







这次主要做的是基于sift特征匹配然后使用RANSAC全景图像拼接
下面简单地对RANSAC算法进行介绍,参考自:https://blog.csdn.net/robinhjwy/article/details/79174914
一、RANSAC概述
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.首先我们先随机假设一小组局内点为初始值。然后用此局内点拟合一个模型,此模型适应于假设的局内点,所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点,将局内点扩充。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为此模型仅仅是在初始的假设的局内点估计的,后续有扩充后,需要更新。
5.最后,通过估计局内点与模型的错误率来评估模型。
整个这个过程为迭代一次,此过程被重复执行固定的次数,每次产生的模型有两个结局:
1、要么因为局内点太少,还不如上一次的模型,而被舍弃,
2、要么因为比现有的模型更好而被选用。
二、RANSAC示例
一个简单的例子是从一组观测数据中找出合适的2维直线。假设观测数据中包含局内点和局外点,其中局内点近似的被直线所通过,而局外点远离于直线。简单的最小二乘法不能找到适应于局内点的直线,原因是最小二乘法尽量去适应包括局外点在内的所有点。相反,RANSAC能得出一个仅仅用局内点计算出模型,并且概率还足够高。但是,RANSAC并不能保证结果一定正确,为了保证算法有足够高的合理概率,我们必须小心的选择算法的参数。

三、RANSAC原理
OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。

其中(x,y)表示目标图像角点位置,(x’,y’)为场景图像角点位置,s为尺度参数。
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
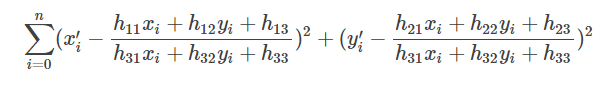
RANSAC算法步骤:
1. 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出变换矩阵H,记为模型M;
2. 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I ;
3. 如果当前内点集 I 元素个数大于最优内点集 I_best , 则更新 I_best = I,同时更新迭代次数k ;
4. 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤;
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的,见上方k的更新;
其中,p为置信度,一般取0.995;w为”内点”的比例 ; m为计算模型所需要的最少样本数=4;
求得单应矩阵后就好办了,把内点留下,内点就是筛选后的好用的点,外点舍弃,外点就有可能是误匹配的点。
四、RANSAC的优点和缺点
RANSAC的优点是它能鲁棒的估计模型参数。例如,它能从包含大量局外点的数据集中估计出高精度的参数。RANSAC的缺点是它计算参数的迭代次数没有上限;如果设置迭代次数的上限,得到的结果可能不是最优的结果,甚至可能得到错误的结果。RANSAC只有一定的概率得到可信的模型,概率与迭代次数成正比。RANSAC的另一个缺点是它要求设置跟问题相关的阀值。
RANSAC只能从特定的数据集中估计出一个模型,如果存在两个(或多个)模型,RANSAC不能找到别的模型。
本次实验主要使用的是sift特征匹配和RANSAC算法,关于sift特征匹配在我的上一篇特征点提取和匹配相关的文章中有对sift特征匹配的详尽介绍此处就不再多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9700
9700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









