






文章目录
前置
以下内容均为精炼sheila Teo的提示策略
理论精炼介绍
1. CO-STAR框架
CO-STAR框架简单介绍
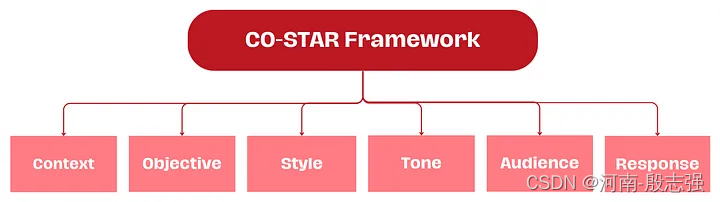
- context: 提供任务的背景资料
- objective: 定义希望LLM执行的任务
- style: 指定希望LLM使用的协作风格
- Tone: 设定LLM回应的态度
- Audience: 确定LLM回答的受众类型
- Response:提供响应的格式
CO-STAR简单示例
# 上下文 #
我想为我公司的新产品做广告。我公司的名字叫Alpha,产品叫Beta,是一款新型的超快吹风机。
# 目标 #
为我创建一个 Facebook 帖子,旨在让人们点击产品链接进行购买。
# 风格 #
遵循为类似产品做广告的成功公司的写作风格,例如戴森。
# 语气 #
有说服力
# 受众 #
我公司在 Facebook 上的受众资料通常是老人。定制您的帖子,以定位这些受众通常在美发产品中寻找的内容。
# 回应 #
Facebook 帖子,保持简洁而有影响力。
2. 创建系统提示【优化LLM问答丰富度】
何为系统提示?
系统提示是附加提示。它是额外的,可以给与LLM对应场景、背景的正确引导。每次提示时,LLM都需要考虑下系统提示中的内容。
系统提示包含内容:
- 任务定义,LLM在聊天过程中必须做什么
- 输出格式,LLM始终需要遵循该输出
- 隔离标识,LLM不回答隔离标识内的内容
系统提示示例
您将使用提供的文本回答问题:
<文本>
[插入文本]
</文本>
<问题>
[插入问题]
</问题>
您将使用以下格式的 JSON 对象进行响应:{“Question”: “Answer”}。
如果文本不包含足够的信息来回答问题,请不要编造信息并给出“NA”的答案。
您只能回答与[插入范围]相关的问题。切勿回答任何与人口统计信息相关的问题,例如年龄、性别和宗教。
3. 使用分隔符分段提示【优化问答准度】
分割符作特殊字符及CO-STAR示例
分隔符是特殊的标记,可帮助 LLM 区分提示的哪些部分应将其视为单个含义单位。 分隔符可以是正常文本不会出现的特殊序列,例###、===、>>>
将 <<<CONVERSATIONS>>>中每个对话的情绪分类为
“正面”或“负面”。给出情感分类,没有任何其他序言文本。
###
对话示例
[特工]:早上好,今天我能帮你什么?
[客户]:这个产品很糟糕,和广告上说的一点都不一样!
[客户]:我非常失望,希望获得全额退款。
[特工]:早上好,今天我能帮你什么吗?
[客户]:嗨,我只是想说,我对你的
产品印象深刻。超出了我的预期!
###
示例输出
阴性
阳性
###
<<<
[特工]:你好!欢迎我们的支持。今天我能帮你什么?
[客户]:您好!我只是想让你知道我收到了我的订单,
这太棒了!
[特工]:很高兴听到!我们很高兴您对购买感到满意。
还有什么我可以帮你的吗?
[客户]:不,就是这样。只是想给出一些积极的反馈。感谢您
的优质服务!
[特工]:您好,感谢您的联系。今天我能帮你什么?
[客户]:我对最近的购买感到非常失望。这根本不是我所期望的。
[特工]:我很遗憾听到这个消息。您能否提供更多详细信息,以便我提供帮助?
[客户]:产品质量差,迟到。我对这次经历真的很
不满意。
>>>
分割符作XML标记
XML 标记是用尖括号括起来的标记,带有开始和结束标记。因为 LLM 已经接受过大量 XML Web 内容的培训,并且已经学会了理解其格式。<>对LLM来说容易理解
使用给出的示例,将以下对话的情绪分为两类之一。给出情感分类,没有任何其他
序言文本。
<class>
正
负
</class>
<example-conversations>
[代理]:早上好,今天我能帮你什么?
[客户]:这个产品很糟糕,和广告上说的一点都不一样!
[客户]:我非常失望,希望获得全额退款。
[特工]:早上好,今天我能帮你什么吗?
[客户]:嗨,我只是想说,我对你的
产品印象深刻。超出了我的预期!
</example-conversations>
<example-classes>
否定
正确
</example-classes>
<conversations>
[特工]:你好!欢迎我们的支持。今天我能帮你什么?
[客户]:您好!我只是想让你知道我收到了我的订单,
这太棒了!
[特工]:很高兴听到!我们很高兴您对购买感到满意。
还有什么我可以帮你的吗?
[客户]:不,就是这样。只是想给出一些积极的反馈。感谢您
的优质服务!
[特工]:您好,感谢您的联系。今天我能帮你什么?
[客户]:我对最近的购买感到非常失望。这根本不是我
所期望的。
[特工]:我很遗憾听到这个消息。您能否提供更多详细信息,以便我
提供帮助?
[客户]:产品质量差,迟到。我对这次经历真的很
不满意。
</conversations>
仅数据的CO-STAR实操
前置分析
- LLM不擅长的数据集分析类型
- 描述统计学:通过均值或方差等度量汇总数字列。
- 相关分析:获得列检精确地相关系数。
- 统计分析:例如假设检验,已确定数据点组之间是否存在统计学上的显著差异。
- 机器学习:对数据集执行预测建模,例如使用线性回归、梯度提升或神经网络。
- LLM擅长的数据集分析类型
- 异常检测:跨列对具有相似特征的数据点进行分组。
- 聚类: 跨列对具有相似特征点的数据点进行分组。
- 跨列关系:识别跨列的组合趋势。
- 文本分析: 基于主题或情绪的分类。
- 趋势分析:识别列内随时间变化的模式、季节性变化或趋势
构建
system prompt:
我希望你扮演数据科学家来分析数据集。不要编造数据集中没有的信息。对于我要求的每个分析,请为我提供准确和明确的答案,而不是向我提供在其他平台上进行分析的代码或说明。
prompt:
#content#
我卖酒。我有一个客户信息数据集:[出生年份、婚姻状况、收入、孩子数量、自上次购买以来的天数、花费金额]。
#############
#objective#
我希望你使用数据集将我的客户聚类到几组,然后给我一些关于如何针对每个组的营销工作的想法。使用此分步过程,不要使用代码:
1. 集群:使用数据集的列对数据集的行进行聚类,使同一集群中的客户具有相似的列值,而不同集群中的客户具有明显不同的列值。确保每行仅属于 1 个集群。
对于找到的每个集群,
2.CLUSTER_INFORMATION:根据数据集列描述聚类。
3. CLUSTER_NAME:解释 [CLUSTER_INFORMATION] 以获取此集群中客户组的短名称。
4. MARKETING_IDEAS:产生想法,向这个客户群推销我的产品。
5. 基本原理:解释为什么 [MARKETING_IDEAS] 对这个客户群是相关和有效的。
#############
# STYLE #
业务分析报告
#############
# TONE #
专业、技术
#############
# Audiouce #
我的商业伙伴。让他们相信您的营销策略是经过深思熟虑的,并有数据充分支持。
#############
# 响应:降价报告 #
<对于 [CLUSTERS] 中的每个集群>
— 客户群:[CLUSTER_NAME]
— 个人资料:[CLUSTER_INFORMATION]
— 营销理念:[MARKETING_IDEAS]
— 基本原理:[基本原理]
<附件>
给出属于每个聚类的行号列表的表格,以便支持您的分析。使用以下表标题:[[CLUSTER_NAME]、行列表]。
#############
# 开始分析 #
如果你明白了,请向我索要我的数据集。
思考
1.何时使用 LLM 分析数据集?
- 归根究底,取决的任务的形式。
- 需要精确数学计算或复杂规则,编程方法优
- 模式识别任务,LLM优(模式识别问题就是用计算的方法根据样本的特征将样本划分到一定的类别中去。模式识别就是通过计算机用数学技术方法来研究模式的自动处理和判读,把环境与客体统称为“模式”)
2.示例对应策略?
- 复杂任务分解为简单步骤
- 引用每个步骤标签
- 格式化LLM响应
- 任务指令与数据集分离

通义千问适合的数据
system prompt:
我希望你扮演文献仿真科学家。对于我要求的每个数据,请为我提供准确和明确的答案。
prompt:
#content#
有一个真实文献数据:<Title: Efficient deep neural networks for classification of COVID-19 based onCT images: Virtualization via software defined radio
Keywords: Computed tomography; ResNet-50; VGG-16; Convolutional neural networks(CNN); Convolutional auto-encoder neural network; (CAENN); COVID-19
Abstract: The novel 2019 coronavirus disease (COVID-19) has infected over 141 million people worldwide since April 20, 2021. More than 200 countries around the world have been affected by the coronavirus pandemic. Screening for COVID-19, we use fast and inexpensive images from computed tomography (CT) scans. In this paper, ResNet-50, VGG-16, convolutional neural network (CNN), convolutional auto-encoder neural network (CAENN), and machine learning (ML) methods are proposed for classifying Chest CT Images of COVID-19. The dataset consists of 1252 CT scans that are positive and 1230 CT scans that are negative for COVID-19 virus. The proposed models have priority over the other models that there is no need of pre-trained networks and data augmentation for them. The classification accuracies of ResNet-50, VGG-16, CNN, and CAENN were obtained 92.24%, 94.07%, 93.84%, and 93.04% respectively. Among ML classifiers, the nearest neighbor (NN) had the highest performance with an accuracy of 94%.
>。
#############
#objective#
我希望你根据content生成仿真数据。使用此分步过程,不要使用代码:
1. title:生成简短的标题。确保每个标题都在50字以内。
2. Abstract: 根据content数据及title生成摘要信息。确保每个摘要都有目的、方法、结果、结论内容。
3. Keywords:根据Abstract生成关键词。确保关键词大于三个,小于六个。
除了上述过程内容,不要生成其他描述性内容。
#############
# STYLE #
文献格式
#############
# Lanuage #
确保生成内容的语言与content保持一致。
#############
# TONE #
科研文献
#############
# 开始分析 #
如果你明白了,请开始回答。
智谱清言适合的样例
<system prompt>
我希望你扮演文献仿真科学家。对于我要求的每个数据,请为我提供准确和明确的答案。
<system prompt/>
<content>
Title: Efficient deep neural networks for classification of COVID-19 based onCT images: Virtualization via software defined radio
Keywords: Computed tomography; ResNet-50; VGG-16; Convolutional neural networks(CNN); Convolutional auto-encoder neural network; (CAENN); COVID-19
Abstract: The novel 2019 coronavirus disease (COVID-19) has infected over 141 million people worldwide since April 20, 2021. More than 200 countries around the world have been affected by the coronavirus pandemic. Screening for COVID-19, we use fast and inexpensive images from computed tomography (CT) scans. In this paper, ResNet-50, VGG-16, convolutional neural network (CNN), convolutional auto-encoder neural network (CAENN), and machine learning (ML) methods are proposed for classifying Chest CT Images of COVID-19. The dataset consists of 1252 CT scans that are positive and 1230 CT scans that are negative for COVID-19 virus. The proposed models have priority over the other models that there is no need of pre-trained networks and data augmentation for them. The classification accuracies of ResNet-50, VGG-16, CNN, and CAENN were obtained 92.24%, 94.07%, 93.84%, and 93.04% respectively. Among ML classifiers, the nearest neighbor (NN) had the highest performance with an accuracy of 94%.
<content/>
<objective>
我希望你根据content生成如下格式数据:
1. title:生成简短的标题。确保每个标题都在50字以内。
2. Abstract: 根据content数据及title生成摘要信息。确保每个摘要都有目的、方法、结果、结论内容。
3. Keywords:根据Abstract生成关键词。确保关键词大于三个,小于六个。
<objective/>
<Lanuage>
确保生成内容的语言与content保持一致。
<Lanuage/>
#############
# 开始分析 #
如果你明白了,请开始回答。除了objective要求的内容,不要生成其他描述性内容。



















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











