







前言
本期将分享「deeplabv3+网络」,论文地址https://arxiv.org/pdf/1905.02423.pdf。源码地址https://github.com/xiaoyufenfei/LEDNet
数据集
本文选取的是WHU-Building-DataSets。数据集[1]包含了从新西兰基督城的航空图像中提取的超过220,000个独立建筑,图像被分割成了8189个512×512像素的片,其中包含了训练集(130,500个建筑),验证集(14,500个建筑)和测试集(42,000个建筑)。
Deeplab v3+
此次我们使用的模型为deeplabv3+。Deeplabv3+是深度学习领域的一个语义分割模型,由Google的研究人员提出。它是在Deeplabv3的基础上进行改进和扩展的,通过添加一个简单的解码器模块来特别改善物体边界的分割结果。 Deeplabv3+模型的整体架构包括Encoder和Decoder两个部分。Encoder部分采用了带有空洞卷积的DCNN,并采用了空洞空间金字塔池化模块(ASPP)来引入多尺度信息。相比Deeplabv3,Deeplabv3+还引入了Decoder模块,将底层特征与高层特征进一步融合,提升分割边界准确度。 在具体的技术实现上,Deeplabv3+采用了深度可分离卷积,这是一种更快速和更强大的编码器-解码器网络。深度可分离卷积将卷积操作分为两个独立的步骤:首先是逐个输入通道进行卷积操作,然后再将卷积结果合并。这种技术可以有效地减少计算量和参数数量,提高模型的效率和性能。 
网络结构
import math
import os
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
bn_mom = 0.0003
class SeparableConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=1,stride=1,padding=0,dilation=1,bias=False,activate_first=True,inplace=True):
super(SeparableConv2d,self).__init__()
self.relu0 = nn.ReLU(inplace=inplace)
self.depthwise = nn.Conv2d(in_channels,in_channels,kernel_size,stride,padding,dilation,groups=in_channels,bias=bias)
self.bn1 = nn.BatchNorm2d(in_channels, momentum=bn_mom)
self.relu1 = nn.ReLU(inplace=True)
self.pointwise = nn.Conv2d(in_channels,out_channels,1,1,0,1,1,bias=bias)
self.bn2 = nn.BatchNorm2d(out_channels, momentum=bn_mom)
self.relu2 = nn.ReLU(inplace=True)
self.activate_first = activate_first
def forward(self,x):
if self.activate_first:
x = self.relu0(x)
x = self.depthwise(x)
x = self.bn1(x)
if not self.activate_first:
x = self.relu1(x)
x = self.pointwise(x)
x = self.bn2(x)
if not self.activate_first:
x = self.relu2(x)
return x
class Block(nn.Module):
def __init__(self,in_filters,out_filters,strides=1,atrous=None,grow_first=True,activate_first=True,inplace=True):
super(Block, self).__init__()
if atrous == None:
atrous = [1]*3
elif isinstance(atrous, int):
atrous_list = [atrous]*3
atrous = atrous_list
idx = 0
self.head_relu = True
if out_filters != in_filters or strides!=1:
self.skip = nn.Conv2d(in_filters,out_filters,1,stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters, momentum=bn_mom)
self.head_relu = False
else:
self.skip=None
self.hook_layer = None
if grow_first:
filters = out_filters
else:
filters = in_filters
self.sepconv1 = SeparableConv2d(in_filters,filters,3,stride=1,padding=1*atrous[0],dilation=atrous[0],bias=False,activate_first=activate_first,inplace=self.head_relu)
self.sepconv2 = SeparableConv2d(filters,out_filters,3,stride=1,padding=1*atrous[1],dilation=atrous[1],bias=False,activate_first=activate_first)
self.sepconv3 = SeparableConv2d(out_filters,out_filters,3,stride=strides,padding=1*atrous[2],dilation=atrous[2],bias=False,activate_first=activate_first,inplace=inplace)
def forward(self,inp):
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else:
skip = inp
x = self.sepconv1(inp)
x = self.sepconv2(x)
self.hook_layer = x
x = self.sepconv3(x)
x+=skip
return x
class Xception(nn.Module):
"""
Xception optimized for the ImageNet dataset, as specified in
https://arxiv.org/pdf/1610.02357.pdf
"""
def __init__(self, downsample_factor):
""" Constructor
Args:
num_classes: number of classes
"""
super(Xception, self).__init__()
stride_list = None
if downsample_factor == 8:
stride_list = [2,1,1]
elif downsample_factor == 16:
stride_list = [2,2,1]
else:
raise ValueError('xception.py: output stride=%d is not supported.'%os)
self.conv1 = nn.Conv2d(3, 32, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(32, momentum=bn_mom)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32,64,3,1,1,bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=bn_mom)
#do relu here
self.block1=Block(64,128,2)
self.block2=Block(128,256,stride_list[0],inplace=False)
self.block3=Block(256,728,stride_list[1])
rate = 16//downsample_factor
self.block4=Block(728,728,1,atrous=rate)
self.block5=Block(728,728,1,atrous=rate)
self.block6=Block(728,728,1,atrous=rate)
self.block7=Block(728,728,1,atrous=rate)
self.block8=Block(728,728,1,atrous=rate)
self.block9=Block(728,728,1,atrous=rate)
self.block10=Block(728,728,1,atrous=rate)
self.block11=Block(728,728,1,atrous=rate)
self.block12=Block(728,728,1,atrous=rate)
self.block13=Block(728,728,1,atrous=rate)
self.block14=Block(728,728,1,atrous=rate)
self.block15=Block(728,728,1,atrous=rate)
self.block16=Block(728,728,1,atrous=[1*rate,1*rate,1*rate])
self.block17=Block(728,728,1,atrous=[1*rate,1*rate,1*rate])
self.block18=Block(728,728,1,atrous=[1*rate,1*rate,1*rate])
self.block19=Block(728,728,1,atrous=[1*rate,1*rate,1*rate])
self.block20=Block(728,1024,stride_list[2],atrous=rate,grow_first=False)
self.conv3 = SeparableConv2d(1024,1536,3,1,1*rate,dilation=rate,activate_first=False)
self.conv4 = SeparableConv2d(1536,1536,3,1,1*rate,dilation=rate,activate_first=False)
self.conv5 = SeparableConv2d(1536,2048,3,1,1*rate,dilation=rate,activate_first=False)
self.layers = []
#------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#-----------------------------
def forward(self, input):
self.layers = []
x = self.conv1(input)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.block1(x)
x = self.block2(x)
low_featrue_layer = self.block2.hook_layer
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
x = self.block12(x)
x = self.block13(x)
x = self.block14(x)
x = self.block15(x)
x = self.block16(x)
x = self.block17(x)
x = self.block18(x)
x = self.block19(x)
x = self.block20(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
return low_featrue_layer,x
def load_url(url, model_dir='./model_data', map_location=None):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
filename = url.split('/')[-1]
cached_file = os.path.join(model_dir, filename)
if os.path.exists(cached_file):
return torch.load(cached_file, map_location=map_location)
else:
return model_zoo.load_url(url,model_dir=model_dir)
def xception(pretrained=False, downsample_factor=16):
model = Xception(downsample_factor=downsample_factor)
if pretrained:
model.load_state_dict(load_url('https://github.com/bubbliiiing/deeplabv3-plus-pytorch/releases/download/v1.0/xception_pytorch_imagenet.pth'), strict=False)
return model
#-----------------------------------------#
# ASPP特征提取模块
# 利用不同膨胀率的膨胀卷积进行特征提取
#-----------------------------------------#
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6*rate, dilation=6*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12*rate, dilation=12*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18*rate, dilation=18*rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch5_conv = nn.Conv2d(dim_in, dim_out, 1, 1, 0,bias=True)
self.branch5_bn = nn.BatchNorm2d(dim_out, momentum=bn_mom)
self.branch5_relu = nn.ReLU(inplace=True)
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out*5, dim_out, 1, 1, padding=0,bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
#-----------------------------------------#
# 一共五个分支
#-----------------------------------------#
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
#-----------------------------------------#
# 第五个分支,全局平均池化+卷积
#-----------------------------------------#
global_feature = torch.mean(x,2,True)
global_feature = torch.mean(global_feature,3,True)
global_feature = self.branch5_conv(global_feature)
global_feature = self.branch5_bn(global_feature)
global_feature = self.branch5_relu(global_feature)
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
#-----------------------------------------#
# 将五个分支的内容堆叠起来
# 然后1x1卷积整合特征。
#-----------------------------------------#
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
class DeepLab(nn.Module):
def __init__(self, num_classes, backbone="xception", pretrained=False, downsample_factor=16):
super(DeepLab, self).__init__()
#----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,256]
# 主干部分 [30,30,2048]
#----------------------------------#
self.backbone = xception(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 2048
low_level_channels = 256
#-----------------------------------------#
# ASPP特征提取模块
# 利用不同膨胀率的膨胀卷积进行特征提取
#-----------------------------------------#
self.aspp = ASPP(dim_in=in_channels, dim_out=256, rate=16//downsample_factor)
#----------------------------------#
# 浅层特征边
#----------------------------------#
self.shortcut_conv = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True)
)
self.cat_conv = nn.Sequential(
nn.Conv2d(48+256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(256, num_classes, 1, stride=1)
def forward(self, x):
H, W = x.size(2), x.size(3)
#-----------------------------------------#
# 获得两个特征层
# low_level_features: 浅层特征-进行卷积处理
# x : 主干部分-利用ASPP结构进行加强特征提取
#-----------------------------------------#
low_level_features, x = self.backbone(x)
x = self.aspp(x)
low_level_features = self.shortcut_conv(low_level_features)
#-----------------------------------------#
# 将加强特征边上采样
# 与浅层特征堆叠后利用卷积进行特征提取
#-----------------------------------------#
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)), mode='bilinear', align_corners=True)
x = self.cat_conv(torch.cat((x, low_level_features), dim=1))
x = self.cls_conv(x)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
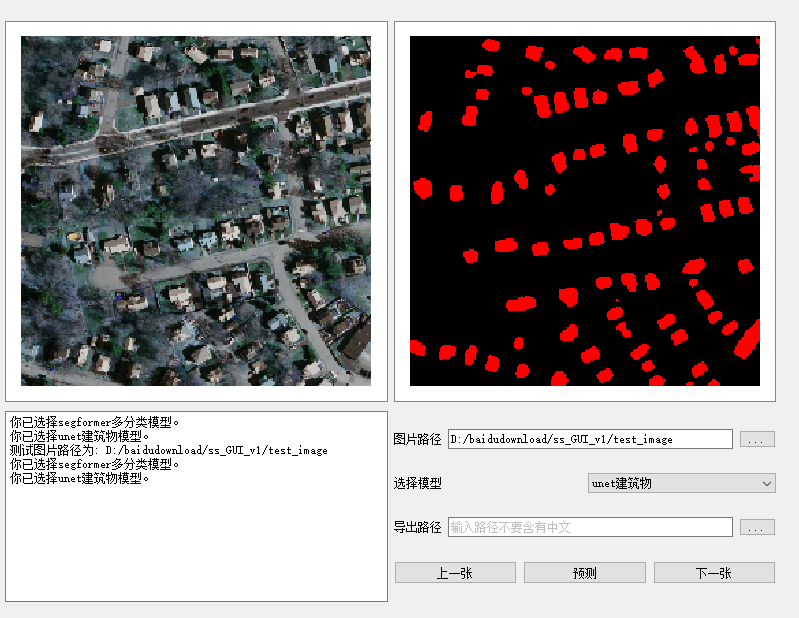
测试结果
结语
「完整代码与训练结果请加入我们的星球。」
「感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的」。
 「加入前不要忘了在公众号首页领取优惠券哦!」
「加入前不要忘了在公众号首页领取优惠券哦!」
往期精彩
WHU-Building-DataSets: https://study.rsgis.whu.edu.cn/pages/download/building_dataset.html
本文由 mdnice 多平台发布
















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











