







1.Introduction

本文不仅检测object, 还把object分为human和物体, 考虑任何物体的关联关系. 目的是学习一个三元组关系<human, action, object>
2.method

作者 在fast rcnn基础上扩展来个分支, 获得三元组的score, 该score由4部分组成:
S
h
,
o
a
=
s
h
⋅
s
o
⋅
s
h
a
⋅
g
h
,
o
a
(1)
S_{h, o}^{a} = s_h \cdot s_o \cdot s_h^a \cdot g_{h, o}^a \tag{1}
Sh,oa=sh⋅so⋅sha⋅gh,oa(1)
- sh和so为检测分支human, object的分类分数
- sha 为human的action分数
- μha 为human交互的object的位置
- gh,oa 为human物交互的似然估计
2.1Model
Object Detection
和faster-rcnn一样, RPN网络产生proposals, 通过RoiAlign提取特征, 然后回归类别与边界框.注意!!!这些边界框只在inferecnce的时候使用, 训练期间使用的为RPN预测的proposals
Action Classification
和分支(a)相似, 通过RoiAlign提取human的特征, 然后得到human的action分数. 由于human可以同时具有多个action(如, 站, 切菜), 所以, 是一个多action的输出, (可以理解为分类), 优化目标为groundtruth和预测action分数sha 的二进制交叉熵.
Target Location
同样通过RoiAlign提取human的特征, 然后预测object的位置.但是只通过该特征预测精确位置是很难的, 所以预测一个概率密度分布, 最后结合检测的objects得到精确的位置.
作者使用高斯函数建立概率密度, 参数μha 由该分支回归得到.公式为: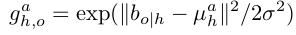
其中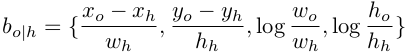
为object相对human的四维位置, 所以μha也是四维的.这和fast rcnn中的回归编码相似. 不同的是human和object是两个不同的目标, 同时object也不需要靠近human(fast rcnn 回归的相对位置起着校正结果的作用). 优化目标为bo|h和μha的smooth L1 Loss. sigma为超参数, 作者设为0.3

如图为human和object交互位置的高斯分布可视化结果. carry action表明object在手上, throw action 表明object在human的前方, sit action 表明object 在human的下方. 所以该分支可以有效的根据human的位置特征, 以及action 预测 object的相对位置.即human, action与object有着关联关系.黄虚线为回归的位置μha (相对位置转为实际位置), 可以看出, 这只是object的粗略位置. 作者做文章的section5 对模型做了一点改进, 可以使模型处理一个action对应多个targets.
Interaction Recogtion
该分支是灵活加入(可以不加入). 分支b只考虑了human的特征, 没有联合考虑. 所以可以替换公式(1)中的sha 为sh,oa . 模型如图3分支c所示, sha可以直接复用分支b, 另一部分并行特体object的特征回归分数, 再将两部分vectors相加接一个sigmoid层得到分数sh,oa
优化目标为groundtruth和预测分数sh,oa 的二进制交叉熵.(同分支b中的action部分)
Multi-task traning
该任务看为一个多任务学习的过程. 三个分支联合训练. 总loss为三个分支loss的和.所有的loss通过rpn proposal 和groundtruth计算. 对每一个图按照正负样本(1:3)sample, 总数最多64个.所以最多16个human 框, 所有的框, 和groundtruth计算iou>0.5进行match, 得到框的类别(human 或者object). 交互分支c的loss只计算正样本三元组. 三个loss权重为1, 其中分支2的action分类部分权重为2:
L
o
s
s
e
s
=
l
o
s
s
a
+
l
o
s
s
b
+
l
o
s
s
c
l
o
s
s
a
=
l
o
s
s
a
_
r
e
g
+
l
o
s
s
a
_
c
l
s
l
o
s
s
b
=
2
⋅
l
o
s
s
b
_
c
l
s
+
l
o
s
s
b
_
r
e
g
l
o
s
s
c
=
l
o
s
s
c
_
c
l
s
Losses = loss_a + loss_b + loss_c \\ loss_a = loss_{a\_reg} + loss_{a\_cls} \\ loss_b = 2 \cdot loss_{b\_cls} + loss_{b\_reg} \\ loss_c = loss_{c\_cls}
Losses=lossa+lossb+lossclossa=lossa_reg+lossa_clslossb=2⋅lossb_cls+lossb_reglossc=lossc_cls
- cls为交叉熵
- reg为smooth L1
Cascaded Inference
inference的目的是找到分数最高的三元组 原则上需要O(n2)的复杂度, 作者采用了一个简单的O(n)的算法.
- 分支a: 先做NMS(IOU>0.3), 再取score>0.05的框. 然后将这些框作用在分支b, c上(和训练的时候不同, 训练的时候用的,groundtruth确定类别, 使用的是rpn的proposal)
- 分支b: 使用分支a的结果计算sha, μha , 复杂度为O(n)
- 分支c, 使用分支a和b得到sh,oa , 复杂度为O(n2), 但实际上是微不足道的???
当一行部分都计算出的时候, 可以计算三元组得分. 作者并不是直接计算所有可能的三元组得分. 而是利用分支b的action以及位置信息, 寻找human对应的可能的object的最大值.
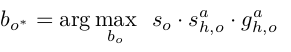
如过图中只有人的动作, 则没有object, 退化为二元组<human, action>
最终的速度为135ms/per image 在单卡Nvidia M40 GPU
Experiments
细节
检测模型为faster-rcnn + fpn, backbone为res50 7*7RoiAlign, 每一个分支都有1024的全连接层.同步梯度下降, 8GPUS batch2.学习率0.001 step为0.0001
结果



作者试图用过Mixture Density Network 替代分支b中的定位网络, 但是发现没有提高, 具体细节见文章附录.
启发:
- 本文的亮点在于人物交互, 在检测出人和物体以后, 通过分支b, c得到action, 建立人与物的三元关系. 并不会提升检测的效果.
- 文章没有考虑人与人之间的关系, 物与物之间的关系. 如人与人可能是分离的, 不同的物体属于同一个人作用范围.
















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











