






0. 说明:
从 Hugging Face 上手动下载预训练的蛋白质语言模型(以ProstT5为例),用模型中的 encoder 部分对蛋白质进行编码,得到 embedding features,用于下游的任务。
【ps. 除了手动下载之外,还可以用其他的下载方式,详情可见 https://zhuanlan.zhihu.com/p/663712983】
【ps. 如果是自动下载,默认下载位置在 ~/.cache/huggingface/】
1. 手动下载与训练模型:
直接从 Hugging Face 网站上下载所有的文件,如下图所示(以 ProstT5 为例,URL = https://huggingface.co/Rostlab/prot_t5_xl_half_uniref50-enc/tree/main):
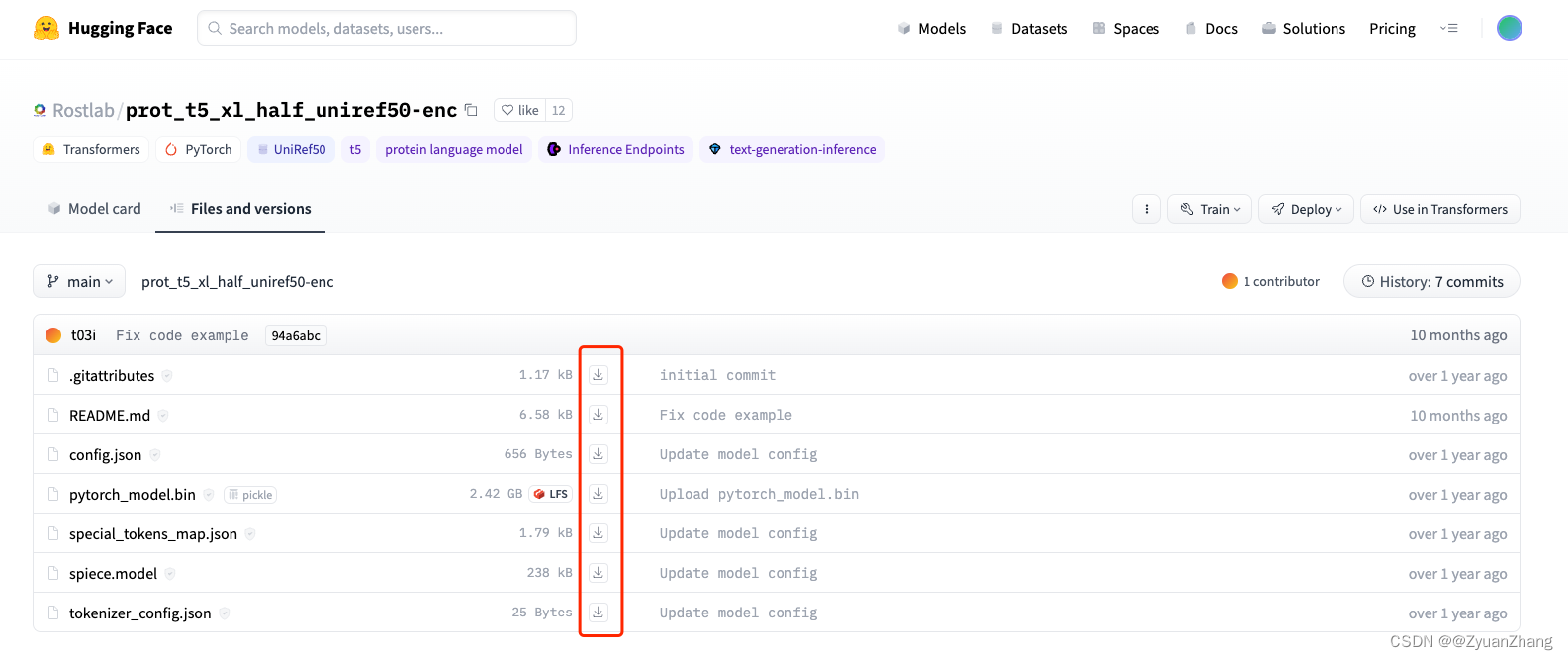
2. 将下载的预训练模型保存到服务器并加载模型:
将上述所有文件放到一个文件夹中,然后上传到服务器上。
加载模型的时候,直接将路径放到T5Tokenizer.from_pretrained()和T5EncoderModel.from_pretrained()中的第一个参数位置即可。
3. 关于模型的使用,可以见 Hugging Face 上提供的案例
PS. 如果有其他问题,会更新本文 . . .
参考:
[1]. https://zhuanlan.zhihu.com/p/663712983

















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









