









课程5
介绍了一些无约束优化的算法
确定下降方向d(or d_k)是算法的核心,不同算法的收敛效果不同。
首先是基于梯度的算法
回顾上一课程内容,当
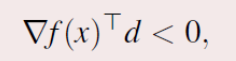
满足时d就是下降方向。
(要清楚如果光 有d是下降方向是不能得出上面图片这个公式的,需要满足f是凸函数)
根据Cauchy-scwarz inequality
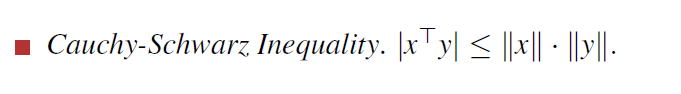
可得d_k≥负梯度,所以下降方向取负梯度方向(证明看5P5)。
怎么理解负梯度就是下降方向?-如果单调上升,梯度为正,负梯度为负->x应减少;如果单调下降,梯度为负,负梯度为正->x应增大。



Lipschitz continuous gradient
lipschitz条件,即利普希茨连续条件(Lipschitz continuity),以德国数学家鲁道夫·利普希茨命名,是一个比通常连续更强的光滑性条件。直觉上,利普希茨连续函数限制了函数改变的速度,符合利普希茨条件的函数的斜率,必小于一个称为利普希茨常数的实数(该常数依函数而定)。可以用中值定理的积分形式来证明,5P9



证明过程为,步长要是固定的
一些等价结果

莱布尼兹连续梯度,步长为1/L,该算法的收敛速度是sublinear的,证明5P15。
梯度算法的收敛速度是O(1/k)。
上述f都只要连续可微
然后就是当f是强凸时,梯度的收敛速度如何
当步长为常数1/L时(还是莱布尼兹连续),收敛速度为linear O(c^k),见5P20
可以使收敛速度更快 5P26,也可以得到stop condition 5P27

第三条体现了我们现在讨论的

最后是加速梯度算法
在梯度算法的基础上,对算法收敛速度进行加速。
有的时候数据选取得不合适,或者进行小批量数据梯度下降时,会出现下降方向并不是最快方向–>出现震荡。所以利用加一个momentum term来消除震荡。

教程里这个方法叫做heavy ball
动量梯度下降法是对梯度下降法的改良版本,通常来说优化效果好于梯度下降法。对梯度下降法不熟悉的可以参考梯度下降法,理解梯度下降法是理解动量梯度下降法的前提,除此之外要搞懂动量梯度下降法需要知道原始方法在实际应用中的不足之处,动量梯度下降法怎样改善了原来方法的不足以及其具体的实现算法。依次从以下几个方面进行说明:
小批量梯度下降法(mini-batch gradient descent)
指数加权平均(exponential weight averages)
动量梯度下降法(gradient descent with momentum)
总结一下他们之间的关系:每次梯度下降都遍历整个数据集会耗费大量计算能力,而mini-batch梯度下降法通过从数据集抽取小批量的数据进行小批度梯度下降解决了这一问题。使用mini-batch会产生下降过程中左右振荡的现象。而动量梯度下降法通过减小振荡对算法进行优化。动量梯度下降法的核心便是对一系列梯度进行指数加权平均
参考:https://blog.csdn.net/qq_36704378/article/details/108020408



如上图所示,黑色量和绿色量沿着上下方向的分量便可以部分抵消(我们想往右边的加号走),就能减小下一步的振荡幅度。
在某些情况下,最速下降法是存在锯齿现象的,这将会导致收敛速度变慢:

造成这种情况是因为在二次函数中,等高线椭球面的形状受 hesse 矩阵的影响,椭球面的长轴与短轴对应矩阵的最小特征值和最大特征值的方向,其大小与特征值的平方根成反比,最大特征值与最小特征值相差越大,椭球面越扁,那么优化路径需要走很大的弯路,计算效率很低。
需要注意的是,最速下降法是每次迭代都需要计算全部样本值的梯度的,而在实际求解过程中,它的收敛速度是比较慢的,是一阶收敛。所以就出现了下面两种方法。

上图漏了
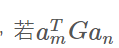
=0
AGD是目前最好的加速梯度方法。
参考:https://zhuanlan.zhihu.com/p/137274399
https://tangxman.github.io/2015/11/18/optimize-gradient/














 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









