







前言
XGBoost是集成学习算法的一种,是基于CART决策树(分类与回归问题的基学习器都使用回归树)的提升算法,相较于GDBT算法它做了很多改进,包括损失函数、正则化等。在性能上也是优于GDBT,尤其是在各大比赛中表现亮眼。
目标函数
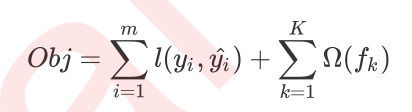
第一项是传统的损失函数,第二项是正则项,防止过拟合。m是训练集数据样本个数。K是基学习器也就是回归树的个数。
求解目标函数
求解目标函数是要求得在第t次迭代中最优的树f(t),因为我们无法用梯度下降或者其他方式来求解,所以我们需要将目标函数转化成简单的,与树结构直接相关的写法,以此来建立树的结构与模型效果之间的直接联系。
首先对于迭代t次后模型的预测结果为:
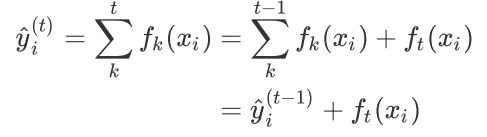
它是由前t-1次迭代后得到的模型的预测结果(第一项),在第t次迭代时已经是常数,所以重点是第二项也就是第t次迭代需要学习的一棵树。
然后对目标函数第一项转换得到:
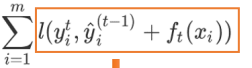
然后将它看作一个函数:
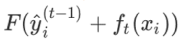
括号里的第一项是常数,所以不考虑。对这个函数进行二阶泰勒展开:

得到:
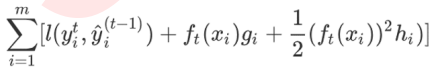
第一项是常数,舍去。
对于第二项,正则化项转化得到
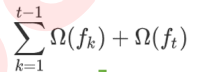
第一项是已知常数,舍去。
最终目标函数被转化为:
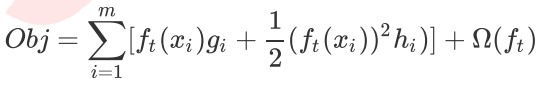
这样目标函数中的g,h只与传统损失函数相关,核心部分是我们需要训练学习的数f(t)。
正则项
对于决策树而言,每个被放入模型的任意样本i最终都会落到一个叶子节点上。对于回归树,通常来说每个叶子节点上的预测值是这个叶子节点上所有样本的标签的均值。但在XGBoost中并不采用这种方式。
对于XGB来说,每个叶子节点上会有一个预测分数(prediction score),也被称为叶子权重。这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取值,用w或 f k ( x i ) f_{k}\left(x_{i}\right) fk(xi)来表示。
当有多棵树的时候,集成模型的回归结果就是所有树的预测分数之和,假设这个集成模型中总共有K棵决策树,则整个模型在这个样本i上给出的预测结果为:
y ^ i ( k ) = ∑ k K f k ( x i ) \hat{y}_{i}^{(k)}=\sum_{k}^{K} f_{k}\left(x_{i}\right) y^i(k)=∑kKfk(xi)
对每一棵树,它都有自己独特的结构,这个结构即是指叶子节点的数量,树的深度,叶子的位置等等所形成的一个可以定义唯一模型的树结构。在这个结构中,我们使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2330
2330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









