









前言
yolov5更新了v6.2,增加了分类模型,于是一时兴起想试试yolov5的分类性能如何,本次使用yolov5s-cls模型,只训练五次,看看在经典数据集mnist上能达到多少准确率,同时为了公正,只使用官方指令进行训练,在kaggle上进行提交测试准确率。
数据集准备
需要下载的自行进入链接
这里我们直接把test.csv和sample_submission.csv下载下来就行了。
在同目录下新建一个py脚本,输入以下内容,来把里面的每一条数据转成28x28的图片。
#oom.py
import pandas as pd
import imageio
df = pd.read_csv('test.csv')
for index,row in df.iterrows():
print(index) #打印序号方便看进度
pixels = row.values.reshape((28, 28))
imageio.imwrite('E:/image/'+str(index) + '.png', pixels)
自行修改保存目录,我这里是在E盘的image文件夹下,然后用命令行直接运行,如果在像vs这样的ide下运行电脑内存不够有可能溢出哦。
打开目录,可以发现已经转换成了图片。
Yolov5训练
链接
首先肯定是把yolov5最新的源码下载下来,然后再转到release页面,可以看到有很多模型:
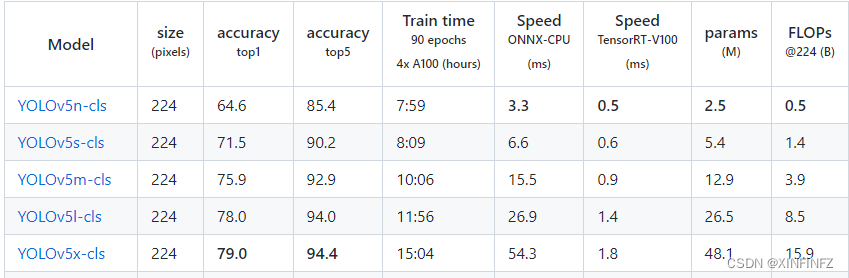
这里如果你电脑显卡比较垃圾,指没有8g内存的老显卡,建议选择最小号的yolov5n-cls模型,因为我的8g显存显卡跑yolov5s-cls还需要把num_workers调成6才能正常运行。
把模型放进源码目录,然后在当前目录启动命令行,输入以下训练:
python classify/train.py --model yolov5s-cls.pt --data mnist --epochs 5 --img 224 --batch 128
然后新版的好像强制要使用wandb这个网页记录训练过程的软件,建议提前注册一个,然后在训练时把wandb给你的api key输入进去激活(我这边不能粘贴,只能手输),正常训练后后可以在wandb查看结果:
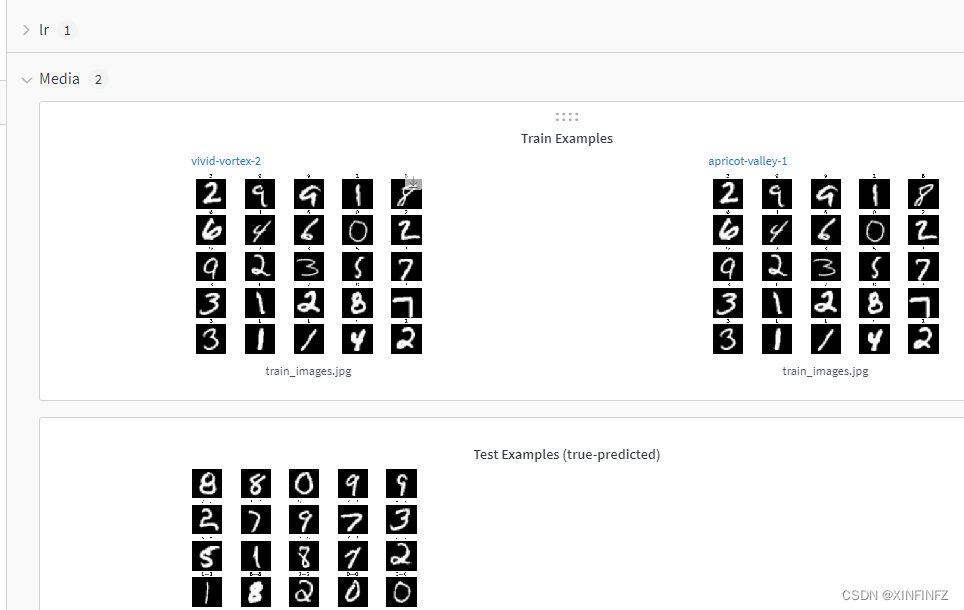
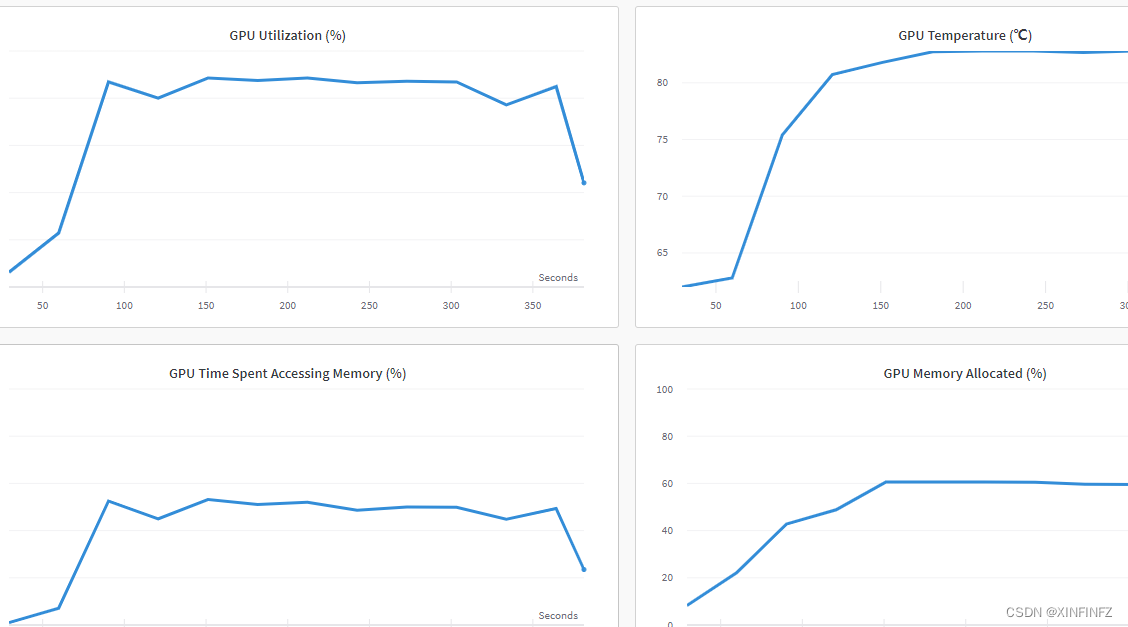
过程,结果查看,中间硬件的使用记录等等都有一个比较详细的过程,特别是硬件这块,能看到cpu和gpu的使用率,温度,占用等等,还是不错的。
可以看到训练四遍准确率就达到0.994了,接下来就是进行预测并保存输出。
Yolov5预测
先到训练目录下把最好的一次模型(best.pt)取出来放到根目录:
然后把先前准备好的数据集图片文件夹整个放进根目录:
把sample_submission.csv放进classify文件夹下方便读取:
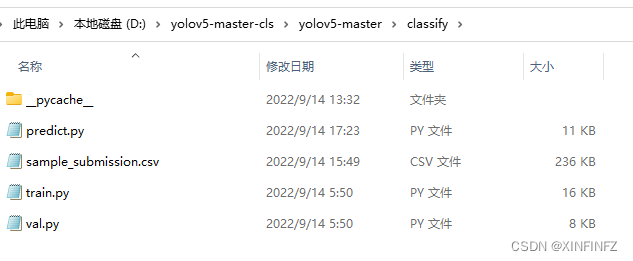
修改predict.py如下,为了看的更清楚,我用vs对原始和修改过的py进行了对比(左边是修改过的):
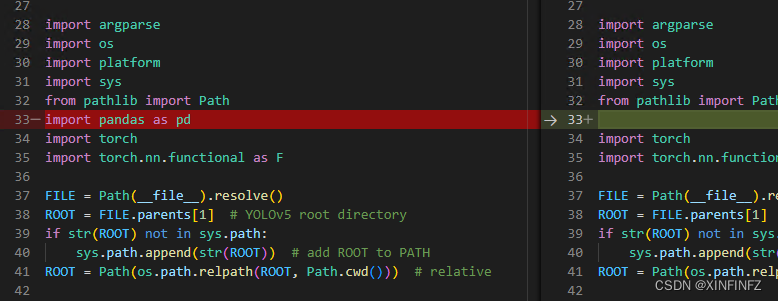
首先添加引用。
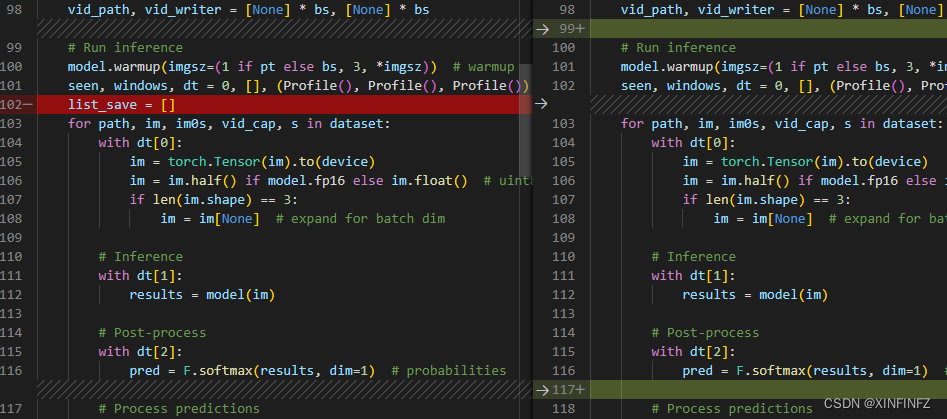
新建一个list_save用来保存预测的结果。
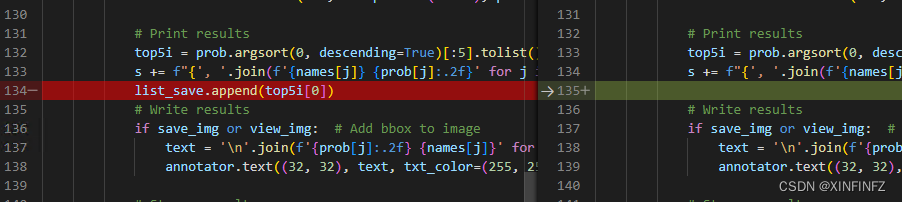
把top5i[0](它官方的输出是输出前五个概率最高的分类,这里我们只取第一个)放进list_save。

读取sample_submission.csv文件里的Label标签并覆盖结果。这里需要注意的是yolov5读取文件路径进行排序时,前面是有字符串的,也就是说不会按照正常数字顺序进行排序,是例如1,10,100这样一位一位去排序,所以顺序是乱的,需要接下来再处理一下。
我们先预测,在命令行输入以下命令,最后得到sub.csv文件。
python classify/predict.py --weights best.pt --source image/ --nosave
–weights指定权重,–source后面直接跟了一个文件夹,下面是所有的图片,–nosave是不保存图片。
然后我们把classify文件夹下生成的sub.csv文件取出来继续读取处理,总体思想是模拟前面有str的排序,然后用正则表达式把数字取出来覆盖sub.csv中的序号列,再整个排序,就得到了正确的结果:
import re
import pandas as pd
unorder_df = pd.read_csv('sub.csv')
list_a=[]
for i in range(0,28000):
list_a.append('image'+str(i)+'.png')
list_b = sorted(list_a) #模拟yolov5文件路径排序
list_c = []
for i in list_b:
x = re.findall("\d+", i) #只匹配数字
x = int(x[0]) #从str转换为数字
list_c.append(x + 1) #加一是因为序号是从1开始的
unorder_df['ImageId']=list_c
df = unorder_df.sort_values(by=['ImageId']) #根据序号列排序
df.to_csv('sub2.csv',index=None)
上传结果
返回kaggle点击submit predictions提交sub2.csv:


可以看到准确率非常高哈,当然本次实验还是有不严谨的地方,那就是没有用kaggle提供的训练集训练,用的是yolov5自动下载的训练集,说不定这个训练集和测试集有重合的地方。















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









