






1.机器学习的一些概念:
1.1有监督学习:
从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标。训练集中的目标是由人标注的。监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优表示某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统(模型)。
1.2无监督学习
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情。非监督学习有两种思路。第一种思路是在指导Agent时不为其指定明确分类,而是在成功时,采用某种形式的激励制度。需要注意的是,这类训练通常会置于决策问题的框架里,因为它的目标不是为了产生一个分类系统,而是做出最大回报的决定,这种思路很好的概括了现实世界,agent可以对正确的行为做出激励,而对错误行为做出惩罚。
无监督学习的方法分为两大类:
(1) 一类为基于概率密度函数估计的直接方法:指设法找到各类别在特征空间的分布参数,再进行分类。
(2) 另一类是称为基于样本间相似性度量的简洁聚类方法:其原理是设法定出不同类别的核心或初始内核,然后依据样本与核心之间的相似性度量将样本聚集成不同的类别。
利用聚类结果,可以提取数据集中隐藏信息,对未来数据进行分类和预测。应用于数据挖掘,模式识别,图像处理等。
PCA和很多deep learning算法都属于无监督学习。
1.3泛化能力
泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力
1.4过拟合欠拟合(方差和偏差以及各自的解决办法)
过拟合通常可以理解为,模型的复杂度要高于实际的问题,所以就会导致模型死记硬背的记住,而没有理解背后的规律。就比如说人脑要比唐诗复杂得多,即使不理解内容,我们也能背下来,但是理解了内容和写法对于我们理解记忆其他唐诗有好处,如果死记硬背那么就仅仅记住了而已。
避免过拟合的方法有很多:(1)尽量减少特征的数量、(2)early stopping、(3)数据集扩增、(4)dropout、(5)正则化包括L1、L2等
欠拟合(under-fitting)是和过拟合相对的现象,可以说是模型的复杂度较低,没法很好的学习到数据背后的规律。就好像开普勒在总结天体运行规律之前,他的老师第谷记录了很多的运行数据,但是都没法用数据去解释天体运行的规律并预测,这就是在天体运行数据上,人们一直处于欠拟合的状态,只知道记录过的过去是这样运行的,但是不知道道理是什么。
解决欠拟合可以从寻找更好的特征(具有代表性的)和使用更多的特征(增大输入向量的维度)。具体的方法:1、添加更多的特征项(比如上下文特征、位置特征等);2、添加多项式特征(例如将线性模型通过添加二次项或者三次项使模型泛化能力更强);3、减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
1.5交叉验证:
折交叉验证将原始数据集随机划分为 k个相同大小的子集,并进行 k 轮验证。每一轮验证都选择一个子集作为验证集,而将剩余的k-1个子样本用作训练集。由于每一轮中选择的验证集都互不相同,每一轮验证得到的结果也是不同的,K个结果的均值就是对泛化性能的最终估计值。
K折价差验证一个特例是K等于原始数据集的容量N,此时每一轮中只有一个样本被用做测试,不同轮次中的村联机则几乎完全一致。这个特例成为留一法。留一法得到的是关于真实误差的近似无偏的估计,其结果太长被认为较为准确。但它的缺点是需要训练的模型数量和原始数据集的样本容量是相等的,当数据量较大时,使用留一法无疑会带来庞大的计算开销。
2.线性回归的原理
对于给定的训练集{(x1, y1), (x2, y2), (x3, y3)…(xn, yn)}, 试图通过学习,找到最佳w, b的取值, 使得训练集上的数据能够符合或者近似方程Y = WX +b(这个就是我们的模型).
3. 线性回归损失函数、代价函数、目标函数
3.1线性回归损失函数(代价函数):
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parameteric estimation) ,在宏观经济学中被用于风险管理(risk mangement)和决策 ,在控制理论中被应用于最优控制理论(optimal control theory)。
3.2目标函数:
目标函数:优化的目标,可以是“损失函数”或者“损失函数+正则项”,分为经验风险最小化,结构风险最小化。就是代价函数 + 正则化项。
4. 优化方法(梯度下降法、牛顿法、拟牛顿法等)
4.1梯度下降法:
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:

梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。
在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
4.2牛顿法:
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
具体步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ’ (x0)(这里f ’ 表示函数 f 的导数)。然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和 x 轴的交点的x坐标,也就是求如下方程的解:
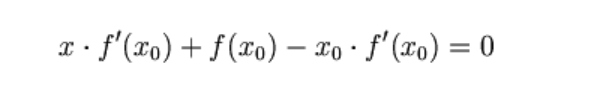
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
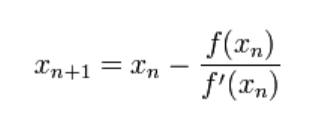
已经证明,如果f ’ 是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f ’ (x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。
4.3拟牛顿法
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型: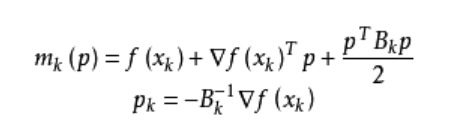
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:
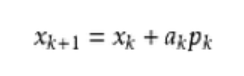
其中我们要求步长ak 满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hesse矩阵Bk 代替真实的Hesse矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk 的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:
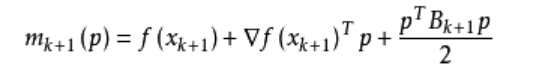
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求
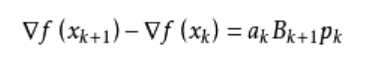
从而得到
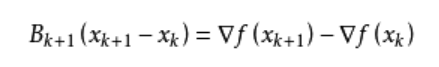
这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
5、线性回归的评估指标
均方误差(MSE)
MSE (Mean Squared Error)叫做均方误差。看公式

这里的y是测试集上的。
用 真实值-预测值 然后平方之后求和平均。
猛着看一下这个公式是不是觉得眼熟,这不就是线性回归的损失函数嘛!!! 对,在线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值不就好了嘛。简单直观暴力!
均方根误差(RMSE)
RMSE(Root Mean Squard Error)均方根误差。

这不就是MSE开个根号么。有意义么?其实实质是一样的。只不过用于数据更好的描述。
例如:要做房价预测,每平方是万元(真贵),我们预测结果也是万元。那么差值的平方单位应该是 千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是 多少千万?。。。。。。于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的可,在描述模型的时候就说,我们模型的误差是多少万元。
MAE
MAE(平均绝对误差)

不用解释了吧。
R Squared
上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价 那么误差单位就是万元。数子可能是3,4,5之类的。那么预测身高就可能是0.1,0.6之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。
看看分类算法的衡量标准就是正确率,而正确率又在0~1之间,最高百分之百。最低0。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢?答案是有的。
那就是R Squared也就R方

6.sklearn参数详解:
sklearn.neighbors.KNeighborsClassifier
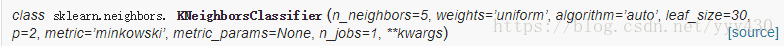
n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
algorithm:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
leaf_size:默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。
p:距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
metric_params:距离公式的其他关键参数,这个可以不管,使用默认的None即可。
n_jobs:并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









