






先介绍一下数据集DRIVE(视网膜血管)
数据集结构
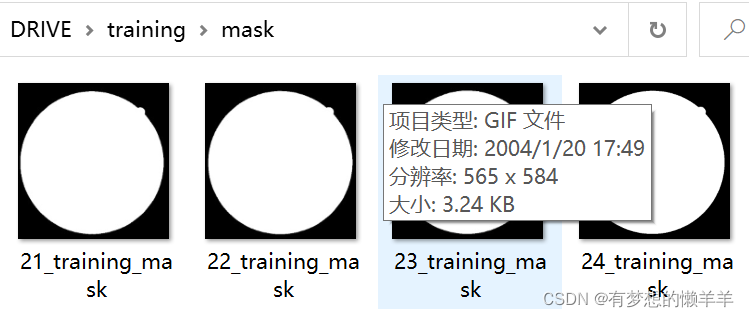
Mask中的白色,像素值是255,为感兴趣区域,相反黑色为0,为不感兴趣区域(直接就是不考虑区域)
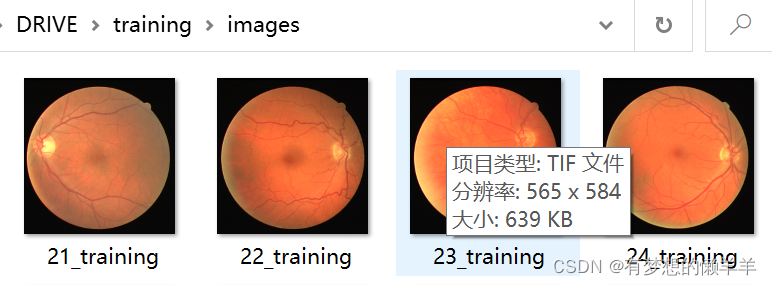
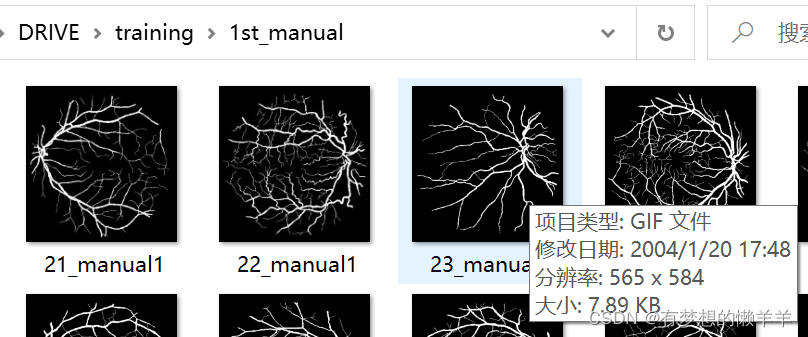
ist_manual,白色为255的前景,黑色为0的背景,前景就是医生标注出来的groudtruth。
对于图像上像素的处理:前景 背景 感兴趣区域 不感兴趣区域 (其中255是不参与计算的)
摸索阶段ing 轻喷!!
import os
from PIL import Image
from torch.utils.data import Dataset
import numpy as np
from torch.utils.data.dataset import T_co
class DRIVE(Dataset): # Drive数据集下 2个文件: training/test
# 初始化数据集属性
def __init__(self,
root:str, # 定义的数据集的路径位置
train:bool, # train=True时,读取数据集中的训练数据,train=False时,读取test数据
transforms = None # 设置数据预处理的方式
):
super(DRIVE, self).__init__()
# 设置一个标志,用于读取数据时是训练集还是验证集
self.flag = 'training' if train else 'test'
# os.path.join:将数据的路径进行拼接
data_root = os.path.join(root,'DRIVE(数据所在的文件名)',self.flag)
# 做一个断言,看当前的路径是否存在,不存在则报错
assert os.path.exists(data_root),f"path '{data_root}' does not exist"
self.transforms = transforms
# 使用i: for i in os.listdir( file_path )方法遍历路径下的数据文件
# i.endswith(条件) 保留遍历到的i,以endswith条件结尾的文件
# 此时获取的是复合条件的数据的名称(带后缀的) img_name
img_name = [i for i in os.listdir(os.path.join(data_root,'images')) if i.endswith("tif")]
# 将获取的数据的名字与data_root等file_path拼接,得到 每个数据的路径
self.img_list = [os.path.join(data_root,"images",i) for i in img_name]
# 获取1st_manual中每个数据的数据路径
self.manual = [os.path.join(data_root,"1st_manual",i.split('_')[0]+"_manual1.gif") for i in img_name]
# 检查一下每个遍历到的manual文件是否存在
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists")
# 同样的方法获取mask文件的路径(此时mask分为training与test)
self.roi_mask = [os.path.join(data_root,"mask",i.split("_")[0]+"_"+self.flag+"_mask.gif") for i in img_name]
# 检查获取的mask文件是否存在
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file{i}does not exists")
def __getitem__(self, idx):
# 根据传入的索引,return要训练的img以及mask(此时的mask是groundtruth)
# 根据传入的索引idx打开img图片,并转换成RGB图像
img = Image.open(self.img_list[idx]).convert('RGB')
# 根据传入的索引idx打开manual图片,并转换成灰度图像
manual = Image.open(self.manual[idx]).convert('L')
# 在设置mask中的类别时,0是背景,1是前景,而此时的mask中的前景像素值是255,所以÷255,令其为1
# 此时mask中的类别就是从0开始的(连续)
manual = np.array(manual) / 255
# roi_mask的图像,并转化成灰度图
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
# 将不感兴趣区域的no_roi区域的像素值设置成255(不参与计算LOSS)
roi_mask = 255 - np.array(roi_mask)
# 使用np.clip()方法,为叠加了manual(GT)与roi_mask后的像素设置像素的上下限
mask = np.clip(manual+roi_mask, a_min=0,a_max=255)
# 此时的感兴趣区域中的前景像素值=1,后景=0,不感兴趣区域像素值=255
# 将numpy格式转回PIL格式的原因:由于预处理transform中的方法处理的是PIL格式
mask = Image.fromarray(mask)
if self.transforms is not None:
img,mask = self.transforms(img,mask)
# 最后将根据idx所以读取的图片,经过预处理及像素值的处理后,返回
return img,mask # (PIL格式)
def __len__(self):
return len(self.img_list) # 返回当前数据集的数量
@staticmethod
# 固定方法,将获取的img及mask构建打包构建成tensor
def collate_fn(batch):
# 将对应batch数量的图像进行打包
images, targets = list(zip(*batch))
#
batched_imgs = cat_list(images,fill_value=0)
batched_targets = cat_list(targets,fill_value=255)
return batched_imgs,batched_targets
def cat_list(images,fill_value):
# 计算输入的图像中channel、H、W的最大值
# 原因:train时,所有的图像会被resize到一个固定的大小
# 而在test时,每张图像的大小可能不同,所以需要计算一下,设置一个合适尺寸的tensor
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
# 给batch前面再增加一个batc_size维度
# 此时的len(images)=batch_size
batch_shape = (len(images,) + max_size)
# 构建新的tensor batch_imgs
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
# 遍历每张img及在对于构建的张量中的每个切片pad_img
for img,pad_img in zip(images,batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
# 验证是否写对:
dataset = DRIVE(root=r'所有数据的',
train=True,
transforms=None)
d1 = dataset[0]
print(d1)

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









