







【NLP算法面经】科大、字节、华为、网易、腾讯、快手、OPPO等算法岗面试详细复盘(★附面题整理★)
🌟 嗨,你好,我是 青松 !
🌈 自小刺头深草里,而今渐觉出蓬蒿。
NLP Github 项目推荐:
-
【AI 藏经阁】:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
【AI 算法面经】:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
【大模型(LLMs)面试笔记】:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题,适合大模型初学者和正在准备面试的小伙伴。
希望能帮助各位同学缩短面试准备时间,不错过金三银四涨薪窗口,迅速收获心仪的Offer 🎉🎉🎉
文章目录
楼主秋招主要投算法岗(偏NLP方向)和数据岗方向,下面分享我的一些面试经历。
一、科大讯飞(NLP)
-
简要介绍自己
-
Python里面哈希表对应哪种结构,是如何解决哈希冲突的
-
DSSM模型和ESIM模型的区别
-
Word2vec原理,word2vec和fasttext原理上的区别
-
Bert原理,bert随机mask掉15%的词,为什么要随机有80%替换为【mask】,10%要替换为别的单词,随机10%不替换
-
文本匹配怎么使用bert
-
实习里的项目
-
Xgb原理
-
编程题:找无序数量的中位数,时间复杂度比排序要快
二、字节跳动(广告算法)
-
AUC的原理(衡量分类器排序的能力),计算(100正,900负,分类器是0到1均匀分布,计算AUC)
-
样本不平衡如何改进,影响了样本原本的分布该怎么办
-
代码实现梯度下降
-
给一个rand5,如何用代码实现rand7(构建[rand5()-1]*5+rand5(),第一项{0,5,10,15,20},第二项{1,2,3,4,5},加和结果{1,2,……,25},踢掉大于21的数,剩下的仍是等概率出现的,在对7求余在加1即可得到rand7())
三、触宝(NLP工程师)
-
面向对象,面向过程,面向切面的不同和优势劣势
-
排序算法稳定性,有那些稳定的排序算法和不稳定的排序算法
-
面向对象的三个性质
-
数组和链表各自的优势劣势
-
一个target,一个数组,找出数组里面所有和为target的组合,数字可以重复(DFS深度遍历,当path求和大于target时回溯)
-
了解哪些分类器,具体介绍
-
决策树分支的标准,gbdt和xgboost的区别
-
梯度消失和梯度爆炸,有什么办法解决
-
k-means的k值如何确定
-
了解哪些损失函数
-
具体介绍word2vec的原理
-
Bert的原理,看过哪些bert改进之后的方法(ALBert的原理,XL-Net了解过吗)
-
Transformer里面self-attention和一般的attention的区别
-
介绍目前实习中做的一些东西
-
聚类的方法有哪些,评价聚类的指标有什么
-
对NLP的前景有什么看法
-
反问问题
四、网易(数据挖掘工程师)
-
介绍一下目前实习中的工作内容
-
怎么迭代模型(收集bad case,重新修正打标签的函数,然后重新训练模型)
-
Bad case怎么收集(需求方反馈)
-
实习中跑的模型(过滤信息)有没有和别人的方法比较过,评价指标是什么
-
有没有和产品运营沟通过的经历
五、oppo(NLP工程师)
-
数学系在算法工程师就业中的优势和劣势
-
编程能力如何
-
概率题:甲、乙两个人轮流吃糖,每一轮吃到的概率为1/2,,先吃到的赢;甲赢的概率。有两颗糖,甲吃到糖个数的期望
-
编程题:求回文数
-
介绍实习中的项目
-
如何缓解过拟合
-
深度学习和传统机器学习的优劣
-
周末会用来干啥
-
遇到困难如何解决
-
给一个1T的无序大数组,找中位数
六、虎牙(NLP工程师)
-
介绍做的比较好的项目
-
fasttext原理,bert预训练
-
实习中的项目
-
算法题:rand11实现rand7
-
卷积神经网络和全连接网络的异同点
-
why 深层网络
-
反问问题
七、阿里CTO线(NLP工程师)
-
介绍实习做过的项目,参加过的比赛
-
简要介绍ESIM模型
-
NLP任务的问题,场景,解决的方法
-
为什么上段实习两个月就走了
九、快手(数据挖掘算法工程师)
-
介绍印象最深的做过的项目
-
介绍Word2vec原理及损失函数
-
介绍ESIM,DSSM
-
Xgboost原理
-
有没有做过大数据量级别的文本匹配(TB级别),用没用过spark,hive等
-
概率题:一个孤岛重男轻女,直到生出男孩为止,男女出生率1比1,初始比例也是1比1,问最终的男女比例。平均一个家庭有多少个孩子。
-
概率题:某疾病发病概率1/1000,患者有95%的概率检测出患病,健康者有5%的概率被误诊,问若一个人被检测出患病,实际患病概率是多少。
-
算法题:旋转数组,查找某个特定值(二分法的变种)
-
算法题:LeetCode股票问题第一问(动态规划)
-
一面结束马上二面:主要聊实习中的业务,重点比较关注私信反垃圾的部分(因为是风控部门)
九、腾讯WXG(NLP)
-
私信反垃圾,如何从整体评估数据的一个恶意率(没做过,答不上来)
-
机器学习如何选取数据
-
如何缓解过拟合
-
介绍L1, L2正则化
-
知道哪些模型评价指标
-
AUC和F1的区别,分别使用在什么场景
-
介绍relu,Sigmoid,tanh
-
知道哪些损失函数(回归,分类)
-
介绍反向传播(BP)
-
介绍损失函数在神经网络中的重要性
-
LSTM,Transfomer,BERT原理
-
介绍SVM
-
介绍卷积神经网络
-
resnet的残差链接
-
手推logistics regression
-
代码题:快速排序
-
介绍NER,POS(词性分析)
-
HMM
-
做题:翻转链表,实现求AUC算法,实现LSTM,python深拷贝和浅拷贝的问题
十、招联金融(数据分析)
-
介绍电信用户流失分类的项目
-
如何处理过拟合
-
Xgboost原理
-
实习经历的收获
-
未来发展的规划(职业定位,工作地点,薪资)
-
介绍项目:电信用户流失
-
实习:私信反垃圾,在线客服人工坐席知识挖掘
-
机器学习解决不了的问题,用更简单的规则匹配怎么做
-
算法实习正则匹配(简要说明就行,递归)
-
对招联金融有什么看法,未来的职业定位
十一、BIGO(NLP)
-
手撕代码:求一个数列正序对个数
-
挖简历:项目和实习
-
手撕代码:挖井的问题(每个家庭都可以打井,成本为c[i],或者挖水管,i,j两家通水管成本为dp[i][j]。求所有家庭喝上水的最小成本)
-
堆排序
十二、华为运营商bg(AI工程师)
-
手撕代码,输出数据库中满足四个要求的样本(具体要求忘记了,涉及到hash)
-
AUC原理,ROC曲线上每个点代表的含义
-
挖项目
-
手撕代码:和字典排序相关,也是easy级别的题目
-
实习经历
-
详细介绍某个实习或者项目,其中在数据预处理,建模,优化,后续改进四个方面上是如何体现的
HR面
-
自我介绍
-
人生中的挫折
-
有去国企的打算吗
-
未来的职业定位和发展
-
对华为的看法,在心目中的排位
-
薪资的期望
十三、汇量(算法工程师)
一面
-
手撕代码:LeetCode17电话号码的字符组合
-
介绍HMM
-
Word2vec和fasttext的区别,fasttext的改进
-
爬虫有用过动态框架吗
-
介绍实习经历、项目
二面
-
手撕代码:一个亿级别的数据,是地球上各个位置的温度,对该数组进行排序,时间复杂度O(n)。面试官非常nice,给了很多提示,最后写出来了…真是惭愧
-
Bagging和boosting的区别
-
过拟合的解决办法
-
知道哪些分类器
-
Svm,LR区别
-
数组和链表的区别
-
哈希冲突的解决方法
十四、三七互娱(算法工程师)
- 聊实习经历,就只有20min
十五、网易云(深度学习算法工程师)
-
介绍项目
-
估计Word2vec的参数量
-
Spark用没用过
-
简要介绍MapReduce的原理
-
挖项目,两面都没有撕代码
十六、字节跳动(nlp算法-DATA)
-
手撕代码:求数组最长上升子序列的长度
-
介绍实习项目
-
Lgb和xgb的区别
十七、深信服(算法工程师)
-
挖项目
-
Python中的字典的查找时间复杂度
-
给定一个数组arr,tagert,求数组元素的组合之和=target的所有可能。(o(N)的解法)
-
聊实习的工作
-
C++编程:分配1024个字节的内存,按字节对内存进行循环赋值,取值为0-255
-
Python代码运行时间超过正常情况要怎么办
十八、百度(算法工程师)
-
两个栈实现一个队列
-
一个连续数组有断点,logN时间复杂度找到它
-
Xgb和lgb的区别,和其他树模型比的优势
-
挖项目
十九、腾讯wxg补招(应用研究)
面了七轮,主要还是挖简历,问一下各种算法原理(基础的LR,kmeans,dbscan,XGB,bert方方面面都涉及到了)。
算法题:1.小于n的正整数里面1出现的次数;2.找出有序数组里面第一个重复1000次的数字3. LeetCode 409
智力题:40匹马8个赛道,每个赛道都可以知道马的排名,如何给这40个马排名
大模型(LLMs)高频面题全面整理(🌟2025 Offer 必备🌟)
全面总结了【大模型面试】的高频面题和答案解析,答案尽量保证通俗易懂且有一定深度。
适合大模型初学者和正在准备面试的小伙伴。
希望也能帮助你快速完成面试准备,先人一步顺利拿到高薪 Offer 🎉🎉🎉
一、大模型进阶面 🎯
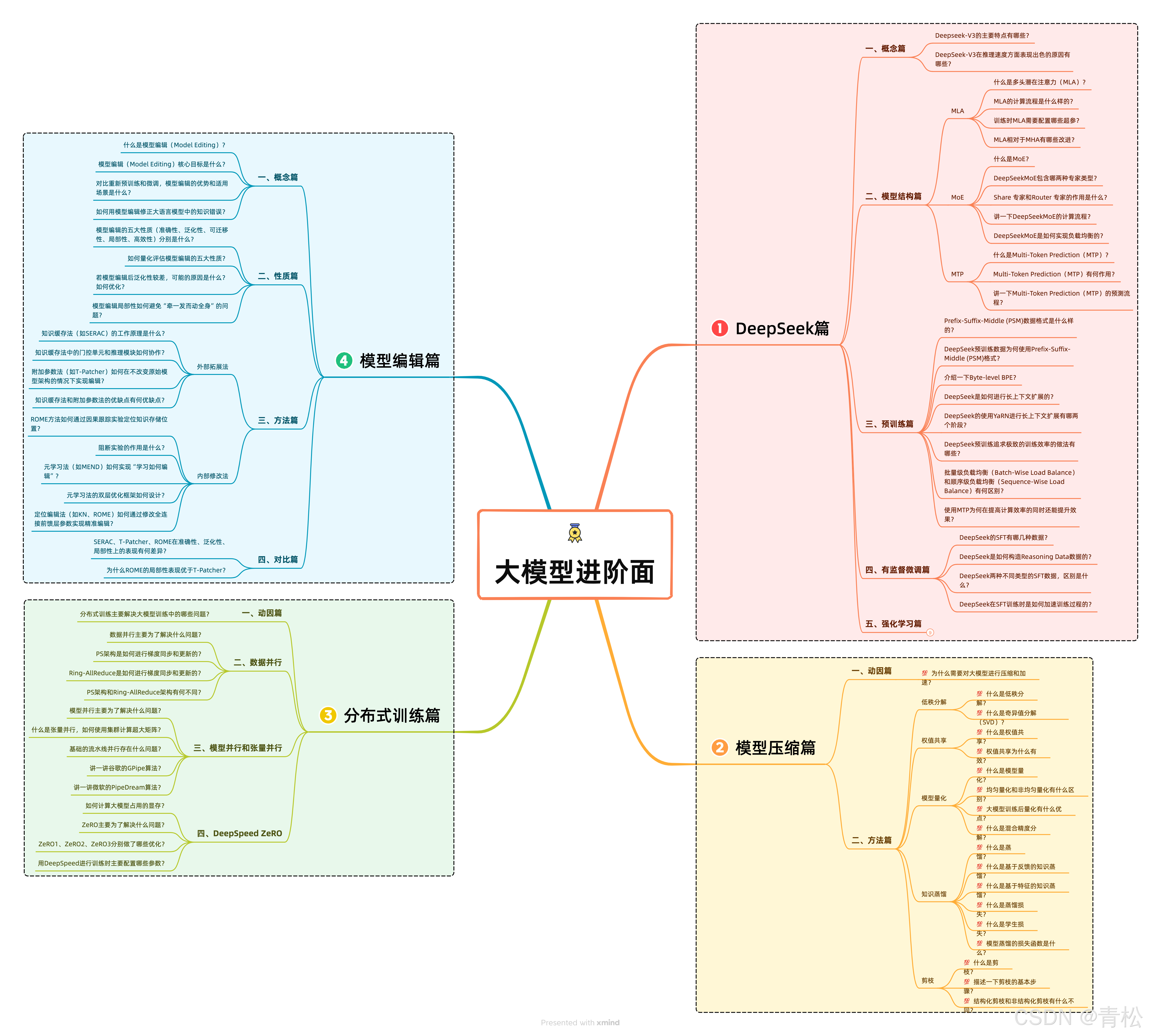
💯【大模型进阶面 之 DeepSeek篇】 你必须要会的高频面题
- 一、概念篇
- 二、模型结构篇
- 三、预训练篇
- 四、有监督微调篇
- 五、强化学习篇
💯【大模型进阶面 之 模型编辑篇】 你必须要会的高频面题
- 模型编辑(Model Editing)核心目标是什么?
- 对比重新预训练和微调,模型编辑的优势和适用场景是什么?
- 如何用模型编辑修正大语言模型中的知识错误?
- 如何量化评估模型编辑的五大性质?
- 模型编辑局部性如何避免“牵一发而动全身”的问题?
- 知识缓存法(如SERAC)的工作原理是什么?
- 附加参数法(如T-Patcher)如何在不改变原始模型架构的情况下实现编辑?
- 知识缓存法和附加参数法的优缺点有何优缺点?
- ROME方法如何通过因果跟踪实验定位知识存储位置?
- 元学习法(如MEND)如何实现“学习如何编辑”?
- 元学习法的双层优化框架如何设计?
- More …
💯【大模型进阶面 之 模型压缩篇】 你必须要会的高频面题
- 💯 为什么需要对大模型进行压缩和加速?
- 💯 什么是低秩分解?
- 💯 什么是奇异值分解(SVD)?
- 💯 权值共享为什么有效?
- 💯 什么是模型量化?
- 💯 什么是混合精度分解?
- 💯 什么是基于反馈的知识蒸馏?
- 💯 什么是基于特征的知识蒸馏?
- 💯 模型蒸馏的损失函数是什么?
- 💯 描述一下剪枝的基本步骤?
- More …
💯【大模型进阶面 之 分布式训练篇】 你必须要会的高频面题
- PS架构和Ring-AllReduce架构有何不同?
- 什么是张量并行,如何使用集群计算超大矩阵?
- 讲一讲谷歌的GPipe算法?
- 讲一讲微软的PipeDream算法?
- ZeRO1、ZeRO2、ZeRO3分别做了哪些优化?
- 用DeepSpeed进行训练时主要配置哪些参数?
- More …
二、大模型微调面 🎯

💯【大模型微调面 之 SFT篇】 你必须要会的高频面题
- 💯 从零训练一个大模型有哪几个核心步骤?
- 💯 为什么要对LLM做有监督微调(SFT)?
- 💯 如何将一个基础模型训练成一个行业模型?
- 💯 如何准备SFT阶段的训练数据?
- 💯 如何自动生成指令构建SFT的训练数据?
- 💯 LM做有监督微调(SFT)变傻了怎么办?
- 💯 有监督微调(SFT)和人工偏好对齐(RLHF)有何区别?
- More …
💯【大模型微调面 之 PEFT篇】 你必须要会的高频面题
- 💯 全量微调与参数高效微调的区别是什么?
- 💯 什么是轻度微调?轻度微调有哪些常用方法?
- 💯 什么是BitFit微调?
- 💯 分层微调如何设置学习率?
- 💯 什么是适配器微调?适配器微调有哪些优势?
- 💯 讲一讲IA3微调?
- 💯 提示学习(Prompting) 代表方法有哪些?
- 💯 指令微调(Instruct-tuning) 和 提示学习(Prompting)的区别是什么?
- 💯 详细说明LoRA的工作原理及其优势?
- 💯 LoRA存在低秩瓶颈问题,ReLoRA和AdaLoRA分别通过哪些方法改进?
- 💯 动态秩分配(如AdaLoRA)如何根据层的重要性调整秩?
- More …
💯【大模型微调面 之 提示学习篇】 你必须要会的高频面题 查看答案
- 💯 提示学习(Prompting) 代表方法有哪些?
- 💯 前缀微调(Prefix-tining)的核心思想?
- 💯 提示微调(Prompt-tuning)的核心思想?
- 💯 P-tuning 的动机是什么?
- 💯 P-tuning v2 进行了哪些改进?
- 💯 提示微调(Prompt-tuning)与 Prefix-tuning 区别是什么?
- 💯 提示微调(Prompt-tuning)与 fine-tuning 区别是什么?
- More …
💯【大模型微调面 之 RLHF篇】 你必须要会的高频面题
- 💯 RLHF有哪几个核心流程?
- 💯 RLHF与SFT的本质区别是什么?为什么不能只用SFT?
- 💯 什么是人类偏好对齐中的"对齐税"(Alignment Tax)?如何缓解?
- 💯 在强化学习中,基于值函数的和基于策略的的优化方法有何区别?
- 💯 什么是近端策略优化(PPO)?
- 💯 RLHF中的PPO主要分哪些步骤?
- 💯 PPO中的重要性采样(Importance Sampling)如何修正策略差异?
- 💯 DPO如何通过隐式奖励建模规避强化学习阶段?
- 💯 DPO vs PPO:训练效率与性能上限的对比分析?
- 💯 RLHF训练数据的格式是什么样的?
- 💯 如何选择人类偏好对齐训练算法?
- More …
💯【大模型微调面 之 提示工程篇】 你必须要会的高频面题
- 💯 Prompt工程与传统微调的区别是什么?
- 💯 如何规范编写Prompt?
- 💯 上下文学习三种形式(零样本、单样本、少样本)的区别?
- 💯 如何通过预训练数据分布和模型规模优化上下文学习效果?
- 💯 思维链(CoT)的核心思想是什么?
- 💯 按部就班(如 Zero-Shot CoT、Auto-CoT)、三思后行(如 ToT、GoT)、集思广益(如 Self-Consistency)三种 CoT 模式有何异同?
- More …
三、大模型(LLMs)基础面 🎯
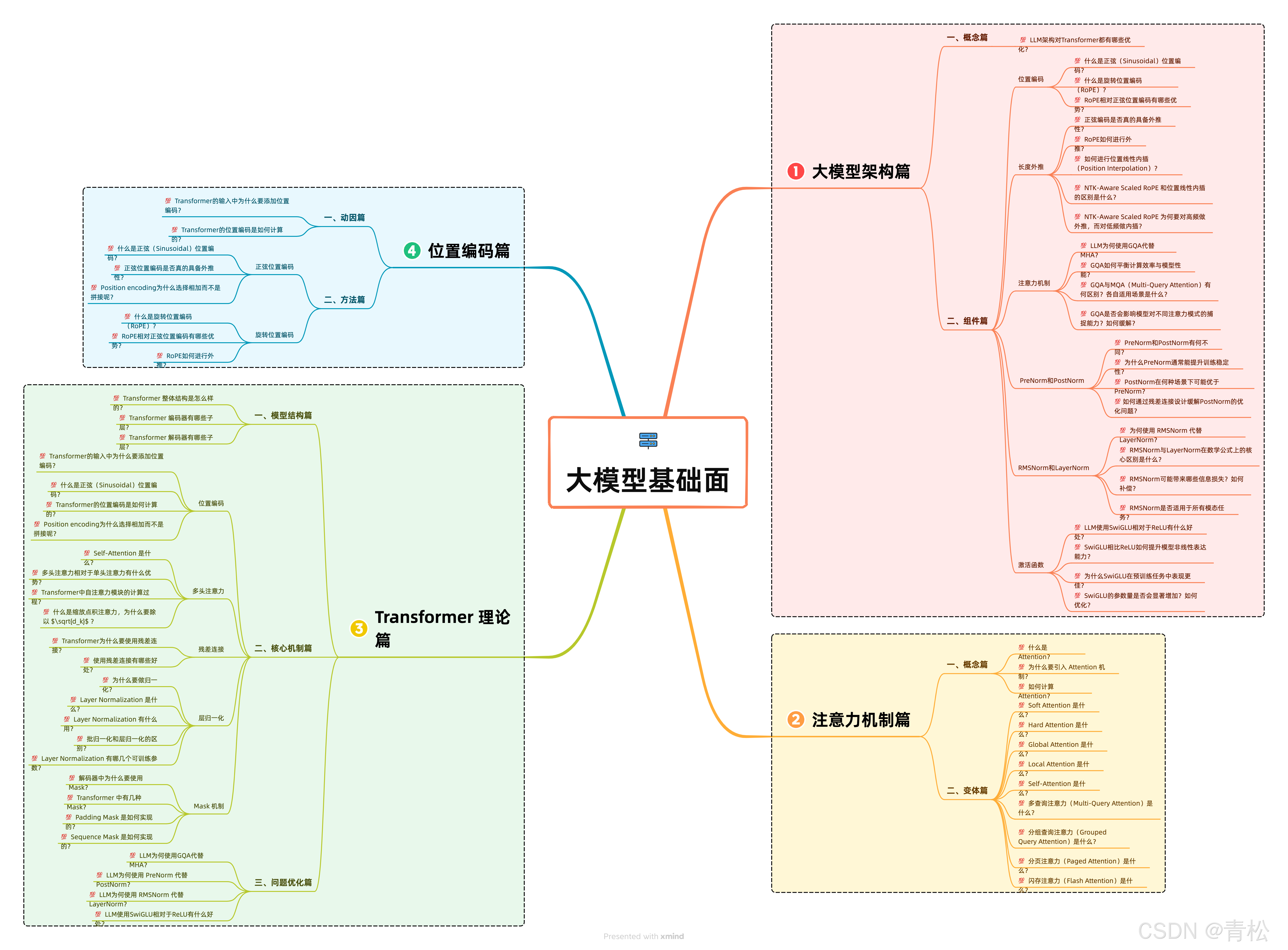
💯【大模型基础面 之 LLM架构篇】 你必须要会的高频面题
- 💯 LLM架构对Transformer都有哪些优化?
- 💯 什么是正弦(Sinusoidal)位置编码?
- 💯 什么是旋转位置编码(RoPE)?
- 💯 RoPE相对正弦位置编码有哪些优势?
- 💯 RoPE如何进行外推?
- 💯 如何进行位置线性内插(Position Interpolation)?
- 💯 NTK-Aware Scaled RoPE 和位置线性内插的区别是什么?
- 💯 PreNorm和PostNorm有何不同?
- 💯 为什么PreNorm通常能提升训练稳定性?
- 💯 为何使用 RMSNorm 代替 LayerNorm?
- 💯 LLM使用SwiGLU相对于ReLU有什么好处?
- 💯 SwiGLU的参数量是否会显著增加?如何优化?
- More …
💯【大模型基础面 之 注意力机制篇】 你必须要会的高频面题
- 💯 为什么要引入 Attention 机制?
- 💯 Soft Attention 是什么?
- 💯 Hard Attention 是什么?
- 💯 Self-Attention 是什么?
- 💯 多查询注意力(Multi-Query Attention)是什么?
- 💯 分组查询注意力(Grouped Query Attention)是什么?
- 💯 分页注意力(Paged Attention)是什么?
- 💯 闪存注意力(Flash Attention)是什么?
- More …
💯【大模型基础面 之 Transformer篇】 你必须要会的高频面题
- 💯 Transformer 整体结构是怎么样的?
- 💯 Transformer的输入中为什么要添加位置编码?
- 💯 Transformer的位置编码是如何计算的?
- 💯 Position encoding为什么选择相加而不是拼接呢?
- 💯 多头注意力相对于单头注意力有什么优势?
- 💯 Transformer中自注意力模块的计算过程?
- 💯 什么是缩放点积注意力,为什么要除以根号d_k?
- 💯 批归一化和层归一化的区别?
- 💯 Layer Normalization 有哪几个可训练参数?
- 💯 Transformer 中有几种 Mask?
- More …
四、NLP 任务实战面 🎯
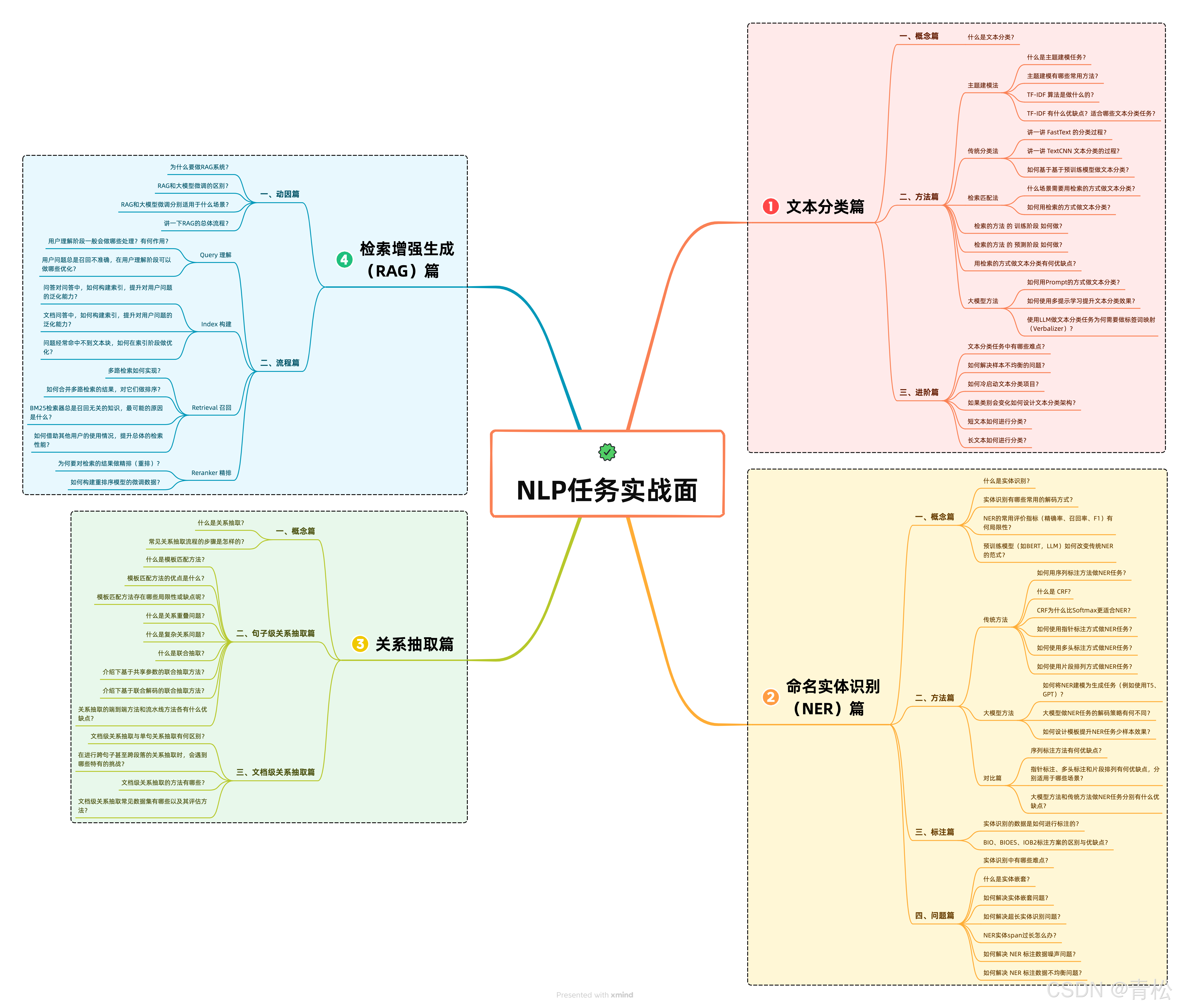
💯【NLP 任务实战面 之 文本分类篇】 你必须要会的高频面题
- 如何用检索的方式做文本分类?
- 如何用Prompt的方式做文本分类?
- 使用LLM做文本分类任务为何需要做标签词映射(Verbalizer)?
- 文本分类任务中有哪些难点?
- 如何解决样本不均衡的问题?
- 如果类别会变化如何设计文本分类架构?
- More …
💯【NLP 任务实战面 之 实体识别篇】 你必须要会的高频面题
- 实体识别中有哪些难点?
- CRF为什么比Softmax更适合NER?
- 如何使用指针标注方式做NER任务?
- 如何使用多头标注方式做NER任务?
- 如何使用片段排列方式做NER任务?
- 实体识别有哪些常用的解码方式?
- 如何解决实体嵌套问题?
- 实体识别的数据是如何进行标注的?
- 如何解决超长实体识别问题?
- More …
💯【NLP 任务实战面 之 关系抽取篇】 你必须要会的高频面题
- 常见关系抽取流程的步骤是怎样的?
- 如何抽取重叠关系和复杂关系?
- 介绍下基于共享参数的联合抽取方法?
- 介绍下基于联合解码的联合抽取方法?
- 关系抽取的端到端方法和流水线方法各有什么优缺点?
- 在进行跨句子甚至跨段落的关系抽取时,会遇到哪些特有的挑战?
💯【NLP 任务实战面 之 RAG篇】 你必须要会的高频面题
- 用户问题总是召回不准确,在用户理解阶段可以做哪些优化?
- 文档问答中,如何构建索引,提升对用户问题的泛化能力?
- 如何合并多路检索的结果,对它们做排序?
- BM25检索器总是召回无关的知识,最可能的原因是什么?
- 如何构建重排序模型的微调数据?
- More …
五、NLP 基础面 🎯
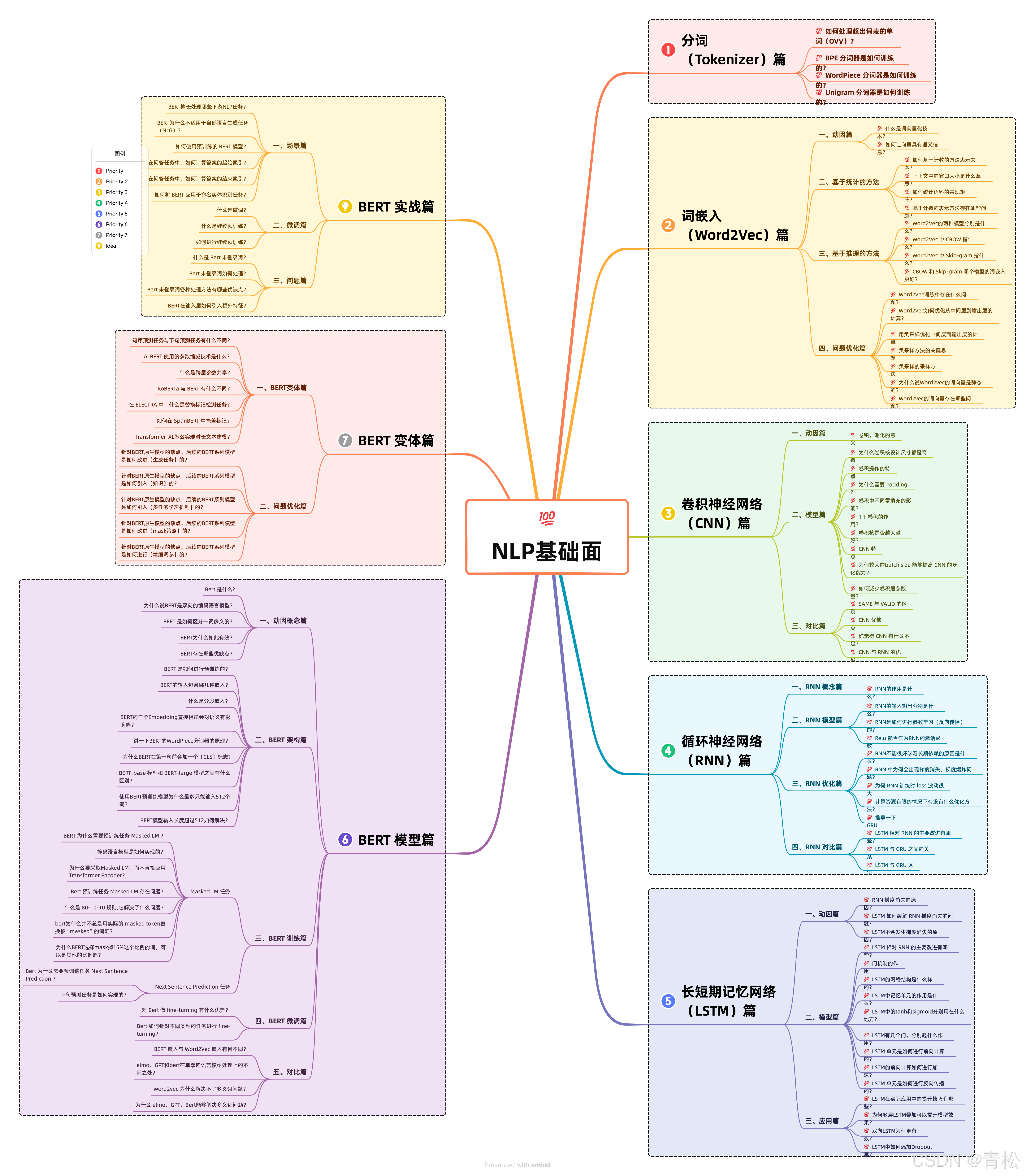
💯【NLP 基础面 之 分词篇】 你必须要会的高频面题
💯【NLP 基础面 之 词嵌入篇】 你必须要会的高频面题
- 基于计数的表示方法存在哪些问题?
- CBOW 和 Skip-gram 哪个模型的词嵌入更好?
- Word2Vec的词向量存在哪些问题?
- 为什么说Word2vec的词向量是静态的?
- Word2Vec如何优化从中间层到输出层的计算?
- 负采样方法的关键思想的关键思想是什么?
- More …
💯【NLP 基础面 之 CNN篇】 你必须要会的高频面题
💯【NLP 基础面 之 RNN篇】 你必须要会的高频面题
💯【NLP 基础面 之 LSTM篇】 你必须要会的高频面题
- LSTM 如何缓解 RNN 梯度消失的问题?
- LSTM中记忆单元的作用是什么?
- LSTM有几个门,分别起什么作用?
- LSTM的前向计算如何进行加速?
- LSTM中的tanh和sigmoid分别用在什么地方?为什么?
- More …
💯【NLP 基础面 之 BERT模型篇】 你必须要会的高频面题
- 为什么说BERT是双向的编码语言模型?
- BERT 是如何区分一词多义的?
- BERT的输入包含哪几种嵌入?
- BERT的三个Embedding直接相加会对语义有影响吗?
- BERT模型输入长度超过512如何解决?
- 什么是 80-10-10 规则,它解决了什么问题?
- BERT 嵌入与 Word2Vec 嵌入有何不同?
- More …
💯【NLP 基础面 之 BERT变体篇】 你必须要会的高频面题
- ALBERT 使用的参数缩减技术是什么?
- RoBERTa 与 BERT 有什么不同?
- 在 ELECTRA 中,什么是替换标记检测任务?
- 如何在 SpanBERT 中掩盖标记?
- Transformer-XL 是怎么实现对长文本建模的?
- More …
💯【NLP 基础面 之 BERT实战篇】 你必须要会的高频面题
- BERT为什么不适用于自然语言生成任务(NLG)?
- 在问答任务中,如何计算答案的起始索引和结束索引?
- 如何将 BERT 应用于命名实体识别任务?
- 如何进行继续预训练?
- Bert 未登录词如何处理?
- BERT在输入层如何引入额外特征?
- More …
六、深度学习面 🎯
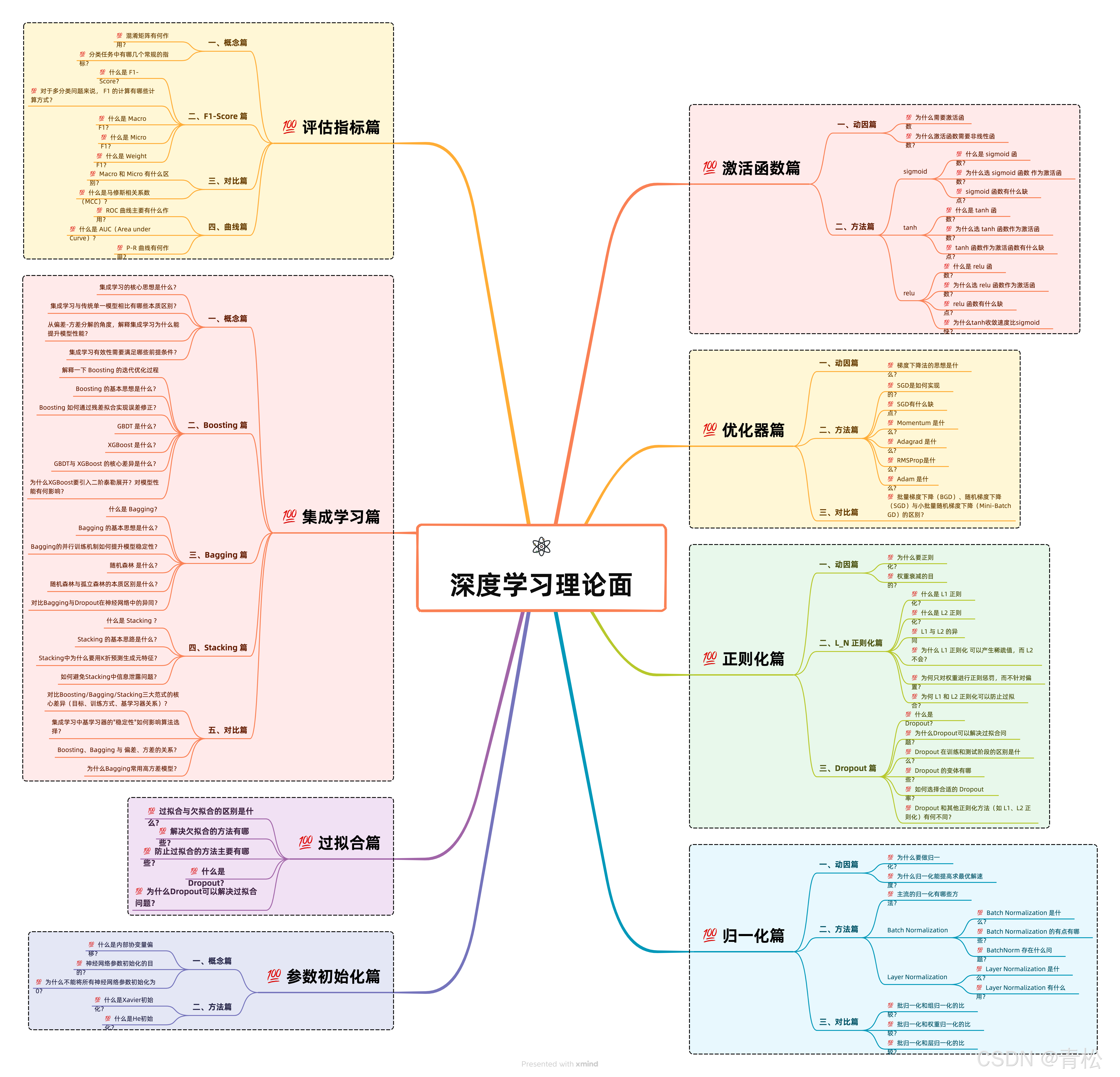
💯【深度学习面 之 激活函数篇】 你必须要会的高频面题
- 💯 为什么激活函数需要非线性函数?
- 💯 sigmoid 函数有什么缺点?
- 💯 tanh 函数作为激活函数有什么缺点?
- 💯 为什么选 relu 函数作为激活函数?
- 💯 为什么tanh收敛速度比sigmoid快?
- 💯 LLM使用SwiGLU相对于ReLU有什么好处?
- 💯 SwiGLU的参数量是否会显著增加?如何优化?
- More …
💯【深度学习面 之 优化器篇】 你必须要会的高频面题
- 💯 SGD是如何实现的?
- 💯 Momentum 是什么?
- 💯 Adagrad 是什么?
- 💯 RMSProp是什么?
- 💯 Adam 是什么?
- 💯 批量梯度下降(BGD)、随机梯度下降(SGD)与小批量随机梯度下降(Mini-Batch GD)的区别?
- More …
💯【深度学习面 之 正则化篇】 你必须要会的高频面题
- 💯 权重衰减的目的?
- 💯 L1 与 L2 的异同?
- 💯 为什么 L1 正则化 可以产生稀疏值,而 L2 不会?
- 💯 为什么Dropout可以解决过拟合问题?
- 💯 Dropout 在训练和测试阶段的区别是什么?
- 💯 如何选择合适的 Dropout 率?
- 💯 Dropout 和其他正则化方法(如 L1、L2 正则化)有何不同?
- More …
💯【深度学习面 之 归一化篇】 你必须要会的高频面题
- 💯 为什么归一化能提高求最优解速度?
- 💯 Batch Normalization 是什么?
- 💯 Layer Normalization 是什么?
- 💯 批归一化和组归一化的比较?
- 💯 批归一化和权重归一化的比较?
- 💯 批归一化和层归一化的比较?
- More …
💯【深度学习面 之 参数初始化篇】 你必须要会的高频面题
💯【深度学习面 之 过拟合篇】 你必须要会的高频面题
💯【深度学习面 之 模型评估篇】 你必须要会的高频面题
- 💯 混淆矩阵有何作用?
- 💯 什么是 F1-Score?
- 💯 什么是 Macro F1?
- 💯 什么是 Micro F1?
- 💯 什么是 Weight F1?
- 💯 Macro 和 Micro 有什么区别?
- 💯 ROC 曲线主要有什么作用?
- 💯 P-R 曲线有何作用?
- More …


















 2606
2606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









