










废话不多说,咱们上源码:
json格式的labels的下载地址:点我
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
## 导入所需要的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import requests
import cv2
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import models
from torchvision import transforms
from PIL import Image
注意,如果从未下载过VGG16,则下载时间会有些长。(500多M)
## 导入预训练好的VGG16网络
vgg16 = models.vgg16(pretrained=True)
print(vgg16)
打印网络结构:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
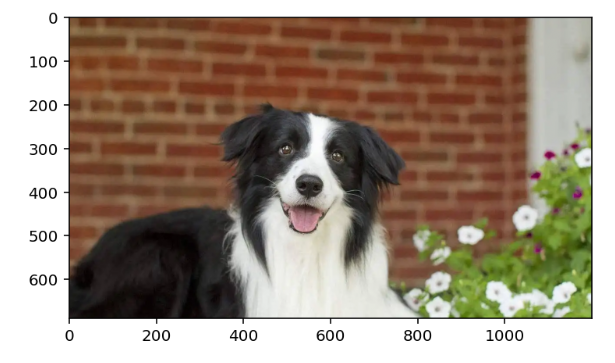
我们试着读取一张图片:
## 读取一张图片,并对其进行可视化
im = Image.open("边牧.png")
# 把图片转化为numpy数组
imarray = np.asarray(im) / 255.0
plt.figure()
plt.imshow(imarray)
plt.show()
输出效果如图所示:
## 对一张图像处理为vgg16网络可以处理的形式
data_transforms = transforms.Compose([
transforms.Resize((224,224)),# 重置图像分辨率
transforms.ToTensor(),# 转化为张量并归一化至[0-1]
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
input_im = data_transforms(im).unsqueeze(0)
print("input_im.shape:",input_im.shape)
input_im.shape: torch.Size([1, 3, 224, 224])
定义hook函数。
hook函数的作用:因为我们使用的是已经预处理好的vgg16网络的参数,所以为了得到在前向传播和反向传播(forward和backward)的图片的shape,我们定义hook函数。关于hook函数更具体的介绍,可以点击这个网页
## 使用钩子获取分类层的2个特征
## 定义一个辅助函数,来获取指定层名称的特征
activation = {} ## 保存不同层的输出
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
试着打印出来vgg网络第4层的参数:
## 获取中间的卷积后的图像特征
vgg16.eval()
## 第四层(maxpool1层),经过第一次最大值池化
vgg16.features[4].register_forward_hook(get_activation("maxpool1"))
_ = vgg16(input_im)
maxpool1 = activation["maxpool1"]
print("获取特征的尺寸为:",maxpool1.shape)
输出结果:获取特征的尺寸为: torch.Size([1, 64, 112, 112])
## 对中间层进行可视化,可视化64个特征映射
plt.figure(figsize=(11,6))
for ii in range(maxpool1.shape[1]):
## 可视化每张手写体
plt.subplot(6,11,ii+1)
plt.imshow(maxpool1.data.numpy()[0,ii,:,:],cmap="gray")
plt.axis("off")
plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()

从图片中我们能发现:很多映射都能分辨出原始图片所包含的内容,反映了网络中的较浅层能够获取图像的较大粒度的特征。
## 获取更深层次的卷积后的图像特征
vgg16.eval()
#获取vgg16中的第21层
vgg16.features[21].register_forward_hook(get_activation("layer21_conv"))
_ = vgg16(input_im)
layer21_conv = activation["layer21_conv"]
print("获取特征的尺寸为:",layer21_conv.shape)
获取特征的尺寸为: torch.Size([1, 512, 28, 28])
## 对中间层进行可视化,只可视化前88个特征映射
plt.figure(figsize=(11,8))
for ii in range(88):
## 可视化每张手写体
plt.subplot(8,11,ii+1)
plt.imshow(layer21_conv.data.numpy()[0,ii,:,:],cmap="gray")
plt.axis("off")
plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()

从上图我们可以发现更深层次的映射已经不能分辨出图像的具体内容。说明更深层的特征映射能从图像中提取更细粒度的特征。
我们之所以使用vgg16,是因为导入vgg16后,可以直接使用该模型对图像数据进行预测,并输出图像所对应的类别。我们下载ImageNet网络对应的1000个json格式的类别标签,点击这里下载文件。下载结束后,我们接着来看:
import json
jsonfile = r'labels.json' # 换成自己的地址
with open(jsonfile, 'r') as load_f:
load_json = json.load(load_f)
# 并把下面内容打开
labels = {int(key): value for (key, value)
in load_json.items()}
上面的程序读取了全部的标签,并将标签整理为字典形式,接下来,我们导入VGG16模型,对图像进行预测:
## 使用VGG16网络预测图像的种类
vgg16.eval()
im_pre = vgg16(input_im)
## 计算预测top-5的可能性
softmax = nn.Softmax(dim=1)
im_pre_prob = softmax(im_pre)
prob,prelab = torch.topk(im_pre_prob,5)
prob = prob.data.numpy().flatten()
prelab = prelab.numpy().flatten()
for ii,lab in enumerate(prelab):
print("index: ", lab ," label: ",labels[lab]," ||",prob[ii])
输出预测结果:
index: 232 label: Border collie || 0.5312159
index: 231 label: collie || 0.446996
index: 217 label: English springer, English springer spaniel || 0.0087789325
index: 230 label: Shetland sheepdog, Shetland sheep dog, Shetland || 0.0018267322
index: 176 label: Saluki, gazelle hound || 0.0015705331
最后的预测结果:有53%的可能性为collie(柯利牧羊犬)。

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









