






课程中认识许多CNN架构。首先是经典网络:
- LeNet-5
- AlexNet
- VGG
之后是近年来的一些网络:
- ResNet
- Inception
- MobileNet
经典网络
LeNet-5
LeNet-5是用于手写数字识别(识别0~9的阿拉伯数字)的网络。它的结构如下:
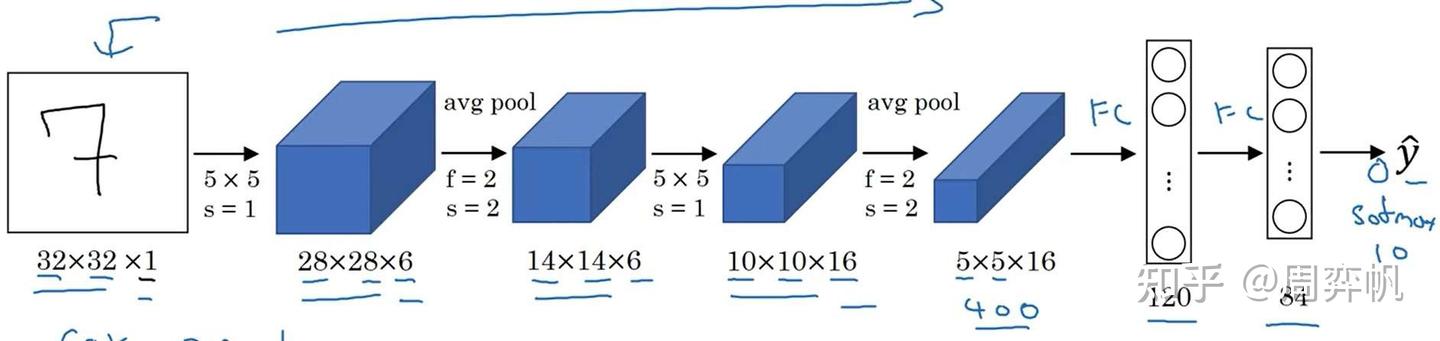
网络是输入是一张[32, 32, 1]的灰度图像,输入经过4个卷积+池化层,再经过两个全连接层,输出一个0~9的数字。这个网络和我们上周见过的网络十分相似,数据体的宽和高在不断变小,而通道数在不断变多。
这篇工作是1998年发表的,当时的神经网络架构和现在我们学的有不少区别:
- 当时padding还没有得到广泛使用,数据体的分辨率会越降越小。
- 当时主要使用平均池化,而现在最大池化更常见。
- 网络只输出一个值,表示识别出来的数字。而现在的多分类任务一般会输出10个值并使用softmax激活函数。
- 当时激活函数只用sigmoid和tanh,没有人用ReLU。
- 当时的算力没有现在这么强,原工作在计算每个通道卷积时使用了很多复杂的小技巧。而现在我们直接算就行了。
LeNet-5只有6万个参数。随着算力的增长,后来的网络越来越大了。
AlexNet
AlexNet是2012年发表的有关图像分类的CNN结构。它的输入是[227, 227, 3]的图像,输出是一个1000类的分类结果。
原论文里写的是输入形状是[224, 224, 3],但实际上这个分辨率是有问题的,按照这个分辨率是算不出后续结果的分辨率的。但现在一些框架对AlexNet的复现中,还是会令输入的分辨率是224。这是因为框架在第一层卷积中加了一个padding的操作,强行让后续数据的分辨率和原论文对上了。
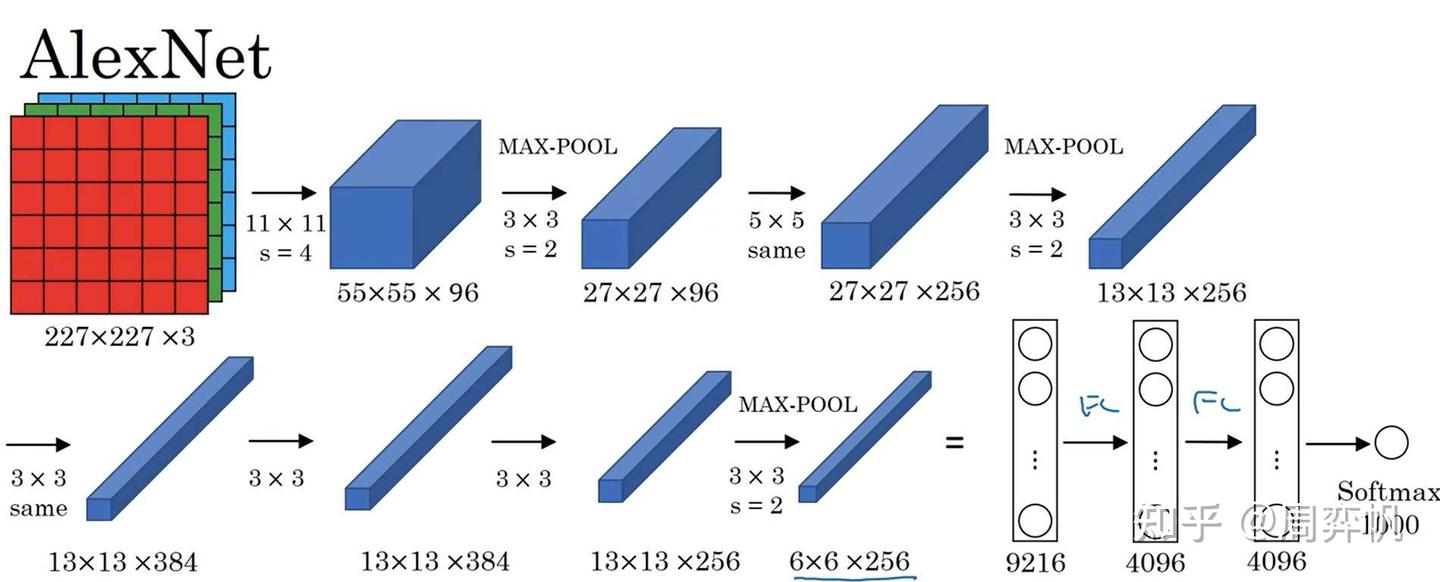
AlexNet和LeNet-5在架构上十分接近。但是,AlexNet做出了以下改进:
- AlexNet用了更多的参数,一共有约6000万个参数。
- 使用ReLU作为激活函数。
AlexNet还提出了其他一些创新,但与我们要学的知识没有那么多关系:
- 当时算力还是比较紧张,AlexNet用了双GPU训练。论文里写了很多相关的工程细节。
- 使用了Local Response Normalization这种归一化层。现在几乎没人用这种归一化。
VGG-16
VGG-16也是一个图像分类网络。VGG的出发点是:为了简化网络结构,只用3x3等长(same)卷积和2x2最大池化。
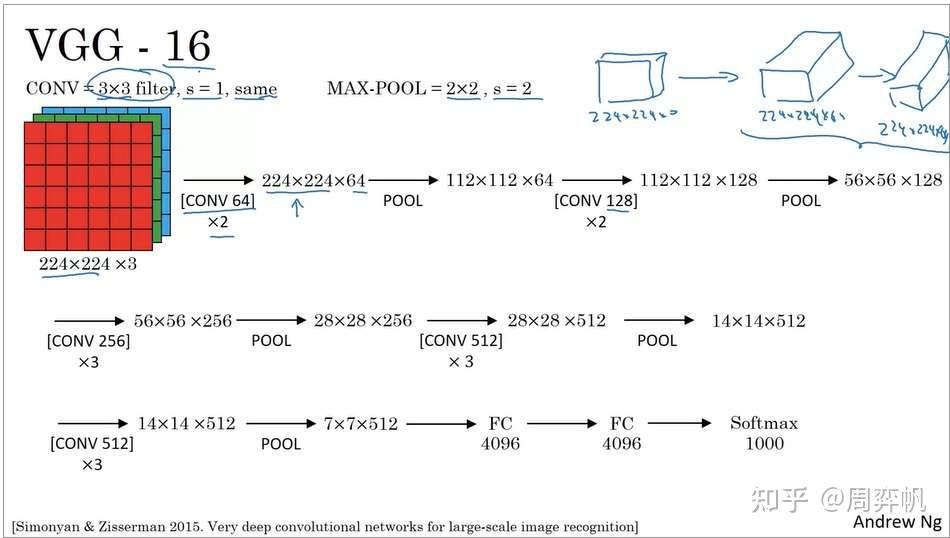
可以看出,VGG也是经过了一系列的卷积和池化层,最后使用全连接层和softmax输出结果。顺带一提,VGG-16里的16表示有16个带参数的层。
VGG非常庞大,有138M(1.38亿)个参数。但是它简洁的结构吸引了很多人的关注。
吴恩达老师鼓励大家去读一读这三篇论文。可以先看AlexNet,再看VGG。LeNet有点难读,可以放到最后去读。
ResNets(基于残差的网络)
非常非常深的神经网络是很难训练的,这主要是由梯度爆炸/弥散问题导致的。在这一节中,我们要学一种叫做“跳连(skip connection)”的网络模块连接方式。使用跳连,我们能让浅层模块的输出直接对接到深层模块的输入上,进而搭建基于残差的网络,解决梯度爆炸/弥散问题,训练深达100层的网络。
残差块
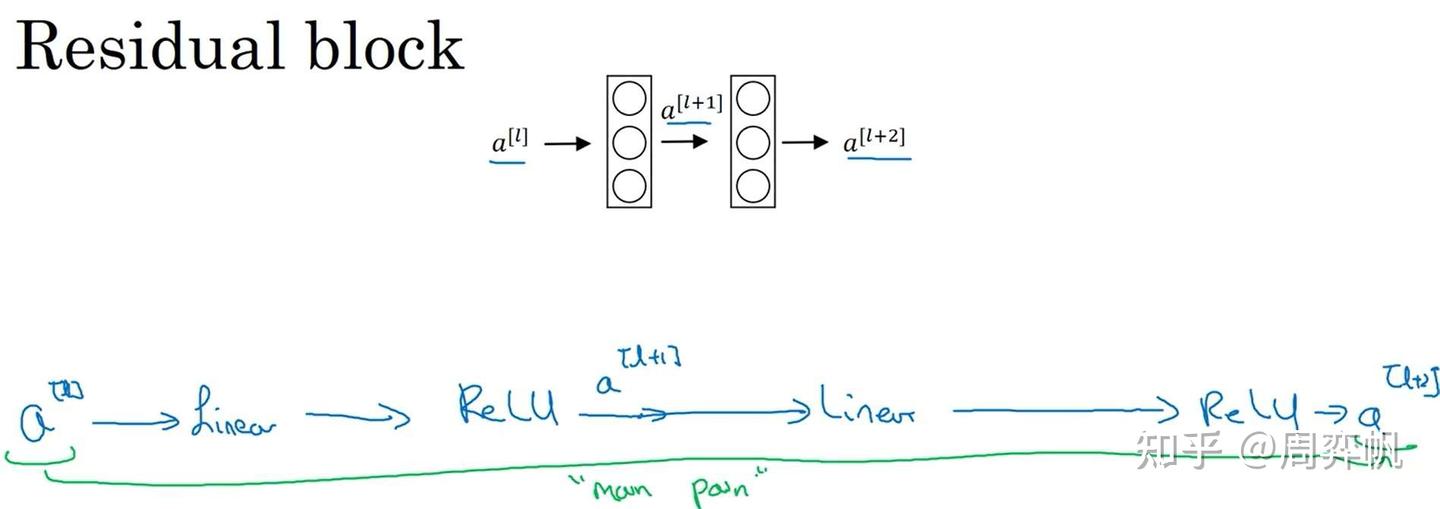
回忆一下,在全连接网络中,假如我们有中间层的输出,是怎么由算出来的呢?我们之前用的公式如下:
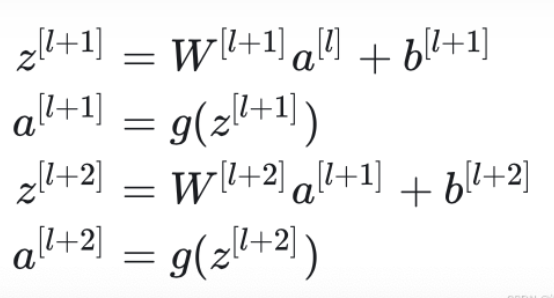
也就是说,要经过一个线性层、一个激活函数、一个线性层、一个激活函数,才能传递到
,这条路径非常长:
而在残差块(Residual block)中,我们使用了一种新的连接方法:
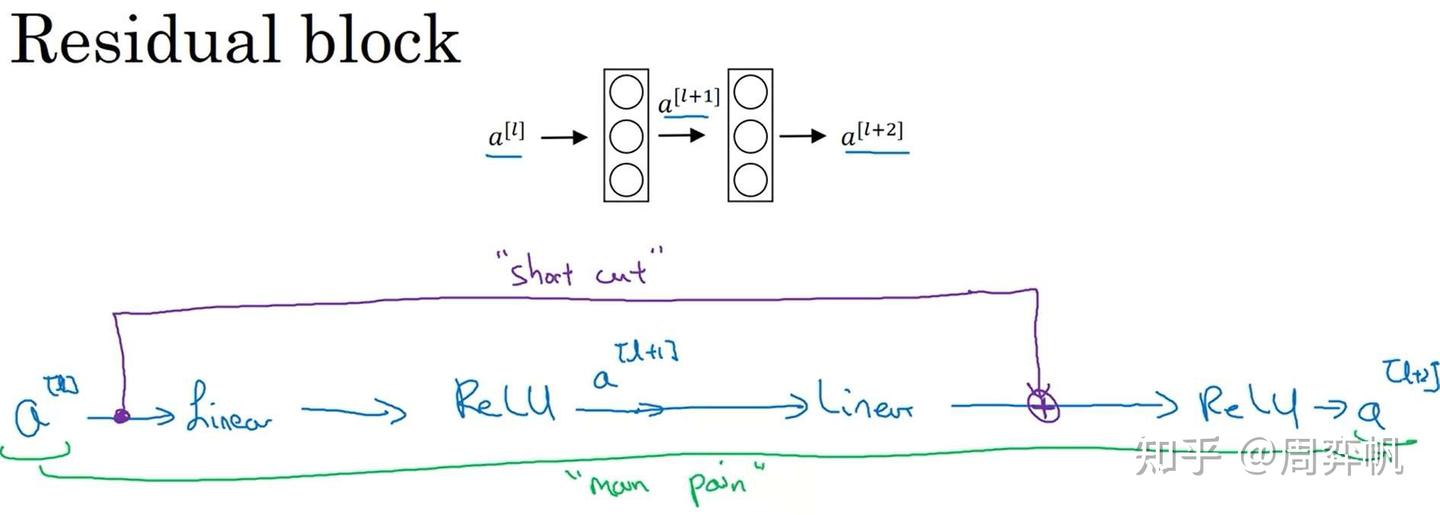
的值被直接加到了第二个ReLU层之前的线性输出上,这是一种类似电路中短路的连接方法(又称跳连)。这样,浅层的信息能更好地传到深层了。
使用这种方法后,计算公式变更为:
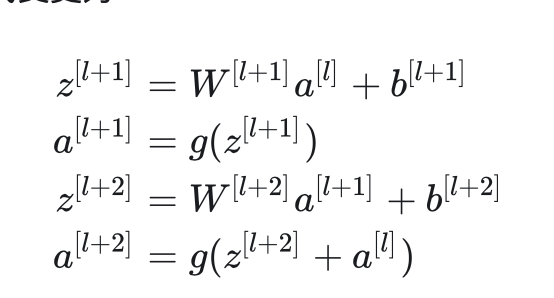
残差块中还有一个要注意的细节。这个式子能够成立,实际上是默认了
,
的维度相同。而一旦
的维度发生了变化,就需要用下面这种方式来调整了。
我们可以用一个W'来完成维度的转换。为了方便理解,我们先让所有a都是一维向量,W'是矩阵。这样,假设的长度是256,的长度是128,则W'的形状就是256*128。
但实际上,a是一个三维的图像张量,三个维度的长度都可能发生变化。因此,对于图像,上式中的W'应该表示的是一个卷积操作。通过卷积操作,我们能够减小图像的宽高,调整图像的通道数,使得和
的维度完全相同。
残差网络
在构建残差网络ResNet时,只要把这种残差块一个一个拼接起来即可。或者从另一个角度来看,对于一个“平坦网络”("plain network", ResNet论文中用的词,用于表示非残差网络),我们只要把线性层两两打包,添加跳连即可。
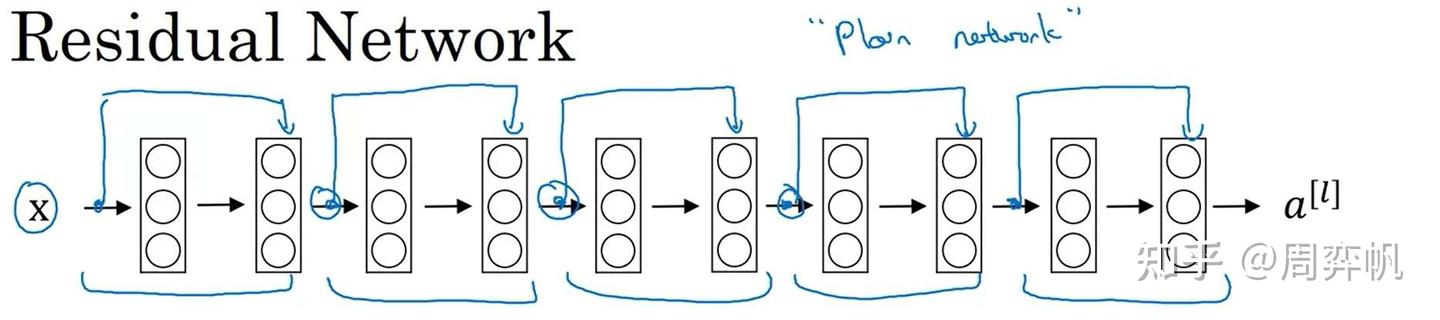
残差块起到了什么作用呢?让我们看看在网络层数变多时,平坦网络和残差网络训练误差的变化趋势:
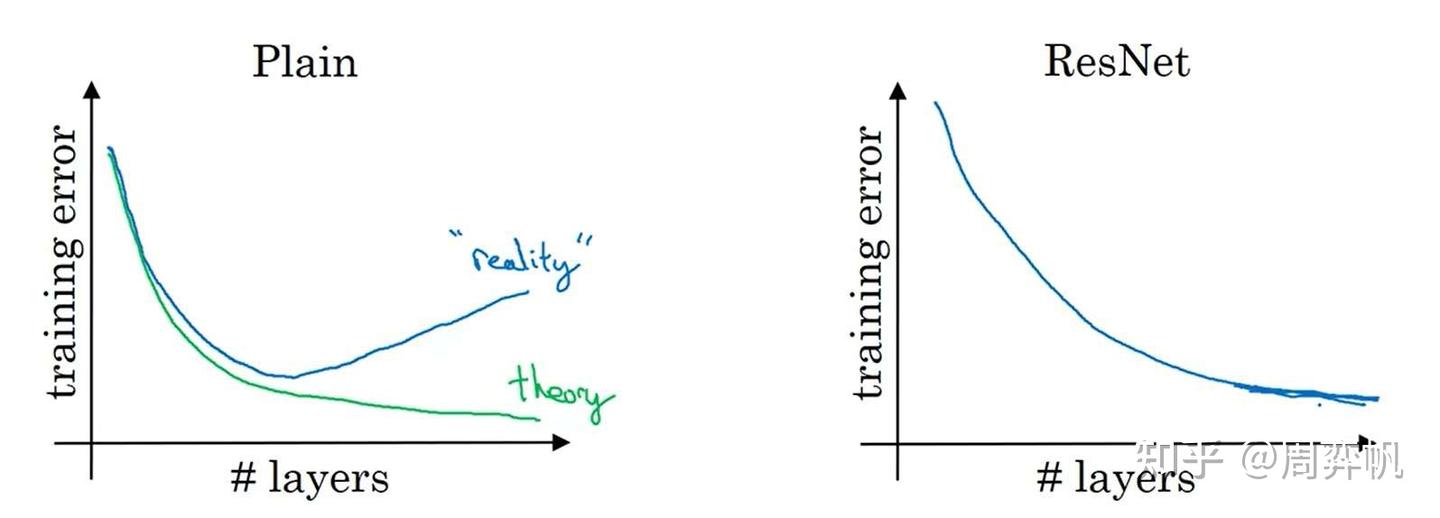
理论上来说,层数越深,训练误差应该越低。但在实际中,对平坦网络增加深度,反而会让误差变高。而使用ResNet后,随着深度增加,训练误差起码不会降低了。
正是有这样的特性,我们可以用ResNet架构去训练非常深的网络。
为什么ResNet是有这样的特性呢?我们还是从刚刚那个ResNet的公式里找答案。
假设我们设计好了一个网络,又给它新加了一个残差块,即多加了两个卷积层,那么最后的输出可以写成:
即
由于正则化的存在,所有W和b都倾向于变的更小,极端情况下,W,b都变为0。那么,
再不妨设,则
也是ReLU的输出,有:
这其实是一个恒等映射,也就是说,新加的残差块对之前的输出没有任何影响。网络非常容易学习到恒等映射。这样,最起码能够保证较深的网络不比浅的网络差。
准备好了所有基础知识,我们来看看完整的ResNet长什么样。
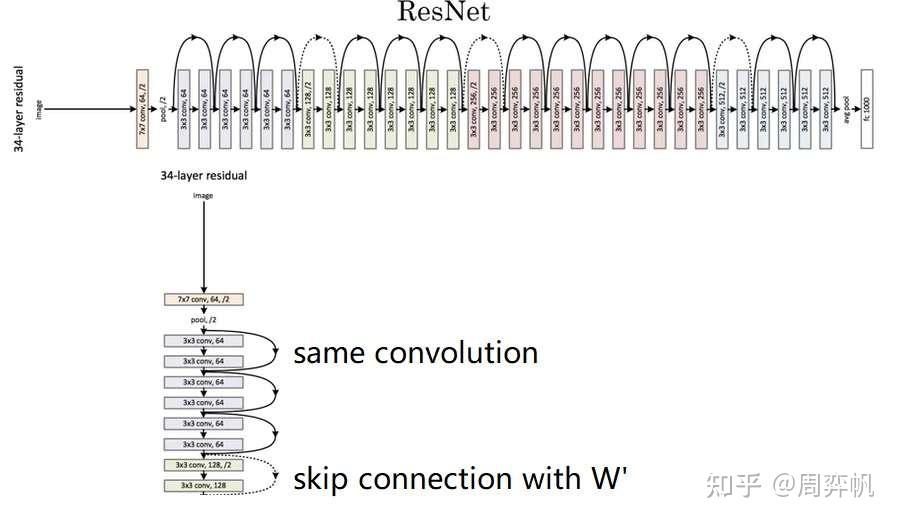
ResNet有几个参数量不同的版本。这里展示的叫做ResNet-34。完整的网络很长,我们只用关注其中一小部分就行了。
一开始,网络还是用一个大卷积核大步幅的卷积以及一个池化操作快速降低图像的宽度,再把数据传入残差块中。和我们刚刚学的一样,残差块有两种,一种是维度相同可以直接相加的(实线),一种是要调整维度的(虚线)。整个网络就是由这若干个这样的残差块组构成。经过所有残差块后,还是和经典的网络一样,用全连接层输出结果。
这里,我们只学习了残差连接的基本原理。ResNet的论文里还有更多有关网络结构、实验的细节。最好能读一读论文。当然,这周的编程实战里我们也会复现ResNet,以加深对其的理解。
Inception 网络
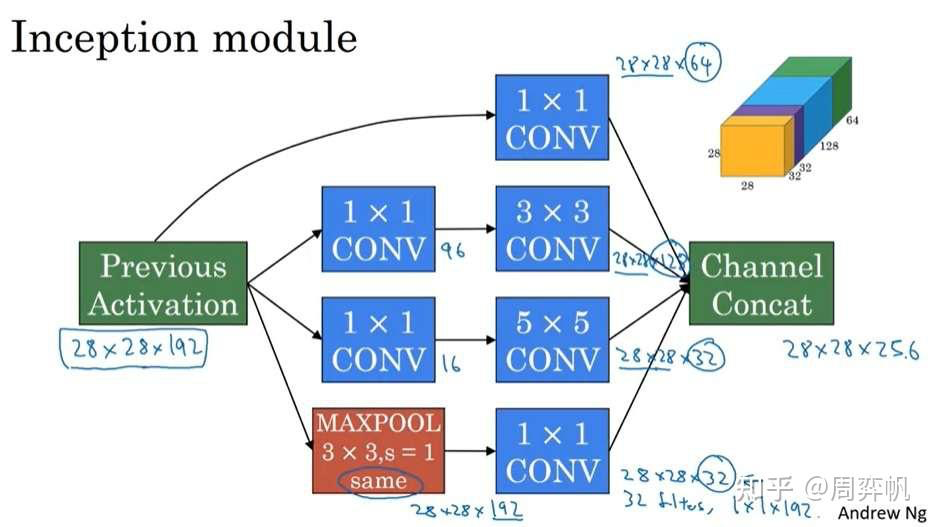
有了之前的知识,我们可以看Inception模块的完整结构了。1x1卷积没有什么特别的。为了减少3x3卷积和5x5卷积的计算量,做这两种卷积之前都会用1x1卷积减少通道数。而为了改变池化结果的通道数,池化后接了一个1x1卷积操作。
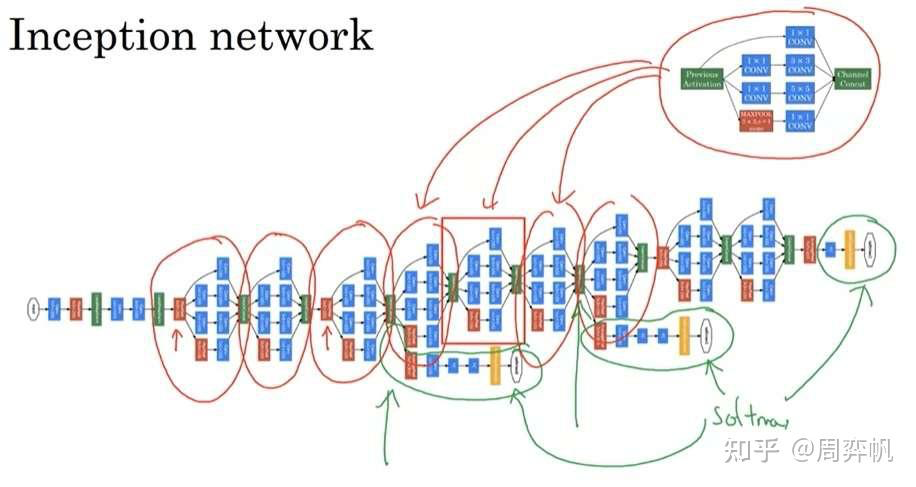
实际上,理解了Inception块,也就能看懂Inception网络了。如下图所示,红框内的模块都是Inception块。而这个网络还有一些小细节:除了和普通网络一样在网络的最后使用softmax输出结果外,这个网络还根据中间结果也输出了几个结果。当然,这些都是早期网络的设计技巧了。
MobileNet
MobileNet,顾名思义,这是一种适用于移动(mobile)设备的神经网络。移动设备的计算资源通常十分紧缺,因此,MobileNet对网络的计算量进行了极致的压缩。
再回顾一下:一次卷积操作中主要的计算量如下:
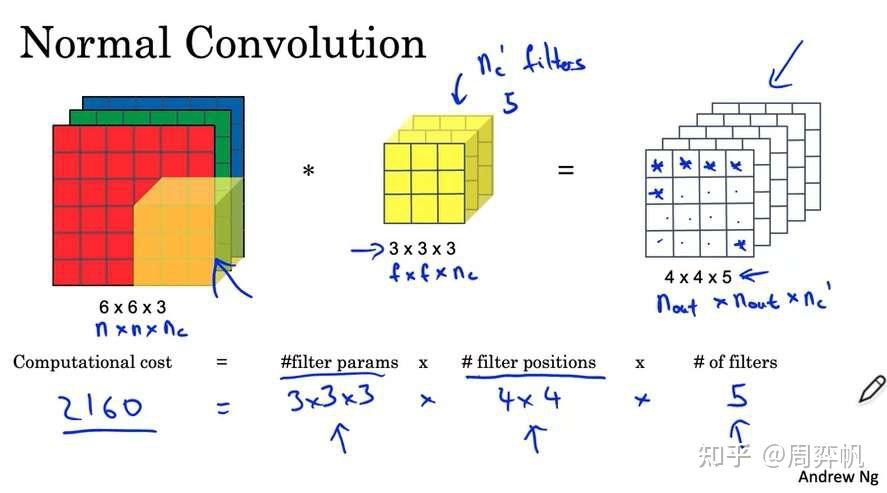
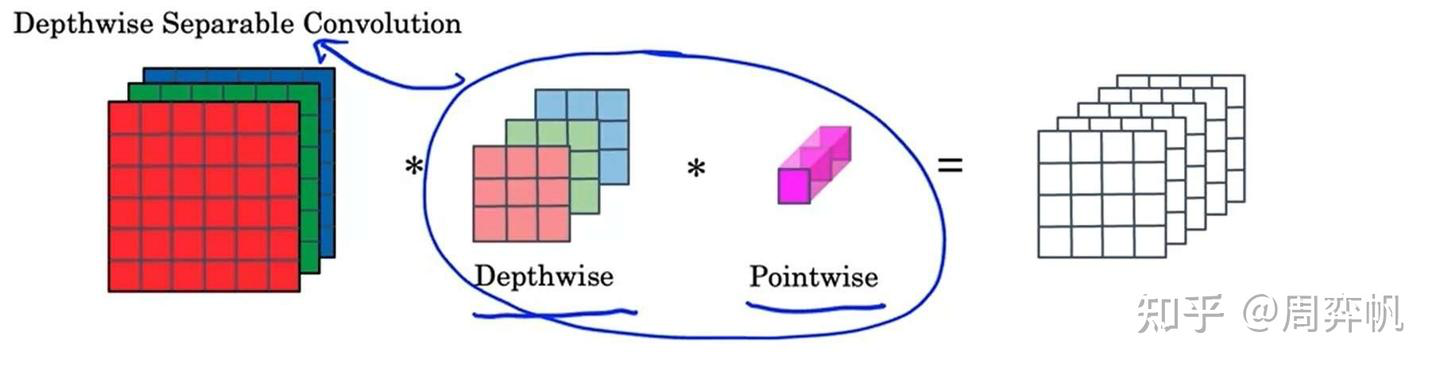
计算量这么大,主要问题出在每一个输出通道都要与每一个输入通道“全连接”上。为此,我们可以考虑让输出通道只由部分的输入通道决定。这样一种卷积的策略叫逐深度可分卷积(Depthwise Separable Convolution)。
这里的depthwise是“逐深度”的意思,但我觉得“逐通道”这个称呼会更容易理解一点。
逐深度可分卷积分为两步:逐深度卷积(depthwise convolution),逐点卷积(pointwise convolution)。逐深度卷积生成新的通道,逐点卷积把各通道的信息关联起来。
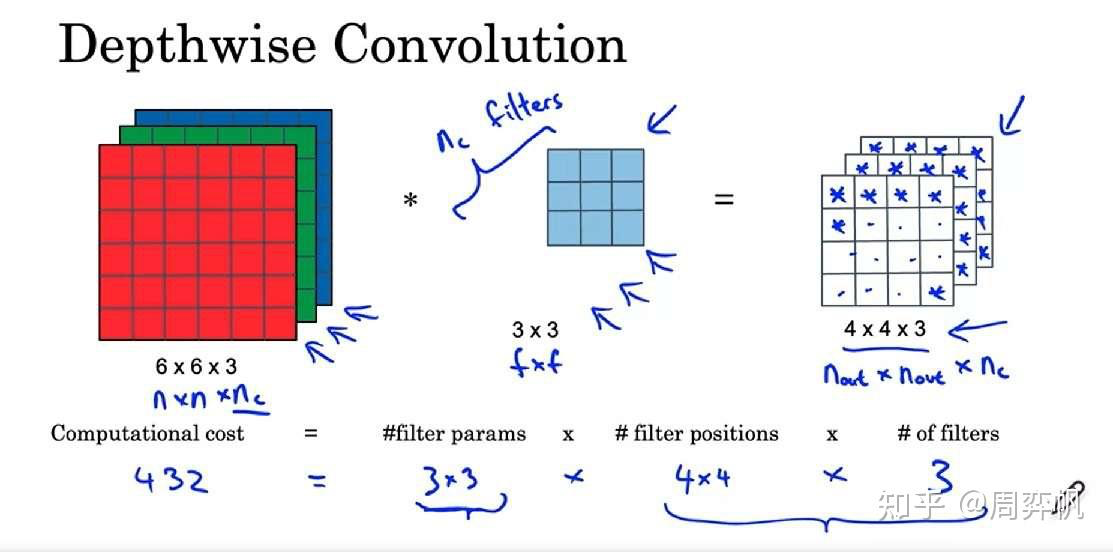
之前,要对下图中的三通道图片做卷积,需要3个卷积核分别处理3个通道。而在逐深度卷积中,我们只要1个卷积核。这个卷积核会把输入图像当成三个单通道图像来看待,分别对原图像的各个通道进行卷积,并生成3个单通道图像,最后把3个单通道图像拼回一个三通道图像。也就是说,逐深度卷积只能生成一幅通道数相同的新图像。
下一步,是逐点卷积,也就是1x1卷积。它用来改变图片的通道数。
![]()
之前的卷积有2160次乘法,现在只有432+240=672次,计算量确实减少了不少。实际上,优化后计算量占原计算量的比例是:
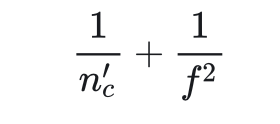
其中是输出通道数,f是卷积核边长。一般来说计算量都会少10倍。
网络结构
知道了MobileNet的基本思想,我们来看几个不同版本的MobileNet。
MobileNet v1
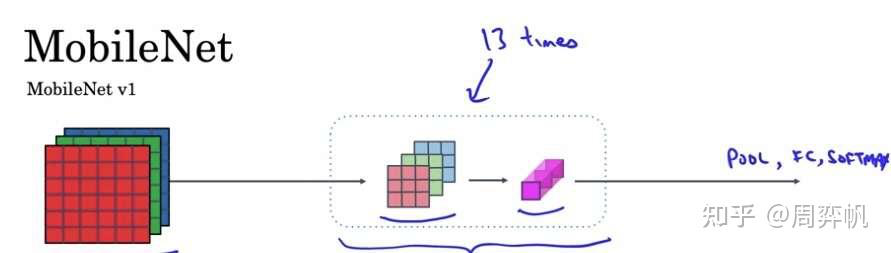
MobileNet v2
两个改进:
- 残差连接
- 扩张(expansion)操作
残差连接和ResNet一样。这里我们关注一下第二个改进。
在MobileNet v2中,先做一个扩张维度的1x1卷积,再做逐深度卷积,最后做之前的逐点1x1卷积。由于最后的逐点卷积起到的是减小维度的作用,所以最后一步操作也叫做投影。
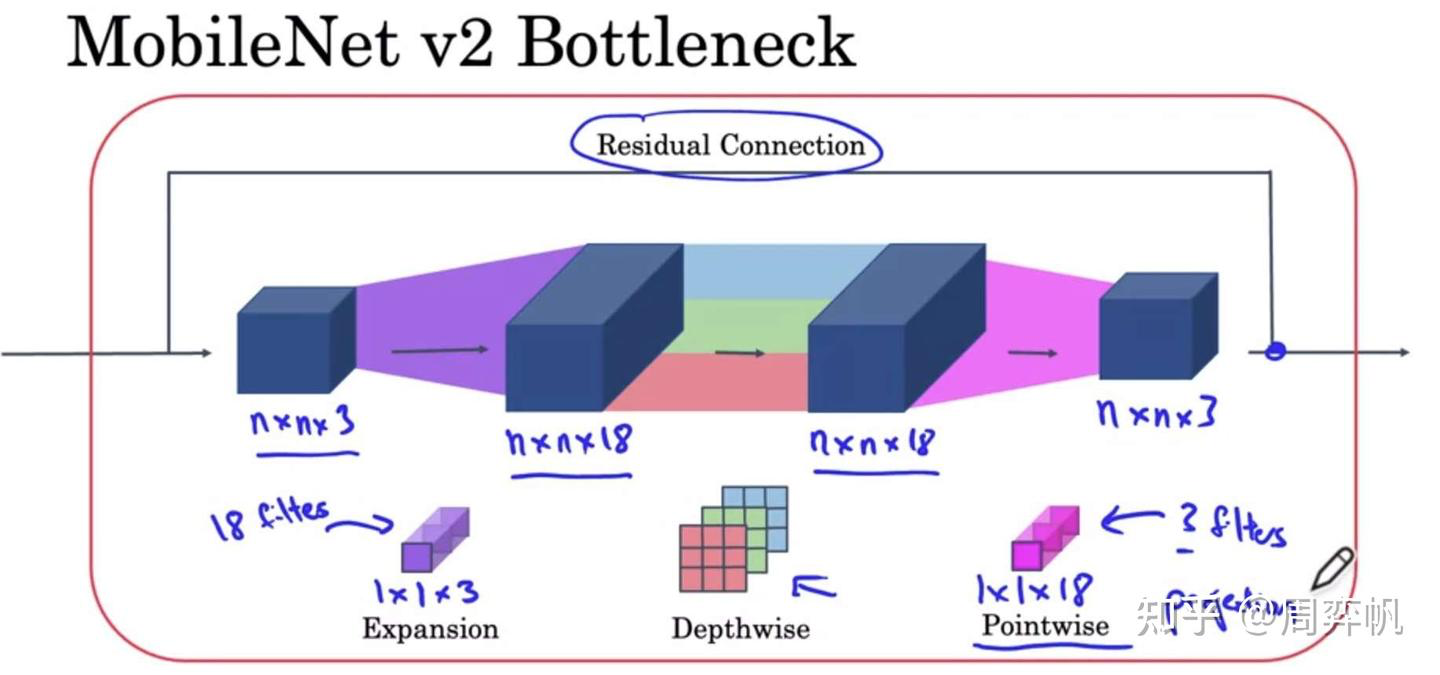
这种架构很好地解决了性能和效果之间的矛盾:在模块之间,数据的通道数只有3,占用内存少;在模块之内,更高通道的数据能拟合更复杂的函数。
EfficientNet
EfficientNet能根据设备的计算能力,自动调整网络占用的资源。
让我们想想,哪些因素决定了一个网络占用的运算资源?我们很快能想到下面这些因素:
- 图像分辨率
- 网络深度
- 特征的长度(即卷积核数量或神经元数量)
在EfficientNet中,我们可以在这三个维度上缩放网络,动态改变网络的计算量。EfficientNet的开源实现中,一般会提供各设备下的最优参数。
卷积网络实现细节
使用开源实现
由于深度学习项目涉及很多训练上的细节,想复现一个前人的工作是很耗时的。最好的学习方法是找到别人的开源代码,在现有代码的基础上学习。
使用迁移学习
如第三门课第二周所学,我们可以用迁移学习,导入别人训练好的模型里的权重为初始权重,加速我们自己模型的训练。
还是以多分类任务的迁移学习为例(比如把一个1000分类的分类器迁移到一个猫、狗、其他的三分类模型上)。迁移后,新的网络至少要删除输出层,并按照新的多分类个数,重新初始化一个输出层。之后,根据新任务的数据集大小,冻结网络的部分参数,从导入的权重开始重新训练网络的其他部分:
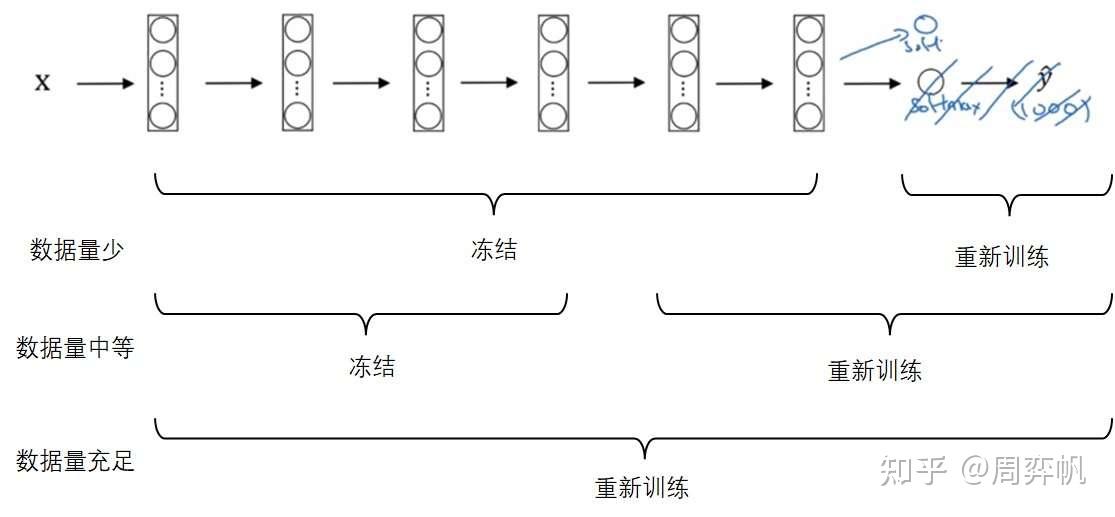
当然,可以多删除几个较深的层,也可以多加入几个除了输出层以外的隐藏层。
数据增强
由于CV任务总是缺少数据,数据增强是一种常见的提升网络性能的手段。
常见的改变形状的数据增强手段有:
- 镜像
- 裁剪
- 旋转
- 扭曲
此外,还可以改变图像的颜色。比如对三个颜色通道都随机加一个偏移量。
数据增强有一些实现上的细节:数据的读取及增强是放在CPU上运行的,训练是放在CPU或GPU上运行的。这两步其实是独立的,可以并行完成。最常见的做法是,在CPU上用多进程(发挥多核的优势)读取数据并进行数据增强,之后把数据搬到GPU上训练。
Pytorch实现ResNet
用到的pytorch基础知识
1. TensorDataset
db = TensorDataset(x, y)
-
TensorDataset:PyTorch 中的工具类,将
x和y包装成一个数据集对象。 -
作用:确保
x[i]和y[i]一一对应(类似(输入, 标签)的配对)。
2. DataLoader
DataLoader(db, batch_size, shuffle=True)
-
DataLoader:PyTorch 的核心工具,用于按批次加载数据。
-
db:上一步创建的数据集。 -
batch_size:每个批次的大小(如32)。 -
shuffle=True:是否打乱数据顺序(每个epoch重新随机排序,防止模型记住数据顺序)
-
所以完整代码是:
-
import torch from torch.utils.data import TensorDataset, DataLoader # 假设有输入数据 x 和标签 y(假设是张量) x = torch.randn(100, 3, 224, 224) # 100张224x224的RGB图像 y = torch.randint(0, 10, (100,)) # 100个标签(0~9的整数) # 创建 TensorDataset 和 DataLoader dataset = TensorDataset(x, y) dataloader = DataLoader(dataset, batch_size=32, shuffle=True) # 使用示例 for batch_x, batch_y in dataloader: print(batch_x.shape, batch_y.shape) # (32,3,224,224) 和 (32,)
3. torch.max
torch.max(out, dim=1)[0]:获取最大值(例如 [2.5, 3.2, 4.6])。
-
torch.max(out, dim=1)[1]:获取最大值对应的索引(即预测的类别编号)。 -
predictions = torch.max(out, dim=1)[1] print(predictions) # 输出:tensor([1, 0, 2])
代码实现:
此次作业的主要目的是使用残差网络实现深层卷积神经网络完成分类问题。

1. ResNets介绍:
1.1 - 深度神经网络的问题
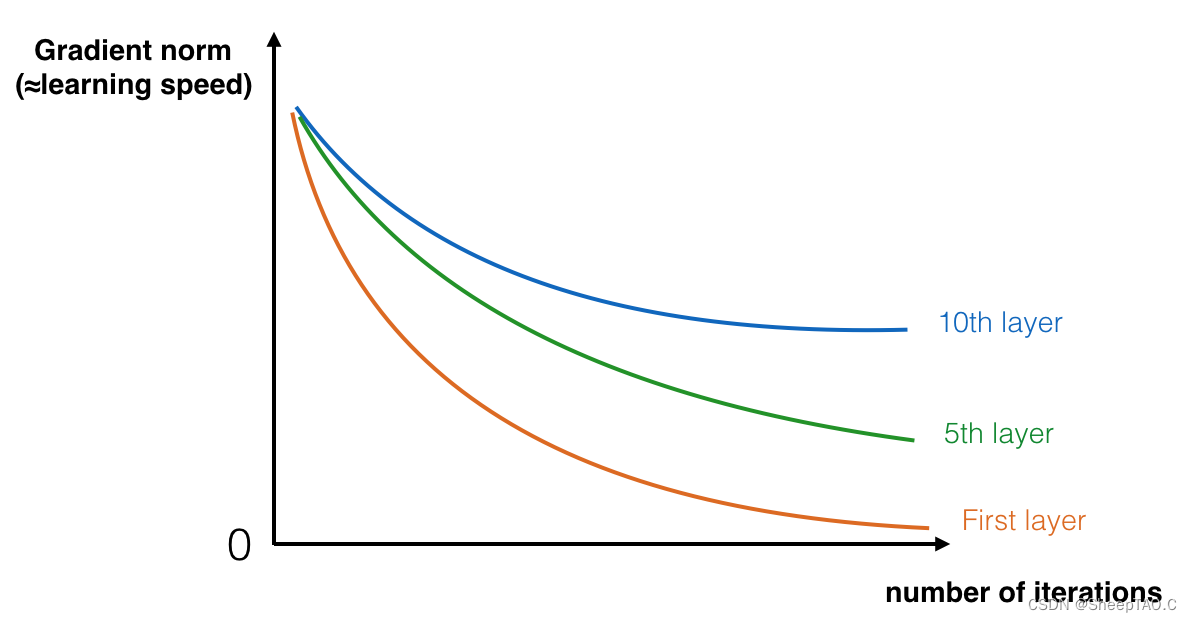
我们知道深度神经网络可以表达出更加复杂的非线性函数,这就可以实现从输入中提取更多不同的特征。但是随着网络层数的加多,梯度消失(vanishing gradient)的效应将被放大,这将导致算法在反向传播时从最后一层传播到第一层的过程中,算法乘了每一层的权重矩阵,因此梯度会很快地下降到接近0(或者很快地增加到一个很大的值)。
具体来说,在训练是你会看到前面层的梯度会非常迅速地降为零:
1.2 - 残差网络
残差网络可以很好解决深度神经网络的上诉问题,主要就是使用跳跃连接(skip connection)让梯度可以直接反向传递给前面的层(earlier layers):

残差块主要有两种,根据输入输出的维度是否相同划分为对等块(identity block)和卷积块(convolutional block)。
1.2.1-对等块
ResNets中的对等块表示输入激活值的维度 和输出激活值的维度
相同的情况。
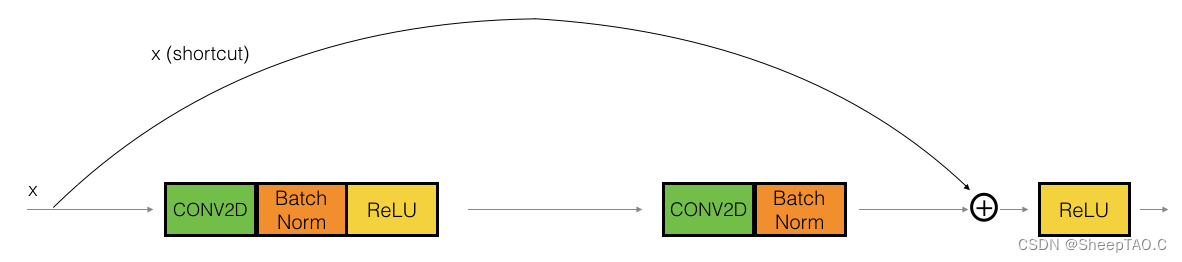
图中上部的路径表示跳跃连接,下部的路径表示主路径。为了加速训练过程,并在每一层添加了BatchNorm的步骤。
在本次试验中你将实现一个更加有效的ResNets的对等块,即进行跨越3个隐藏层的跳跃连接而非2个:
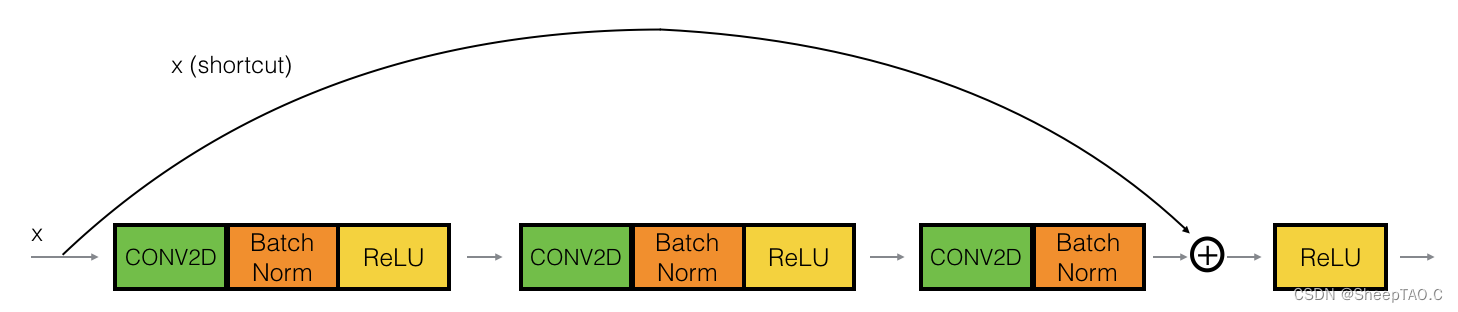
1.2.2 - 卷积块
ResNets中的卷积块表示输入激活值的维度 和输出激活值的维度
不相同的情况。对于不相同的情况我们对跳跃连接的部分再次应用一个卷积层(CONV2D)以此达到输入输出维度相同的目的。
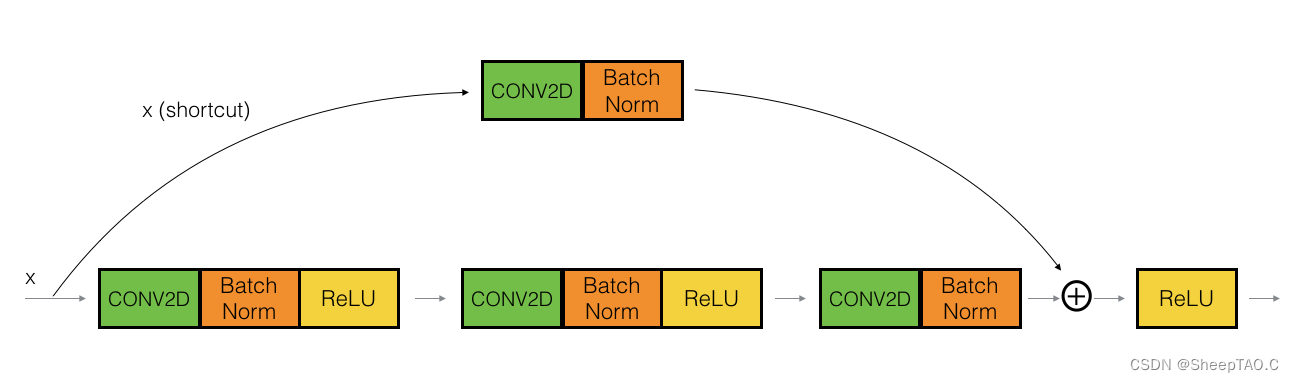
这个应用到跳跃连接的卷积层和视频中所说的矩阵 拥有相同的作用,不过注意这个卷积层不会应用任何的非线性函数,因为这个路径的作用仅仅是更改输入层
的维度以便和输出层
的维度相匹配。
1.2.3 - 模型架构
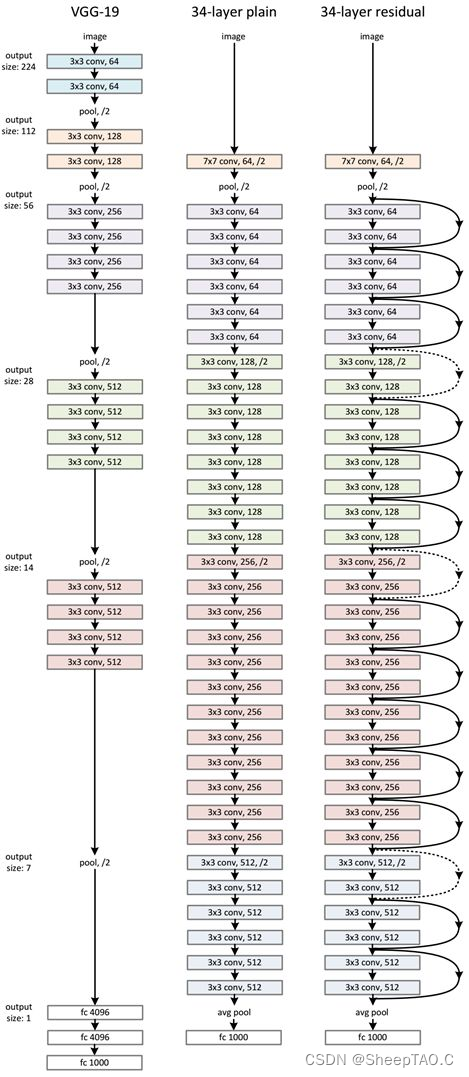
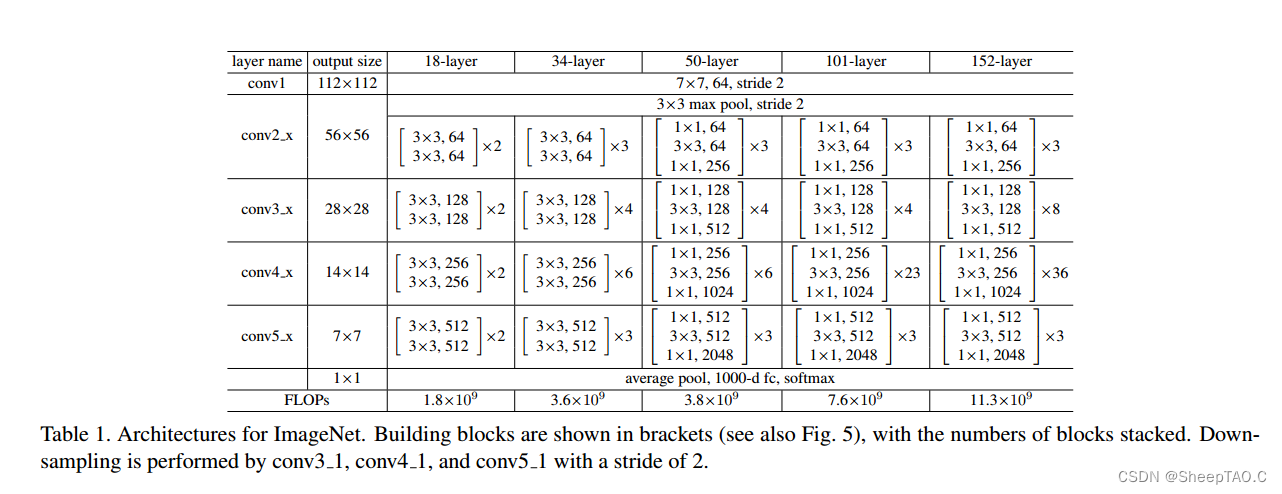
残差块用的卷积核为kernel_size=3.模型的conv3_1,conv4_1,conv5_1之前做了宽高减半的downsample.conv2_x是通过maxpool(stride=2)完成的下采样.其余的是通过conv2d(stride=2)完成的.
2. 构建ResNets模型
2.1 构建残差块
class Residual(nn.Module):
def __init__(self, in_channels, out_channels,stride = 1)->None:
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, stride = stride, kernel_size =3, padding =1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size =3, padding =1)
self.bn2 = nn.BatchNorm2d(out_channels)
if in_channels != out_channels:
self.conv1x1 = nn.Conv2d(in_channels, out_channels,kernel_size=1,stride=stride)
else:
self.conv1x1 = None
def forward(self, x):
o1 = self.relu(self.bn1(self.conv1(x)))
o2 = self.bn2(self.conv2(o1))
#print("o2 shape",o2.shape)
#print("x:",x.shape)
if self.conv1x1:
x = self.conv1x1(x)
return self.relu(o2+x)2.2 残差网络
class ResNet(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super().__init__()
self.model = nn.Sequential(nn.Conv2d(in_channels=in_channels,
out_channels=64,
stride = 2,
kernel_size=7,
padding = 3),#其中 padding=3 是 kernel_size//2,确保 padding='same' 的效果。
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
Residual(64,64),
Residual(64,64),
Residual(64,64),
Residual(64,128,stride=2),
Residual(128,128),
Residual(128,128),
Residual(128,128),
Residual(128,256,stride=2),
Residual(256,256),
Residual(256,256),
Residual(256,256),
Residual(256,256),
Residual(256,256),
Residual(256,512,stride=2),
Residual(512,512),
Residual(512,512),
nn.AdaptiveAvgPool2d(output_size=1)## 自适应平均池化,指定输出(H,W)
)
self.fc = nn.Linear(512, num_classes)
self.softmax = nn.Softmax(dim=1)
#print(self.model)
def forward(self, x):
out = self.model(x)
#print("out.shape:",out.shape)
out = out.reshape(x.shape[0], -1)
#print("out.shape:",out.shape)
self.fc(out)
return out
def predict(self, x):
out = self.forward(x)
out = self.softmax(out)
return torch.max(out, dim=1)[1]3. 数据预处理
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5','r')
test_dataset = h5py.File('datasets/test_signs.h5','r')
# 直接从把h5数组转化为tensor太慢,先转成numpy再转到tensor更快
train_set_x = torch.from_numpy(np.array(train_dataset['train_set_x']))
train_set_y = torch.from_numpy(np.array(train_dataset['train_set_y']))
test_set_x = torch.from_numpy(np.array(test_dataset['test_set_x']))
test_set_y = torch.from_numpy(np.array(test_dataset['test_set_y']))
classes = torch.tensor(test_dataset['list_classes'])
train_set_x = train_set_x.permute(0,3,1,2) /255
test_set_x = test_set_x.permute(0,3,1,2) /255
return train_set_x,train_set_y,test_set_x,test_set_y,classes
def data_loader(x, y, batch_size = 32):
db = TensorDataset(x, y)
return DataLoader(db, batch_size, shuffle=True)
train_X,train_Y,test_X,test_Y,classes = load_dataset()
print(f'The num of train set:{train_X.shape[0]}')
print(f'The num of test set:{test_X.shape[0]}')
print(f'The shape of train set(x): {train_X.shape}')
print(f'The shape of train set(y): {train_Y.shape}')
print(f'The number of class: {classes.shape[0]}')
4. 训练模型
def train(train_X: np.ndarray,
train_Y: np.ndarray,
num_classes:int,
batch_size=32,
num_epoch=5):
in_channels = train_X.shape[1]
net = ResNet(in_channels, num_classes)
loss_fn = torch.nn.CrossEntropyLoss()
train_loader = data_loader(train_X, train_Y, batch_size)
optimizer = torch.optim.Adam(net.parameters(),
5e-4)
for e in range(num_epoch):
for step, (batch_x, batch_y) in enumerate(train_loader):
output = net.forward(batch_x)
loss = loss_fn(output, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch {e}. loss: {loss}')
return netnet = train(train_X, train_Y, classes.shape[0])
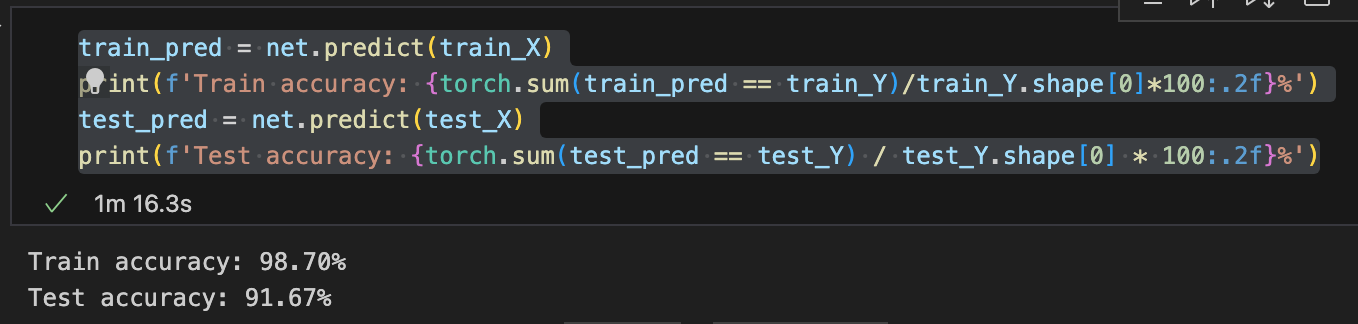
train_pred = net.predict(train_X)
print(f'Train accuracy: {torch.sum(train_pred == train_Y)/train_Y.shape[0]*100:.2f}%')
test_pred = net.predict(test_X)
print(f'Test accuracy: {torch.sum(test_pred == test_Y) / test_Y.shape[0] * 100:.2f}%') 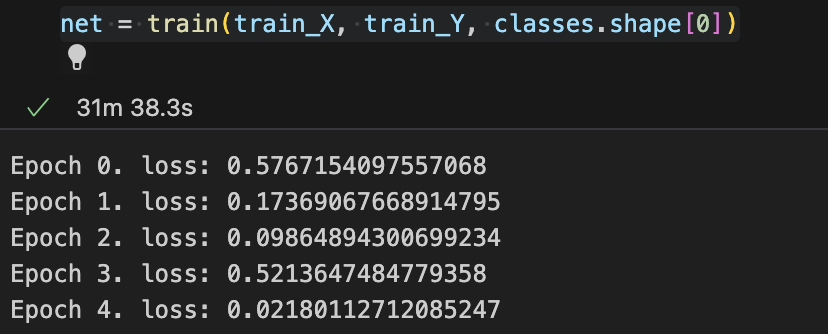
clear memory
%%javascript
IPython.notebook.save_checkpoint();
if (confirm("Clear memory?") == true)
{
IPython.notebook.kernel.restart();
}
参考了
吴恩达深度学习C4W2残差网络[Pytorch实现]_吴恩达 残差网络 练习 pytorch-CSDN博客
https://zhuanlan.zhihu.com/p/544917913

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









