区中的顶点交换消息。事实上,生成和处理本地消息比非本地消息要快得多,因此我们忽略处理本地消息的时间成本。在流模型中,我们使用 Pk(v) = {V1(v), V2(v), …, Vk(v)} 表示分区集,使用 Vi(v) 表示分配给 PVi 的顶点集,当顶点 v 位于流的头部。
c
o
s
t
i
c
o
m
p
(
v
)
cost_i^{comp}(v)
costicomp(v) 和
c
o
s
t
i
c
o
m
m
(
v
)
cost_i^{comm}(v)
costicomm(v) 分别表示顶点 v 到来时 Vi(v) 的估计计算时间和通信时间。令 w(vertex) 为每个顶点的平均计算工作负载量,w(edge) 为每个边的平均通信工作负载量。那么
c
o
s
t
i
c
o
m
p
(
v
)
cost_i^{comp}(v)
costicomp(v) 和
c
o
s
t
i
c
o
m
m
(
v
)
cost_i^{comm}(v)
costicomm(v) 可以通过以下方式计算:
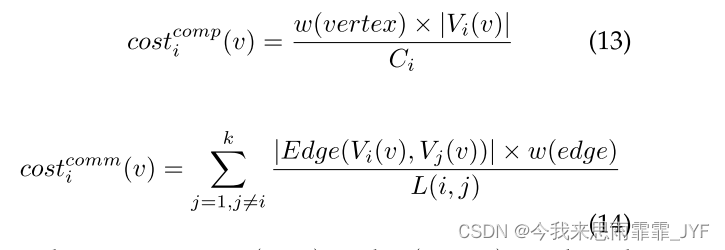
参数 w(edge) 和 w(vertex) 是基于工作负载的,我们将在4.4节中进一步讨论。当顶点 v 被分配到一个分区时,我们计算 v 产生的增量计算和增量通信成本。我们使用
Δ
cos
t
i
c
o
m
p
(
v
)
\Delta \cos t_i^{comp}(v)
Δcosticomp(v) 和
Δ
cos
t
i
c
o
m
m
(
v
)
\Delta \cos t_i^{comm}(v)
Δcosticomm(v) 分别表示增量计算时间成本和通信时间成本。同样,它们可以通过以下方式计算:
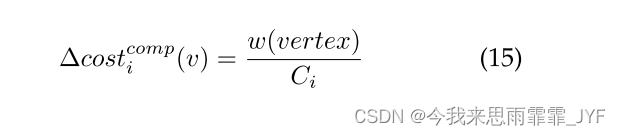
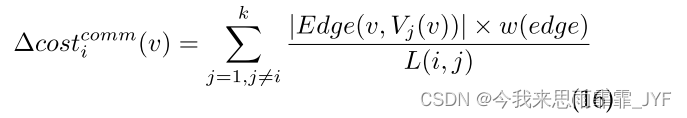
最后,当流中的所有顶点都被分配时,
t
i
c
o
m
p
t_i^{comp}
ticomp 和
t
i
c
o
m
m
t_i^{comm}
ticomm可以通过
cos
t
i
c
o
m
p
(
v
n
)
\cos t_i^{comp}({v_n})
costicomp(vn)和
cos
t
i
c
o
m
m
(
v
n
)
\cos t_i^{comm}({v_n})
costicomm(vn) 来估计。这里,
v
n
{v_n}
vn 是流中的最后一个顶点。
分析参数后,现在我们根据时间最小化目标函数正式定义启发式。在我们的系统中,我们使用阻塞I/O模型,其中CPU和I/O串行操作。在此模型中,
τ
ˉ
i
=
t
i
c
o
m
p
+
t
i
c
o
m
m
{\bar \tau _i} = t_i^{comp} + t_i^{comm}
τˉi=ticomp+ticomm。请注意,
cos
t
i
c
o
m
p
(
v
)
\cos t_i^{comp}(v)
costicomp(v) 和
cos
t
i
c
o
m
m
(
v
)
\cos t_i^{comm}(v)
costicomm(v) 都是估计的运行时间,我们可以直接对两个时间单位进行线性求和。
1)Min-Workload(MW) - 最直接的启发式算法是将 v 分配给具有最小工作负载的分区。如果结果相同,我们会随机分配给一个分区。Min-Workload更多地关注于工作负载平衡,但对每个顶点产生的额外成本的权重较小。因此,它可能是平衡的,但具有巨大的通信成本。
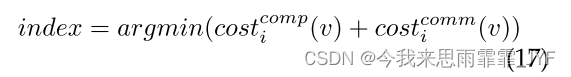
2)Min-Increased(MI)—将v分配给增量工作负载最小的分区。这种启发式方法探讨了每个顶点增加的代价最小的思想。与Min-Workload相比,Min-Increased的目标是最小化每个顶点的增量工作量,而忽略平衡。
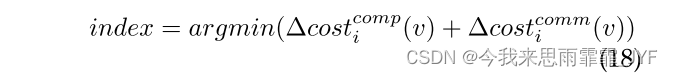
3)平衡的最小增量(BMI)—将v分配给增量工作负载最小的分区,并根据该分区中的总工作负载进行惩罚,以细化分数。这种启发式方法倾向于找到一个分区,它不仅具有较低的当前成本,而且更重要的是对顶点产生较小的额外成本。我们使用惩罚函数来平衡工作负载。[13]使用 Penalty(x) = x 来解决另一个类似的问题。但是,这个简单的函数倾向于平衡工作负载。在本文中,我们将此函数扩展为一系列函数,Penalty(x) =
x
λ
{x^\lambda }
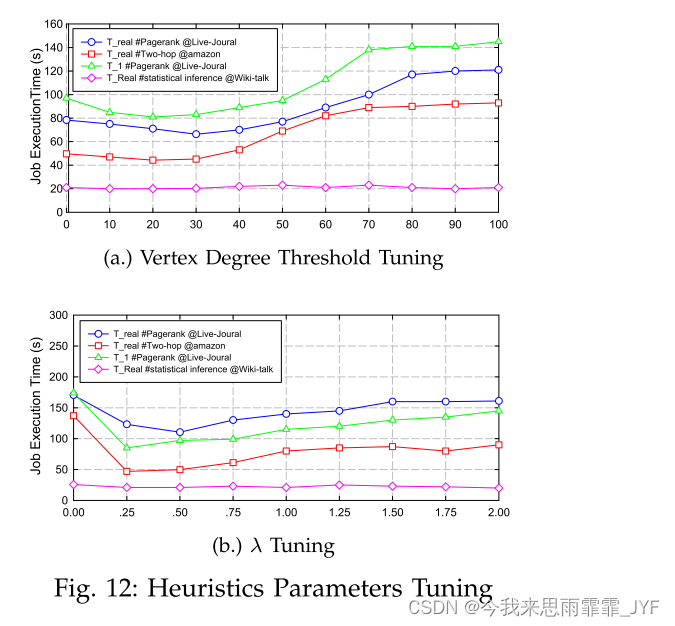
xλ。特别地,当λ=0时,Penalty(x)是常数,使得Balanced Min-increase启发式退化为Min-increase。当 λ 变大时,Balanced Min-increase 更接近 Min-Workload。 λ 的选择将在 5.2 节中讨论。
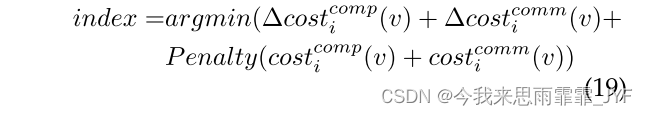
4)Combined(CB) - 给出一种将顶点分为高度和低度的方法,然后使用 Min-Workload 分配低度顶点,使用 Balanced Min-Increased 分配高度节点。阈值的选择将在 5.2 节中讨论。
5)计算平衡散列(CPH) - 根据 PVi 的计算能力以概率将 v 分配给分区 i。PVi 中的顶点数量与 Ci 成正比。这种启发式方法根据计算能力来平衡工作负载。
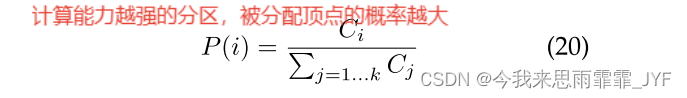
6)通信平衡散列(CMH) - 根据 PVi 的通信能力以概率将 v 分配给分区 i。它类似于使用通信能力作为衡量标准的平衡计算。
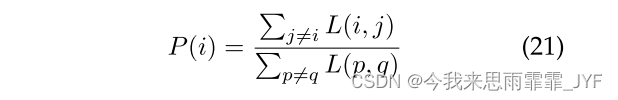
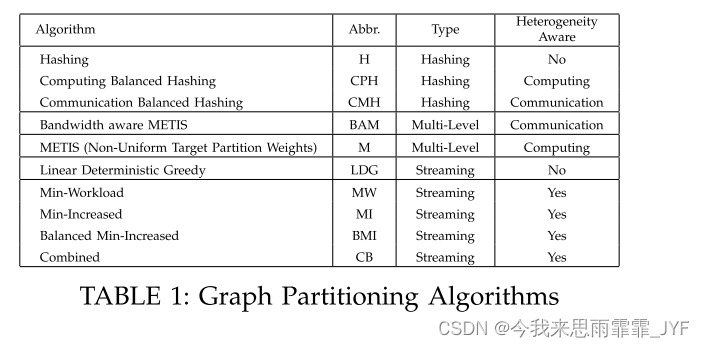
事实上,我们使用规则5和规则6作为基于计算能力和通信能力分配工作量的基准。我们将其他启发式与计算平衡散列和通信平衡散列进行比较。此外,我们还与其他最先进的流和多级算法进行了比较。表 1 总结了图划分算法。
用数学下限来分析每个启发式是很有价值的。不幸的是,对于流的随机顺序,对于一次性流分区算法,找到最佳下界是 NP 困难的[27]。[26]已经证明,没有算法可以通过随机或对抗性流排序获得 O(n) 近似。因此,在本文中,我们提出了几种启发式方法,并将在以后的实验研究中报告它们的表现。
基于工作负载的参数
在本小节中,我们讨论如何根据工作负载计算 w(edge) 和 w(vertex)。 w(vertex) 是一个顶点的计算作业量。w(edge) 是一条边的通信作业量。我们引入这两个参数来分别标准化计算成本和通信成本,它们仅用于我们的启发式。因此,我们可以通过将计算成本和通信成本相加来得出总成本,同时公平且无偏见。为了计算 w(edge) 和 w(vertex),我们引入了以下特定于工作负载的指标。
渐近时间复杂度是对一个顶点的计算工作量的估计。假设数据图上一个顶点的平均邻居数为 n,则该度量可以使用 O(F(n)) 表示。
渐近通信复杂性是对一个顶点的通信工作量的估计。我们使用 O(T(n)) 来表示这一度量,n 是数据图上一个顶点的平均邻居数。
O(F(n))使用相同的计算能力单位Ci,O(T(n))使用相同的通信能力单位L(i,j)。这两个指标用作先验知识。以工作负载PageRank为例,如果我们使用浮点运算作为计算单元,64位作为通信单元。具有 n 个邻居的顶点的计算复杂度为 F(n) = O(n),通信复杂度为 T(n) = 1。这里,n是顶点的邻居数。这些值 F(n) 和 T(n) 可以根据流信息轻松计算出来。然后,我们得到:
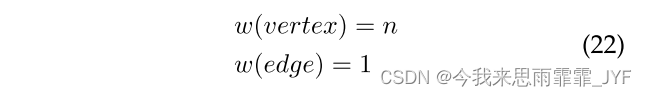
使用这两个参数,我们可以更准确地估计一个顶点的处理成本。
实验
为了评估我们的异构感知图分区方法的性能,我们开发了一个原型系统(异构环境感知图处理系统,即 HeAPS)。它遵循Google的Pregel设计[18],采用块I/O模型,其中CPU和I/O串行操作。我们实现了上面讨论的流图分区算法和其他最先进的图分区算法进行比较。
我们进行了严格的实验来评估本文提出的异构分区方法。我们首先介绍实验设置,其中包括数据集描述、异构环境设计和所选的评估指标。然后我们揭示了在不同环境、数据集和工作负载设置下展示的分区性能。最后,我们讨论启发式规则中使用的参数的影响。
实验装置
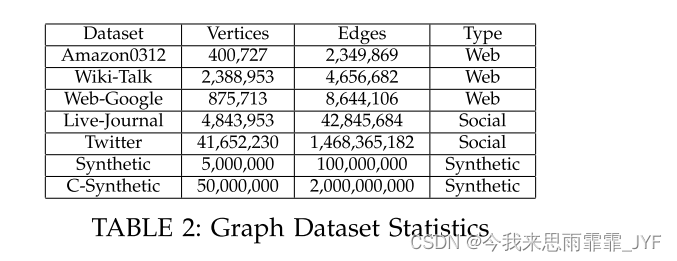
数据集:我们使用了 5 个真实世界的图表:LiveJournal、Amazon0312、Twitter、Web-Standford 和 Web-Google;和两个合成图。所有实验数据集如表 2 所示。真实世界数据集可在网络上公开获取 [4]。我们将其转化为无向图,并在原始图的基础上增加倒边,消除环圈。
异构集群:我们在两个代表性集群上进行了实验,并调整了一些设置以反映丰富的异构环境。第一个集群(ClusterA)是一个具有 28 个节点的同构集群。每个节点都有AMD Opteron 4180 CPU、48GB内存、1000Mbit网络适配器和10TB磁盘RAID。CPU 具有 0.8 GHz、1.8 GHz 和 2.6 GHz 的可变 CPU 频率。所有节点均通过 1 Gbps 路由器连接。我们手动更改硬件配置来模拟硬件异构性。这反映了当组织升级硬件或某些机器成为集群瓶颈时的场景。对于这个集群,我们通过以下步骤模拟了通信和计算能力的不平衡。
- 通信能力(网络带宽):我们通过不同的网络带宽来模拟不同的通信能力。受虚拟机设计的启发,我们使用包装的虚拟网络适配器 (VNA) 新颖地模拟网络带宽。VNA连接真实的网络适配器和HeAPS客户端,以便客户端通过VNA相互连接,并且可以设置不同的带宽。因此,我们可以以受控的方式模拟网络带宽。
- 计算能力:为了模拟不同的CPU硬件,我们将CPU设置为不同的频率。在我们的实验中,我们使用了三个级别的频率:2.6GHz、1.8GHz 和 0.8GHz。
另一个集群(ClusterB)是如图2所示的异构集群。我们使用这个集群来模拟自然的异构环境。
异构拓扑:我们在实验中使用了七种模拟集群拓扑(ClusterA)和一种真实拓扑(ClusterB)。下面列出了拓扑及其符号。
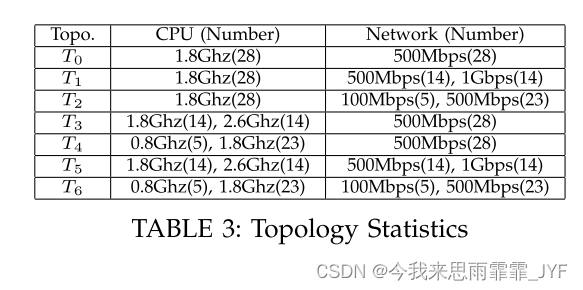
如表3所示,T0:被视为均匀环境。T1:所有CPU频率均设置为1.8Ghz。一半 NVA 调整为 500Mbps,另一半调整为 1000Mbps。这用于模拟网络性能的提高。例如,升级网络适配器带宽或升级路由器带宽。T2:所有CPU频率均设置为1.8Ghz。其中 5 个 NVA 设置为 100Mbps,其他设置为 500Mbps。这是为了模拟某些节点成为网络瓶颈。T3:一半CPU频率设置为2.6Ghz,其余设置为1.8Ghz。所有 NVA 均为 500Mbps。这是CPU升级的模拟。T4:其中5个CPU频率设置为0.8Ghz,其他为1.8Ghz。所有 NVA 均为 500Mbps。这是为了模拟某些机器的计算能力低于其他机器。我们想测试计算瓶颈是否影响图划分算法的性能。T5:一半机器使用 2.6Ghz 的 CPU 频率和 1000Mbps 的 NVA。其他使用 1.8Ghz 的 CPU 和 500Mbps 的 NVA。这是升级具有强大CPU和网络的硬件的模拟。T6:其中 5 台机器使用 0.8Ghz 的 CPU 频率和 100Mbps 的 NVA。其他使用 1.8Ghz 的 CPU 和 500Mbps 的 NVA。这是对具有 10 台机器的集群的模拟,性能较低,是瓶颈。Treal:我们使用图 2 中的原始网络配置和 CPU 频率。对于每个拓扑,我们测量 4.1 中提到的指标并生成物理图来对异构环境进行建模。
评估指标:为了系统地评估异构环境中的分区和计算性能,我们选择一组评估指标来衡量每个算法的性能。 - **边切割率(ECR)**表示图中分区之间的切割边的百分比,定义为ECR = ec/|E|,其中ec表示分区之间的切割边的数量,|E|表示图中边的总数。事实上,在异构环境中,ECR无法指示应用程序的运行时间。为了进行更好的评估,我们引入了以下附加指标。
- **作业执行时间(JET)**测量从将图处理作业提交到 HeAPS 到作业完成所花费的时间。这里我们只记录了超步的执行时间,不包括加载时间。
- 运行时间标准差(SDT)。我们测量了每台机器每个超级步的运行时间总和。然后我们计算标准差来评估划分结果是否平衡。
比较方法:在本实验中,我们选择了几种最先进的划分方法作为基线,以证明我们提出的方法的优势。表1列出了以下实验中使用的分区算法。这里选择的最有效的同质算法包括散列和最佳流式启发式线性确定性贪婪方法[27]。此外,我们还将我们的流算法与广泛使用的多级方法 METIS [14] 和异构带宽感知 METIS [10] 进行了比较。对于 METIS,我们启用了非均匀目标分区权重选项。 METIS中使用的每个分区的权重是根据 PVi 的计算能力生成的。
分区性能
现在我们展示不同图划分算法在不同环境下的划分性能。我们针对表 2 中所示的所有图形数据集和多个工作负载运行了实验。由于篇幅限制,这里主要展示一些数据集上的结果。其他数据集上的实验结果也显示出相似的性能。所有实验进行五次并报告平均结果。
我们将输入图划分为 ClusterA 的 28 个分区和 ClusterB 的 26 个分区。事实上,拓扑可以分为4种类型的环境,即同构环境、I/O异构环境、CPU异构环境和I/O&CPU异构环境。
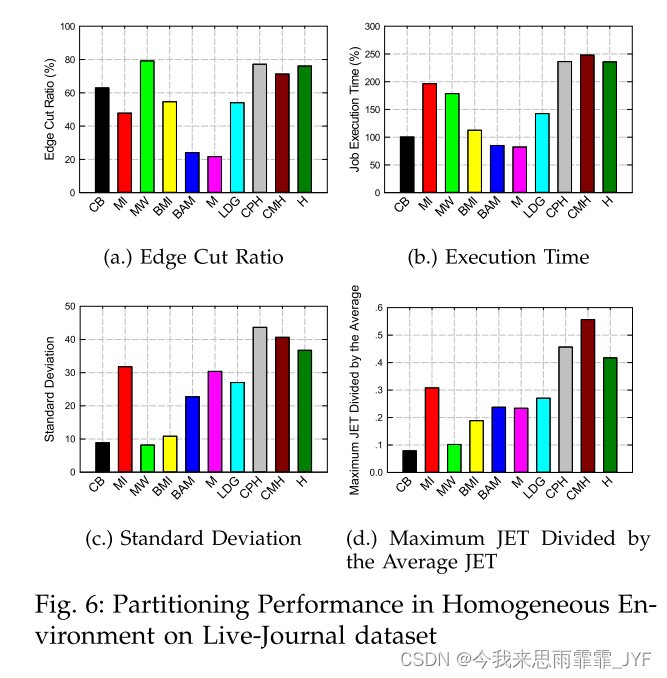
同质环境:如图 6(a) 所示,我们在运行 10 次迭代的 Pagerank 工作负载的同质环境 T0 中的 Live-Journal 数据集上测试了这些算法。我们的启发式算法接近最佳竞争对手,同质流图划分,ECR上的LDG。在图 6(b) 中的作业执行时间上,异构感知流方法、平衡最小增加和组合优于 LDG。这种减少是由于我们新的目标函数对每个节点的工作负载平衡效应带来的。多级算法在低边缘切割率方面优于流式算法。正如我们所看到的,我们的一些方法具有更高的 ECR,同时具有更短的作业执行时间。原因是作业执行时间是由系统中最慢的节点决定的。传统的图划分方法,例如METIS 和 LDG 的目标是最小化边缘切割率,而我们提出的反对函数旨在最小化执行时间。JET 的标准差和最大 JET 除以平均 JET 的结果如图 6(c)和(d)所示,证明 Balanced Min-increases、Combined 和 MinWorkload 算法比其他算法可以获得更平衡的运行结果。
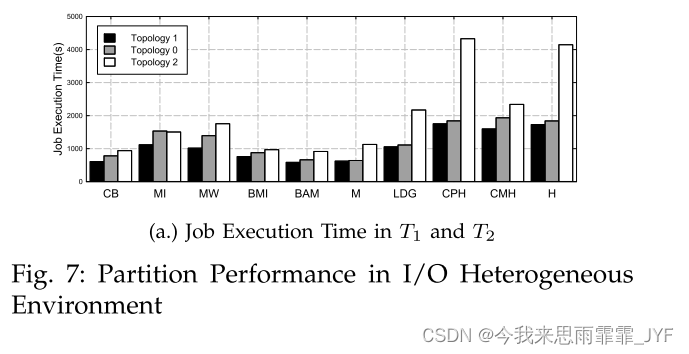
I/O 异构环境:我们在拓扑 T1、T2 上评估了这些算法。在图 7 中,我们显示了 Twitter 数据集上拓扑 T1、T2 和 T0 中的作业执行时间。我们的异构启发式算法显着优于同构流算法。这是因为当某些节点具有更快的通信速度时,我们的方法可以自适应地为这些节点分配更多的通信工作量,并减少较慢节点的负担。因此,总运行时间可以显着减少。短的执行时间和低方差证明了所提出方法的优越性。异构算法根据通信能力来平衡工作负载,使得性能较低的节点分配较少的工作负载并且可以更快地完成任务。
CPU异构环境:拓扑T3、T4属于这种类型。图 8 显示了运行 10 次迭代 Pagerank 工作负载的综合数据集上 T3、T4 和 T0 的 JET。在CPU能力升级的拓扑T3中,带宽感知METIS仅获得3%的运行时间改进,因为它不感知计算能力的变化。相比之下,与 T0 相比,几乎我们所有的启发式方法在 JET 中都有超过 40% 的改进。此外,组合启发式优于带宽感知 METIS,后者需要更长的时间来划分图。在拓扑 T4 中,组合和平衡最小增加启发式算法均优于带宽感知 METIS,因为后者运行时间大幅增加。与 T0 中使用的时间相比,METIS 运行工作负载的时间多了大约 49%,其他同类算法在 JET 中通常也会遭受大约 30% 的退化。
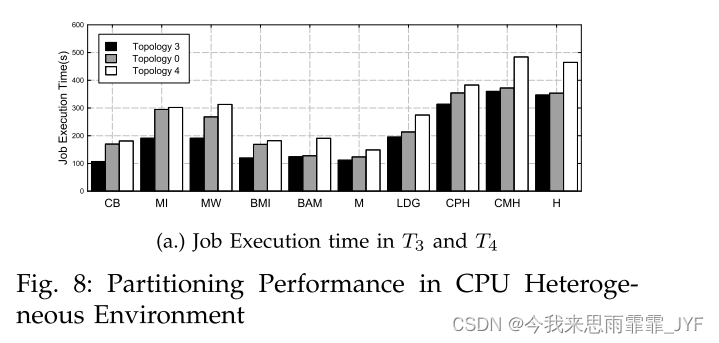
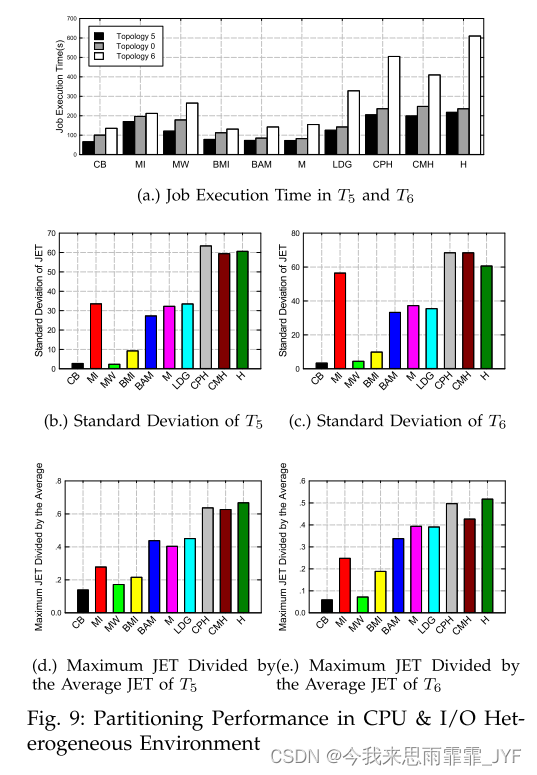
I/O 和 CPU 异构环境:我们在 LiveJournal 数据集上的拓扑 T5 和 T6 中运行了此实验,运行 10 次迭代的 Pagerank 工作负载,其中考虑了 I/O 和 CPU 异构性。图 9 中的结果表明,在拓扑 T5 和 T6 中,我们的最佳启发式组合和平衡最小增加比带宽感知 METIS 花费的处理时间更少。与LDG/METIS相比也有显着的改进。图9(b)和©显示了物理节点的标准差。标准差表明工作量的不平衡。正如我们所观察到的,同质方法和带宽感知 METIS 高度不平衡。这是因为,在这种 CPU 和 I/O 异构环境中,同类方法仍然将工作负载均匀地分配给每个节点,并且带宽感知 METIS 可以解决 I/O 异构性。事实上,如图9(a)所示,不平衡的工作负载显着影响了整体运行时间。相比之下,我们的方法可以通过在高性能节点上分配更多顶点来更好地利用高性能节点,并使每个分区的工作负载更加平衡。图 9 (d) 和 (e) 进一步显示了拓扑 T5 和 T6 中的最大 JET 除以平均 JET,这证实了我们的方法可以平衡节点上的 JET 时间。
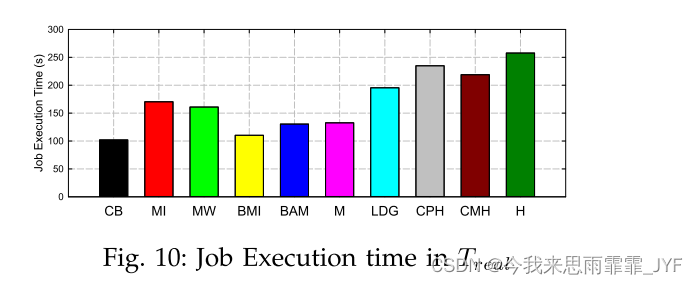
自然异构性:我们继续在具有 26 个节点的真实集群 Treal 上评估我们提出的异构分区方法的性能。我们测量了该集群上的物理图,并在 LiveJournal 数据集上运行了 10 次迭代的 PageRank 工作负载。如图 10 所示,最佳算法是组合算法,其次是平衡最小增加算法和带宽感知 METIS。LDG大约比Combined花费两倍的时间。该实验证实我们的方法适用于自然异构环境,这在现代云基础设施中尤其常见。
从以上三个实验可以得出结论,我们提出的分区算法在不同情况下都是鲁棒且高效的,并且当计算环境从同质变为异构时可以带来令人印象深刻的好处。此外,与CPU异构环境中的CPH和I/O异构环境中的CMH相比,组合平衡最小增加启发法显示出显着的改进。这表明我们的启发式方法不仅可以平衡工作负载,还可以降低通信成本,从而最大限度地减少处理作业的总运行时间。
我们进一步研究了平衡最小增量法和组合启发式法中使用的参数。
结论
在本文中,我们系统地研究和建模了当前并行图处理系统中异构计算环境的特征。然后,我们提出了一种新颖的图划分目标函数来解决复杂异构计算环境中当前的挑战。基于这个策略,我们设计了几种基于流的启发式算法,可以显着提高分区性能并减少作业执行时间。实验结果验证了我们新方法的优越性。
我们未来的工作有几个有希望的方向。首先,对异构分区场景进行进一步的理论分析是有价值的。其次,流处理的新排序是提高分区性能的潜在方法。最后,我们可以深入到工作负载世界,提取模式,以更好地指导和改进并行图处理系统。















 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









