







1. 多分类问题:
1.1 路透社数据集加载
路透社数据集由路透社在1986年发布,包含46个不同的主题:某些主题样本较多,某些较少,但是训练集中每个主题都至少含有10个样本。
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
## 与 IMDB 数据集一样,用 num_words=10000 将数据设定为前1w个最常出现的单词。
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/reuters.npz
2110848/2110848 [==============================] - 0s 0us/step
print(len(train_data))
print(train_data)
## 包含 8982 个训练样本
## train_data 存储形式和 IMDB 一样,后续需要做类似的数据预处理。
8982
[list([1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 4579, 1005, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 1245, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12])
list([1, 3267, 699, 3434, 2295, 56, 2, 7511, 9, 56, 3906, 1073, 81, 5, 1198, 57, 366, 737, 132, 20, 4093, 7, 2, 49, 2295, 2, 1037, 3267, 699, 3434, 8, 7, 10, 241, 16, 855, 129, 231, 783, 5, 4, 587, 2295, 2, 2, 775, 7, 48, 34, 191, 44, 35, 1795, 505, 17, 12])
list([1, 53, 12, 284, 15, 14, 272, 26, 53, 959, 32, 818, 15, 14, 272, 26, 39, 684, 70, 11, 14, 12, 3886, 18, 180, 183, 187, 70, 11, 14, 102, 32, 11, 29, 53, 44, 704, 15, 14, 19, 758, 15, 53, 959, 47, 1013, 15, 14, 19, 132, 15, 39, 965, 32, 11, 14, 147, 72, 11, 180, 183, 187, 44, 11, 14, 102, 19, 11, 123, 186, 90, 67, 960, 4, 78, 13, 68, 467, 511, 110, 59, 89, 90, 67, 1390, 55, 2678, 92, 617, 80, 1274, 46, 905, 220, 13, 4, 346, 48, 235, 629, 5, 211, 5, 1118, 7, 2, 81, 5, 187, 11, 15, 9, 1709, 201, 5, 47, 3615, 18, 478, 4514, 5, 1118, 7, 232, 2, 71, 5, 160, 63, 11, 9, 2, 81, 5, 102, 59, 11, 17, 12])
...
list([1, 141, 3890, 387, 81, 8, 16, 1629, 10, 340, 1241, 850, 31, 56, 3890, 691, 9, 1241, 71, 9, 5985, 2, 2, 699, 2, 2, 2, 699, 244, 5945, 4, 49, 8, 4, 656, 850, 33, 2993, 9, 2139, 340, 3371, 1493, 9, 2, 22, 2, 1094, 687, 83, 35, 15, 257, 6, 57, 9190, 7, 4, 5956, 654, 5, 2, 6191, 1371, 4, 49, 8, 16, 369, 646, 6, 1076, 7, 124, 407, 17, 12])
list([1, 53, 46, 957, 26, 14, 74, 132, 26, 39, 46, 258, 3614, 18, 14, 74, 134, 5131, 18, 88, 2321, 72, 11, 14, 1842, 32, 11, 123, 383, 89, 39, 46, 235, 10, 864, 728, 5, 258, 44, 11, 15, 22, 753, 9, 42, 92, 131, 728, 5, 69, 312, 11, 15, 22, 222, 2, 3237, 383, 48, 39, 74, 235, 10, 864, 276, 5, 61, 32, 11, 15, 21, 4, 211, 5, 126, 1072, 42, 92, 131, 46, 19, 352, 11, 15, 22, 710, 220, 9, 42, 92, 131, 276, 5, 59, 61, 11, 15, 22, 10, 455, 7, 1172, 137, 336, 1325, 6, 1532, 142, 971, 6463, 43, 359, 5, 4, 326, 753, 364, 17, 12])
list([1, 227, 2406, 91, 2, 125, 2855, 21, 4, 3976, 76, 7, 4, 757, 481, 3976, 790, 5259, 5654, 9, 111, 149, 8, 7, 10, 76, 223, 51, 4, 417, 8, 1047, 91, 6917, 1688, 340, 7, 194, 9411, 6, 1894, 21, 127, 2151, 2394, 1456, 6, 3034, 4, 329, 433, 7, 65, 87, 1127, 10, 8219, 1475, 290, 9, 21, 567, 16, 1926, 24, 4, 76, 209, 30, 4033, 6655, 5654, 8, 4, 60, 8, 4, 966, 308, 40, 2575, 129, 2, 295, 277, 1071, 9, 24, 286, 2114, 234, 222, 9, 4, 906, 3994, 8519, 114, 5758, 1752, 7, 4, 113, 17, 12])]
print(len(test_data))
print(test_data)
## 包含 2246个测试样本
2246
[list([1, 4, 1378, 2025, 9, 697, 4622, 111, 8, 25, 109, 29, 3650, 11, 150, 244, 364, 33, 30, 30, 1398, 333, 6, 2, 159, 9, 1084, 363, 13, 2, 71, 9, 2, 71, 117, 4, 225, 78, 206, 10, 9, 1214, 8, 4, 270, 5, 2, 7, 748, 48, 9, 2, 7, 207, 1451, 966, 1864, 793, 97, 133, 336, 7, 4, 493, 98, 273, 104, 284, 25, 39, 338, 22, 905, 220, 3465, 644, 59, 20, 6, 119, 61, 11, 15, 58, 579, 26, 10, 67, 7, 4, 738, 98, 43, 88, 333, 722, 12, 20, 6, 19, 746, 35, 15, 10, 9, 1214, 855, 129, 783, 21, 4, 2280, 244, 364, 51, 16, 299, 452, 16, 515, 4, 99, 29, 5, 4, 364, 281, 48, 10, 9, 1214, 23, 644, 47, 20, 324, 27, 56, 2, 2, 5, 192, 510, 17, 12])
list([1, 2768, 283, 122, 7, 4, 89, 544, 463, 29, 798, 748, 40, 85, 306, 28, 19, 59, 11, 82, 84, 22, 10, 1315, 19, 12, 11, 82, 52, 29, 283, 1135, 558, 2, 265, 2, 6607, 8, 6607, 118, 371, 10, 1503, 281, 4, 143, 4811, 760, 50, 2088, 225, 139, 683, 4, 48, 193, 862, 41, 967, 1999, 30, 1086, 36, 8, 28, 602, 19, 32, 11, 82, 5, 4, 89, 544, 463, 41, 30, 6273, 13, 260, 951, 6607, 8, 69, 1749, 18, 82, 41, 30, 306, 3342, 13, 4, 37, 38, 283, 555, 649, 18, 82, 13, 1721, 282, 9, 132, 18, 82, 41, 30, 385, 21, 4, 169, 76, 36, 8, 107, 4, 106, 524, 10, 295, 3825, 2, 2476, 6, 3684, 6940, 4, 1126, 41, 263, 84, 395, 649, 18, 82, 838, 1317, 4, 572, 4, 106, 13, 25, 595, 2445, 40, 85, 7369, 518, 5, 4, 1126, 51, 115, 680, 16, 6, 719, 250, 27, 429, 6607, 8, 6940, 114, 343, 84, 142, 20, 5, 1145, 1538, 4, 65, 494, 474, 27, 69, 445, 11, 1816, 6607, 8, 109, 181, 2768, 2, 62, 1810, 6, 624, 901, 6940, 107, 4, 1126, 34, 524, 4, 6940, 1126, 41, 447, 7, 1427, 13, 69, 251, 18, 872, 876, 1539, 468, 9063, 242, 5, 646, 27, 1888, 169, 283, 87, 9, 10, 2, 260, 182, 122, 678, 306, 13, 4, 99, 216, 7, 89, 544, 64, 85, 2333, 6, 195, 7254, 6337, 268, 609, 4, 195, 41, 1017, 2765, 2, 4, 73, 706, 2, 92, 4, 91, 3917, 36, 8, 51, 144, 23, 1858, 129, 564, 13, 269, 678, 115, 55, 866, 189, 814, 604, 838, 117, 380, 595, 951, 320, 4, 398, 57, 2233, 7411, 269, 274, 87, 6607, 8, 787, 283, 34, 596, 661, 5467, 13, 2362, 1816, 90, 2, 84, 22, 2202, 1816, 54, 748, 6607, 8, 87, 62, 6154, 84, 161, 5, 1208, 480, 4, 2, 416, 6, 538, 122, 115, 55, 129, 1104, 1445, 345, 389, 31, 4, 169, 76, 36, 8, 787, 398, 7, 4, 2, 1507, 64, 8862, 22, 125, 2, 9, 2876, 172, 399, 9, 2, 5206, 9, 2, 122, 36, 8, 6642, 172, 247, 100, 97, 6940, 34, 75, 477, 541, 4, 283, 182, 4, 2, 295, 301, 2, 125, 2, 6607, 8, 77, 57, 445, 283, 1998, 217, 31, 380, 704, 51, 77, 2, 509, 5, 476, 9, 2876, 122, 115, 853, 6, 1061, 52, 10, 2, 2, 1308, 5, 4, 283, 182, 36, 8, 5296, 114, 30, 531, 6, 6376, 9, 2470, 529, 13, 2, 2, 58, 529, 7, 2148, 2, 185, 1028, 240, 5296, 1028, 949, 657, 57, 6, 1046, 283, 36, 8, 6607, 8, 4, 2217, 34, 9177, 13, 10, 4910, 5, 4, 141, 283, 120, 50, 2877, 7, 1049, 43, 10, 181, 283, 734, 115, 55, 3356, 476, 6, 2195, 10, 73, 120, 50, 41, 6877, 169, 87, 6607, 8, 107, 144, 23, 129, 120, 169, 87, 33, 2409, 30, 1888, 1171, 161, 4, 294, 517, 23, 2, 25, 398, 9, 2060, 283, 21, 4, 236, 36, 8, 143, 169, 87, 641, 1569, 28, 69, 61, 376, 514, 90, 1249, 62, 2, 13, 4, 2217, 696, 122, 404, 2936, 22, 134, 6, 187, 514, 10, 1249, 107, 4, 96, 1043, 1569, 13, 10, 184, 28, 61, 376, 514, 268, 680, 4, 320, 6, 154, 6, 69, 160, 514, 10, 1249, 27, 4, 153, 5, 52, 29, 36, 8, 6607, 8, 612, 408, 10, 3133, 283, 76, 27, 1504, 31, 169, 951, 2, 122, 36, 8, 283, 236, 62, 641, 84, 618, 2, 22, 8417, 8409, 9, 274, 7322, 399, 7587, 51, 115, 55, 45, 4044, 31, 4, 490, 558, 36, 8, 224, 2, 115, 57, 85, 1655, 2671, 5, 283, 6, 4, 37, 38, 7, 1797, 185, 77, 4446, 4, 555, 298, 77, 240, 2, 7, 327, 652, 194, 8773, 6233, 34, 2, 5463, 4884, 1297, 6, 240, 260, 458, 87, 6, 134, 514, 10, 1249, 22, 196, 514, 4, 37, 38, 309, 213, 54, 207, 8577, 25, 134, 139, 89, 283, 494, 555, 22, 4, 2217, 6, 2172, 4278, 434, 835, 22, 3598, 3746, 434, 835, 7, 48, 6607, 8, 618, 225, 586, 333, 122, 572, 126, 2768, 1998, 62, 133, 6, 2458, 233, 28, 602, 188, 5, 4, 704, 1998, 62, 45, 885, 281, 4, 48, 193, 760, 36, 8, 115, 680, 78, 58, 109, 95, 6, 1732, 1516, 281, 4, 225, 760, 17, 12])
list([1, 4, 309, 2276, 4759, 5, 2015, 403, 1920, 33, 1575, 1627, 1173, 87, 13, 536, 78, 6490, 399, 7, 2068, 212, 10, 634, 179, 8, 137, 5602, 7, 2775, 33, 30, 1015, 43, 33, 5602, 50, 489, 4, 403, 6, 96, 399, 7, 1953, 3587, 8427, 6603, 4132, 3669, 8180, 7163, 9, 2015, 8, 2, 2, 1683, 791, 5, 740, 220, 707, 13, 4, 634, 634, 54, 1405, 6331, 4, 361, 182, 24, 511, 972, 137, 403, 1920, 529, 6, 96, 3711, 399, 41, 30, 2776, 21, 10, 8491, 2002, 503, 5, 188, 6, 353, 26, 2474, 21, 432, 4, 4234, 23, 3288, 435, 34, 737, 6, 246, 7528, 274, 1173, 1627, 87, 13, 399, 992, 27, 274, 403, 87, 2631, 85, 480, 52, 2015, 403, 820, 13, 10, 139, 9, 115, 949, 609, 890, 819, 6, 812, 593, 7, 576, 7, 194, 2329, 216, 2, 8, 2, 8, 634, 33, 768, 2085, 593, 4, 403, 1920, 185, 9, 107, 403, 87, 2, 107, 1635, 410, 4, 682, 189, 161, 1635, 762, 274, 5319, 115, 30, 43, 389, 410, 4, 682, 107, 1635, 762, 456, 36, 8, 184, 4057, 95, 1854, 107, 403, 87, 302, 2, 8, 129, 100, 756, 7, 3288, 96, 298, 55, 370, 731, 866, 189, 115, 949, 9695, 115, 949, 343, 756, 2, 9, 115, 949, 343, 756, 2509, 36, 8, 17, 12])
...
list([1, 1809, 124, 53, 653, 26, 39, 5439, 18, 14, 5893, 18, 155, 177, 53, 544, 26, 39, 19, 5121, 18, 14, 19, 6382, 18, 280, 3882, 11, 14, 3123, 32, 11, 695, 3614, 47, 11, 14, 3615, 63, 11, 430, 3259, 44, 11, 14, 61, 11, 17, 12])
list([1, 5586, 2, 71, 8, 23, 166, 344, 10, 78, 13, 68, 80, 467, 606, 6, 261, 5, 146, 93, 124, 4, 166, 75, 3603, 2, 5907, 265, 8692, 1251, 2, 297, 1127, 195, 9, 621, 575, 1080, 5907, 7, 378, 104, 421, 648, 20, 5, 4, 49, 2, 8, 1708, 28, 4, 303, 163, 524, 10, 1220, 6, 455, 4, 326, 685, 6, 2, 422, 71, 142, 73, 863, 62, 75, 3603, 6, 4, 326, 166, 2, 34, 1652, 3603, 6, 4, 166, 4, 49, 8, 17, 12])
list([1, 706, 209, 658, 4, 37, 38, 309, 484, 4, 1434, 6, 933, 4, 89, 709, 377, 101, 28, 4, 143, 511, 101, 5, 47, 758, 15, 90, 2388, 7, 809, 6, 444, 2035, 4, 911, 5, 709, 198, 1997, 634, 3644, 3798, 2305, 8, 1486, 6, 674, 480, 10, 990, 309, 4008, 2190, 2305, 1849, 24, 68, 583, 242, 5, 4, 143, 709, 364, 7376, 41, 30, 13, 706, 6, 837, 4, 377, 101, 6, 631, 28, 47, 758, 15, 36, 1413, 107, 4, 377, 101, 62, 47, 758, 15, 634, 114, 713, 888, 1412, 6, 343, 37, 38, 1116, 95, 1136, 269, 43, 1488, 1170, 6, 226, 2, 4, 377, 101, 136, 143, 1032, 4, 89, 709, 377, 101, 1217, 30, 478, 97, 47, 948, 15, 90, 4594, 2, 5853, 41, 30, 13, 706, 6, 455, 4, 465, 474, 6, 837, 634, 6, 2069, 4, 709, 377, 101, 28, 47, 758, 15, 7, 463, 29, 89, 1017, 97, 148, 16, 6, 47, 948, 15, 4, 48, 511, 377, 101, 23, 47, 758, 15, 161, 5, 4, 47, 12, 20, 7424, 7978, 386, 240, 2305, 2634, 24, 10, 181, 1475, 7, 194, 534, 21, 709, 364, 756, 33, 30, 4, 386, 404, 36, 118, 4, 2190, 24, 4, 911, 7, 1116, 23, 24, 4, 37, 38, 377, 101, 1976, 42, 9964, 6, 127, 122, 9, 7609, 1136, 692, 13, 37, 38, 1116, 446, 69, 4, 234, 709, 7614, 1320, 13, 126, 1006, 5, 338, 458, 2305, 8, 4, 1136, 911, 23, 4, 307, 2016, 36, 8, 634, 23, 325, 2863, 4, 820, 9, 129, 2767, 40, 836, 85, 1523, 17, 12])]
print(list(set(train_labels)))
print(list(set(test_labels)))
## 训练和测试标签都有46个类别
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]
1.2 数据集预处理:
和 IMDB 数据集一样,将序列数据向量化,转化为张量。
包括 样本数据向量化 和 标签向量化。
数据向量化
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
## 生成一个 n*10000 的2D张量,对每一行而言,其中值为1.的位置表示该位置对应的单词在句子(sequence)中存在
## 将训练数据和测试数据向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
print(x_test.shape)
print(x_test)
(2246, 10000)
[[0. 1. 1. ... 0. 0. 0.]
[0. 1. 1. ... 0. 0. 0.]
[0. 1. 1. ... 0. 0. 0.]
...
[0. 1. 0. ... 0. 0. 0.]
[0. 1. 1. ... 0. 0. 0.]
[0. 1. 1. ... 0. 0. 0.]]
标签向量化 (one-hot encode)
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
print(one_hot_test_labels.shape)
print(one_hot_test_labels)
(2246, 46)
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 1. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
1.3 构建网络:
与 IDMB 二分类问题相比,多分类问题的关键在于 输出类别增多,输出空间的维度变大(此处由 二分类的2维 变成了 多分类的46维);
因此,如果还是和 IMDB 的网络一样使用16维的中间层 (16个隐藏单元),那么可能无法获得足够的信息,所以需要维度更大的中间层 (此处用 32个隐藏单元,与书中给出的64个隐藏单元不同,因为用64个的话,模型刚开始训练就出现了过拟合现象,可能是硬件升级导致的);
## 定义模型
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, activation="relu", input_shape=(10000,)))
model.add(layers.Dense(32, activation="relu")) ## 中间层包含32个隐藏单元
model.add(layers.Dense(46, activation="softmax")) ## 输出层包含46个隐藏单元,表示每个样本都会输出一个46维的向量,向量中的每个元素代表不同的输出类别
## 最后一层用 softmax 激活,将输出46个不同类别上的概率分布,总和为1.
## 编译模型
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
## 损失函数用的是 分类交叉熵函数 (categorical_crossentropy)
1.4 训练模型:
从训练集中留出 1000 个样本作为验证集,剩下的7982作为训练集
## 预留出验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
## 训练模型
## 训练20次,批量大小为512
import tensorflow as tf
tf.config.run_functions_eagerly(True)
## 该版本的 tensorflow 需要加上这一行,否则报错:
## ValueError: Creating variables on a non-first call to a function decorated with tf.function.
history = model.fit(partial_x_train,
partial_y_train,
batch_size=512,
epochs=20,
validation_data=(x_val, y_val))
Epoch 1/20
16/16 [==============================] - 1s 44ms/step - loss: 2.9901 - accuracy: 0.4608 - val_loss: 2.2753 - val_accuracy: 0.5610
Epoch 2/20
16/16 [==============================] - 1s 32ms/step - loss: 1.9436 - accuracy: 0.6143 - val_loss: 1.7261 - val_accuracy: 0.6250
Epoch 3/20
16/16 [==============================] - 1s 32ms/step - loss: 1.5143 - accuracy: 0.6794 - val_loss: 1.4657 - val_accuracy: 0.6680
Epoch 4/20
16/16 [==============================] - 0s 30ms/step - loss: 1.2668 - accuracy: 0.7226 - val_loss: 1.3284 - val_accuracy: 0.6970
Epoch 5/20
16/16 [==============================] - 0s 30ms/step - loss: 1.0926 - accuracy: 0.7625 - val_loss: 1.2174 - val_accuracy: 0.7380
Epoch 6/20
16/16 [==============================] - 0s 30ms/step - loss: 0.9552 - accuracy: 0.7945 - val_loss: 1.1462 - val_accuracy: 0.7520
Epoch 7/20
16/16 [==============================] - 0s 30ms/step - loss: 0.8368 - accuracy: 0.8191 - val_loss: 1.0916 - val_accuracy: 0.7600
Epoch 8/20
16/16 [==============================] - 0s 30ms/step - loss: 0.7341 - accuracy: 0.8421 - val_loss: 1.0458 - val_accuracy: 0.7740
Epoch 9/20
16/16 [==============================] - 0s 30ms/step - loss: 0.6430 - accuracy: 0.8601 - val_loss: 1.0127 - val_accuracy: 0.7820
Epoch 10/20
16/16 [==============================] - 0s 30ms/step - loss: 0.5613 - accuracy: 0.8748 - val_loss: 0.9958 - val_accuracy: 0.7890
Epoch 11/20
16/16 [==============================] - 0s 30ms/step - loss: 0.4923 - accuracy: 0.8895 - val_loss: 0.9751 - val_accuracy: 0.7970
Epoch 12/20
16/16 [==============================] - 0s 29ms/step - loss: 0.4319 - accuracy: 0.9042 - val_loss: 0.9602 - val_accuracy: 0.8040
Epoch 13/20
16/16 [==============================] - 0s 30ms/step - loss: 0.3787 - accuracy: 0.9163 - val_loss: 0.9512 - val_accuracy: 0.8060
Epoch 14/20
16/16 [==============================] - 0s 30ms/step - loss: 0.3341 - accuracy: 0.9257 - val_loss: 0.9827 - val_accuracy: 0.7990
Epoch 15/20
16/16 [==============================] - 1s 32ms/step - loss: 0.2971 - accuracy: 0.9322 - val_loss: 0.9512 - val_accuracy: 0.8100
Epoch 16/20
16/16 [==============================] - 1s 33ms/step - loss: 0.2663 - accuracy: 0.9391 - val_loss: 0.9596 - val_accuracy: 0.8050
Epoch 17/20
16/16 [==============================] - 1s 32ms/step - loss: 0.2379 - accuracy: 0.9417 - val_loss: 0.9816 - val_accuracy: 0.7990
Epoch 18/20
16/16 [==============================] - 0s 30ms/step - loss: 0.2135 - accuracy: 0.9475 - val_loss: 0.9874 - val_accuracy: 0.7990
Epoch 19/20
16/16 [==============================] - 1s 33ms/step - loss: 0.1969 - accuracy: 0.9504 - val_loss: 0.9853 - val_accuracy: 0.8070
Epoch 20/20
16/16 [==============================] - 1s 32ms/step - loss: 0.1808 - accuracy: 0.9498 - val_loss: 1.0121 - val_accuracy: 0.8020
1.5 可视化监控指标
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
## 训练损失和验证损失
import matplotlib.pyplot as plt
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1, len(loss_values)+1)
plt.plot(epochs, loss_values, "bo", label="Training loss") ## "bo" 表示蓝色圆点
plt.plot(epochs, val_loss_values, "b", label="Validation loss") ## "bo" 表示蓝色实线
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()

## 练精度和验证精度
acc_values = history_dict["accuracy"]
val_acc_values = history_dict["val_accuracy"]
plt.plot(epochs, acc_values, "bo", label="Training accuracy") ## "bo" 表示蓝色圆点
plt.plot(epochs, val_acc_values, "b", label="Validation accuracy") ## "bo" 表示蓝色实线
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
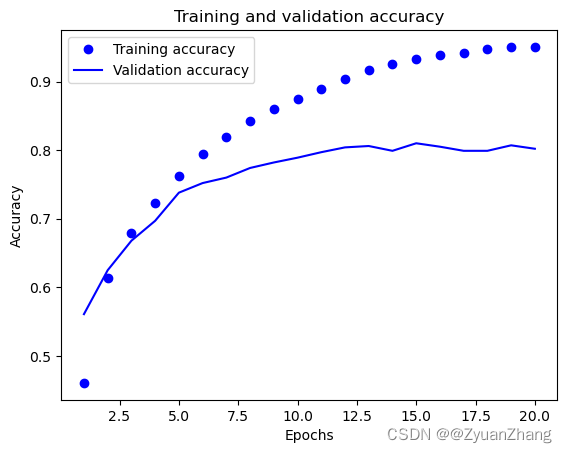
1.6 从头开始训练模型:
模型中间层没有采用书中给的64个隐藏单元 (因为用64个隐藏单元,模型可能刚开始就出现了过拟合。可能是因为硬件升级导致的),所以这里用了32个隐藏单元,最终结果类似于书中给出的结果。
从可视化结果来看,训练次数达到13次是,模型达到最佳效果。所以用 epochs=13 重新训练模型,并在测试集上测试评估。
## 构建模型
model = models.Sequential()
model.add(layers.Dense(32, activation="relu", input_shape=(10000,)))
model.add(layers.Dense(32, activation="relu"))
model.add(layers.Dense(46, activation="softmax"))
## 编译模型
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
## 将 epochs 设置为 13 重新训练模型,并在测试集上做测试
model.fit(partial_x_train,
partial_y_train,
epochs=13,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
Epoch 1/13
1/16 [>.............................] - ETA: 1s - loss: 3.8319 - accuracy: 0.0098
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow_gpu/lib/python3.10/site-packages/tensorflow/python/data/ops/structured_function.py:254: UserWarning: Even though the `tf.config.experimental_run_functions_eagerly` option is set, this option does not apply to tf.data functions. To force eager execution of tf.data functions, please use `tf.data.experimental.enable_debug_mode()`.
warnings.warn(
16/16 [==============================] - 1s 39ms/step - loss: 3.0634 - accuracy: 0.4962 - val_loss: 2.3043 - val_accuracy: 0.6060
Epoch 2/13
16/16 [==============================] - 1s 32ms/step - loss: 1.8882 - accuracy: 0.6600 - val_loss: 1.6528 - val_accuracy: 0.6600
Epoch 3/13
16/16 [==============================] - 1s 33ms/step - loss: 1.4111 - accuracy: 0.7201 - val_loss: 1.3767 - val_accuracy: 0.7130
Epoch 4/13
16/16 [==============================] - 0s 30ms/step - loss: 1.1538 - accuracy: 0.7573 - val_loss: 1.2404 - val_accuracy: 0.7290
Epoch 5/13
16/16 [==============================] - 0s 31ms/step - loss: 0.9805 - accuracy: 0.7831 - val_loss: 1.1452 - val_accuracy: 0.7510
Epoch 6/13
16/16 [==============================] - 0s 30ms/step - loss: 0.8459 - accuracy: 0.8138 - val_loss: 1.0883 - val_accuracy: 0.7630
Epoch 7/13
16/16 [==============================] - 0s 30ms/step - loss: 0.7324 - accuracy: 0.8380 - val_loss: 1.0423 - val_accuracy: 0.7740
Epoch 8/13
16/16 [==============================] - 0s 30ms/step - loss: 0.6342 - accuracy: 0.8602 - val_loss: 1.0112 - val_accuracy: 0.7840
Epoch 9/13
16/16 [==============================] - 1s 33ms/step - loss: 0.5470 - accuracy: 0.8821 - val_loss: 0.9850 - val_accuracy: 0.7980
Epoch 10/13
16/16 [==============================] - 1s 32ms/step - loss: 0.4743 - accuracy: 0.9002 - val_loss: 0.9823 - val_accuracy: 0.8010
Epoch 11/13
16/16 [==============================] - 1s 33ms/step - loss: 0.4105 - accuracy: 0.9131 - val_loss: 0.9727 - val_accuracy: 0.8020
Epoch 12/13
16/16 [==============================] - 1s 34ms/step - loss: 0.3582 - accuracy: 0.9228 - val_loss: 0.9602 - val_accuracy: 0.8100
Epoch 13/13
16/16 [==============================] - 1s 32ms/step - loss: 0.3140 - accuracy: 0.9303 - val_loss: 0.9571 - val_accuracy: 0.8160
71/71 [==============================] - 1s 18ms/step - loss: 1.0241 - accuracy: 0.7805
print(results)
[1.0240509510040283, 0.7804986834526062]
和完全随机地预测相比(预测精度大约19%),模型的预测精度相当好了(大约79%)。
## 随机预测的精度
import copy
test_labels_copy = copy.copy(test_labels) ## 深拷贝 test_labels 一份,得到的备份不受原来的变化的影响
np.random.shuffle(test_labels_copy)
hit_array = np.array(test_labels) == np.array(test_labels_copy) ## 如果相等,赋值为1.
float(np.sum(hit_array)) / len(test_labels)
0.18833481745325023
1.7 用训练好的模型在新数据上进行预测:
predictions = model.predict(x_test) ## 在测试集上进行预测
19/71 [=======>......................] - ETA: 0s
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow_gpu/lib/python3.10/site-packages/tensorflow/python/data/ops/structured_function.py:254: UserWarning: Even though the `tf.config.experimental_run_functions_eagerly` option is set, this option does not apply to tf.data functions. To force eager execution of tf.data functions, please use `tf.data.experimental.enable_debug_mode()`.
warnings.warn(
71/71 [==============================] - 0s 5ms/step
## 每个样本的输出都是长度为46的向量
print(predictions[0].shape)
## 每个样本的输出向量的所有元素之和是1.
print(np.sum(predictions[0]))
## 每个样本中,最大的元素(概率最大)对应的类别就是预测类别
print(np.argmax(predictions[0]))
(46,)
1.0000001
3
1.8 小结:
-
如果标签的编码方式不是one-hot,而是直接转化为整数张量 (标签对应分类编码),(对于整数标签)那么对应的损失函数要换成 “sparse_categorical_crossentropy”;
-
如果有N个类别,最后的输出层应该是大小为 N 的Dense层(隐藏单元个数为 N);
-
对于单标签、多分类问题,网络最后一层应该用 softmax 激活,从而得到 N 个输出类别上的概率分布 (总和为1.);
-
多分类问题的损失函数应该使用 分类交叉熵 (categorical_crossentropy) 函数;















 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









