






此为论文泛读
论文的核心在于ensemble + dropout (或者说用dropout的方法代替ensemble)
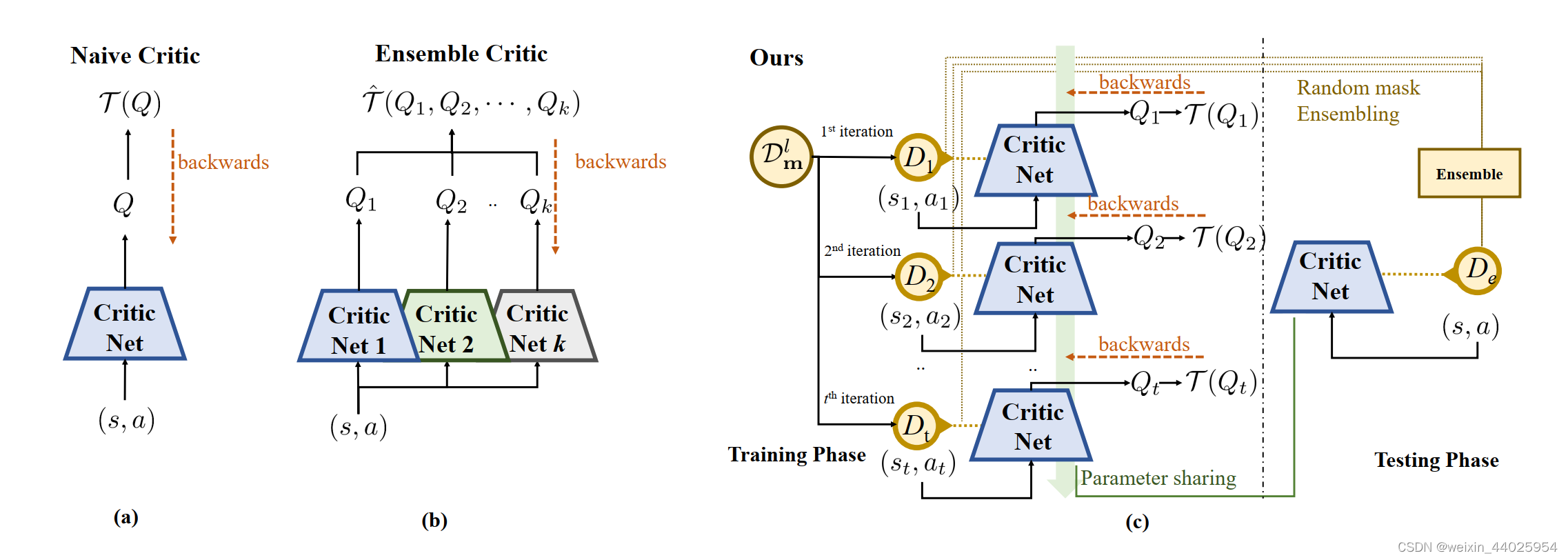
Introduction
文中认为ensemble方法可以让agent更加robust,但是多个网络计算开销太大,因此只需要一个网络即可。同时使用了dropout方法。
文章的contributions:
提出了MEPG,不需要额外的loss和计算开销
进行了理论分析
将MEPG应用在DDPG和SAC上,达到sota
Minimalist Ensemble Policy Gradient
当训练Q时,通过dropout方法,相当于训练了ensemble。训练Policy时,使用完整的Q网络。
具体来说

但是如果直接这样做,会导致贝尔曼方程两侧分布不匹配:
![]()
就是说左边的Q是通过dropout的,右边的Q_target也是dropout,但两个dropout不一样。
为了解决这个问题,提出了minimalist ensemble consistent Bellman update.
其实就是让等式两边的mask一致。
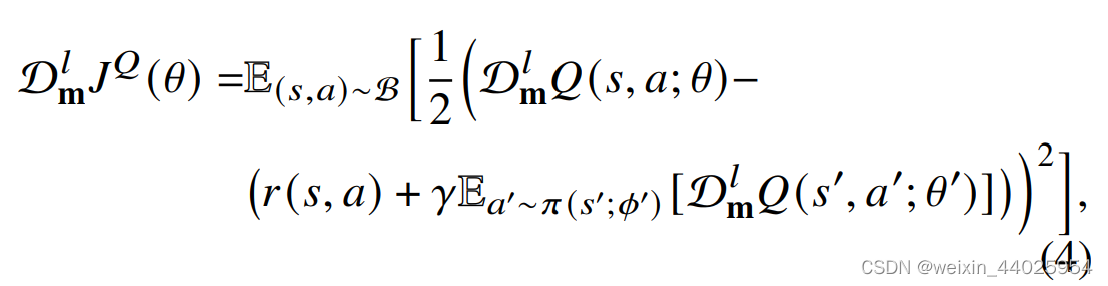
MEPG framework
policy evaluation: minimalist ensemble consistent Bellman update
policy improvement: conventional policy gradient

每次sample的batch相当于训练ensemble的一个net
还有SAC的变种,差不多。
Theoretical Analysis
证明dropout operator能被视为一个deep GP。
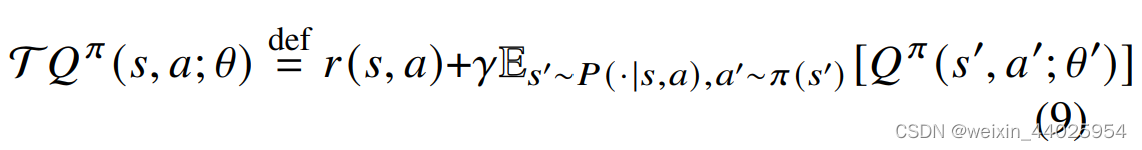
Adam使用了L2正则化,
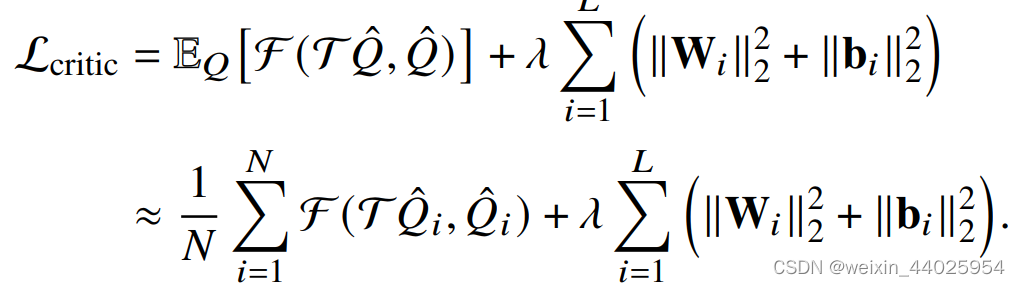
给出一个协方差函数:
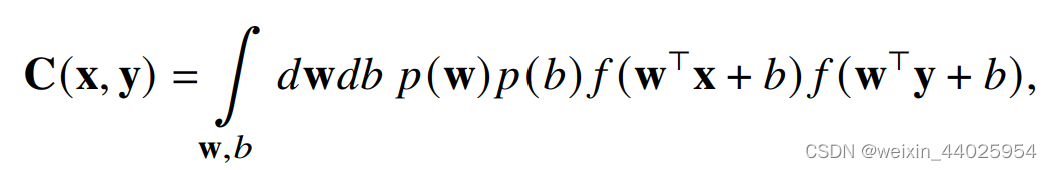
deep GP不太懂,得看看文献
Experiment















 1600
1600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









