







混淆矩阵是评判模型结果的一种指标,属于模型评估的一部分,常用于评判分类器模型的优劣。

首先要明白两个标志位的含义?第一位表示分类器是否预测正确,第二位表示分类器的预测结果。因此我们应该从后往前看,先看预测结果是Positive(正样本)还是Negative(负样本)?再看分类器有没有预测正确。
TP:True Positive,分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量。
FP:False Positive,分类器预测结果为正样本,实际为负样本,即误报的负样本数量。
TN:True Negative,分类器预测结果为负样本,实际为负样本,即负样本被正确识别的数量。
FN:False Negative,分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
我的理解:以TP为例。TP,字面意思,真正的 正样本。首先一点,只有预测值才有真假一说,真实值是没有真假一说的,或者就认为是真的,因为真实值是已经发生的。所以,TP的T指的是预测值的真假性,此处为T,即P正样本这一预测值是正确的,何为正确,即符合真实值。

以daisy为例,将下图划分为四个区域:
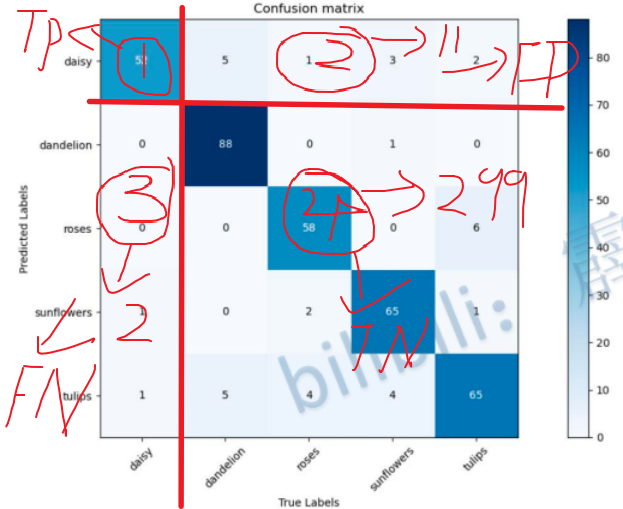
部分代码:
for i in range(self.num_classes):
# 真正例(True Positives,TP),即混淆矩阵中对角线上的值,表示类别i被正确预测为类别i的次数
TP = self.matrix[i, i] # 分类器预测结果为正,实际也为正
# 假正例(False Positives,FP),即混淆矩阵中第i行除了对角线上的所有值的和,表示被错误地预测为类别i的次数
FP = np.sum(self.matrix[i, :]) - TP # 分类器预测结果为正,实际为负
# 假负例(False Negatives,FN),即混淆矩阵中第i列除了对角线上的所有值的和,表示类别i被错误地预测为其他类别的次数
FN = np.sum(self.matrix[:, i]) - TP # 分类器预测结果为负,实际为正
# 真负例(True Negatives,TN),即混淆矩阵中除了第i行和第i列之外的所有值的和,表示其他类别被正确预测为非类别i的次数
TN = np.sum(self.matrix) - TP - FP - FN # 分类器预测结果为负(不是...类),实际为负(不是...类)
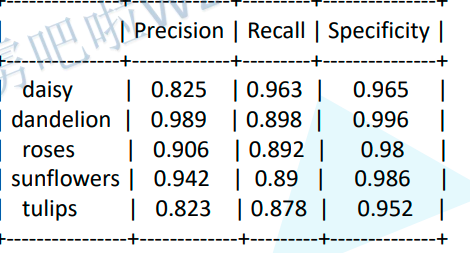
# 真正例占所有被预测为该类别的样本的比例。如果分母(TP + FP)为0(即没有样本被预测为该类),则精度设为0
Precision = round(TP / (TP + FP), 3) if TP + FP != 0 else 0.
# 真正例占所有实际属于该类别的样本的比例。如果分母(TP + FN)为0(即没有实际属于该类的样本),则召回率设为0
Recall = round(TP / (TP + FN), 3) if TP + FN != 0 else 0.
# 真负例占所有被预测为非该类别的样本的比例。如果分母(TN + FP)为0(即没有样本被预测为非该类),则特异性设为0
Specificity = round(TN / (TN + FP), 3) if TN + FP != 0 else 0.














 4495
4495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









