










 AnomMAN模型提出了一种无监督方法来检测多视图属性网络中的异常。该模型利用注意机制融合不同视图的特征,并通过图自动编码器克服图卷积在异常检测中的局限。实验在DBLP和IMDB数据集上验证了AnomMAN的有效性,相比于其他先进算法,AnomMAN表现更优。
AnomMAN模型提出了一种无监督方法来检测多视图属性网络中的异常。该模型利用注意机制融合不同视图的特征,并通过图自动编码器克服图卷积在异常检测中的局限。实验在DBLP和IMDB数据集上验证了AnomMAN的有效性,相比于其他先进算法,AnomMAN表现更优。
论文链接:AnomMAN: Detect Anomaly on Multi-view Attributed Networks。
一、前言
1.1 以往图异常检测算法的问题
大多数图异常检测算法仅仅考虑单种类型节点的交互活动来检测属性网络上的异常,但未能考虑多视图属性网络中的丰富交互活动。 事实上,在多视图属性网络中统一考虑所有不同类型的交互并检测异常实例仍然是一项具有挑战性的任务。
1.2 AnomMAN模型的意义和贡献
AnomMAN用于检测多视图属性网络上的异常。 为了同时考虑节点属性和节点之间所有的交互活动,作者使用注意机制来定义网络中所有视图的重要性。 此外,由于其低通特性,图卷积操作不能简单地应用于异常检测任务。 因此,AnomMAN 使用图自动编码器模块来克服这个缺点并将其转化为其自身的优势。
贡献如下:
- 提出了一个无监督模型,它可以从所有视图中学习数据的不同表示,并同时考虑节点属性和节点的所有交互活动。 据论文描述,这是第一个在多视图属性网络上检测异常模型。
- AnomMAN 可以在没有真实信息的情况下检测异常,以实现标签数量的不平衡。 作者利用 Graph Convolution 操作在异常检测任务中作为低通滤波器的缺点,使用更简单但功能更强大的低通滤波器来检测异常。
- 作者在具有结构和属性异常的真实数据集上评估了模型。 实验证明了AnomMAN在多视图属性网络上的异常检测任务中的优越性。
二、AnomMAN模型
2.1 模型结构
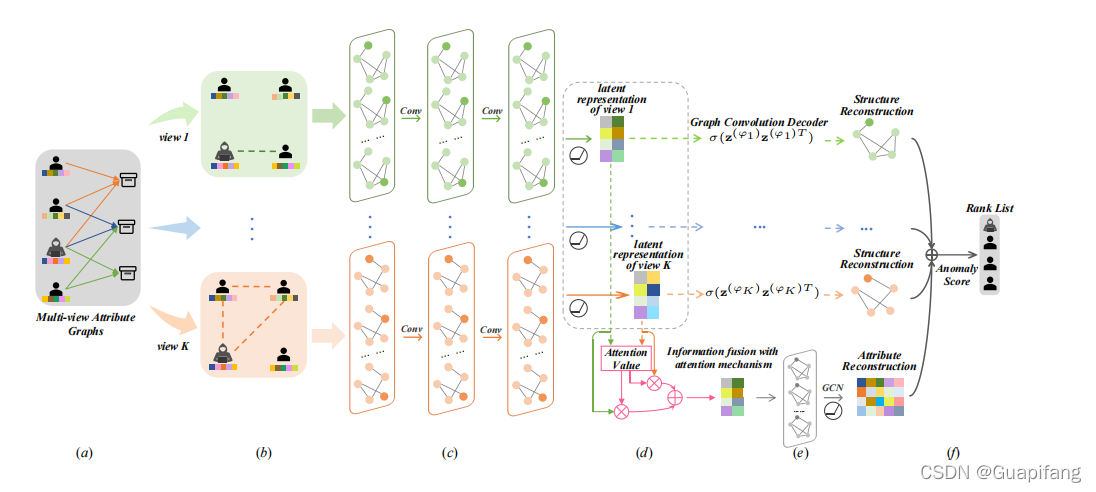
AnomMAN模型框架:
a. 原始输入由多视图属性子图组成。
b. 根据不同的视图提取子图。
c. 多视图属性网络编码器层将结构和属性嵌入到相同的子空间中。
d. 将不同视图的潜在的特征表达与注意力机制融合在一起。
e. 重构节点的结构和特征属性。
f. 根据重建损失得到异常分数。
2.2 模型的数学公式
2.2.1 子图的定义
不同的视角得到的子图:如果用户A和用户B做了同样的活动,就得到一个关于A和B的活动子图(比如用户A评论了商品,用户B也评论了商品,于是得到一个评论视角的子图,活动行为为评论)。存在K种活动类型,于是会得到K种子图。
子图的数学定义如下:
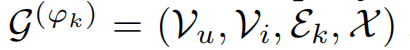
第一个参数V(u)表示用户user类型节点集合,第二个参数V(i)表示商品item类型节点集合,第三个参数表示活动类型,第4个参数表示用户节点特征信息。这里引申出一个关系矩阵A,A(i,j)=1表示用户i和用户j对同一个物品做了第k种类型的活动行为、否则A(i,j)=0。不同的视角下有不同的关系矩阵A。
然后我们的任务是去检测存在异常的节点。
2.2.2 Multi-view Attributed Networks Encoder(多视图属性网络编码器)
传统的深度自编码器不适合处理具有拓扑结构的数据,所以自然用了GCN作为编码器,不同视图的子网络图中有不同的GCN编码器。
所以针对每个子图的信息编码函数如下:
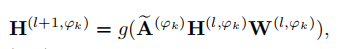
A是关系矩阵,W是参数矩阵,g是非线性的激活函数,H是节点的特征向量矩阵,l表示第l层编码,当l=0时,H等于节点的原始特征向量矩阵X。然后还要对关系矩阵进行标准化,然后得到下面的公式,好吧,这个就是GCN的数学表达式,看不懂的点击这里DGL框架搭建GCN图卷积神经网络模型。
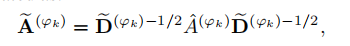
每个子图经过GCN编码后得到输出如下:
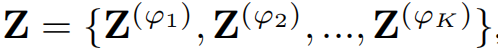
每个Z都包含了对应属性图下n个用户节点的表达向量。
但是这里有一个问题,作者表示,GCN作为一个作为低通滤波器,容易过滤掉很多异常信息,这就会使得异常检测很困难,因此作者将多层的GCN进行简化得到了如下最终的表达式:
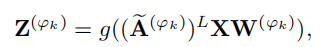
2.2.3 Information Fusion on Multi-view Attributed Networks(多视图属性网络的信息融合)
到这里我们已经得到了每个视图下的节点特征信息的编码表达,通常,多视图属性网络中的每个节点都包含各种语义信息,特定视图的节点表示只能反映特定视图的节点信息,为了学习更全面的表示,作者将所有视图的编码表征融合在一起。作者采用了注意力机制去融合所有视图下的特征表达。公式如下:
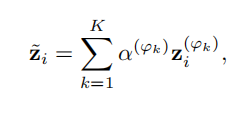
 如果不了解注意力机制的同学可以先详细了解一下,剩下的就是注意力权重的计算:
如果不了解注意力机制的同学可以先详细了解一下,剩下的就是注意力权重的计算:
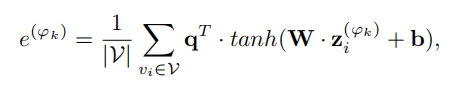
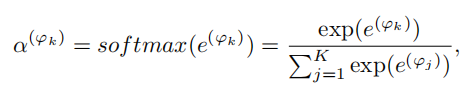
最终每个用户节点的特征表达如下:
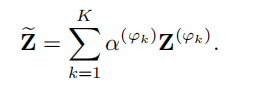
2.2.4 Attribute and Structure Reconstruction Decoder on Multi-view Attributed Networks(多视图属性网络上的属性和结构重构解码器)
在得到了最终的节点特征表达之后,我们需要在每个视图中重建节点的属性和网络的结构,为了后面计算属性误差和重构误差。
2.2.4.1 网络结构重构解码器
针对每个视图中的网络结构重构,简单来说就是重构用户节点之间的邻接矩阵A,也可以理解为去得到两个节点之间存在联系的可能性。这里用sigmoid函数把输出的权重映射到0-1之间,于是在第k种视图中,节点i和节点j之间存在联系的可能性计算公式如下:
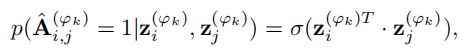
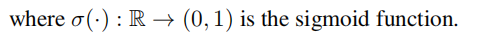
因此,重构后的关系矩阵如下:
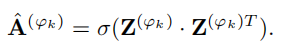
然后继续得到重构误差如下:
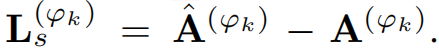
通过第一范式得到最终的重构误差表达式:
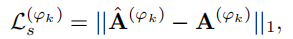
2.2.4.2 网络属性重构解码器
上述的网络结构重构需要针对每个视图单独计算,这里的节点属性特征重构针对整个图的节点计算,不需要再单独每个视图计算,因此重构的节点属性特征表达如下:
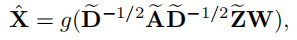
然后得到节点重构的误差如下:
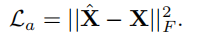
2.2.4.3 异常检测
最终我们结合结构的重构误差和节点属性的重构误差如下:
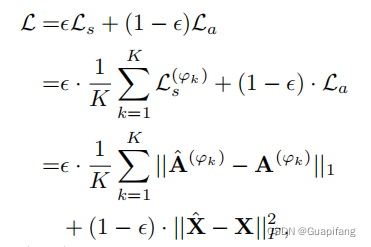
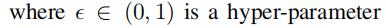
然后针对每个节点,得到的异常分数为:


2.3 模型的训练目标
把下面这个总的损失函数尽可能最小化,然后需要手动调整超参数:
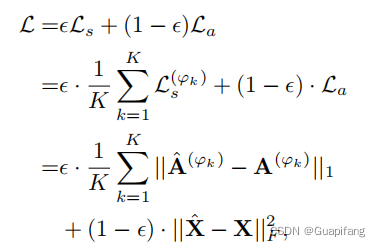
三、实验的结果
3.1 数据集
这里作者采用了两个真实的数据集去评估模型:
- DBLP:这是一个来自 DBLP 数据集的学术合作多视图属性网络。 多视图属性网络中有 3025 个节点,每个节点代表一个特定的作者。 在该数据集中,视图数设置为 K = 3。该数据集中定义的网络中的 3 个视图包括:共同作者(两位作者为同一篇论文合作)、共同会议(两位作者在 同一会议)和共同任期(两位作者在同一学期发表论文)。 作者的属性对应于由关键字表示的词袋的元素。
- IMDB:这是来自 IMDB 数据集的电影关系多视图属性网络。 多视图属性网络中有 4780 个节点,每个节点代表一个特定的电影。 在这个数据集中,视图的数量设置为 K = 3。这个数据集中定义的 3 个视图包括:co-actor(两部电影由同一演员表演)、codirector(两部电影由同一导演执导)和 同年(同一年上映两部电影)。 电影属性是表示情节的词袋的元素。
3.2 对比的算法模型
作者这里对比了几种异常检测算法模型,如下:
- LOF:通过上下文检测异常并且只考虑节点属性的模型。
- ANOMALOUS:基于残差分析和 CUR 分解去检测属性图上的异常。
- Radar:通过分析节点属性的残差来检测异常。
- Dominant:是在属性网络上检测异常的算法,它没有考虑网络的不同视角。
其中Dominant 和 Radar 是之前两种最先进的算法,用于检测属性网络上的异常。
3.3 实验的设置
- 输出的特征表达z的维度为30。
- 优化器为Adam。
- 学习率为0.001。
- 超参数L设置为3,另外一个超参数设置为0.5。
- 激活函数为ReLU。
至于其他基线模型,就针对这些模型的原始论文进行了模型设置。

3.4 实验的结果
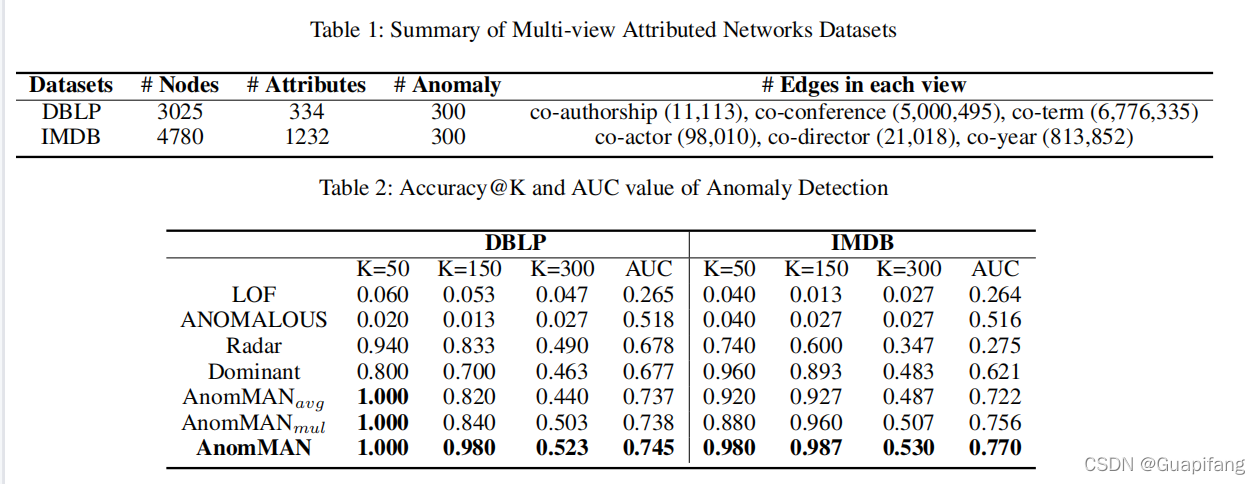
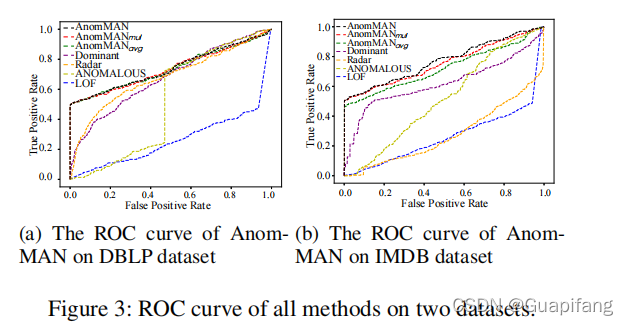
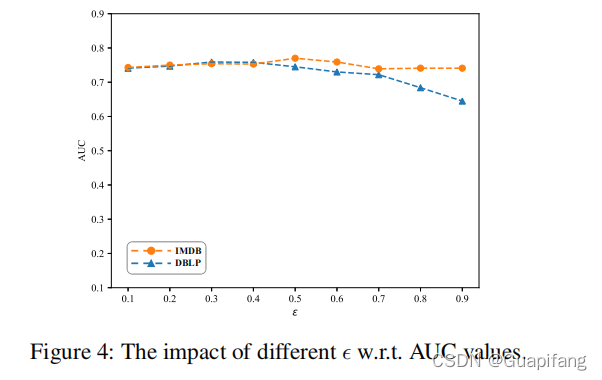
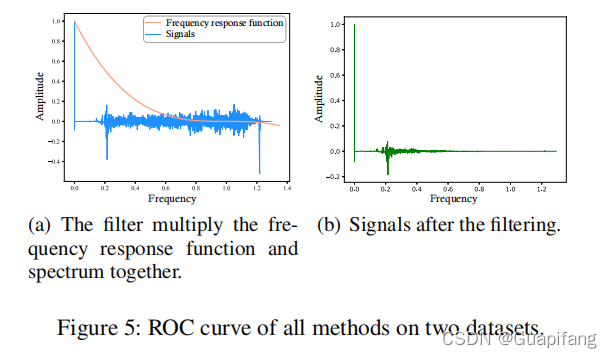
四、结论
在本文中,作者提出了 AnomMAN(Detect Anomaly on Multi-view Attributed Networks)模型,旨在检测多视图属性网络上的异常。 AnomMAN 解决了当前算法在多视图属性网络异常检测中的局限性。 AnomMAN 使用基于图自动编码器的模型来克服图卷积作为低通滤波器在异常检测任务中的缺点。 此外,它使用更强的低通滤波器作为 AnomMAN 的多视图属性网络编码器,并在此任务中表现出更好的性能。 在两个真实世界数据集上的实验结果表明,AnomMAN 优于最先进的模型和该论文模型的两个变体。

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









