







前言
本期将分享「FC-EF、FC-Siam-conc、FC-Siam-diff」,论文地址https://ieeexplore.ieee.org/abstract/document/8451652。
数据集
此次我们使用的是WHU building dataset,该数据集的前后两个时相影像分别拍摄于2012年与2016年的新西兰,反映的是地震发生后当地的重建情况,更注重不同层次的建筑物变化。
FC-EF、FC-Siam-conc、FC-Siam-diff
FC-EF(Fully Convolutional Early Fusion)是全卷积网络的 早期融合与UNet结合。FC-EF只包括4个最大池化层和4个上采样层,不同于U-Net中的5个。网络的输入是将一对图像中的两张图像在通道维度上进行拼接。
FC-Siam-conc是通过孪生网络共享参数,分别处理变化前后影像,然后在解码层与生成特征进行拼接。
FC-Siam-diff在conc的基础上,对前后影像的特征求差,再与解码层的生成特征进行拼接。 
网络结构
FC-EF
# Rodrigo Caye Daudt
# https://rcdaudt.github.io/
# Daudt, R. C., Le Saux, B., & Boulch, A. "Fully convolutional siamese networks for change detection". In 2018 25th IEEE International Conference on Image Processing (ICIP) (pp. 4063-4067). IEEE.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.padding import ReplicationPad2d
class Unet(nn.Module):
"""EF segmentation network."""
def __init__(self, input_nbr, label_nbr):
super(Unet, self).__init__()
self.input_nbr = input_nbr
self.conv11 = nn.Conv2d(input_nbr, 16, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(16)
self.do11 = nn.Dropout2d(p=0.2)
self.conv12 = nn.Conv2d(16, 16, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(16)
self.do12 = nn.Dropout2d(p=0.2)
self.conv21 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(32)
self.do21 = nn.Dropout2d(p=0.2)
self.conv22 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(32)
self.do22 = nn.Dropout2d(p=0.2)
self.conv31 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(64)
self.do31 = nn.Dropout2d(p=0.2)
self.conv32 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(64)
self.do32 = nn.Dropout2d(p=0.2)
self.conv33 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(64)
self.do33 = nn.Dropout2d(p=0.2)
self.conv41 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(128)
self.do41 = nn.Dropout2d(p=0.2)
self.conv42 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(128)
self.do42 = nn.Dropout2d(p=0.2)
self.conv43 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(128)
self.do43 = nn.Dropout2d(p=0.2)
self.upconv4 = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv43d = nn.ConvTranspose2d(256, 128, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(128)
self.do43d = nn.Dropout2d(p=0.2)
self.conv42d = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(128)
self.do42d = nn.Dropout2d(p=0.2)
self.conv41d = nn.ConvTranspose2d(128, 64, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(64)
self.do41d = nn.Dropout2d(p=0.2)
self.upconv3 = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv33d = nn.ConvTranspose2d(128, 64, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(64)
self.do33d = nn.Dropout2d(p=0.2)
self.conv32d = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(64)
self.do32d = nn.Dropout2d(p=0.2)
self.conv31d = nn.ConvTranspose2d(64, 32, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(32)
self.do31d = nn.Dropout2d(p=0.2)
self.upconv2 = nn.ConvTranspose2d(32, 32, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv22d = nn.ConvTranspose2d(64, 32, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(32)
self.do22d = nn.Dropout2d(p=0.2)
self.conv21d = nn.ConvTranspose2d(32, 16, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(16)
self.do21d = nn.Dropout2d(p=0.2)
self.upconv1 = nn.ConvTranspose2d(16, 16, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv12d = nn.ConvTranspose2d(32, 16, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(16)
self.do12d = nn.Dropout2d(p=0.2)
self.conv11d = nn.ConvTranspose2d(16, label_nbr, kernel_size=3, padding=1)
self.sm = nn.LogSoftmax(dim=1)
def forward(self, x1, x2):
x = torch.cat((x1, x2), 1)
"""Forward method."""
# Stage 1
x11 = self.do11(F.relu(self.bn11(self.conv11(x))))
x12 = self.do12(F.relu(self.bn12(self.conv12(x11))))
x1p = F.max_pool2d(x12, kernel_size=2, stride=2)
# Stage 2
x21 = self.do21(F.relu(self.bn21(self.conv21(x1p))))
x22 = self.do22(F.relu(self.bn22(self.conv22(x21))))
x2p = F.max_pool2d(x22, kernel_size=2, stride=2)
# Stage 3
x31 = self.do31(F.relu(self.bn31(self.conv31(x2p))))
x32 = self.do32(F.relu(self.bn32(self.conv32(x31))))
x33 = self.do33(F.relu(self.bn33(self.conv33(x32))))
x3p = F.max_pool2d(x33, kernel_size=2, stride=2)
# Stage 4
x41 = self.do41(F.relu(self.bn41(self.conv41(x3p))))
x42 = self.do42(F.relu(self.bn42(self.conv42(x41))))
x43 = self.do43(F.relu(self.bn43(self.conv43(x42))))
x4p = F.max_pool2d(x43, kernel_size=2, stride=2)
# Stage 4d
x4d = self.upconv4(x4p)
pad4 = ReplicationPad2d((0, x43.size(3) - x4d.size(3), 0, x43.size(2) - x4d.size(2)))
x4d = torch.cat((pad4(x4d), x43), 1)
x43d = self.do43d(F.relu(self.bn43d(self.conv43d(x4d))))
x42d = self.do42d(F.relu(self.bn42d(self.conv42d(x43d))))
x41d = self.do41d(F.relu(self.bn41d(self.conv41d(x42d))))
# Stage 3d
x3d = self.upconv3(x41d)
pad3 = ReplicationPad2d((0, x33.size(3) - x3d.size(3), 0, x33.size(2) - x3d.size(2)))
x3d = torch.cat((pad3(x3d), x33), 1)
x33d = self.do33d(F.relu(self.bn33d(self.conv33d(x3d))))
x32d = self.do32d(F.relu(self.bn32d(self.conv32d(x33d))))
x31d = self.do31d(F.relu(self.bn31d(self.conv31d(x32d))))
# Stage 2d
x2d = self.upconv2(x31d)
pad2 = ReplicationPad2d((0, x22.size(3) - x2d.size(3), 0, x22.size(2) - x2d.size(2)))
x2d = torch.cat((pad2(x2d), x22), 1)
x22d = self.do22d(F.relu(self.bn22d(self.conv22d(x2d))))
x21d = self.do21d(F.relu(self.bn21d(self.conv21d(x22d))))
# Stage 1d
x1d = self.upconv1(x21d)
pad1 = ReplicationPad2d((0, x12.size(3) - x1d.size(3), 0, x12.size(2) - x1d.size(2)))
x1d = torch.cat((pad1(x1d), x12), 1)
x12d = self.do12d(F.relu(self.bn12d(self.conv12d(x1d))))
x11d = self.conv11d(x12d)
return self.sm(x11d)
FC-Siam-conc
# Rodrigo Caye Daudt
# https://rcdaudt.github.io/
# Daudt, R. C., Le Saux, B., & Boulch, A. "Fully convolutional siamese networks for change detection". In 2018 25th IEEE International Conference on Image Processing (ICIP) (pp. 4063-4067). IEEE.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.padding import ReplicationPad2d
class SiamUnet_conc(nn.Module):
"""SiamUnet_conc segmentation network."""
def __init__(self, input_nbr, label_nbr):
super(SiamUnet_conc, self).__init__()
self.input_nbr = input_nbr
self.conv11 = nn.Conv2d(input_nbr, 16, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(16)
self.do11 = nn.Dropout2d(p=0.2)
self.conv12 = nn.Conv2d(16, 16, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(16)
self.do12 = nn.Dropout2d(p=0.2)
self.conv21 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(32)
self.do21 = nn.Dropout2d(p=0.2)
self.conv22 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(32)
self.do22 = nn.Dropout2d(p=0.2)
self.conv31 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(64)
self.do31 = nn.Dropout2d(p=0.2)
self.conv32 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(64)
self.do32 = nn.Dropout2d(p=0.2)
self.conv33 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(64)
self.do33 = nn.Dropout2d(p=0.2)
self.conv41 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(128)
self.do41 = nn.Dropout2d(p=0.2)
self.conv42 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(128)
self.do42 = nn.Dropout2d(p=0.2)
self.conv43 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(128)
self.do43 = nn.Dropout2d(p=0.2)
self.upconv4 = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv43d = nn.ConvTranspose2d(384, 128, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(128)
self.do43d = nn.Dropout2d(p=0.2)
self.conv42d = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(128)
self.do42d = nn.Dropout2d(p=0.2)
self.conv41d = nn.ConvTranspose2d(128, 64, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(64)
self.do41d = nn.Dropout2d(p=0.2)
self.upconv3 = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv33d = nn.ConvTranspose2d(192, 64, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(64)
self.do33d = nn.Dropout2d(p=0.2)
self.conv32d = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(64)
self.do32d = nn.Dropout2d(p=0.2)
self.conv31d = nn.ConvTranspose2d(64, 32, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(32)
self.do31d = nn.Dropout2d(p=0.2)
self.upconv2 = nn.ConvTranspose2d(32, 32, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv22d = nn.ConvTranspose2d(96, 32, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(32)
self.do22d = nn.Dropout2d(p=0.2)
self.conv21d = nn.ConvTranspose2d(32, 16, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(16)
self.do21d = nn.Dropout2d(p=0.2)
self.upconv1 = nn.ConvTranspose2d(16, 16, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv12d = nn.ConvTranspose2d(48, 16, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(16)
self.do12d = nn.Dropout2d(p=0.2)
self.conv11d = nn.ConvTranspose2d(16, label_nbr, kernel_size=3, padding=1)
self.sm = nn.LogSoftmax(dim=1)
def forward(self, x1, x2):
"""Forward method."""
# Stage 1
x11 = self.do11(F.relu(self.bn11(self.conv11(x1))))
x12_1 = self.do12(F.relu(self.bn12(self.conv12(x11))))
x1p = F.max_pool2d(x12_1, kernel_size=2, stride=2)
# Stage 2
x21 = self.do21(F.relu(self.bn21(self.conv21(x1p))))
x22_1 = self.do22(F.relu(self.bn22(self.conv22(x21))))
x2p = F.max_pool2d(x22_1, kernel_size=2, stride=2)
# Stage 3
x31 = self.do31(F.relu(self.bn31(self.conv31(x2p))))
x32 = self.do32(F.relu(self.bn32(self.conv32(x31))))
x33_1 = self.do33(F.relu(self.bn33(self.conv33(x32))))
x3p = F.max_pool2d(x33_1, kernel_size=2, stride=2)
# Stage 4
x41 = self.do41(F.relu(self.bn41(self.conv41(x3p))))
x42 = self.do42(F.relu(self.bn42(self.conv42(x41))))
x43_1 = self.do43(F.relu(self.bn43(self.conv43(x42))))
x4p = F.max_pool2d(x43_1, kernel_size=2, stride=2)
####################################################
# Stage 1
x11 = self.do11(F.relu(self.bn11(self.conv11(x2))))
x12_2 = self.do12(F.relu(self.bn12(self.conv12(x11))))
x1p = F.max_pool2d(x12_2, kernel_size=2, stride=2)
# Stage 2
x21 = self.do21(F.relu(self.bn21(self.conv21(x1p))))
x22_2 = self.do22(F.relu(self.bn22(self.conv22(x21))))
x2p = F.max_pool2d(x22_2, kernel_size=2, stride=2)
# Stage 3
x31 = self.do31(F.relu(self.bn31(self.conv31(x2p))))
x32 = self.do32(F.relu(self.bn32(self.conv32(x31))))
x33_2 = self.do33(F.relu(self.bn33(self.conv33(x32))))
x3p = F.max_pool2d(x33_2, kernel_size=2, stride=2)
# Stage 4
x41 = self.do41(F.relu(self.bn41(self.conv41(x3p))))
x42 = self.do42(F.relu(self.bn42(self.conv42(x41))))
x43_2 = self.do43(F.relu(self.bn43(self.conv43(x42))))
x4p = F.max_pool2d(x43_2, kernel_size=2, stride=2)
####################################################
# Stage 4d
x4d = self.upconv4(x4p)
pad4 = ReplicationPad2d((0, x43_1.size(3) - x4d.size(3), 0, x43_1.size(2) - x4d.size(2)))
x4d = torch.cat((pad4(x4d), x43_1, x43_2), 1)
x43d = self.do43d(F.relu(self.bn43d(self.conv43d(x4d))))
x42d = self.do42d(F.relu(self.bn42d(self.conv42d(x43d))))
x41d = self.do41d(F.relu(self.bn41d(self.conv41d(x42d))))
# Stage 3d
x3d = self.upconv3(x41d)
pad3 = ReplicationPad2d((0, x33_1.size(3) - x3d.size(3), 0, x33_1.size(2) - x3d.size(2)))
x3d = torch.cat((pad3(x3d), x33_1, x33_2), 1)
x33d = self.do33d(F.relu(self.bn33d(self.conv33d(x3d))))
x32d = self.do32d(F.relu(self.bn32d(self.conv32d(x33d))))
x31d = self.do31d(F.relu(self.bn31d(self.conv31d(x32d))))
# Stage 2d
x2d = self.upconv2(x31d)
pad2 = ReplicationPad2d((0, x22_1.size(3) - x2d.size(3), 0, x22_1.size(2) - x2d.size(2)))
x2d = torch.cat((pad2(x2d), x22_1, x22_2), 1)
x22d = self.do22d(F.relu(self.bn22d(self.conv22d(x2d))))
x21d = self.do21d(F.relu(self.bn21d(self.conv21d(x22d))))
# Stage 1d
x1d = self.upconv1(x21d)
pad1 = ReplicationPad2d((0, x12_1.size(3) - x1d.size(3), 0, x12_1.size(2) - x1d.size(2)))
x1d = torch.cat((pad1(x1d), x12_1, x12_2), 1)
x12d = self.do12d(F.relu(self.bn12d(self.conv12d(x1d))))
x11d = self.conv11d(x12d)
return self.sm(x11d)
FC-Siam-diff
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.padding import ReplicationPad2d
class SiamUnet_diff(nn.Module):
"""SiamUnet_diff segmentation network."""
def __init__(self, input_nbr, label_nbr):
super(SiamUnet_diff, self).__init__()
self.input_nbr = input_nbr
self.conv11 = nn.Conv2d(input_nbr, 16, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(16)
self.do11 = nn.Dropout2d(p=0.2)
self.conv12 = nn.Conv2d(16, 16, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(16)
self.do12 = nn.Dropout2d(p=0.2)
self.conv21 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(32)
self.do21 = nn.Dropout2d(p=0.2)
self.conv22 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(32)
self.do22 = nn.Dropout2d(p=0.2)
self.conv31 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(64)
self.do31 = nn.Dropout2d(p=0.2)
self.conv32 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(64)
self.do32 = nn.Dropout2d(p=0.2)
self.conv33 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(64)
self.do33 = nn.Dropout2d(p=0.2)
self.conv41 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(128)
self.do41 = nn.Dropout2d(p=0.2)
self.conv42 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(128)
self.do42 = nn.Dropout2d(p=0.2)
self.conv43 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(128)
self.do43 = nn.Dropout2d(p=0.2)
self.upconv4 = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv43d = nn.ConvTranspose2d(256, 128, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(128)
self.do43d = nn.Dropout2d(p=0.2)
self.conv42d = nn.ConvTranspose2d(128, 128, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(128)
self.do42d = nn.Dropout2d(p=0.2)
self.conv41d = nn.ConvTranspose2d(128, 64, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(64)
self.do41d = nn.Dropout2d(p=0.2)
self.upconv3 = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv33d = nn.ConvTranspose2d(128, 64, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(64)
self.do33d = nn.Dropout2d(p=0.2)
self.conv32d = nn.ConvTranspose2d(64, 64, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(64)
self.do32d = nn.Dropout2d(p=0.2)
self.conv31d = nn.ConvTranspose2d(64, 32, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(32)
self.do31d = nn.Dropout2d(p=0.2)
self.upconv2 = nn.ConvTranspose2d(32, 32, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv22d = nn.ConvTranspose2d(64, 32, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(32)
self.do22d = nn.Dropout2d(p=0.2)
self.conv21d = nn.ConvTranspose2d(32, 16, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(16)
self.do21d = nn.Dropout2d(p=0.2)
self.upconv1 = nn.ConvTranspose2d(16, 16, kernel_size=3, padding=1, stride=2, output_padding=1)
self.conv12d = nn.ConvTranspose2d(32, 16, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(16)
self.do12d = nn.Dropout2d(p=0.2)
self.conv11d = nn.ConvTranspose2d(16, label_nbr, kernel_size=3, padding=1)
self.sm = nn.Softmax(dim=1)
def forward(self, x1, x2):
"""Forward method."""
# Stage 1
x11 = self.do11(F.relu(self.bn11(self.conv11(x1))))
x12_1 = self.do12(F.relu(self.bn12(self.conv12(x11))))
x1p = F.max_pool2d(x12_1, kernel_size=2, stride=2)
# Stage 2
x21 = self.do21(F.relu(self.bn21(self.conv21(x1p))))
x22_1 = self.do22(F.relu(self.bn22(self.conv22(x21))))
x2p = F.max_pool2d(x22_1, kernel_size=2, stride=2)
# Stage 3
x31 = self.do31(F.relu(self.bn31(self.conv31(x2p))))
x32 = self.do32(F.relu(self.bn32(self.conv32(x31))))
x33_1 = self.do33(F.relu(self.bn33(self.conv33(x32))))
x3p = F.max_pool2d(x33_1, kernel_size=2, stride=2)
# Stage 4
x41 = self.do41(F.relu(self.bn41(self.conv41(x3p))))
x42 = self.do42(F.relu(self.bn42(self.conv42(x41))))
x43_1 = self.do43(F.relu(self.bn43(self.conv43(x42))))
x4p = F.max_pool2d(x43_1, kernel_size=2, stride=2)
####################################################
# Stage 1
x11 = self.do11(F.relu(self.bn11(self.conv11(x2))))
x12_2 = self.do12(F.relu(self.bn12(self.conv12(x11))))
x1p = F.max_pool2d(x12_2, kernel_size=2, stride=2)
# Stage 2
x21 = self.do21(F.relu(self.bn21(self.conv21(x1p))))
x22_2 = self.do22(F.relu(self.bn22(self.conv22(x21))))
x2p = F.max_pool2d(x22_2, kernel_size=2, stride=2)
# Stage 3
x31 = self.do31(F.relu(self.bn31(self.conv31(x2p))))
x32 = self.do32(F.relu(self.bn32(self.conv32(x31))))
x33_2 = self.do33(F.relu(self.bn33(self.conv33(x32))))
x3p = F.max_pool2d(x33_2, kernel_size=2, stride=2)
# Stage 4
x41 = self.do41(F.relu(self.bn41(self.conv41(x3p))))
x42 = self.do42(F.relu(self.bn42(self.conv42(x41))))
x43_2 = self.do43(F.relu(self.bn43(self.conv43(x42))))
x4p = F.max_pool2d(x43_2, kernel_size=2, stride=2)
# Stage 4d
x4d = self.upconv4(x4p)
pad4 = ReplicationPad2d((0, x43_1.size(3) - x4d.size(3), 0, x43_1.size(2) - x4d.size(2)))
x4d = torch.cat((pad4(x4d), torch.abs(x43_1 - x43_2)), 1)
x43d = self.do43d(F.relu(self.bn43d(self.conv43d(x4d))))
x42d = self.do42d(F.relu(self.bn42d(self.conv42d(x43d))))
x41d = self.do41d(F.relu(self.bn41d(self.conv41d(x42d))))
# Stage 3d
x3d = self.upconv3(x41d)
pad3 = ReplicationPad2d((0, x33_1.size(3) - x3d.size(3), 0, x33_1.size(2) - x3d.size(2)))
x3d = torch.cat((pad3(x3d), torch.abs(x33_1 - x33_2)), 1)
x33d = self.do33d(F.relu(self.bn33d(self.conv33d(x3d))))
x32d = self.do32d(F.relu(self.bn32d(self.conv32d(x33d))))
x31d = self.do31d(F.relu(self.bn31d(self.conv31d(x32d))))
# Stage 2d
x2d = self.upconv2(x31d)
pad2 = ReplicationPad2d((0, x22_1.size(3) - x2d.size(3), 0, x22_1.size(2) - x2d.size(2)))
x2d = torch.cat((pad2(x2d), torch.abs(x22_1 - x22_2)), 1)
x22d = self.do22d(F.relu(self.bn22d(self.conv22d(x2d))))
x21d = self.do21d(F.relu(self.bn21d(self.conv21d(x22d))))
# Stage 1d
x1d = self.upconv1(x21d)
pad1 = ReplicationPad2d((0, x12_1.size(3) - x1d.size(3), 0, x12_1.size(2) - x1d.size(2)))
x1d = torch.cat((pad1(x1d), torch.abs(x12_1 - x12_2)), 1)
x12d = self.do12d(F.relu(self.bn12d(self.conv12d(x1d))))
x11d = self.conv11d(x12d)
return self.sm(x11d)
训练变化与测试精度
FC-EF
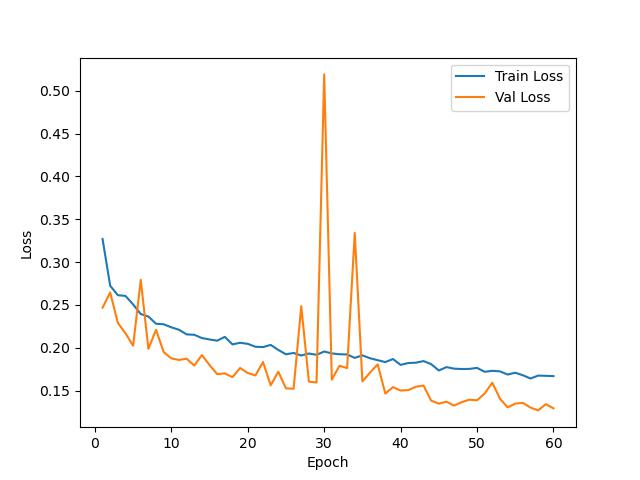

FC-Siam-conc
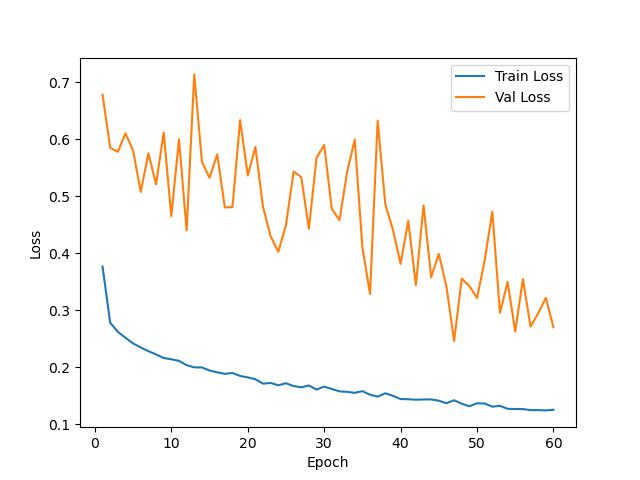

FC-Siam-diff


总结
完整代码与训练结果请加入我们的星球。
「感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的」。
 加入前不要忘了公众号首页领取优惠券哦!
加入前不要忘了公众号首页领取优惠券哦!
往期精彩



本文由 mdnice 多平台发布
















 3260
3260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











