






Visible-Infrared(可见红外) Person Re-Identification(行人重识别) via Semantic Alignment(语义对齐) and Affinity Inference(亲和度推断)
- Semantic Alignment(语义对齐):语义对齐涉及诸如词嵌入、语义相似度度量和本体映射等技术,以弥合不同信息表示之间的差距。
- Affinity Inference(亲和度推断):亲和性推断指的是根据实体的属性、行为或其他相关因素推断或推断实体之间关系或连接的可能性或强度的过程。
- Part-based(基于部件):通常指的是一种检测目标的方法,该方法将目标视为由多个部件或子部分组成。这种方法认为目标的不同部件具有特定的特征或形态,并利用这些部件的信息来提高目标检测的准确性和鲁棒性。
目录
3.1 Formulation and Overview(公式和概述)
3.2 Semantic-Aligned Feature Learning (SAFL)(语义对齐特征学习)
3.3 Affinity Inference Module(AIM)(亲和推理模块)
3.4 Training and Inference(训练和推理)
4.2 Comparison with State-of-the-art Methods
一、摘要
研究背景:可见光-红外行人重识别(VI-ReID)侧重于对不同模态摄像机拍摄的相同身份的行人图像进行匹配。(不同模态下,匹配相同身份的行人)
研究问题:
- 1. 基于部件(part-based)的方法从特征图中提取细粒度特征,取得了很大的成功。但是,现有的基于部件(part-based)的特征提取方法大多采用水平分割的方式来获取部件(part)特征,由于行人运动不规律而导致部件(part)特征不对齐。
- 2. 此外,目前大多数方法使用输出特征的欧氏或余弦距离来度量相似性,没有考虑行人之间的关系。不对齐的部件(part)特征和朴素的推理方法都限制了现有工作的性能。
主要工作:本文提出一种语义对齐和亲和度推理框架(SAAI),旨在将潜在语义部分特征与可学习的原型相对齐,并利用亲和度信息改进推理(本文核心)。首先提出语义对齐特征学习,利用像素化特征和可学习原型之间的相似性来聚合潜在语义部件(part)特征。然后,设计亲和度推理模块来优化基于行人关系的推理。
研究成果:在SYSU-MM01和RegDB数据集上的实验结果表明,提出的SAAI框架具有良好的性能。
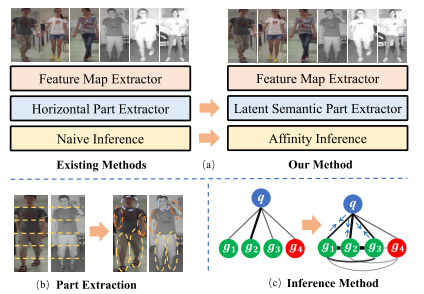
传统方法(左),本文方法(右)
二、引言
结构:
可见光-红外行人再识别任务简介 —> 结合示例图像阐述任务难点(行人由于运动而不位于固定位置;语义不对齐等) —> 结合示图指出现有方法缺陷(改进动机) —> 引出本文主要工作:
- 1. 提出了一个语义对齐和亲和力推理框架(SAAI),对齐潜在的语义部分功能,更好地利用辅助亲和力信息。
- 2. SAAI框架由语义对齐特征学习(SAFL)和 亲和推理模块(AIM)组成。
- 3. SAFL具体流程。
- 4. 提出了AIM计算距离的附加信息从亲和矩阵 + 具体流程。
—> 贡献
三、方法
3.1 Formulation and Overview(公式和概述)
1)问题公式化(目的):使用 和
,分别用
图像表示 查询集 ,用
图像表示 图库集 。查询集和图库集中的图像属于不同的模态。
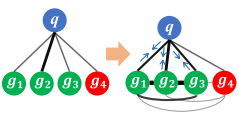
VI-ReID(可见光-红外行人再识别)旨在建立查询q和图库图像g之间的对应关系。
2)概述
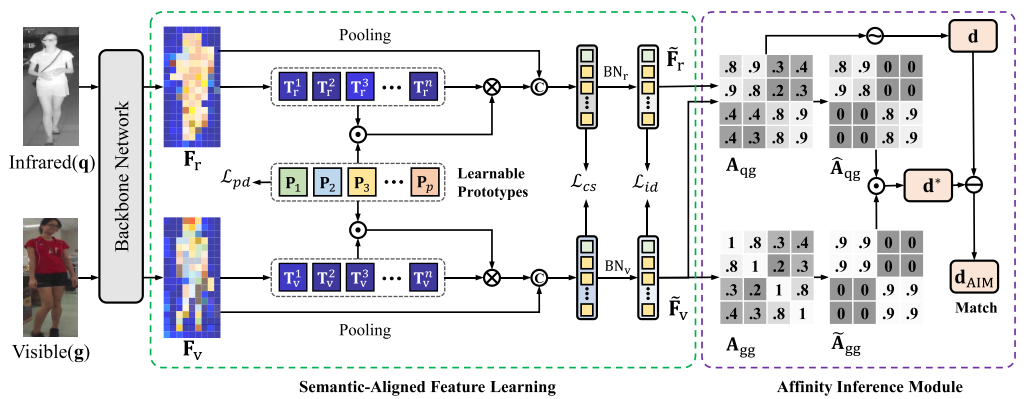
SAAI总体框架如下图所示,主要包括 semantic-aligned feature learning (SAFL) 和 affinity inference module (AIM) 两个模块。
模块设计理念:
(1)语义对齐特征学习(SAFL):通过 像素特征 与 可学习原型 之间的 相似性 来提取潜在语义部分特征。直觉上,有意义的部件(part)应该由具有相似内容的特征组成,形成部件(part)的一致性。
(2)亲和度推理模块(AIM):利用行人关系优化推理。当查询图像q与图库图像g具有较高的相似性时,可以减小q与其他类似图像g之间的距离。我们的方法使用亲和矩阵模拟上述过程来修正距离计算。
Q:可学习原型是什么?是一组可学习的随机参数吗?
3.2 Semantic-Aligned Feature Learning (SAFL)(语义对齐特征学习)
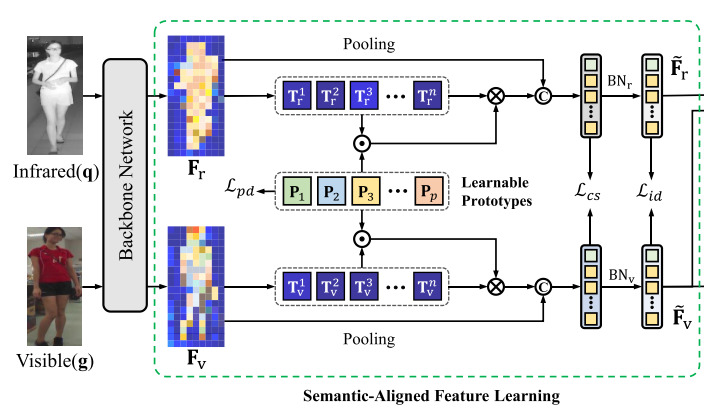
目的:为了缓解行人运动引起的局部特征不对齐问题,本文提出语义对齐特征学习。
方法:具体地说,当从特征图中提取潜在语义部件特征时,应该给与目标部件相似的像素级特征给予更高的权重。(需要为每个部件提供一个参考特征)
(于是)使用可学习原型 作为潜在语义部分特征的参考,其中
表示第
个可学习原型,
表示此类可学习原型的总数。(可学习原型
已学习适当的潜在语义)每个可学习的原型旨在从特征图中聚类出唯一的潜在语义部分特征。(利用 可学习原型
对 目标部件相似的像素级特征 加权,具体做法类似注意力机制)
原理:将两种模态的逐像素特征与共享的可学习原型进行比较,以确定它们对每个潜在语义部分特征的加权贡献。
过程:
(1)获取相似度矩阵 :首先,将特征图
划分为像素级特征
,其中
表示第 i 个像素级特征,
表示像素级特征的数量。根据位置向每个像素特征添加可学习的位置嵌入,以提供空间信息。空间信息可以增强潜在语义部分特征的空间稳定性。随后,该模块计算
与
的相似度矩阵
为:
![]()
其中,⊙ 表示矩阵乘法,σ(·)表示Sigmoid激活函数。设计Sigmoid激活函数以增强数值稳定性。
(2)获取潜在语义部件特征 :以可学习原型
为参考,我们得到的相似性矩阵
来描述
和
之间的亲和力。像素级特征和可学习原型之间的高相似性分数表明像素级特征可能属于潜在语义部分。因此,利用
作为权重来聚合逐像素特征以形成潜在语义部件特征
,如下所示:
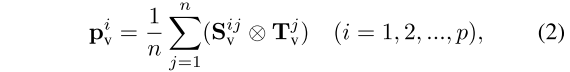
其中,⊗ 表示逐元素相乘, 表示
和
之间的相似度得分。(
和
维度不匹配,原文虽然说这里做 “逐像素相乘” ,但是根据 “源码” 和 后文提到的
维度,这里 ⊗ 应该是矩阵乘法 )
(3)获取增广特征 :潜在语义部件特征pv包含行人的局部信息。只需将
与全局特征
连接起来即可获得增广特征
为:
![]()
其中, 表示特征连接,
表示平均池化,
表示全局特征。
包含局部和全局信息。
(4)获取 和 归一化处理:类似地,可以以相同的方式从特征映射
中构建
。
和
由共享的可学习原型p提取,因此
和
可以实现潜在语义部件级别的对齐。为了缓解模态差距,设计了一个双分支 BNNeck 来分别 归一化
和
。其输出是
和
( 归一化后 )。
代码实现:
本质上 SAFL 就是一种注意力, BNNeck 实际很类似SK模块(SKNet:http://t.csdnimg.cn/vGmRm)。
class SAFL(nn.Module):
def __init__(self, dim = 2048, part_num = 6) -> None:
super().__init__()
self.part_num = part_num
self.part_tokens = nn.Parameter(nn.init.kaiming_normal_(torch.empty(part_num, 2048)))
self.pos_embeding = nn.Parameter(nn.init.kaiming_normal_(torch.empty(18 * 9, dim)))
self.active = nn.Sigmoid()
def forward(self, x):
B, C, H, W = x.shape
x = x.view(B, C, -1).permute(0, 2, 1) # [B, HW, C]
x_pos = x + self.pos_embeding
attn = self.part_tokens @ x_pos.transpose(-1, -2)
attn = self.active(attn)
x = attn @ x / H / W
return x.view(B, -1), attn(5)分类损失 :利用分类损失
来引导模型学习身份信息。
(6)部件多样性损失 :
用来增加潜在的语义部件的多样性。(设计初衷)训练每个原型来提取不同的部件特征,以鼓励可学习的原型关注行人的不同区域。
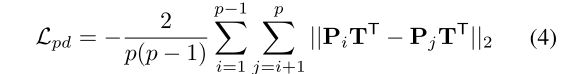
其中, 和
表示第 i 个和第 j 个可学习原型,并且
表示
和
以便于描述。(
与
类似,由
获得)
( 很明显是一个L1范数,
会
与每一个可学习原型的差距,以此增加潜在的语义部件的多样性)
(7)中心分离损失 :
用来训练网络区分不同的行人。
的目标是使具有相同身份的样本彼此靠近,同时将属于不同身份的实例中心分开。为了减少网络过拟合问题并增加特征多样性,只收集样本到其各自中心的范围
。
可以表示为:
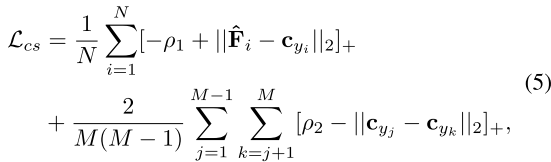
其中,N表示批量大小, 表示第 i 个特征,
表示第 i 个标签,
表示
的中心,M表示中心的数量,
是样本到中心之间的差距,
是中心之间的差距。
3.3 Affinity Inference Module(AIM)(亲和推理模块)
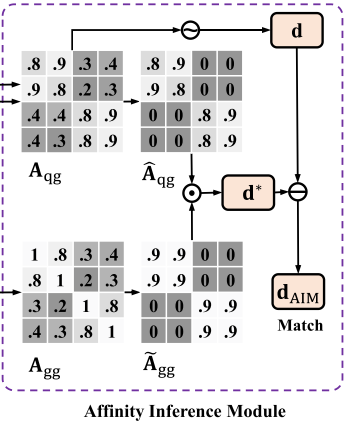
动机:基于欧氏距离或余弦距离的行人图像匹配效果有限。这些方法忽略了亲和度信息,并在推理过程中将图库图像视为不同的实体(图库图像中有相同身份的行人图像)。因此,我们提出了亲和推理模块(AIM),它利用行人的关系来修改距离。
思想:AIM背后的直觉是,可以利用与查询图像具有高亲和力的图库图像来修改距离。AIM算法能够捕捉图库图像之间潜在的相似度信息,并将其纳入距离计算中,优化匹配性能。(分别计算 gallery-gallery 和 query-gallery 之间的亲和度,建立起 q-g-g 的亲和关系,间接缩小查询图像与其他图库图像的距离,提高重识别精度)

过程:
(1)计算亲和矩阵 和
:该框架将查询图像 q 和图库图像 g 分别转换为特征
和
。AIM首先利用
和
之间的 余弦相似度 计算 query-gallery亲和矩阵
。类似地,AIM还可以从所有图库图像对计算 gallery-gallery 亲和矩阵
。(利用 余弦相似度 计算 亲和矩阵 )
(2)删除噪波值: 和
包含了丰富的亲和力信息。然而,在矩阵中存在噪声值。这些噪声值可能会误导我们接下来的距离计算,导致结果不准确。
去掉较小值以删除噪波值:为了解决这个问题,提出了一个有效的噪声抑制策略。这些噪声值在数值上很小。基于此属性,可以通过清除亲和矩阵中的较小值来去除噪声值。为了描述方便,以 为例。首先,确定
的每行中第
个最大值
,并将任何小于
的值设置为0,如下所示:
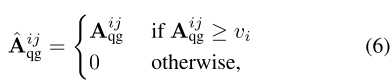
(3)扩大代表性:用最相似的邻居的平均值替换当前值可以提供亲和度信息的更稳定的表示。 包含图库图像之间的亲和力信息,可用于扩展表示。具体地,给定图库图像
,可以找到与
最相似的
个图库图像
。然后,用
个图库图像的平均亲和度得分扩展原始亲和度信息为:
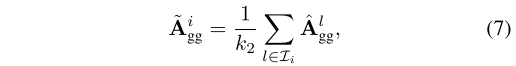
(4)最后的距离计算: 表示查询图像和图库图像之间的余弦相似度。可以用
将余弦相似度转换为基本距离d,如下所示:
![]()
此外,AIM还利用了 和
来辅助距离测量。如果查询
图像类似于图库图像
,则该模块减小
与类似于
的图库图像之间的距离。减小的距离取决于这些图像与
之间的亲和力。修正的距离
可以计算为:
![]()
( 和
点积计算出一个修正的距离
,实际上意图是计算出 q->g->g 之间的距离)
最后,从d中减去d来修正距离。最终距离可以计算为:
![]()
(这样就缩短了查询图像q与其他本质上亲和的图库图像的距离。g-g亲和,q-g亲和,减去这个距离,拉近q与相似图库图像的距离)
代码实现:
import torch
def getNewFeature(x, y, k1, k2, mean: bool = False):
dismat = x @ y.T
val, rank = dismat.topk(k1)
dismat[dismat < val[:, -1].unsqueeze(1)] = 0 # 删除噪波值
if mean:
dismat = dismat[rank[:, :k2]].mean(dim=1) # 扩大代表性
return dismat
def AIM(qf: torch.tensor, gf: torch.tensor, k1, k2):
qf = qf.to('cuda')
gf = gf.to('cuda')
qf = torch.nn.functional.normalize(qf)
gf = torch.nn.functional.normalize(gf)
new_qf = torch.concat([getNewFeature(qf, gf, k1, k2)], dim=1)
new_gf = torch.concat([getNewFeature(gf, gf, k1, k2, mean=True)], dim=1)
new_qf = torch.nn.functional.normalize(new_qf)
new_gf = torch.nn.functional.normalize(new_gf)
# additional use of relationships between query sets
# new_qf = torch.concat([getNewFeature(qf, qf, k1, k2, mean=True), getNewFeature(qf, gf, k1, k2)], dim=1)
# new_gf = torch.concat([getNewFeature(gf, qf, k1, k2), getNewFeature(gf, gf, k1, k2, mean=True)], dim=1)
return (-new_qf @ new_gf.T - qf @ gf.T).to('cpu') # 最后的距离计算3.4 Training and Inference(训练和推理)
损失函数:
![]()
其中 是平衡损失项的超参数。
四、实验
4.1 Datasets and Settings
数据集描述(数据集容量 + 采集对象 + 采集设备配置 + 捕获方式 + 数据模态):
SYSU-MM01 是 VI-ReID 领域中开创性的大规模基准数据集。总共有287628张可见光图像和15792张红外图像。它记录了491个行人,有四个可见光摄像头和两个红外摄像头。捕获环境包括室内和室外设置。根据不同的配置,有多种评估模式。根据是否包括户外拍摄的图像,这些模式被分类为所有搜索和室内搜索设置。此外,根据图库中图像数量的不同,模式可以进一步细分为单镜头和多镜头场景。
评估指标:累积匹配特征(CMC)和平均精密度(mAP)
实施细节(实验设备 + 数据传入方式/随机种子 + 数据增强 + 优化策略 + 训练轮次):SAAI框架使用PyTorch框架实现,并在单个RTX 3090 GPU上执行。采用ResNet-50 作为主干。对于每一批,随机抽取16个身份,每个身份包含8个图像。输入图像最初被调整为288×144的一致尺寸。然后,应用一系列增强技术,包括随机裁剪,随机擦除,随机水平翻转和随机灰度。Adam使用线性预热策略对网络进行了优化。初始学习率设置为0.0003.5,在80和120个epoch时分别降低0.1和0.01。训练过程总共跨越160个轮次。
4.2 Comparison with State-of-the-art Methods
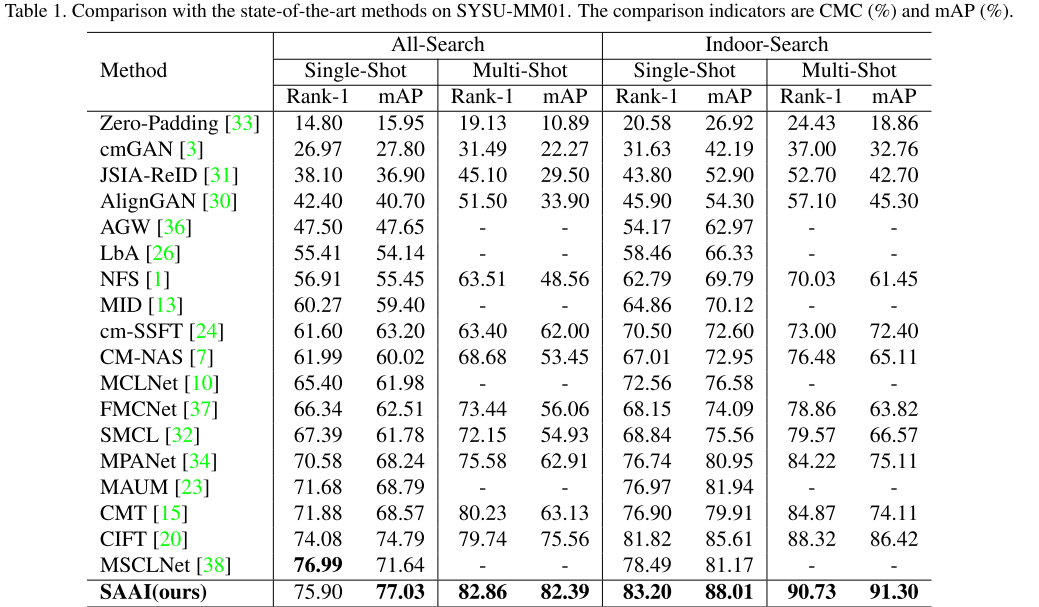
在SYSU-MM01上的对比实验(结果 + 优于sora比例): 在所有测试设置下,本文模型在mAP方面都优于SOTA。本文模型在mAP中达到了77.03%,在全搜索和单次设置下,比最好的SOTA(CIFT)提高了2.24%。此外,我们的模型也取得了相当大的成绩,在Rank-1。在室内搜索和单镜头设置下,本文模型在Rank-1中达到83.20%,比最好的SOTA(CIFT)高出1.38%。
4.3. Ablation Study
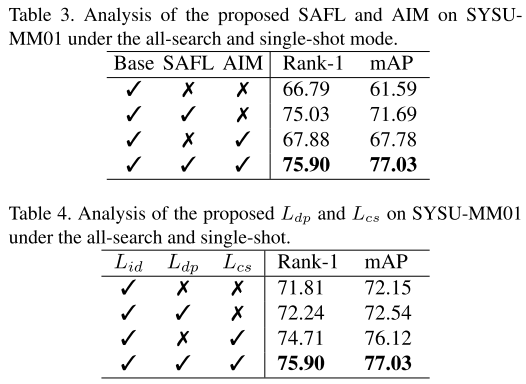
1)针对模块的消融实验:表3显示了SAFL和AIM实现的性能改进。SAFL使Rank-1和mAP分别提高了8.24%和10.10%。AIM使Rank-1和mAP分别提高1.09%和6.19%。当结合起来时,SAFL和AIM进一步提高了整体性能,证明了SAFL和AIM的有效性。(基线 + 模块)
2)针对损失函数的消融实验:表4说明了Ldp和Lcs的影响。Ldp导致 Rank-1 提高 0.43%,mAP提高 0.39%。另一方面,Lcs导致Rank-1提升了2.90%,mAP提升了3.97%。此外,Ldp和Lcs的组合使用进一步增强了整体性能,证明了这些损失的有效性。
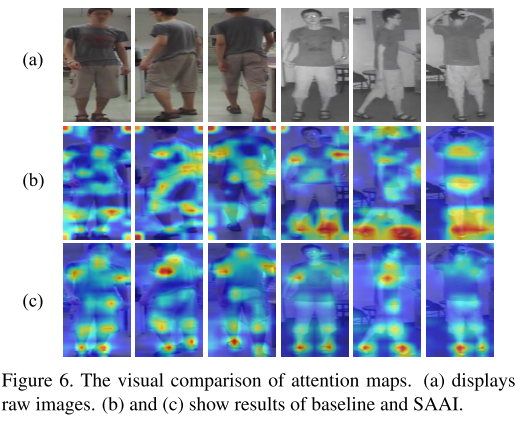
注意力热图分析:可视化基线和SAAI的注意力图。如图所示,SAAI比基线更准确地关注主体部分。结果表明,SAFL的能力,有效地提取潜在的语义部分,从而提高了特征定位和对齐。
五、结论
本文提出了语义对齐和亲和推理框架(SAAI)的可见红外人的ReID。
SAFL细节介绍(原理解释 + 作用):本文首先设计了一个语义对齐的特征学习过程,通过考虑像素级特征和可学习原型之间的相似性来对齐潜在的语义部分。该方法有效地降低了行人运动的影响,增强了特征表示的独特性。
AIM模块细节介绍(原理解释):此外,我们提出了一个亲和力推理模块,利用行人的关系来修改距离计算。
实验成果:通过在SYSU-MM 01和RegDB数据集上进行的广泛实验,我们的框架对VI-ReID表现出了显著的功效。


















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











