






工具介绍
LLM基础结构介绍:https://bbycroft.net/llm
模型内置了nano-gpt、gpt-2、gpt-3,展示gpt这种大模型的基础结构

工具使用
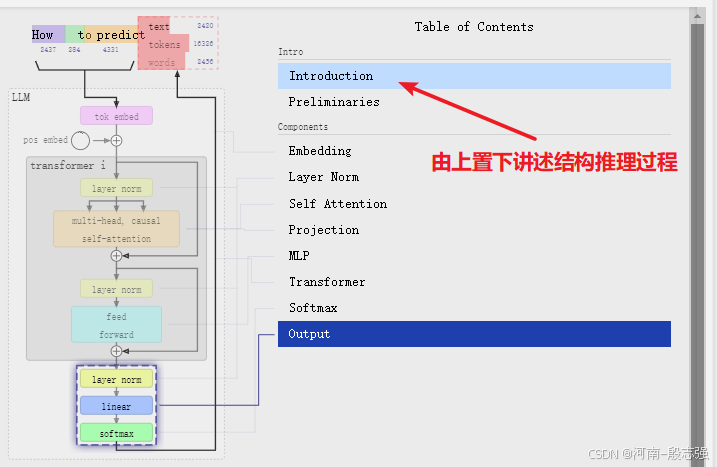
结构解读
LLM有embedding、layer Norm、transformer(self Attention、projection、MLP)、softmax、output组成。下面关注以维度来追踪结构变化。
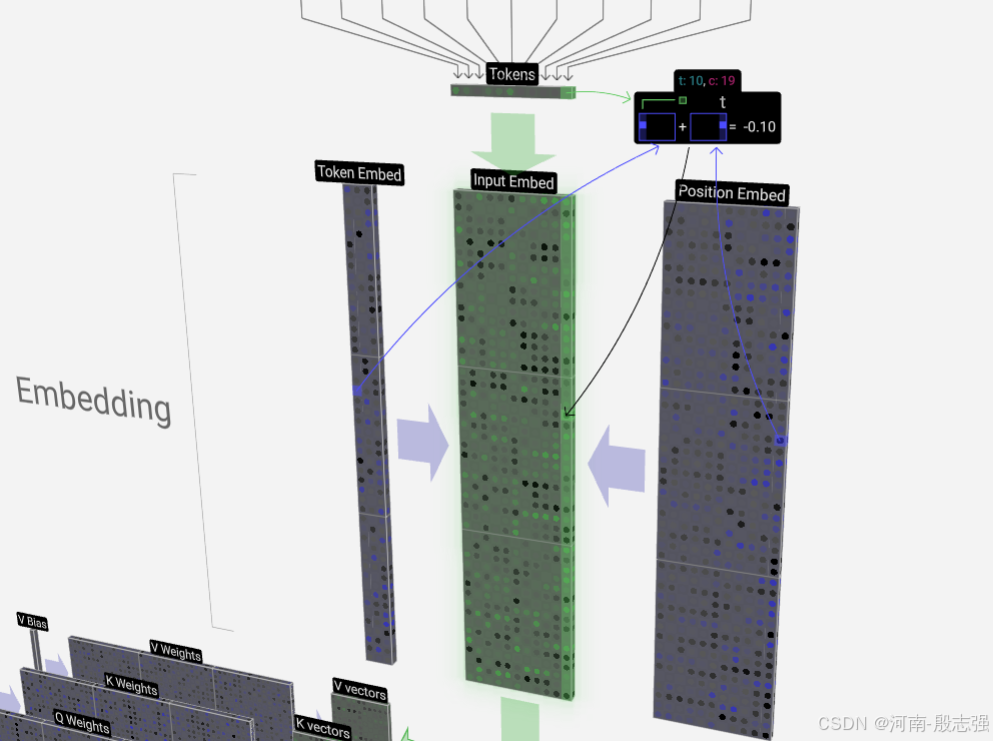
embedding 做这样一件事
将文本转换的token及位置编码组成embedding,此时,input与token一维维度相同。
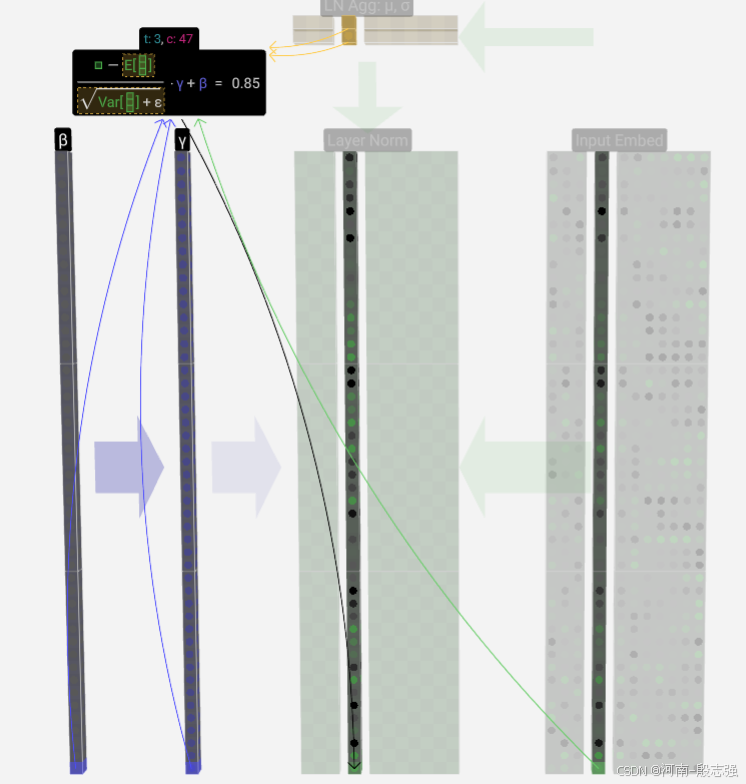
layer Norm 层归一化
将input数值标准化,且通过layer Norm后维度不变,与input相同
self-attention
经典注意力机制公式,此时qkv矩阵二维维度等于lay-norm层
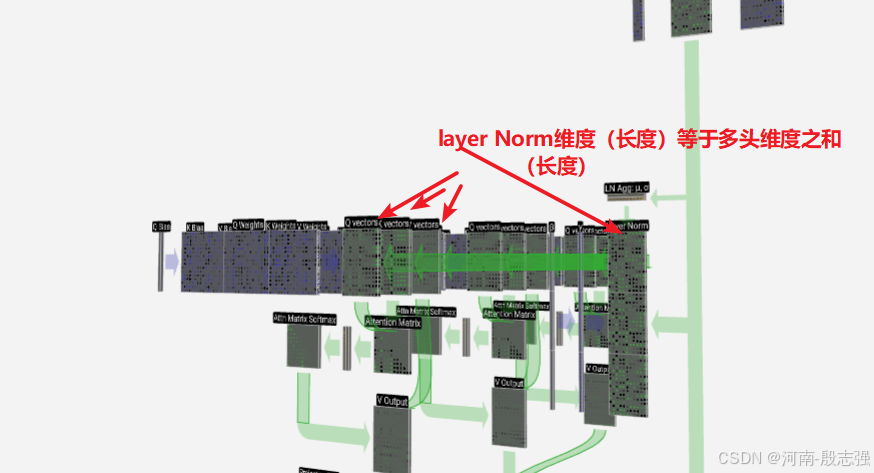
projection
projection将多头信息合并到一个统一的维度中。将多头中的V合并可计算出等于layer Norm的维度。
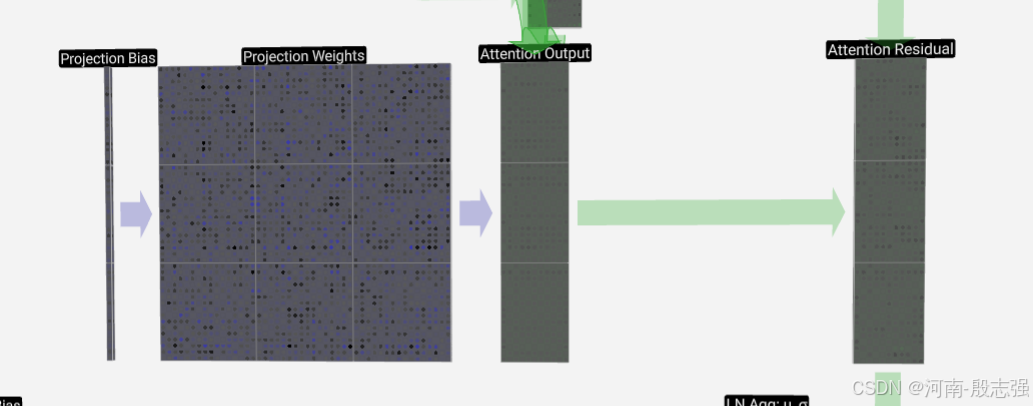
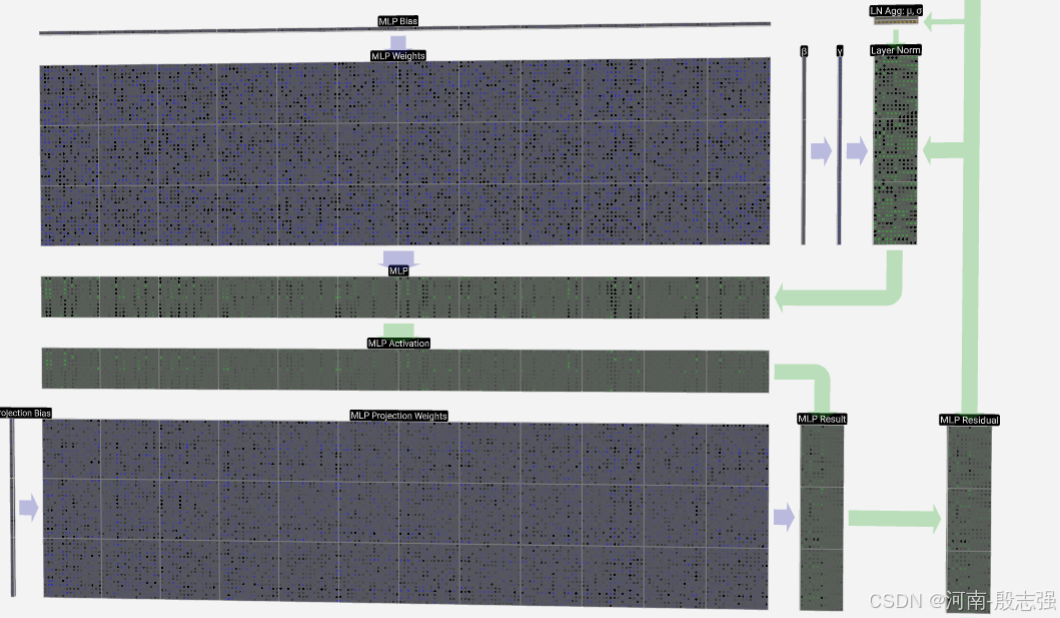
MLP
MLP通过逐层重新组合信息,每层重组的信息经过激活函数放大或抑制后进入下一层数据重组,实现特征提取和知识获取。layer Norm经过mlp激活后维度不变。
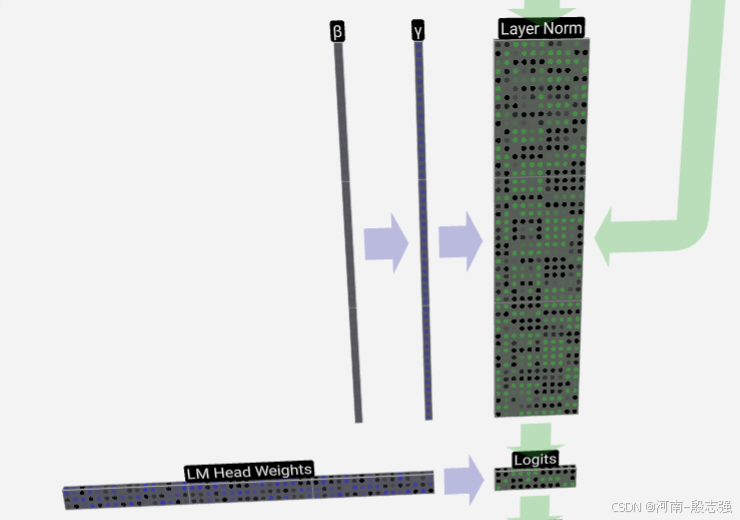
softmax
layer Norm (nm)通过softmax层计算得到一个下一个词的概率分布矩阵,该过程会通过Head weights(kn)将layer Norm降维到表示一个词表维度(k*m)
语义信息获取实例
- Qwen2.5-1.5B模型结构:
- Qwen2ForCausalLM:是模型核心部分,包含Qwen2Model和lm_head。
- Qwen2Model:是模型主体,包含以下组件:
- 嵌入层(embed_tokens):将输入的token IDs转换为嵌入向量,向量维度是1536。
- 自注意力机制层(layers):由28个Qwen2DecoderLayer组成,每个Qwen2DecoderLayer包含:
- 自注意力(self_attn):Qwen2SdpaAttention包含q_proj、k_proj、v_proj、o_proj、rotary_emb等组件,用于捕捉序列中的关键信息。
- 前馈网络(mlp):包含三个线性层(gate_proj、up_proj、down_proj)和一个SiLU激活函数,用于非线性变换。
- 归一化层(input_layernorm、post_attention_layernorm):用于归一化输入和注意力输出,保持梯度稳定。
- lm_head:是一个线性层,将经过Qwen2Model处理后的隐藏状态转换为词汇表大小的logits,用于下一个token的生成。
语义信息的存储位置
-
隐藏状态(Hidden States)
核心位置:各Transformer层的输出隐藏状态
底层(Lower Layers):第1-9层,主要编码词性、句法等基础语义
中层(Middle Layers):第10-19层,处理短语级语义和局部上下文
高层(Upper Layers):第20-28层,存储篇章级语义和抽象概念 -
注意力头(Attention Heads)
分布特征:共32层 × 24头 = 768个独立头
局部聚焦头(如层3的头5):捕捉邻近token的依存关系
全局关联头(如层25的头12):建模长距离语义关联
语义信息的提取方法
- 隐藏状态捕获(PyTorch示例)
import torch
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("Qwen/Qwen2.5-1.5B", output_hidden_states=True)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-1.5B")
inputs = tokenizer("语义信息提取示例", return_tensors="pt")
outputs = model(**inputs)
# 获取各层隐藏状态(Tuple[Tensor])
all_hidden_states = outputs.hidden_states # shape: (num_layers+1, batch, seq_len, hidden_dim)
# 提取第24层语义表示
layer_24_semantic = all_hidden_states[24][0] # shape: (seq_len, 4096)
2. 注意力头分析
python
复制
# 启用注意力输出
model = AutoModel.from_pretrained("Qwen/Qwen2.5-1.5B", output_attentions=True)
outputs = model(**inputs)
# 获取注意力权重(Tuple[Tensor])
all_attentions = outputs.attentions # shape: (num_layers, batch, num_heads, seq_len, seq_len)
# 分析第16层第8头
layer16_head8_attention = all_attentions[15][0,7] # shape: (seq_len, seq_len)
三、语义信息的可视化工具
1. BERTViz
python
复制
from bertviz import head_view
# 生成注意力可视化
head_view(
attentions=all_attentions,
tokens=tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
)
- TensorBoard投影
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
writer.add_embedding(
layer_24_semantic,
metadata=tokenizer.tokenize(inputs["input_ids"][0]),
tag="semantic_layer24"
)
典型应用场景
语义层级 技术指标 应用方向
底层(1-6) 局部语法特征 实体识别、词性标注
中层(7-18) 短语级语义 情感分析、关系抽取
高层(19-32) 全局语义 文本摘要、问答系统



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











