









1 介绍
年份:2022
期刊: European conference on computer vision
引用量:251
代码:https://github.com/G-U-N/ECCV22-FOSTER
Wang F Y, Zhou D W, Ye H J, et al. Foster: Feature boosting and compression for class-incremental learning[C]//European conference on computer vision. Cham: Springer Nature Switzerland, 2022: 398-414.
本文提出了一种名为FOSTER的新颖两阶段学习范式,用于类别增量学习,该范式通过动态扩展新模块来适应新类别,并通过网络结构蒸馏策略去除冗余参数和特征维度,以维持单一的主干模型。
2 创新点
- 两阶段学习范式:提出了一个名为FOSTER的新型两阶段学习范式,用于类别增量学习,包括特征增强(boosting)和特征压缩(compression)两个阶段。
- 动态模块扩展:在特征增强阶段,动态扩展新的模块来适应新类别,通过拟合目标模型和原始模型输出之间的残差来增强模型对新类别的识别能力。
- 有效的知识蒸馏策略:在特征压缩阶段,通过一种有效的知识蒸馏策略去除冗余参数和不一致的特征维度,以维持单一的主干模型,减少存储和计算开销。
- 对类别不平衡的调整:引入了Logits Alignment策略来减轻类别不平衡造成的分类偏差,通过调整老类别和新类别的logits比例来平衡对老类别和新类别的学习。
- 特征增强策略:提出了Feature Enhancement策略,通过初始化一个新的线性分类器并使用知识蒸馏,鼓励新模块学习老类别,增强模型对老类别的表示能力。
- 平衡蒸馏策略:在特征压缩阶段,提出了Balanced Distillation策略,考虑类别先验并调整不同类别的蒸馏信息权重,以适应类别不平衡的训练数据集。
- 实验验证:在CIFAR-100和ImageNet-100/1000等不同设置下验证了FOSTER方法的有效性,并在多个基准测试中取得了最先进的性能。
3 相关研究
- 知识蒸馏(Knowledge Distillation):
- 目标是将教师模型的"暗知识"转移到学生模型,通过鼓励学生模型的输出接近教师模型的输出。
- Hinton, G., Vinyals, O., Dean, J., et al.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 2(7) (2015)
- rehearsal(复演策略):
- 使模型能够部分访问旧数据,通过存储以前任务的示例进行复演。
- Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: icarl: Incremental classifier and representation learning. In: CVPR, pp. 2001–2010 (2017)
- Dynamic Architectures(动态架构):
- 创建新模块来动态处理不断增长的训练分布。
- Douillard, A., Ram´e, A., Couairon, G., Cord, M.: Dytox: Transformers for continual learning with dynamic token expansion. arXiv preprint arXiv:2111.11326 (2021)
- Boosting(提升算法):
- 一类将弱学习器转换为强学习器的机器学习算法。
- Zhou, Z.H.: Ensemble Methods: Foundations and Algorithms. CRC Press (2012)
- Class-Incremental Learning Setup(类别增量学习设置):
- 描述了类别增量学习的基本过程,其中模型在每个阶段接收一批新的训练数据,并要求在所有已见过的类别上表现良好。
- French, R.M.: Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 3(4), 128–135 (1999)
4 算法
4.1 算法原理
- 特征增强(Feature Boosting)阶段:
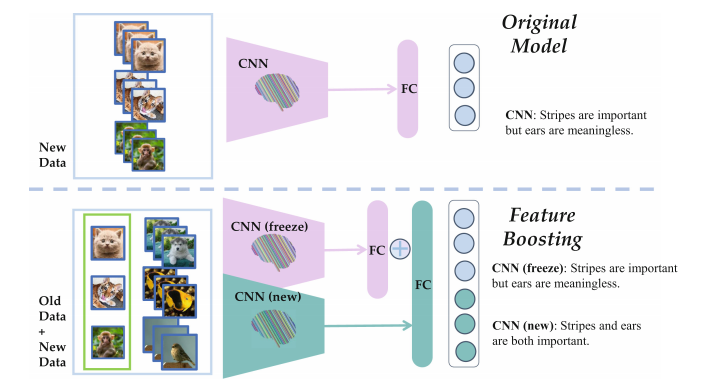
- 动态模块扩展:在每一轮新类别的学习中,算法会动态扩展一个新的模块来适应新类别的数据。这个新模块专门用来拟合目标模型和原始模型输出之间的残差,即新类别数据的预测误差。
- 知识蒸馏:为了维持对旧类别的识别能力,算法利用知识蒸馏技术,通过旧模型的输出来指导新模块的学习,确保新模块在处理旧类别时不会破坏已有的知识。
- 对类别不平衡的调整(Logits Alignment):由于新旧类别的数据量可能存在不平衡,算法通过调整新旧类别在模型输出(logits)上的权重比例,来减轻这种不平衡对模型学习的影响。
- 特征增强策略:为了进一步促进新模块对旧类别的学习,算法引入了一个额外的线性分类器,要求新模块的特征表示能够正确分类所有已见过的类别。
- 特征压缩(Feature Compression)阶段:
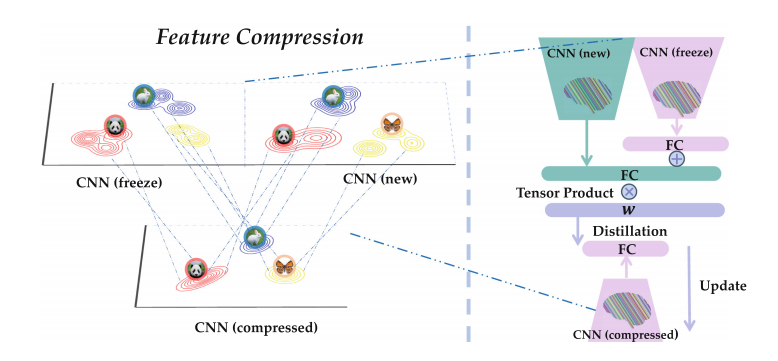
- 参数和特征维度的精简:在特征增强阶段,模型可能会增加大量的参数和特征维度。为了维持单一的主干模型并减少存储与计算开销,算法通过知识蒸馏策略来压缩模型,移除冗余的参数和不一致的特征维度。
- 平衡蒸馏:在执行知识蒸馏时,算法考虑了类别不平衡的问题,通过为不同类别的蒸馏信息分配不同的权重,来进一步优化模型的性能。
4.4 算法步骤
1. 特征增强(Feature Boosting)阶段
步骤1:初始化模型
- 在初始阶段,使用原始模型 F t − 1 F_{t-1} Ft−1对当前任务的数据进行训练。
步骤2:动态扩展新模块
- 当新类别的数据到来时,冻结旧模型 F t − 1 F_{t-1} Ft−1的参数,并扩展一个新的特征提取器 ϕ t \phi_t ϕt 和一个新的全连接层 W t W_t Wt来处理新旧类别。
步骤3:拟合残差
- 通过最小化新旧模型输出之间的残差来训练新模块,即优化目标是使新模型 F t F_t Ft的输出接近于 F t − 1 F_{t-1} Ft−1的输出与目标标签之间的差异。
步骤4:知识蒸馏
- 使用旧模型 F t − 1 F_{t-1} Ft−1的输出作为软目标,通过知识蒸馏来指导新模块的学习,以保留对旧类别的知识。
步骤5:对类别不平衡的调整(Logits Alignment)
- 通过调整新旧类别在模型输出(logits)上的权重比例,来减轻类别不平衡的影响。
步骤6:特征增强策略
- 通过额外的线性分类器和知识蒸馏,进一步促使新模块学习旧类别的特征表示。
2. 特征压缩(Feature Compression)阶段
步骤7:压缩模型
- 在特征增强阶段后,模型可能会变得过于庞大。通过知识蒸馏策略,将新旧模块的特征表示压缩到一个单一的主干模型中,以减少参数数量和计算开销。
步骤8:平衡蒸馏
- 在执行知识蒸馏时,考虑类别不平衡的问题,通过为不同类别的蒸馏信息分配不同的权重,进一步优化模型的性能。
步骤9:模型微调
- 在压缩过程中,可能需要对模型进行微调,以确保在减少参数的同时,模型性能不会显著下降。
3. 迭代学习
步骤10:重复上述过程
- 对于每一个新的类别增量学习任务,重复上述特征增强和压缩的过程,不断扩展和压缩模型,以适应新的数据流。
5 实验分析
(1)数据集
实验在CIFAR-100和ImageNet-100/1000这两个广泛使用的类别增量学习基准数据集上进行。
使用了两种协议:CIFAR-100/ImageNet-100的B0(基础0)和B50(基础50),以及ImageNet-1000的100类每步的设置。
(2)实现细节:
使用Pytorch和PyCIL框架实现FOSTER算法。
对于ImageNet,使用标准的ResNet-18作为特征提取器;对于CIFAR-100,使用修改版的ResNet32。
实验中使用了SGD优化器,余弦退火调度器调整学习率,并采用了数据增强技术。
(3)定量结果:
在CIFAR-100数据集上,FOSTER在所有六种设置中都优于其他最先进的策略,包括长期增量学习和大步增量学习任务。
在ImageNet-100和ImageNet-1000数据集上,FOSTER在大多数设置中也优于其他方法,并且在ImageNet-1000上提高了平均Top-1准确率。
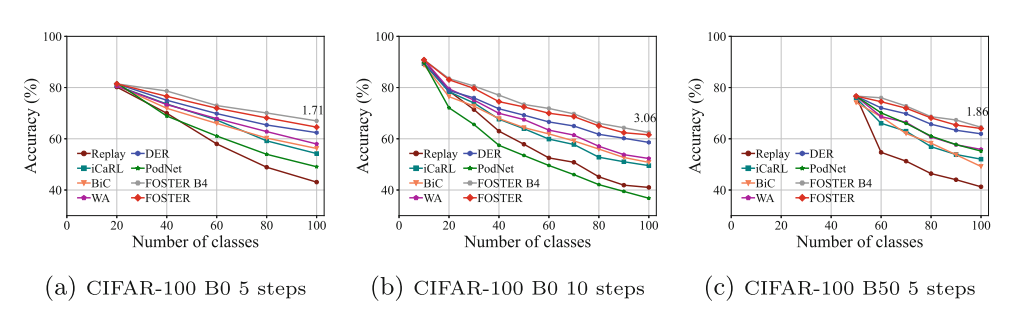
(4)消融研究:
对FOSTER的不同组件进行了消融实验,验证了Logits Alignment、Feature Enhancement和Balanced Knowledge Distillation等组件的有效性。
实验表明,这些组件对于提高模型在新旧类别上的性能至关重要。
(5)超参数敏感性研究:
对超参数β进行了敏感性分析,结果表明FOSTER在不同的β值下表现稳定。
随着每个类别的样本数量增加,模型在最后阶段的准确度逐渐提高,表明FOSTER能够有效利用更多的样本来提升性能。
(6)Grad-CAM可视化:
通过Grad-CAM可视化,展示了特征增强前后模型在关注图像区域上的变化,证明了新模块能够发现并纠正旧模型忽略的重要特征。
6 思考
(1)本文算法在蒸馏的时候,没有考虑参数保护,没有特定的解决灾难性遗忘的方法。并且在第一阶段,采用的是特征提取模块之间,没有利用知识迁移。
(2)采用的是PyCIL的框架,并且复现了多种算法。


















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











