









操作环境:WSL - Oracle Linux + RTX 4050 Laptop edition
渣渣笔记本实在是跑不了更大模型了😂
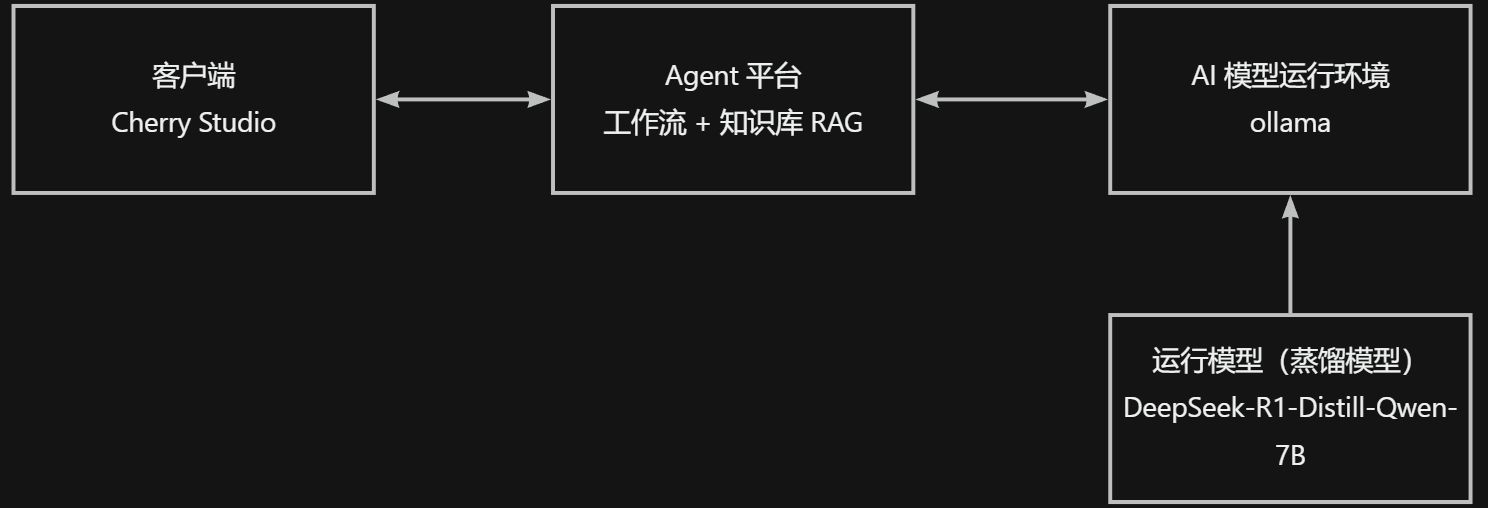
整体架构
WSL 配置显卡加速环境
总体流程
安装教程:https://zhuanlan.zhihu.com/p/681092042
总体流程:

- 优化 WSL 系统配置:配置更大的内存、禁用 SWAP 缓存
- 安装 N 卡驱动 nvidia-smi
- 安装 CUDA 驱动:CUDA Toolkit
- 安装 cudnn 加速库:cudnn
相关软件的含义和区别

WSL 系统优化
实测时发现,由于 WSL 默认参数配置的内存太小,经常会启用 SWAP 内存(用硬盘空间充当虚拟内存),导致硬盘占用 100% 爆炸
因此调整 WSL 配置
参考资料:https://zhuanlan.zhihu.com/p/704210605
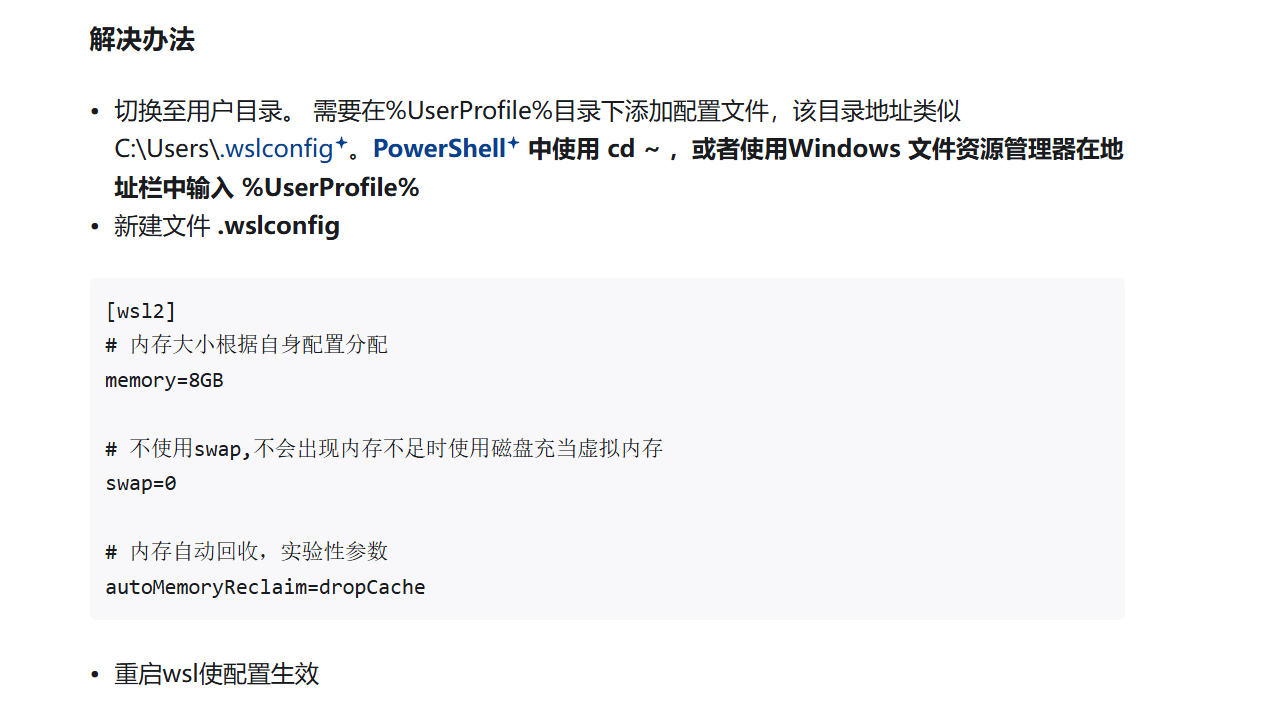
个人配置(我的电脑有 24G 内存,所以可以分多一点,大家自己的电脑看情况修改):调大分配的内存、禁用 swap
[wsl2]
# 内存大小根据自身配置分配
memory=12GB
# 不使用swap,不会出现内存不足时使用硬盘充当虚拟内存,保证硬盘不会100%占用爆炸
swap=0
重启 WSL 的指令(在 windows 下的终端输出)
# 关闭所有 wsl
wsl --shutdown
# 获取发行版名称(下面指令输出结果中的 name 列)
wsl -l -v
# 启动某一发行版的 wsl(名称=上一指令的 name 列)
wsl -d <发行版名称>
# 启动默认 wsl (上面查询发行版名称,输出结果中带 * 号的为默认发行版)
wsl
安装 N 卡驱动 & cuda 驱动 -- nvidia-smi
参考网页:https://docs.nvidia.com/cuda/wsl-user-guide/index.html#getting-started-with-cuda-on-wsl
如果在 Windows 上已经正确安装了 WSL ,则驱动已经默认安装

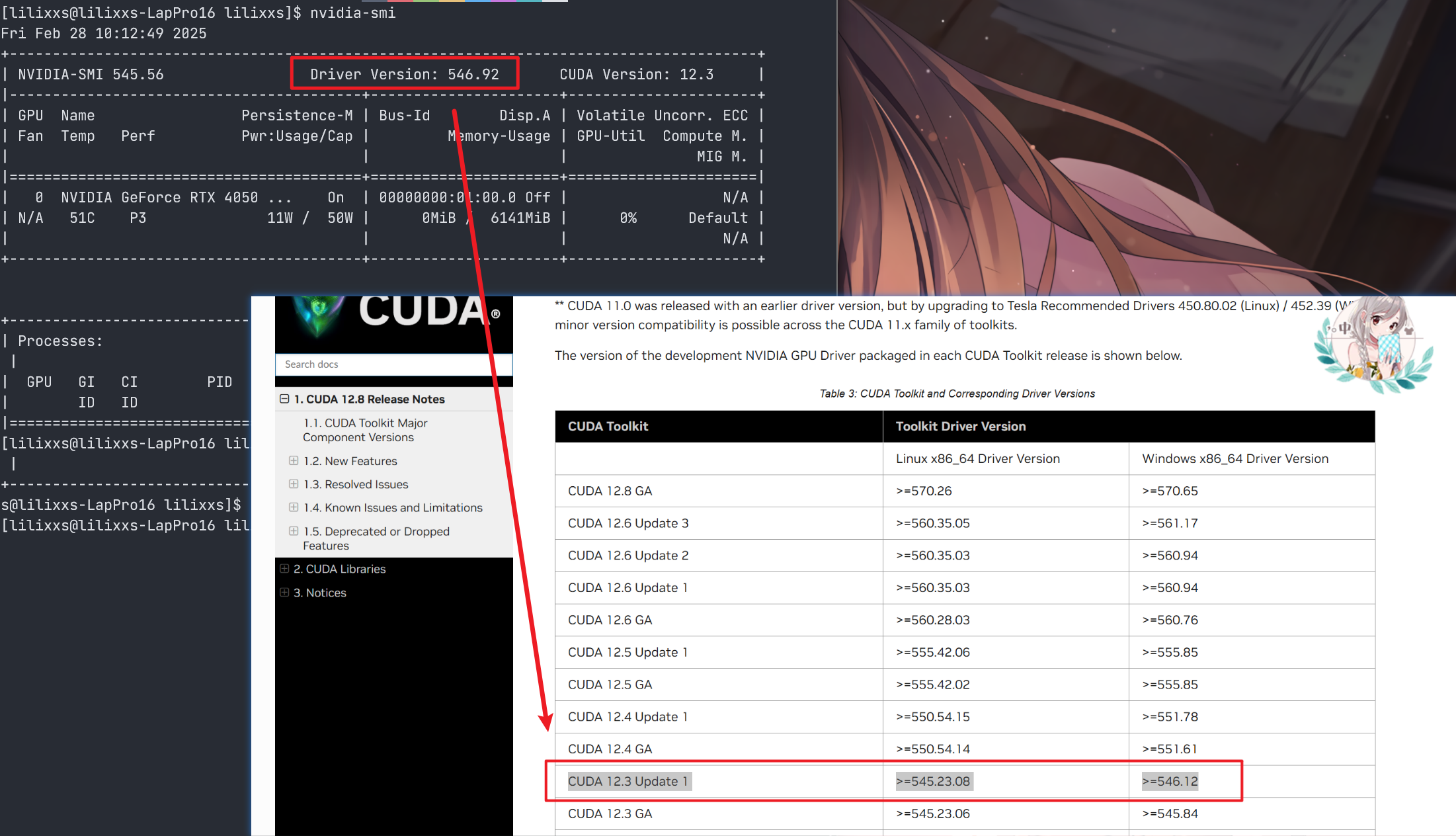
执行nvidia-smi获取当前下显卡信息(我的渣渣笔记本 4050)
[lilixxs@lilixxs-LapPro16 lilixxs]$ nvidia-smi
Wed Feb 26 15:20:50 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.56 Driver Version: 546.92 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4050 ... On | 00000000:01:00.0 Off | N/A |
| N/A 50C P8 2W / 80W | 724MiB / 6141MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
安装 GCC
CUDA 驱动要求安装 gcc(C 语言编译器)
参考教程:https://juejin.cn/post/7369413136225779764
相关指令(注意要加--allowerasing参数,允许升级gcc编译器相关文件)
sudo dnf install -y --allowerasing glibc gcc
安装 CUDA 驱动 -- CUDA Toolkit
安装包下载地址:https://developer.nvidia.com/cuda-toolkit-archive
注意:
- 这里需要根据驱动选择对应的 CUDA 版本,根据《CUDA 版本发布说明》选择具体版本
CUDA 版本发布说明:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
- 需要下载
WSL专版
我的 WSL 系统是 Oracle Linux 8.7 ,不是 Ubuntu,因此无法安装 deb 软件包,只能通过 lrunfile 方式安装

相关指令(官方文档提供的)
# 下载安装包(runfile)
wget https://developer.download.nvidia.com/compute/cuda/12.3.0/local_installers/cuda_12.3.0_545.23.06_linux.run
# 运行安装程序
sudo sh cuda_12.3.0_545.23.06_linux.run
注意:这软件包很大(4.1 GB)因此需要耐心等待下载完成
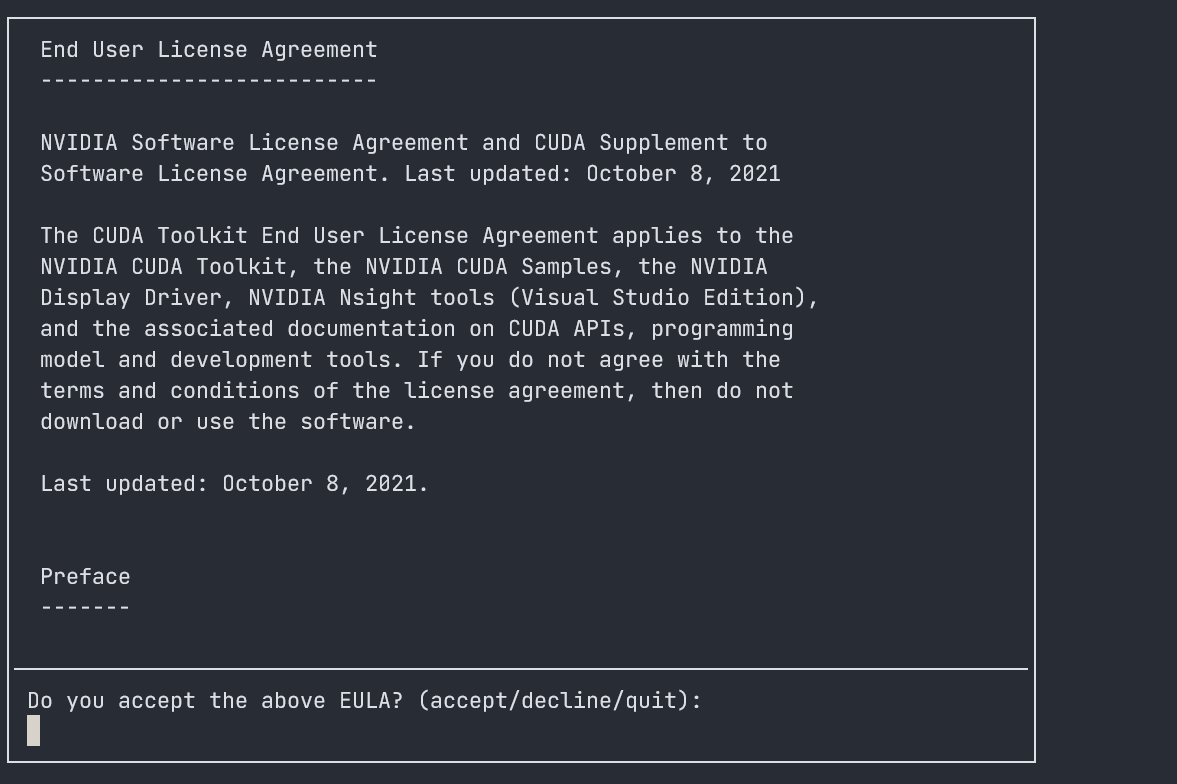
安装过程
- 同意协议(需要输 accept)
 2. 选择要安装的模块(enter 这里只选 CUDA Toolkit 和 Documention 即可) 然后选择 install 进行安装
2. 选择要安装的模块(enter 这里只选 CUDA Toolkit 和 Documention 即可) 然后选择 install 进行安装
安装完成后,根据教程将以上路径加入系统中
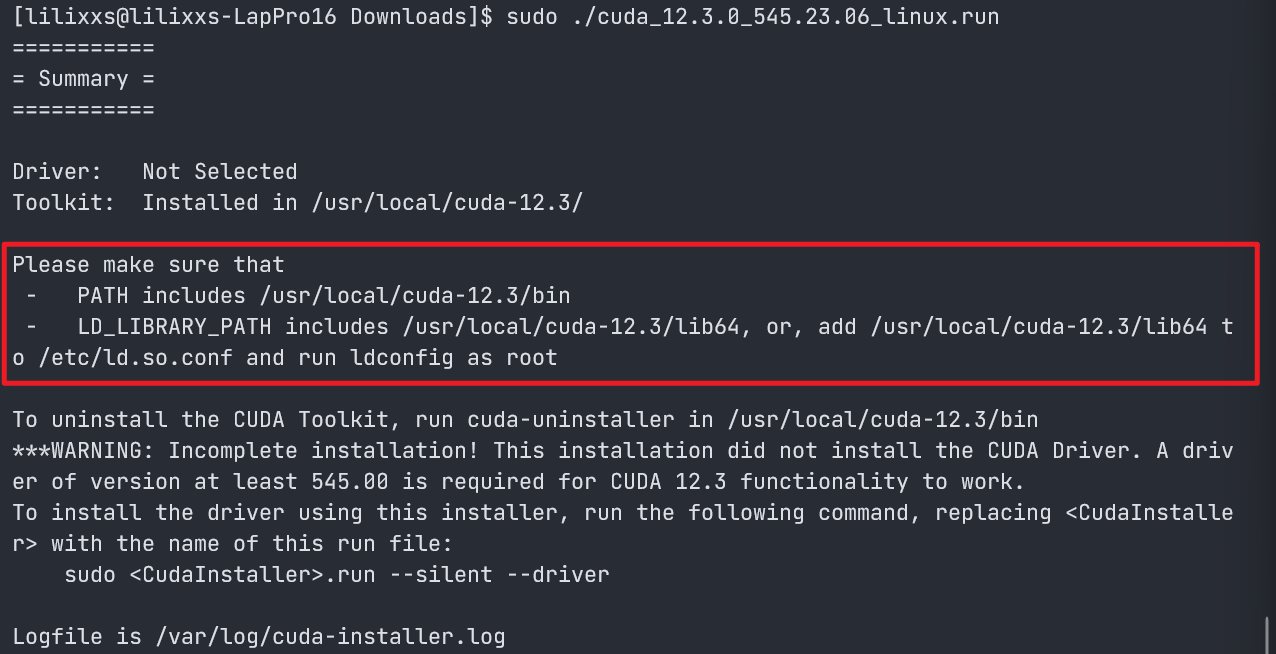
-
打开
~/.bashrc添加以下内容# add CUDA libs export PATH="$PATH:/usr/local/cuda-12.3/bin" export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-12.3/lib64" -
保存文件并退出,然后输入以下指令,应用配置
source ~/.bashrc
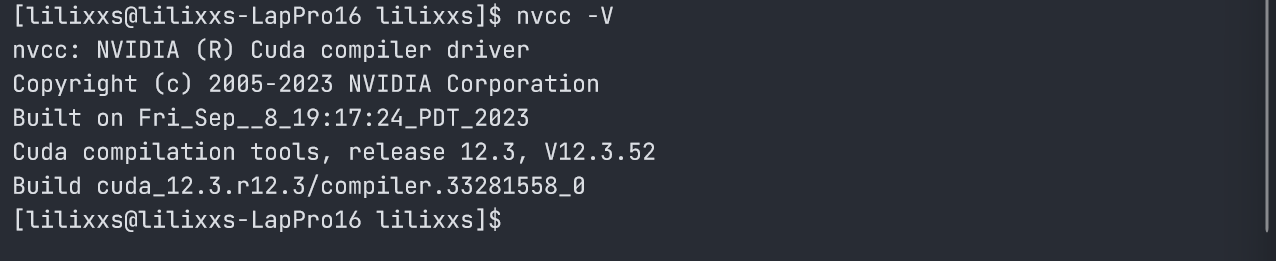
检验安装是否完成:输入nvcc -V查看 CUDA 自带的 C 语言编译器版本,若有版本输出则说明 CUDA 驱动安装成功
安装 CUDA 机器学习加速包 -- cudnn
安装 zlib
sudo dnf install -y zlib
安装 cudnn 软件包
https://developer.nvidia.com/cudnn-downloads
按需要选择对应版本,支持信息:https://docs.nvidia.com/deeplearning/cudnn/backend/v9.7.1/reference/support-matrix.html
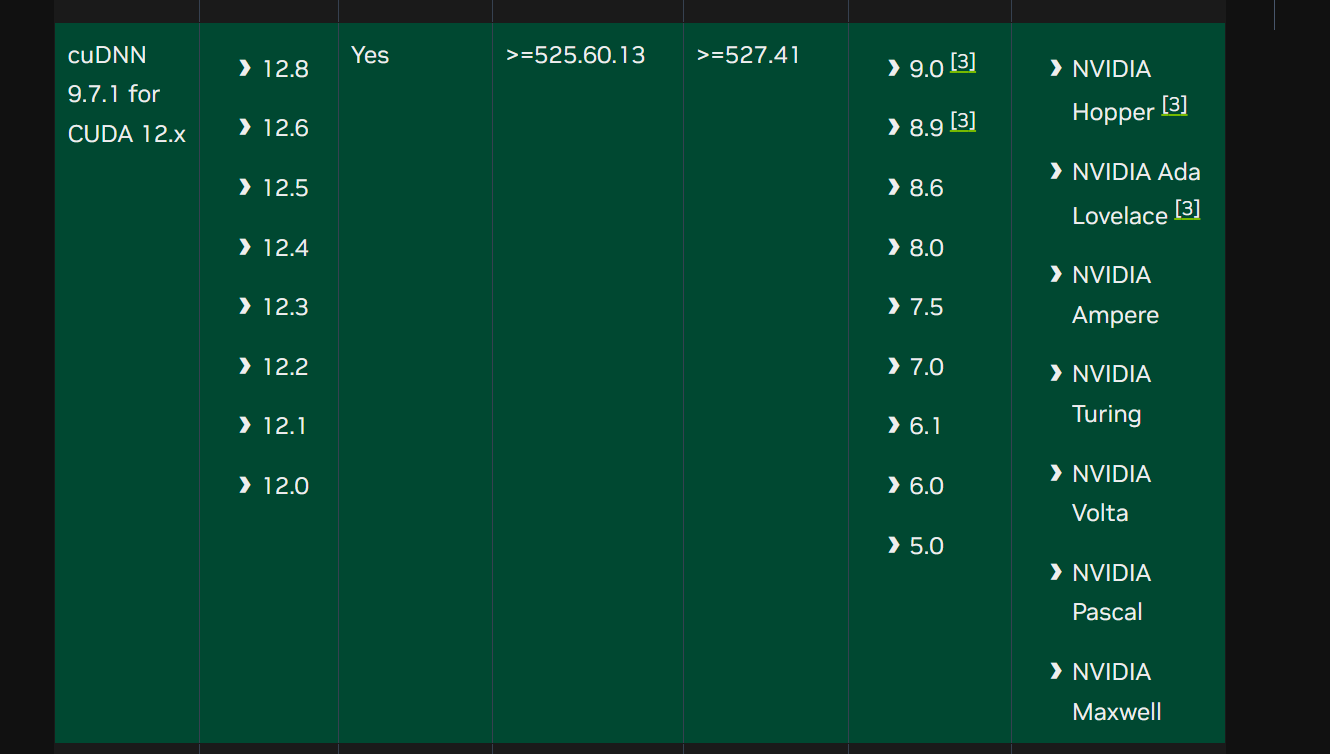
我安装的系统是 Oracle Linux 8.7 ,属于 RHEL 8 的衍生发行版,因此选择 RHEL 8 版本

也可以从存档页面中下载:https://developer.download.nvidia.cn/compute/cudnn/redist/cudnn/
-
下载安装包
# 链接模版 wget https://developer.download.nvidia.com/compute/cudnn/9.x.y/local_installers/cudnn-local-repo-$distro-9.x.y-1.0-1.$architecture.rpm # 其中 # 9.x.y = cudnn 库的版本 --> 9.7.1 # distro = 发行版 --> rhel8 # architecture = 硬件架构 --> x86_64 # 根据以上配置生成的真正地址 wget https://developer.download.nvidia.com/compute/cudnn/9.7.1/local_installers/cudnn-local-repo-rhel8-9.7.1-1.0-1.x86_64.rpm -
安装本地包
# 设置执行权限 chmod a+x cudnn-local-repo-rhel8-9.7.1-1.0-1.x86_64.rpm # 安装下载的软件包(设置为本地源) sudo rpm -i cudnn-local-repo-rhel8-9.7.1-1.0-1.x86_64.rpm sudo dnf clean all # 安装软件包 sudo dnf -y install --allowerasing cudnn9-cuda-12
也可使用网络安装
-
启用仓库
# 示例模版 sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/$distro/$arch/cuda-$distro.repo # distro 和 arch 参考下文 # 对于 Oracle Linux 8.7 --> distro=rhel8, arch=x86_64 sudo dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo sudo dnf clean all- distro 和 arch 对应发行版和硬件架构,有如下选择
 Oracle Linux 8.7 基于 RHEL 8,因此使用选择
Oracle Linux 8.7 基于 RHEL 8,因此使用选择distro=rhel8和arch=x86_64
- distro 和 arch 对应发行版和硬件架构,有如下选择
-
安装软件包(注意对应 CUDA 版本,CUDA 12 或 CUDA 11 )
sudo dnf -y install cudnn-cuda-12
注意:软件包很大(2.1 GB),需要耐心等待下载完成
AI 运行环境 -- ollama
docker 加速支持 -- 安装 nvidia Container Toolkit 软件包
这里使用 ollama 的 docker 镜像来运行
官方文章(在 github 上,需要梯子):https://github.com/ollama/ollama/blob/main/docs/docker.md
使用 yum 源进行安装
注意:以下操作都需要梯子,请自行准备,否则是龟速
-
配置生产存储库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \ sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo -
配置存储库以使用实验性软件包
sudo yum-config-manager --enable nvidia-container-toolkit-experimental -
安装 NVIDIA Container Toolkit 软件包
sudo yum install -y nvidia-container-toolkit -
配置应用 Container Toolkit 环境,然后重启 docker 服务
sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
安装 docker 版 ollama
参考网址:https://github.com/ollama/ollama/blob/main/docs/docker.md
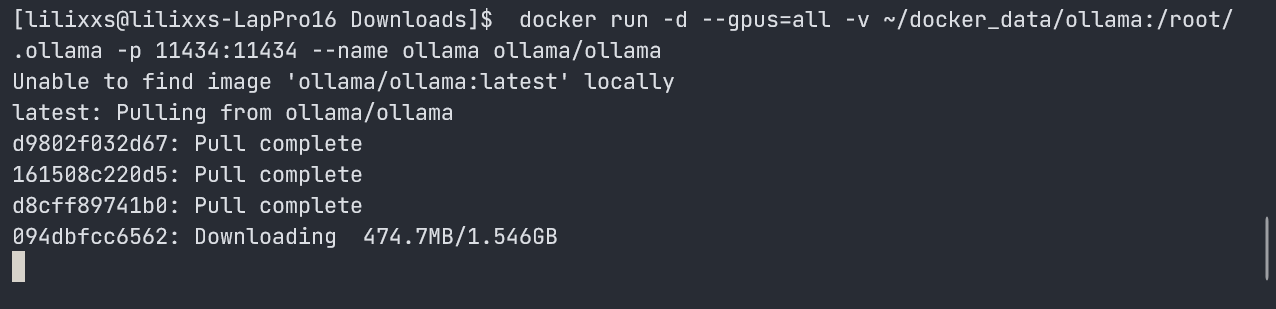
拉取并运行 docker 镜像
docker run -d --gpus=all -v ~/docker_data/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-d:后台运行--gpus=all使用所有的 GPU 资源(可惜我只有自带的一张渣渣 4050 显卡)-v ~/docker_data/ollama:/root/.ollama映射数据,将 ollama 下载的内容保存到 WSL 系统的 ~/docker_data/ollama 路径下-p 11434:11434映射端口,将11434端口暴露出来,此端口也是后台服务的端口
注意:容器比较大(有一层有 1.6G),需要耐心等待
然后进入容器中(使用docker exec指令)
docker exec -it ollama bash
即可执行ollama的相关指令
ollama 拉取部署模型
基本步骤
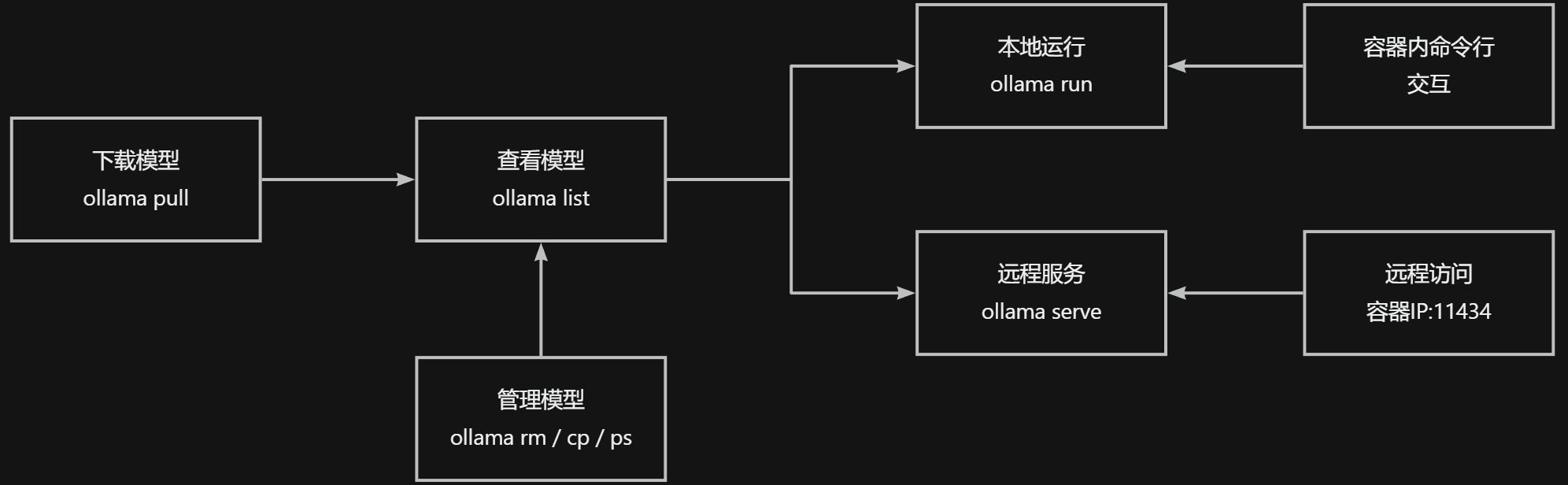
- 从网上下载模型:
ollama pull - 查看已经下载的模型:
ollama list- 删除模型:
ollama rm <模型名称> - 复制模型:
ollama cp <模型名称> - 查看正在运行的模型:
ollama ps
- 删除模型:
- 运行模型
- 本地运行:
ollama run - 提供后台服务(API):
ollama serve
- 本地运行:
在线拉取模型(ollama pull)
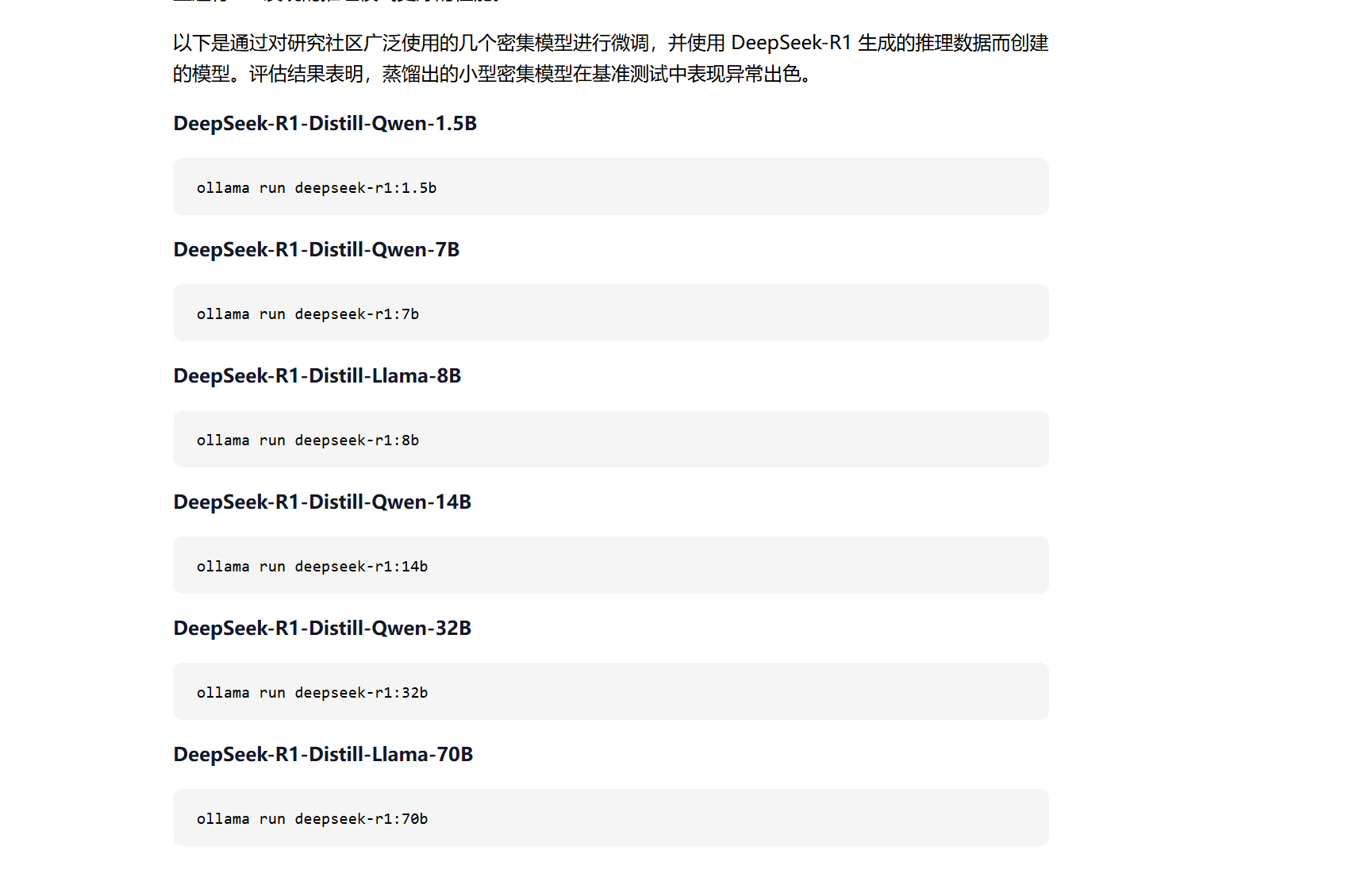
这里选择的是7B模型
ollama pull deepseek-r1:7b

注意:模型比较大(4.7 GB) ,需要翻墙,且需要耐心等待
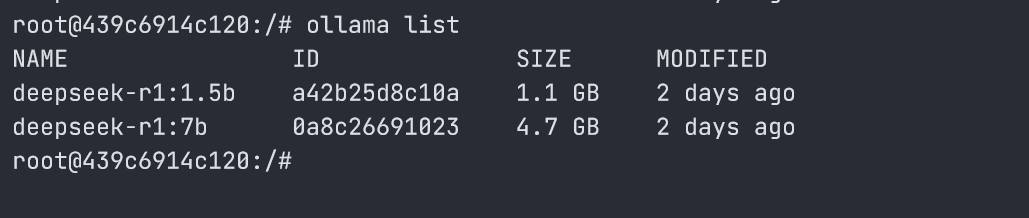
查看已经下载的模型(ollama list)
在 docker 容器内,输入以下指令,可看到已经下载的模型,模型名称,模型大小(占用的硬盘空间)等信息
ollama list
管理模型的相关指令
在 docker 容器内,输入以下指令管理已经下载的模型:- 删除已经下载的模型:
ollama rm <模型名称> - 复制模型:
ollama cp <模型名称> <新模型名称> - 查看正在运行的模型:
ollama ps
ollama 运行模型
在命令行中运行模型
进入到容器中,然后运行下方指令,可在命令行中进行对话
ollama run <模型名称>
# 示例
ollama run deepseek-r1:7b
在send a message中输入想要对话的内容即可
回答内容中,<think>范围内为思考链的内容,范围外为真正回答的结果

注意:这种运行方式不是很稳定,且功能较少,主要用于测试,实际使用中应尽量避免这种运行方法
提供后台服务(API)
- 如果按照以上来部署(部署 docker 容器版的 ollama),则 docker 容器启动时(输入 docker run 指令)后台服务就已经开启了
- 如果是直接部署在自己的 linux 系统上,则需要以下指令来启动 ollama 后台服务
ollama serve
客户端测试连接
完成以上步骤后,即可使用客户端测试进行连接了
这里使用的是cherry studio。这是一款开源、功能强大、由国人大佬开发的 AI 客户端
在软件界面,点击左下角进入:设置 --> 模型服务 --> Ollama
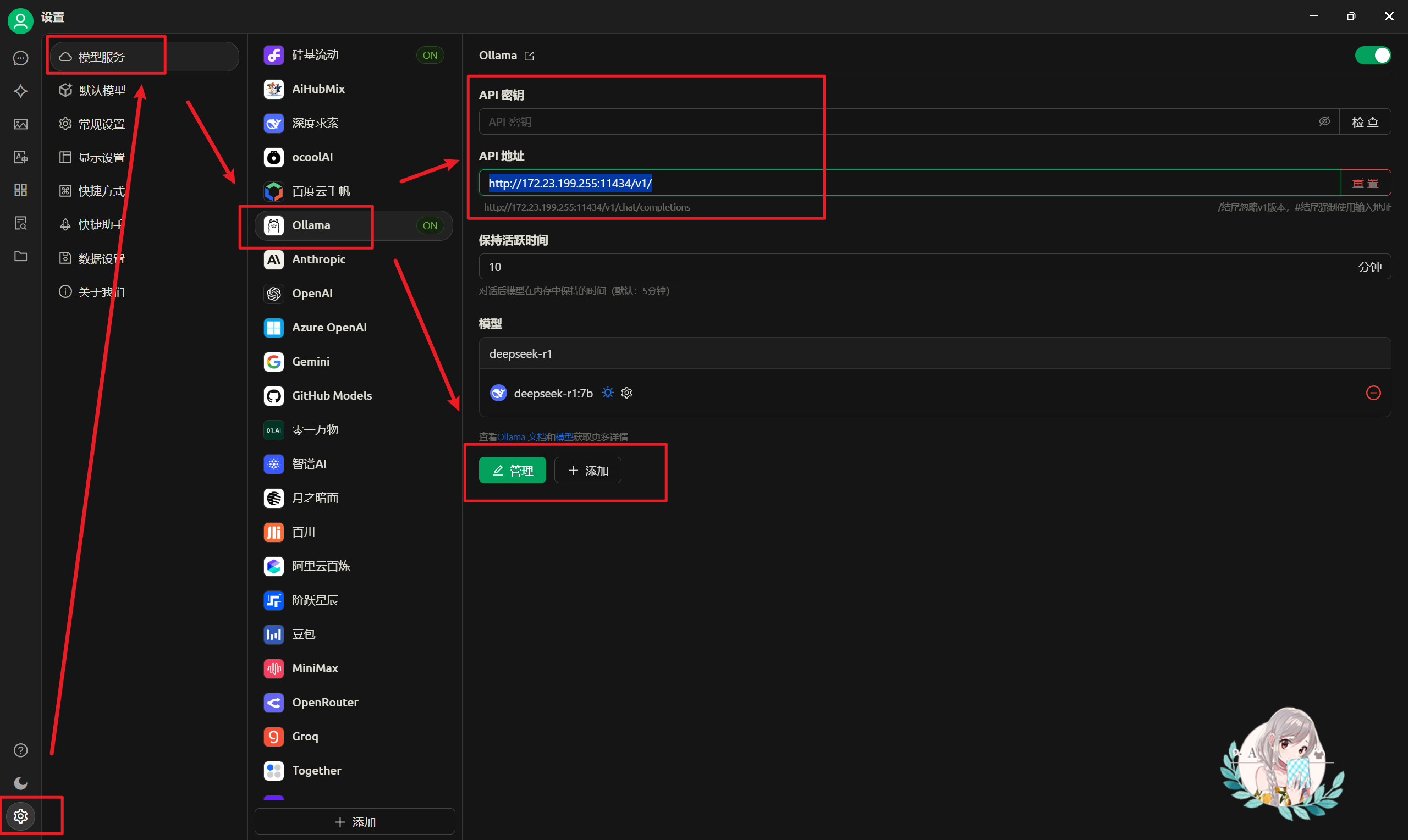
如果是本地部署,则
- API 秘钥留空
- API 地址 = WSL 系统的 IP 地址: docker 容器暴露的端口
- WSL 系统的 IP 地址
在 WSL 系统中(容器外的 Linux 系统),输入ifconfig查看 eth 开头的网络的 ip 地址(这里为 172.23.199.255)
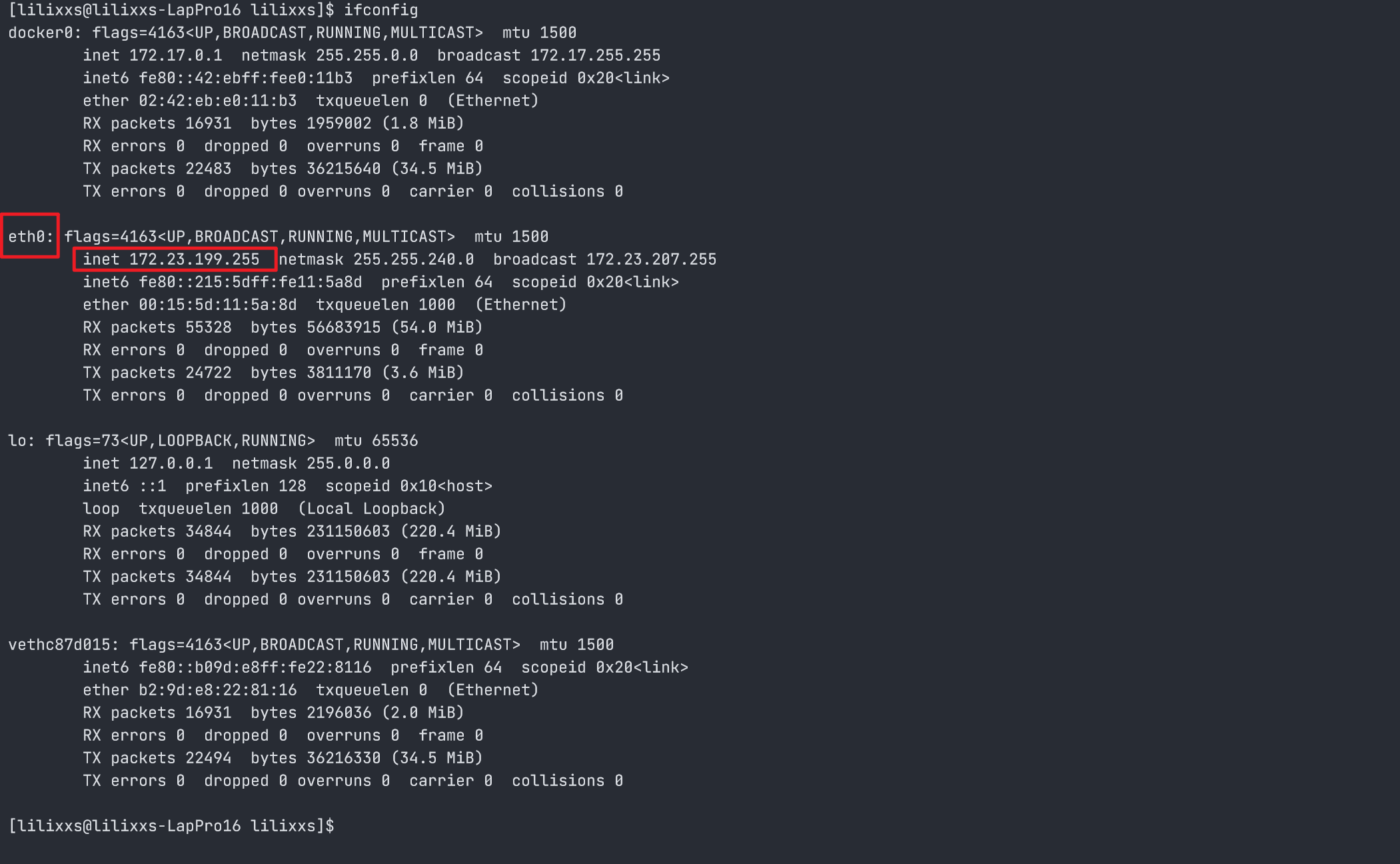
- docker 容器暴露的端口(默认为 11434)
在 WSL 系统中,输入docker ps -a指令,查看 ollama 容器的暴露端口,看箭头前的端口号(这里是 11434)

- 因此最后填的内容为
http://172.23.199.255:11434/v1/
- WSL 系统的 IP 地址
- 模型
- 新增的时候,点击【添加】;修改既有的,点击【修改】
- 添加模型时
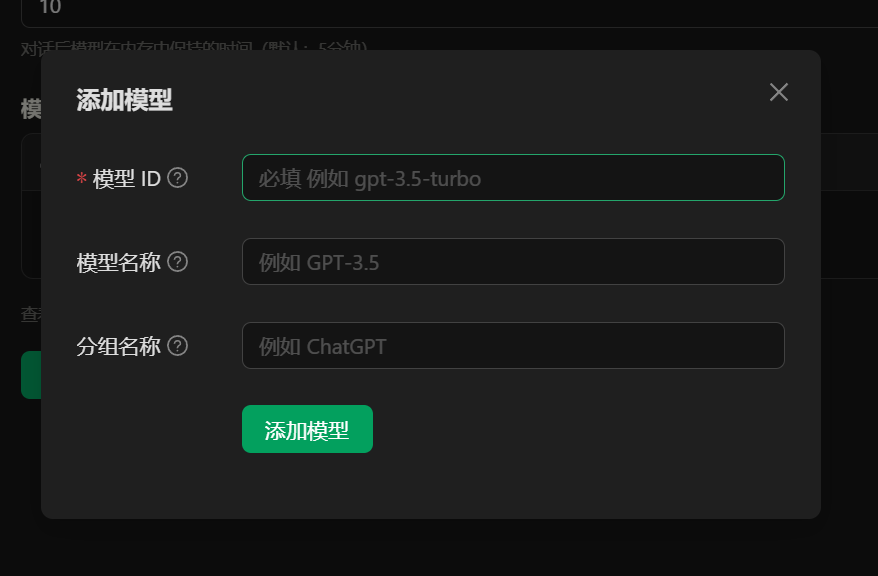
- 模型 ID,在 ollama 容器中,输入查看已经下载的模型指令
ollama list,查看 name(如这里选用deepseek-r1:7b)

- 模型名称、分组名称可任意填,此客户端在界面会显示模型名称和分组
- 模型 ID,在 ollama 容器中,输入查看已经下载的模型指令
设置完成,就可以进行对话了
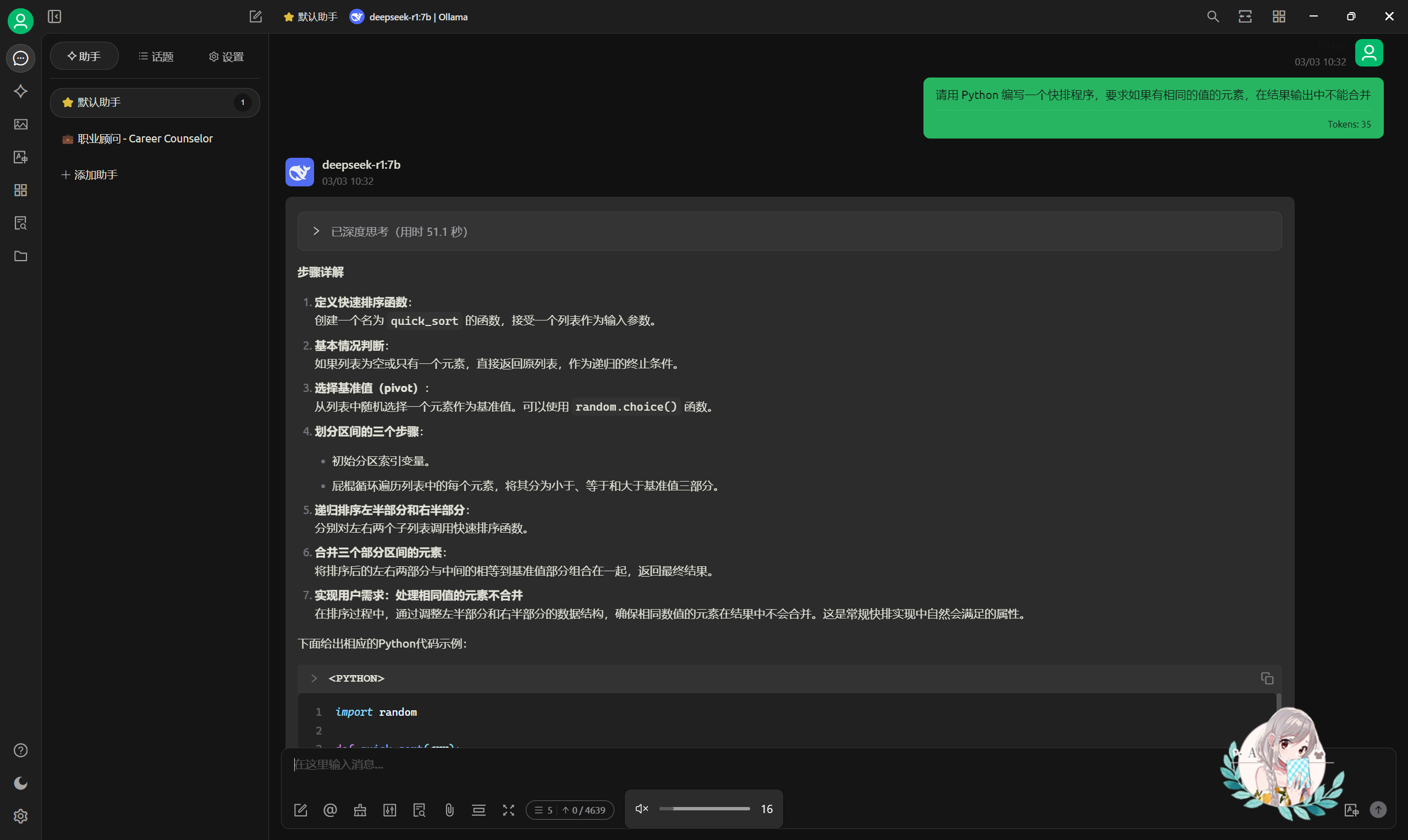
可以看出,此时的问答只是最基础的问答:
- 只能使用最基本的对话,无法从自己的知识库中获取信息
- 提示词比较固定,效果较差
- 一次运行只能支持一次对话,无法创建自动化的流程(如多次问答实现复杂、具体的输出)
- 缺乏权鉴、流控、敏感词筛选等功能,接口直接暴露,安全性不足
这就是为何要使用 Agent 平台的原因
Agent 平台
平台选型
目前(2025-3-3)最火的 Agent 平台(免费开源、功能完善、社区活跃)有以下两个- Dify:https://dify.ai/zh
- FastGPT:https://fastgpt.cn/zh
这里选择 FastGPT 进行测试
FastGPT 整体操作流程
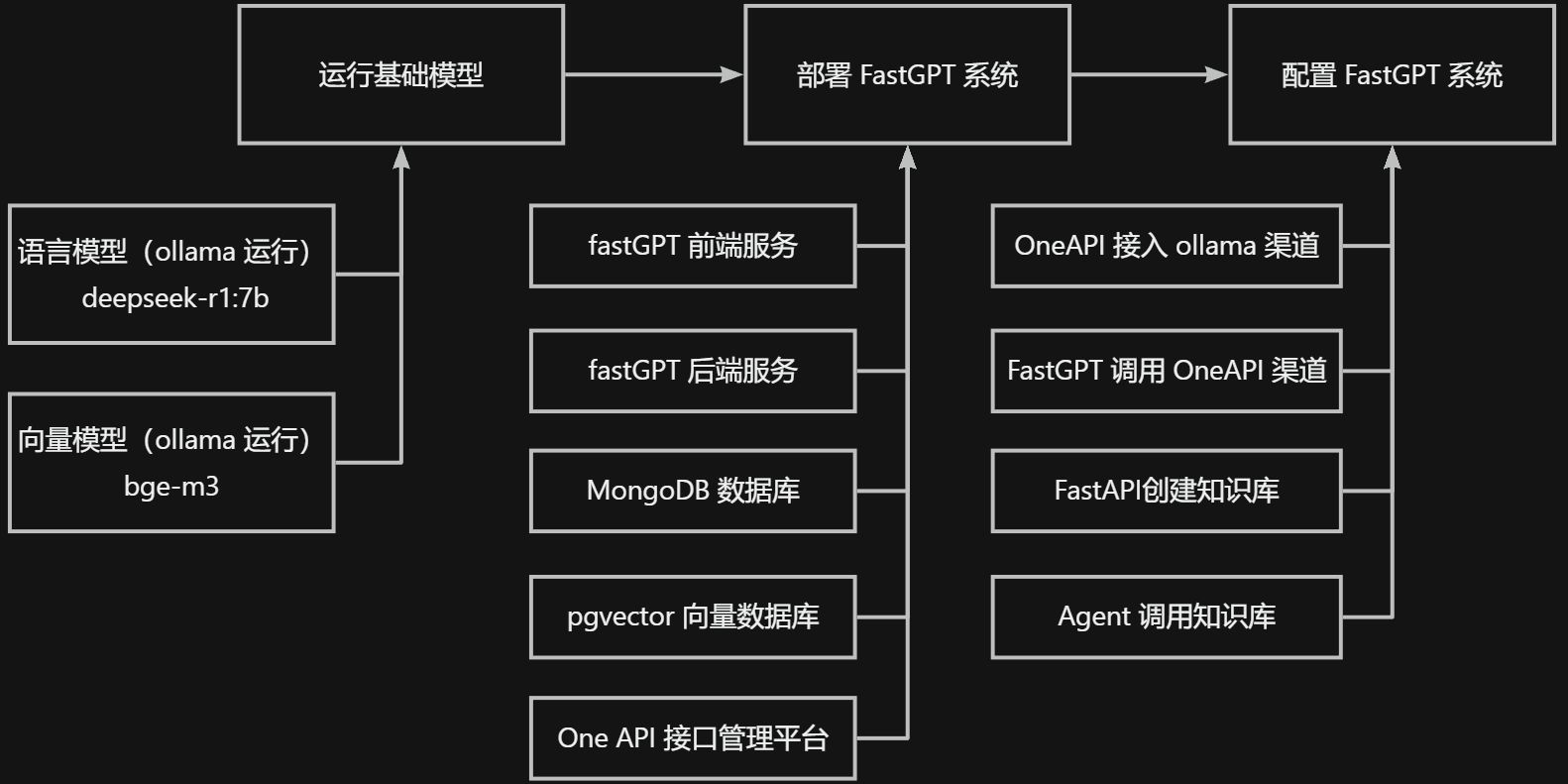
- 运行基础模型
- 运行 AI 模型(之前部署 Ollama 已经实现了)
- 运行向量模型,用于知识库导入数据的处理(接下来要安装相关模型)
- 部署 FastGPT 系统(使用 docker-compose 进行部署)
- fastGPT 前端项目 + fastGPT sandbox 后台服务
- AI接口接入 = One API
- 向量数据库 = pgvector
- 数据数据库 = mongodb + mysql
- 配置 FastAPI 系统
- 配置 AI 模型的渠道(统一从 One API 接入各种厂商的模型)
- 配置 AI 模型(上面部署的 ollama)
- 配置向量模型
- 配置 FastAPI 从 One API 的对应渠道调用 AI 模型
- 创建知识库,并使用向量模型处理导入的数据
- 创建聊天,并调用知识库数据
- 配置 AI 模型的渠道(统一从 One API 接入各种厂商的模型)
运行基础模型(向量模型:bge-m3)
向量模型用于处理知识库相关内容
- 将文本切分为不同分段
- 根据提问,搜索并返回最接近的分段,供大语言模型的回答进行参考
以下为按照官方文档部署的 m3e 模型,实测无法正常启动
参考资料:https://zhuanlan.zhihu.com/p/675271031
这里选用
GPU 运行的版本,运行指令如下docker run -d --name m3e -p 6008:6008 --gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
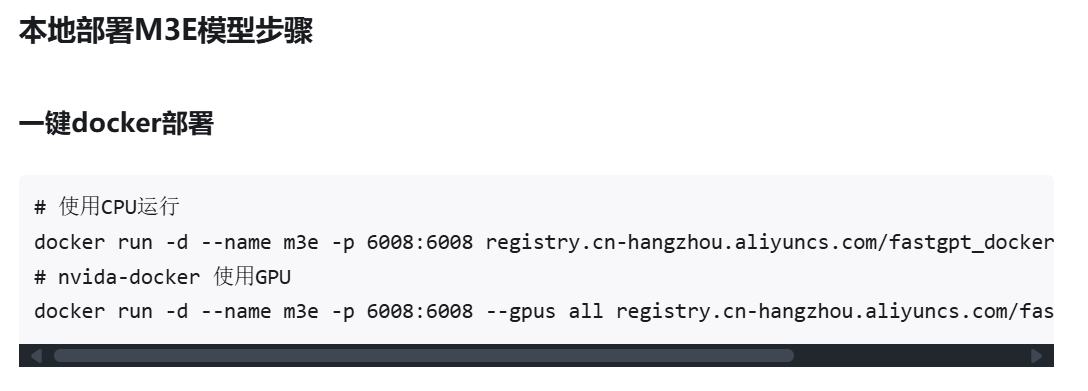
尝试从 ollama 拉取、部署向量模型(和上文部署模型步骤相同,这里快速过一下)
使用 bge-m3向量模型,这也是一款偏向中文的、性能优秀的向量模型。官方介绍(在 github 需要梯子):https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md
# 进入 ollama
docker exec -it 439c6914c120 bash
# 拉取向量模型
ollama pull bge-m3
# 查看模型是否已经下载
ollama ls
部署 FastGPT 系统
根据官网步骤进行安装:https://doc.fastgpt.cn/docs/development/docker/
使用docker-compose方法进行部署,这里使用 pgvector 版本,部署比较简单
pgvector、milvus、zilliz 是不同的向量数据库,性能、硬件要求不同
- zilliz 是云服务版的向量数据库,需要花钱
- 剩下 2 个数据库,性能和硬件要求由低到高:pgvector、milvus
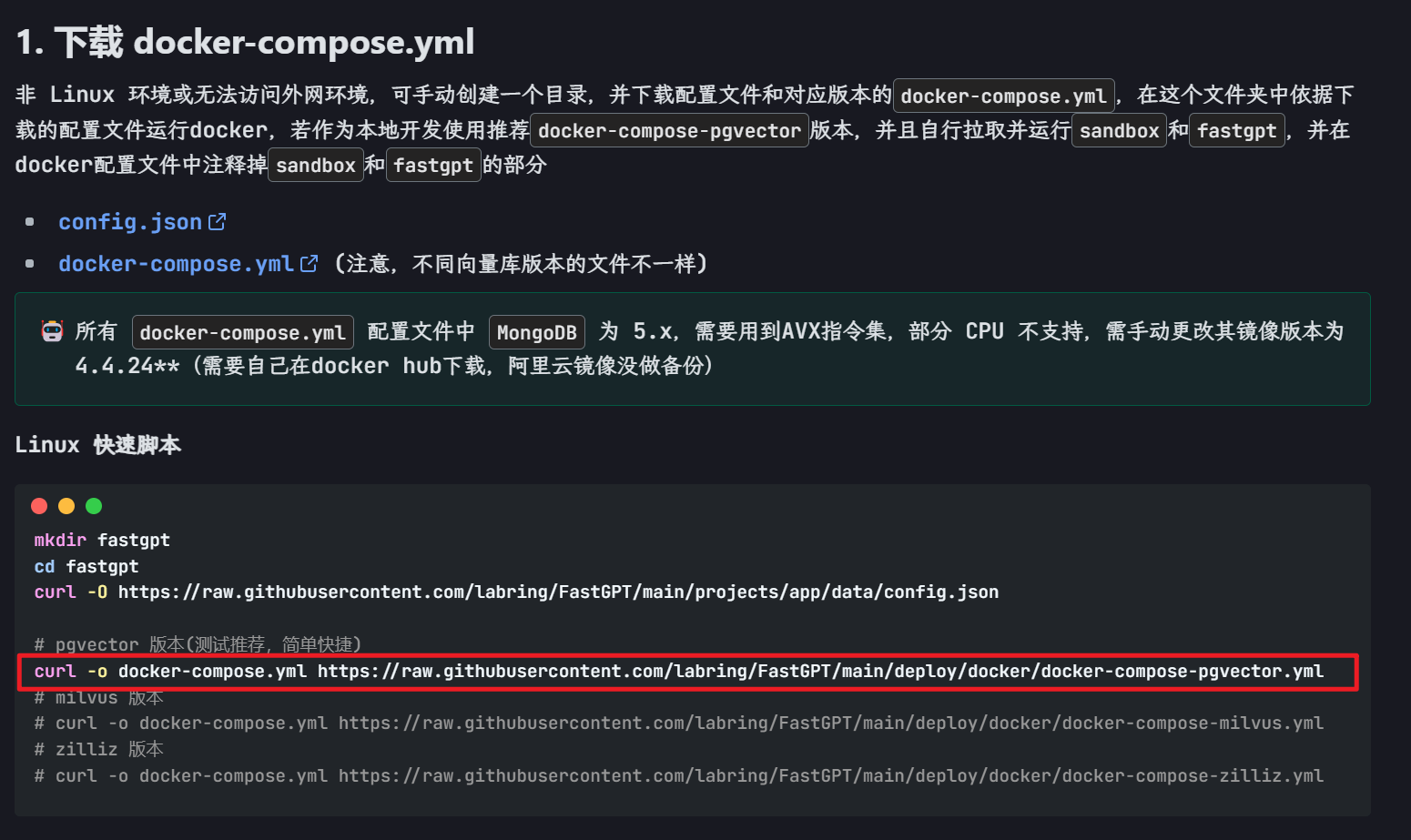
注意:这里需要下载 6 个软件包(one-api、fastgpt、mysql、mongodb、pgvector、sandbox),需要一些时间,请耐心等待
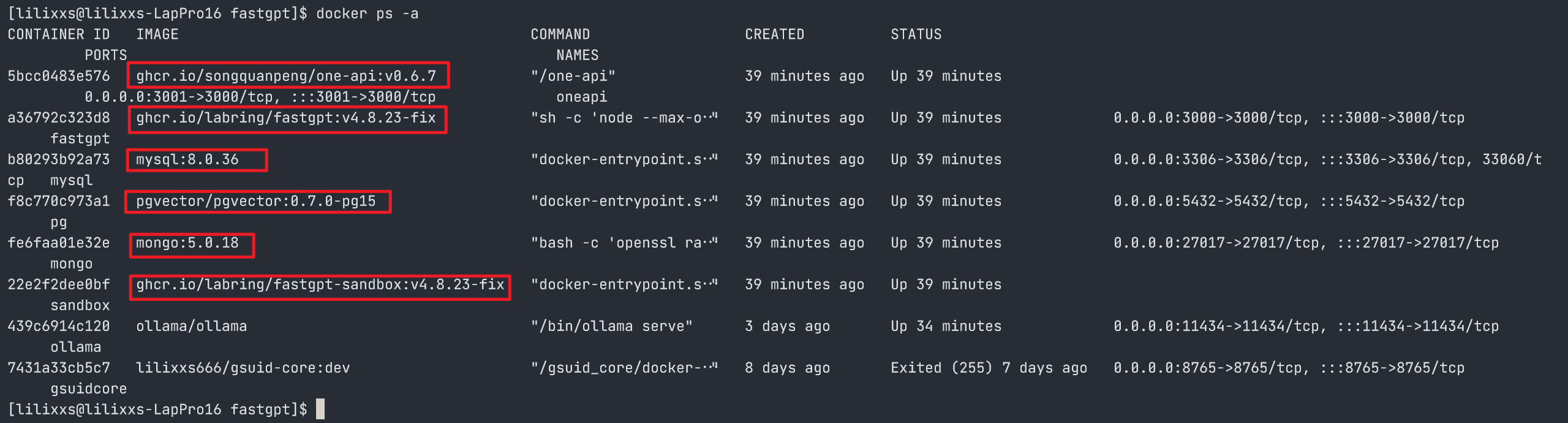
问题1:mongodb 报错
状况:mongodb 容器反复重启,oneapi 和 fastgpt 界面都打不开。查看 mongodb 日志,一直有报错问题原因:mongodb 的 replica set (副本集)初始化不成功
进入 mongodb 的docker 容器
# 以上图为例,momgodb 容器的 id = fe6faa01e32e
docker exec -it fe6faa01e32e bash
进入 mongodb 的容器内部后,执行以下指令,初始化 mongodb
# 连接数据库(这里要填Mongo的用户名和密码)
# mongodb 的用户名,默认为 myusername
# mongodb 的密码,默认为 mypassword
mongo -u myusername -p mypassword --authenticationDatabase admin
# 初始化副本集,只有一个单节点(容器本身的节点) mongo:27017 。
# 如果需要外网访问,需要增加Mongo连接参数:directConnection=true
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo:27017" }
]
})
# 检查状态。如果提示 rs0 状态为 ok: 1,则代表运行成功
rs.status()
- auth 中的用户名、密码在
docker-compose.yaml文件中位置如下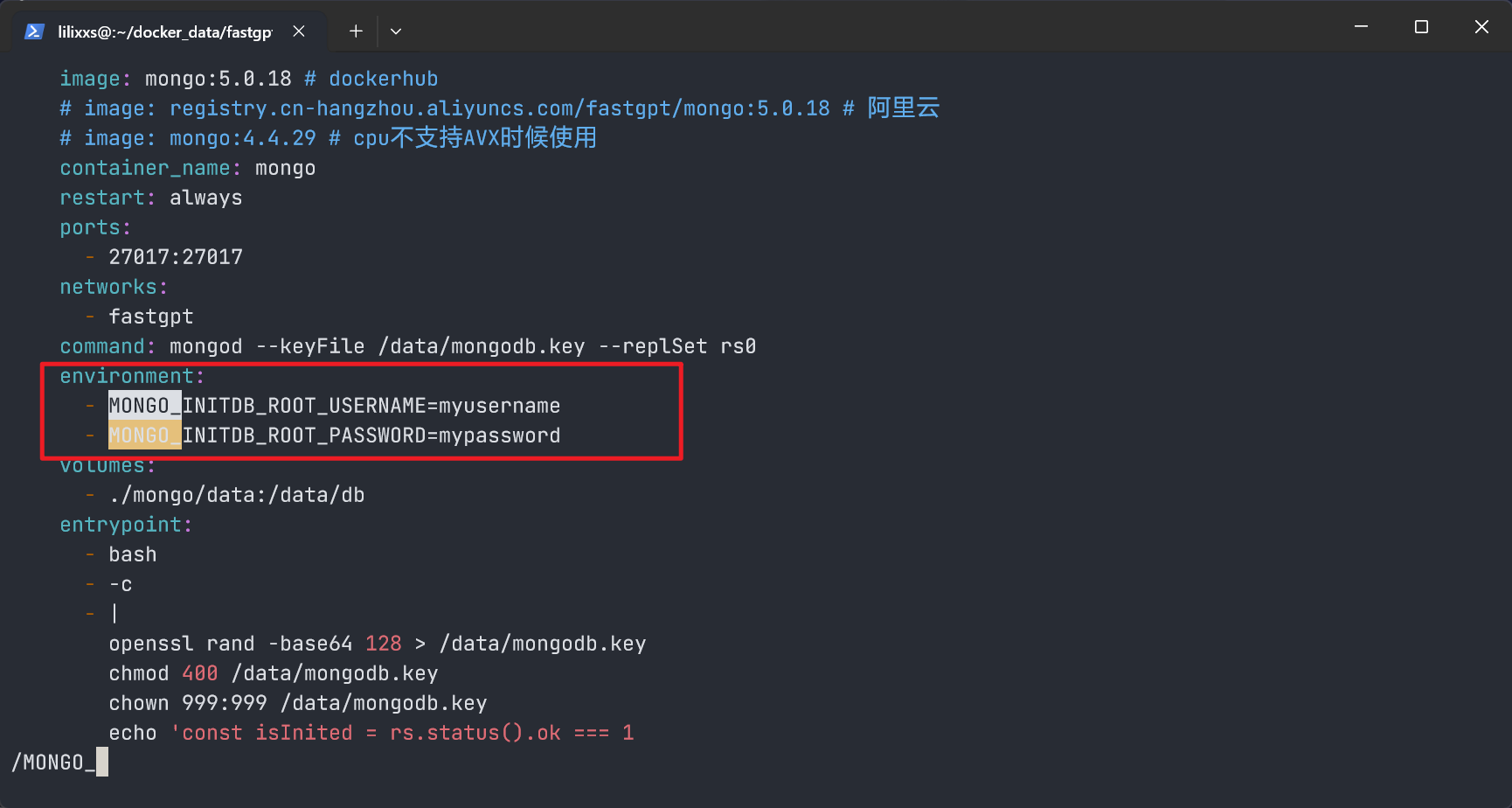
- MONGO_INITDB_ROOT_USERNAME = 用户名,默认为 myusername
- MONGO_INITDB_ROOT_PASSWORD = 密码,默认为 mypassword
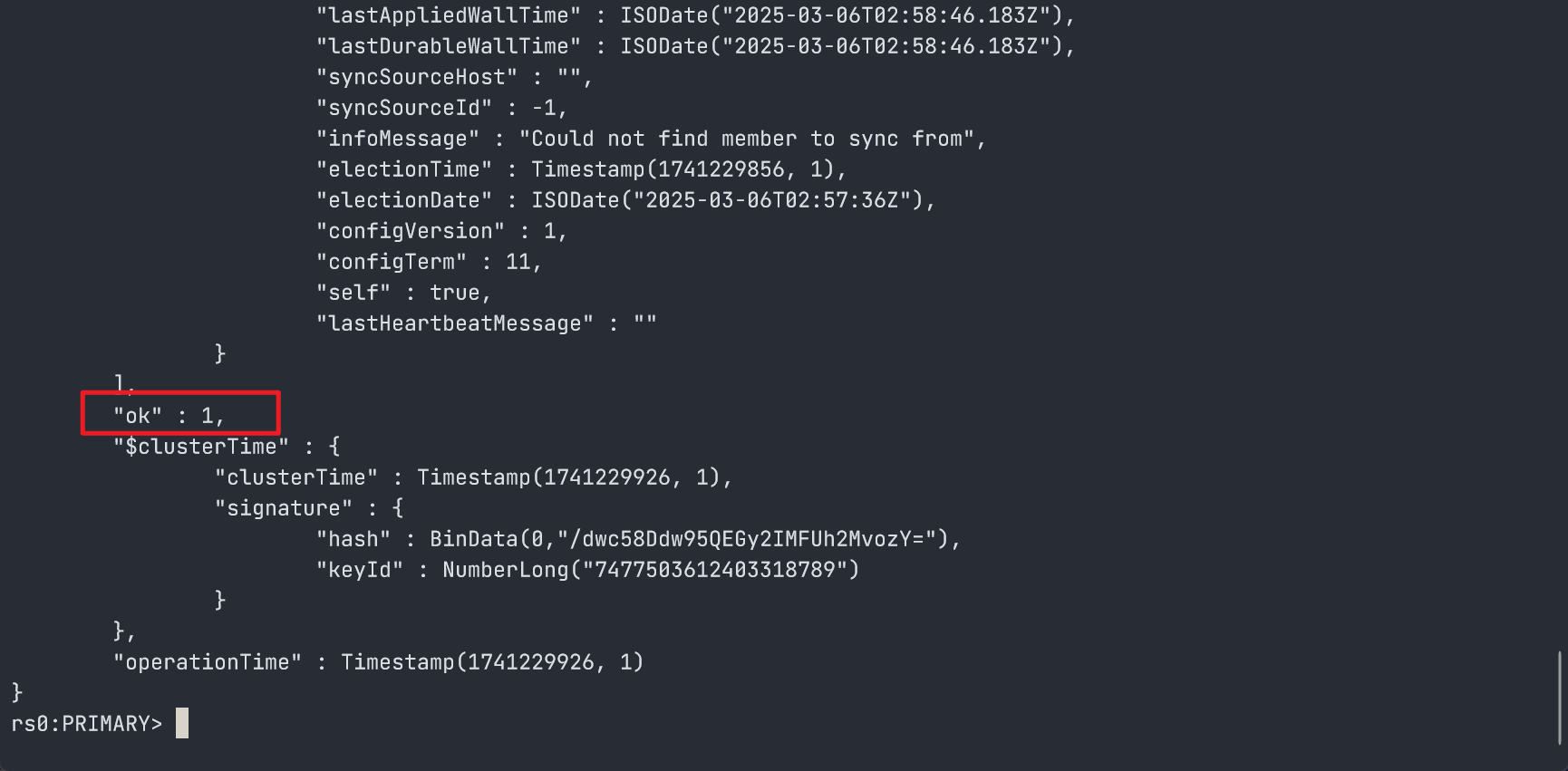
- 运行成功时
rs.status()输出的部分内容,有ok: 1就说明执行成功了
问题2:fastgpt 日志报错,[mongoose] XXX timed out after YYY ms

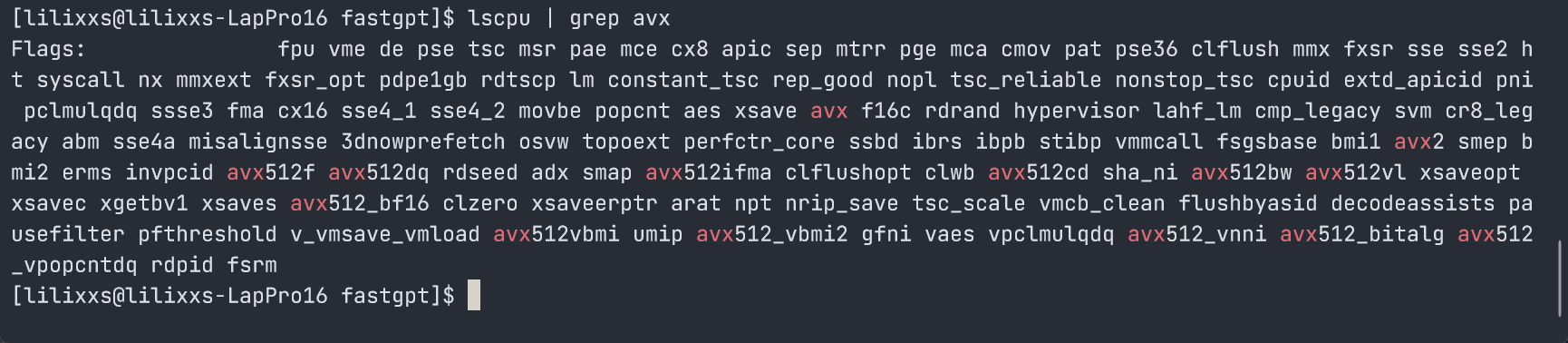
检查自己的CPU 是否支持 AVX(在 WSL 命令行中输出以下指令)
lscpu | grep avx
能找到关键词,说明 CPU 支持(如下图),否则不支持
若不支持,则要根据官方帮助第1条使用 4.X 版本的 mongodb:
- 在
docker-compose.yaml文件中修改,保存修改 - 执行
docker compose down指令,删除无法正常运行的旧 mongodb 容器 - 重新执行
docker compose up -d指令,重新创建新的 mongo 容器
经个人测试,我的 CPU 支持 AVX,但仍然报错,解决方法如下:
- 开启并确认 mongodb 的副本集功能和状态是否正常,如上一小节,进入 mongodb 容器内设置
- 按顺序重启以下服务,mongodb --> oneapi --> fastgpt
配置 FastGPT 系统
配置 OneAPI 接入 ollama 渠道
FastGPT 部署完成后,使用http://WSL系统IP地址:3001,在浏览器访问 OneAPI 界面
WSL系统的IP地址,可在WSL系统中使用ifconfig指令查询,找到ethXX的网络IP地址(inet)
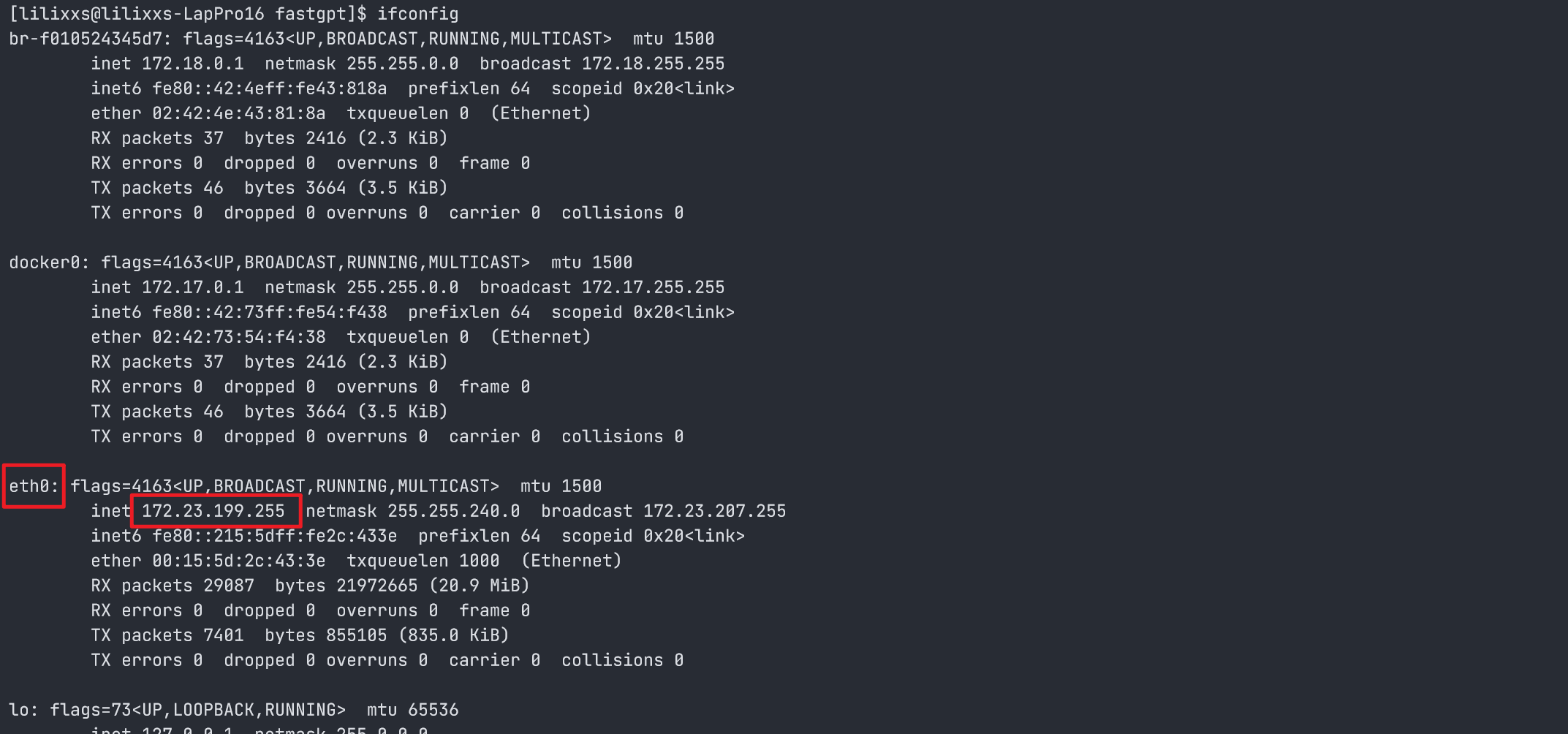
如上图所示,我的 WSL 系统的 IP 地址为:172.23.199.255。则 OneAPI 界面地址为:http://172.23.199.255:3001
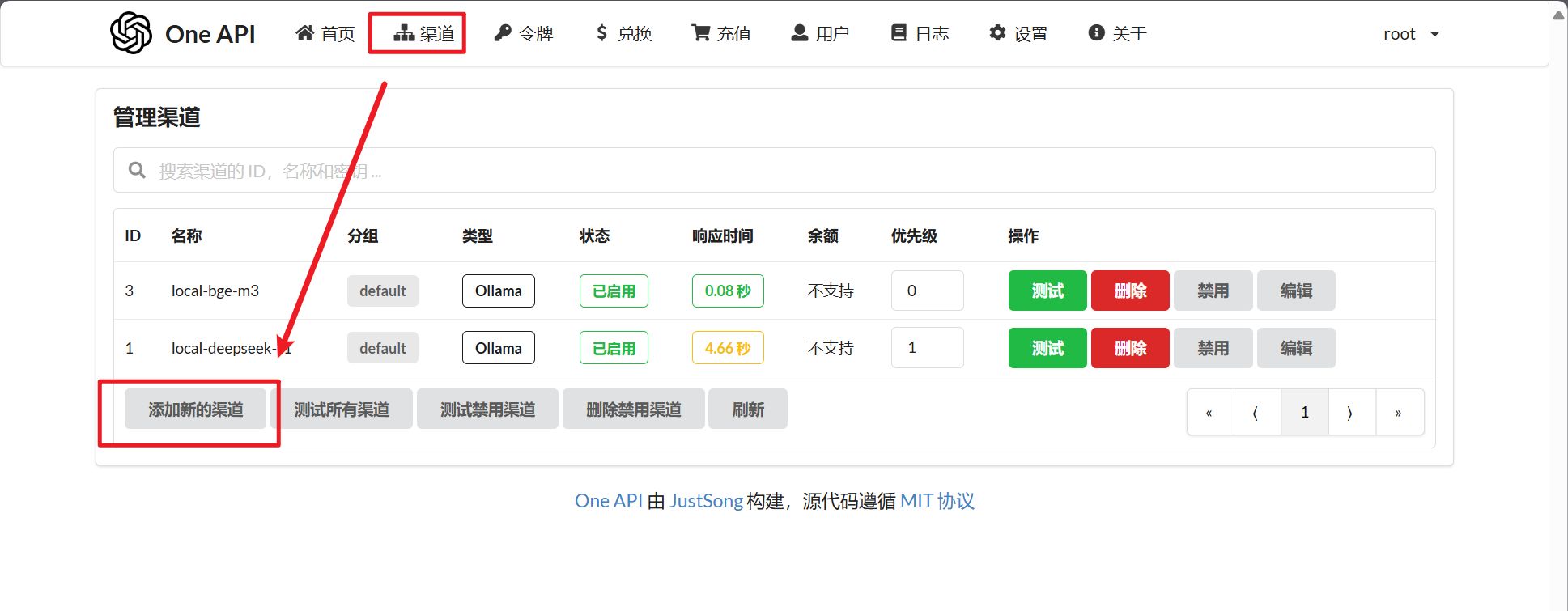
进入界面后,点击【渠道】–>【添加新的渠道】
添加语言模型(deepseek-r1:7b)
点击【渠道】–>【添加新的渠道】
按照以下方式进行配置
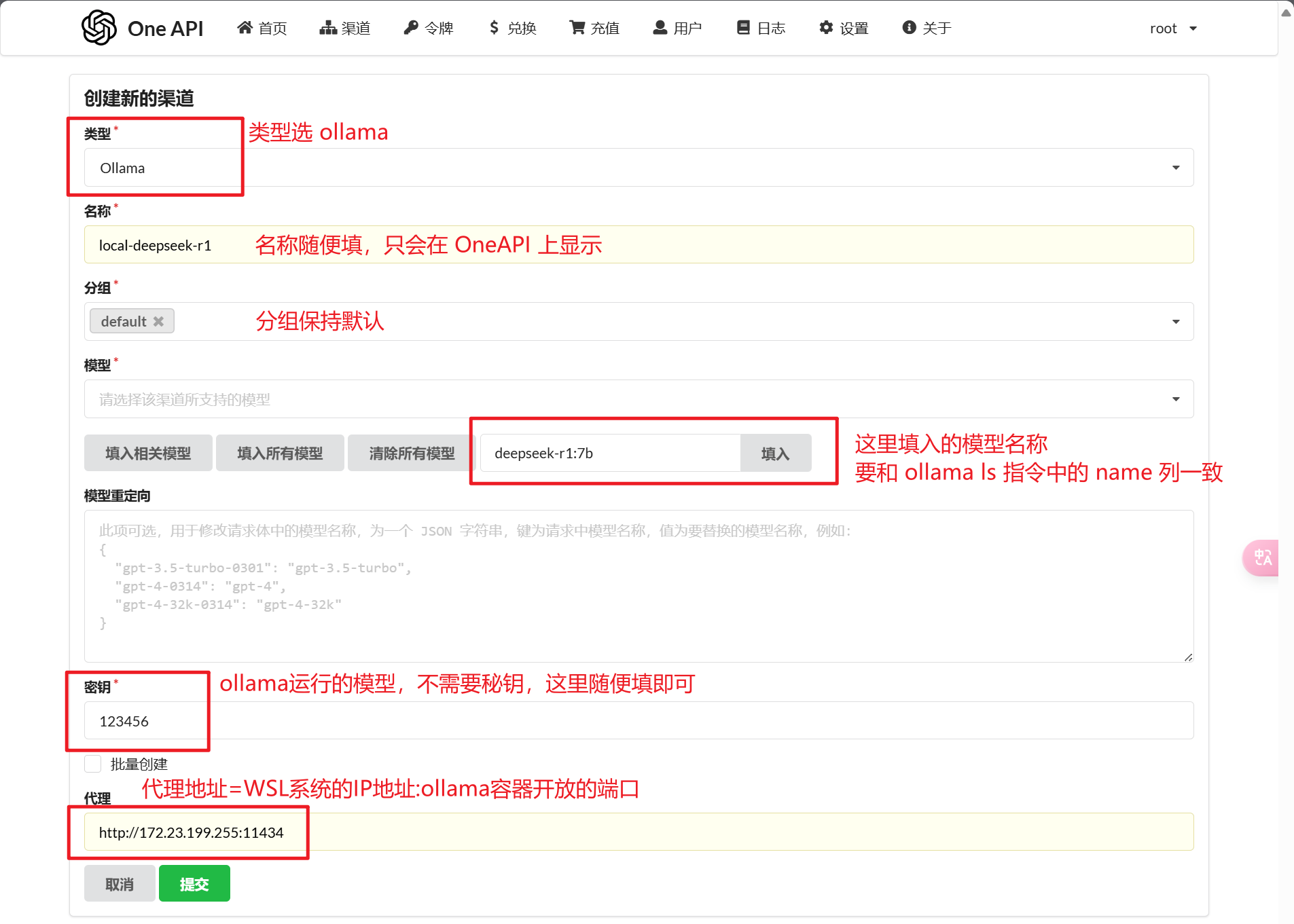
- 代理地址 = WSL 系统的 IP 地址:ollama 容器的开放的端口
- 密码随便填(ollama 直接运行模型,不需要进行秘钥校验)
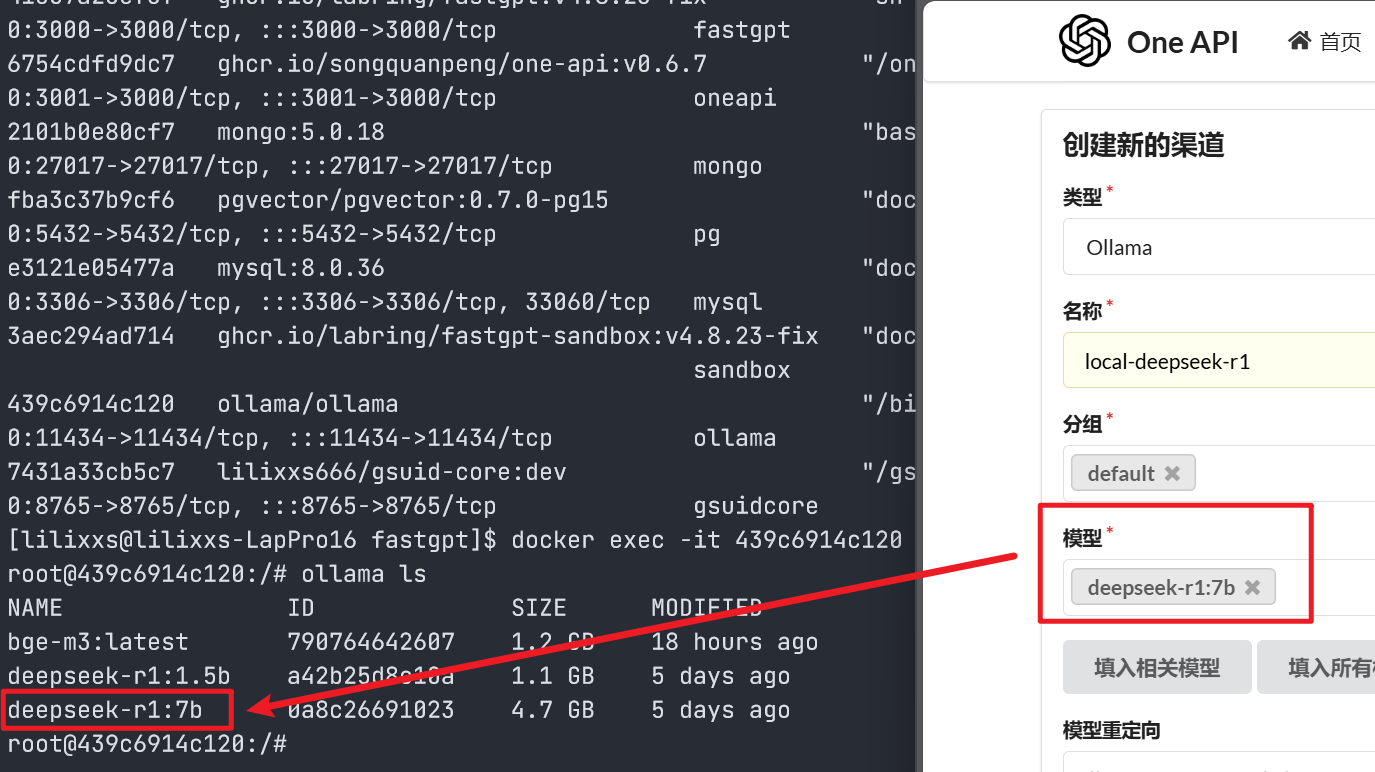
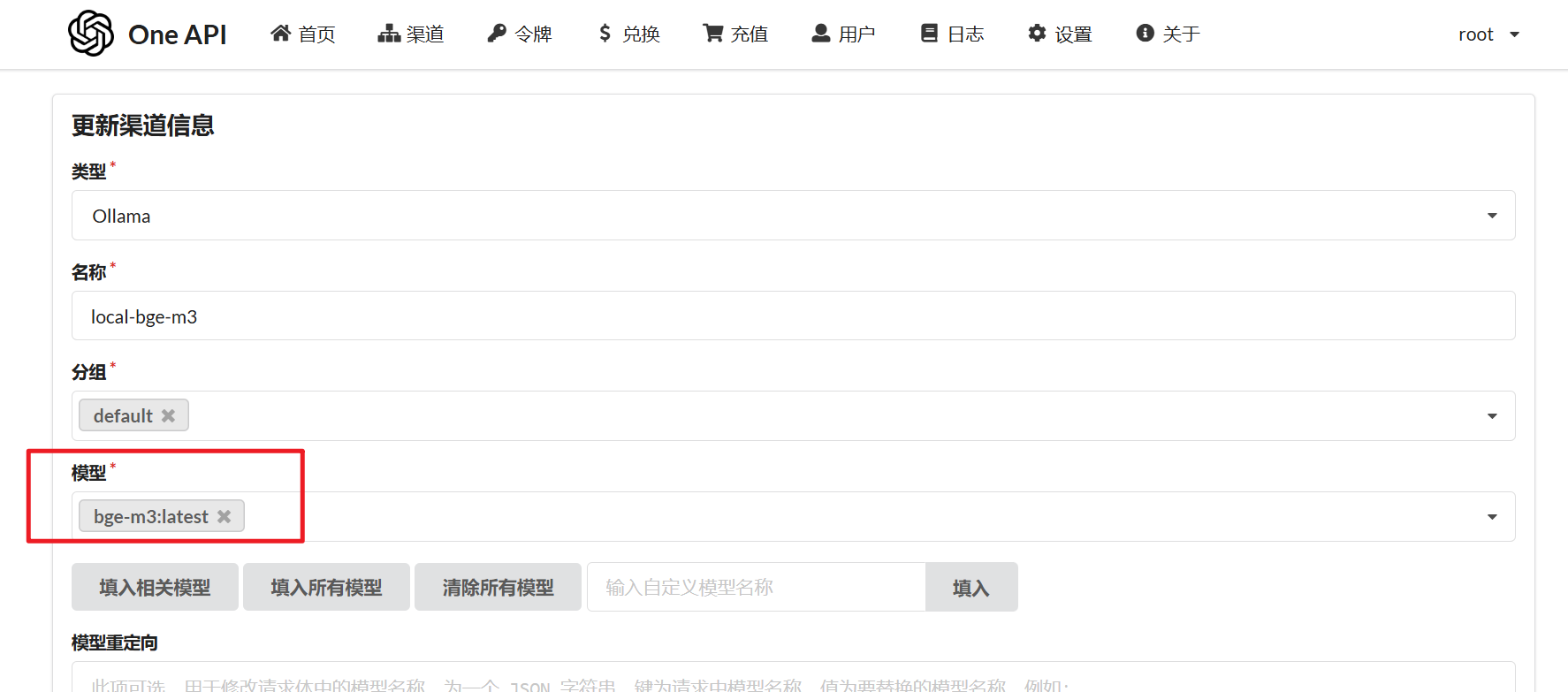
- 模型名称要与
ollama ls中输出的名称相同
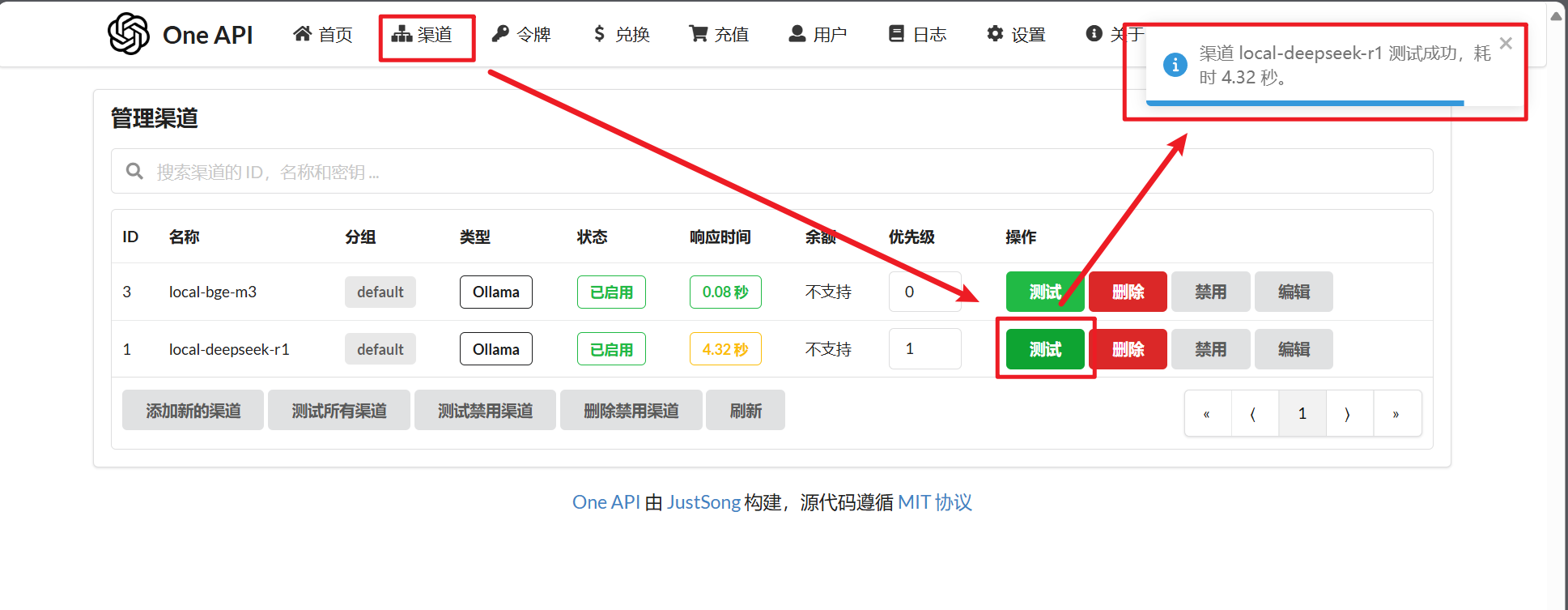
添加完成后,返回【渠道界面】,点击【测试】,应该能输出“测试成功”的信息
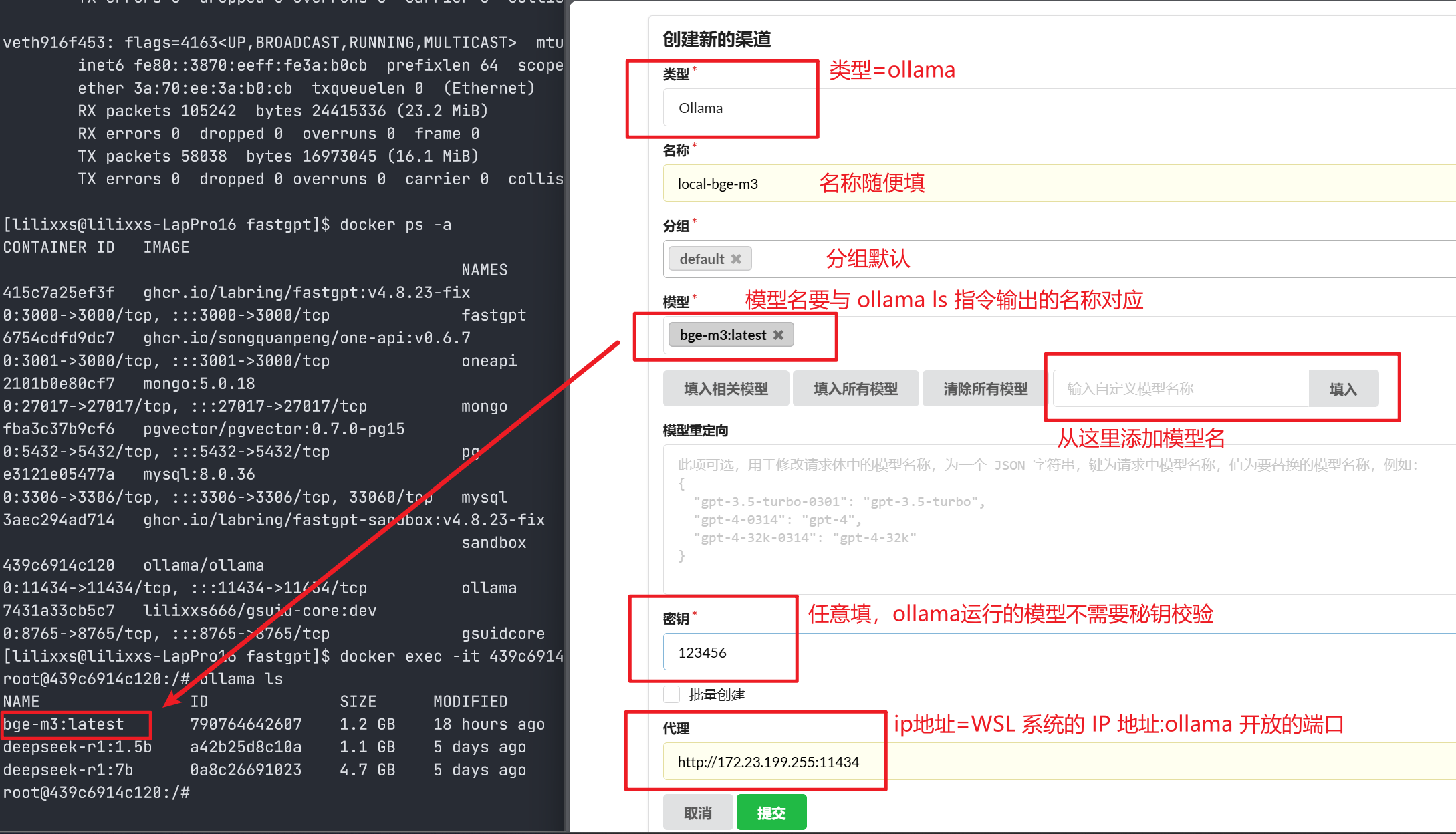
添加向量模型(bge-3m)
按照上面的步骤,同样添加一个新的渠道:- 点击【渠道】–>【添加新的渠道】
- 按照以下方式进行配置(主要注意模型名称,其他配置和上面的 deepseek 配置相同)
配置 FastGPT 接入 FastGPT 渠道
FastGPT 部署完成后,使用http://WSL系统IP地址:3000,在浏览器访问 FastGPT 界面
点击:【账号】–>【模型供应商】–>【模型配置】–>新增模型
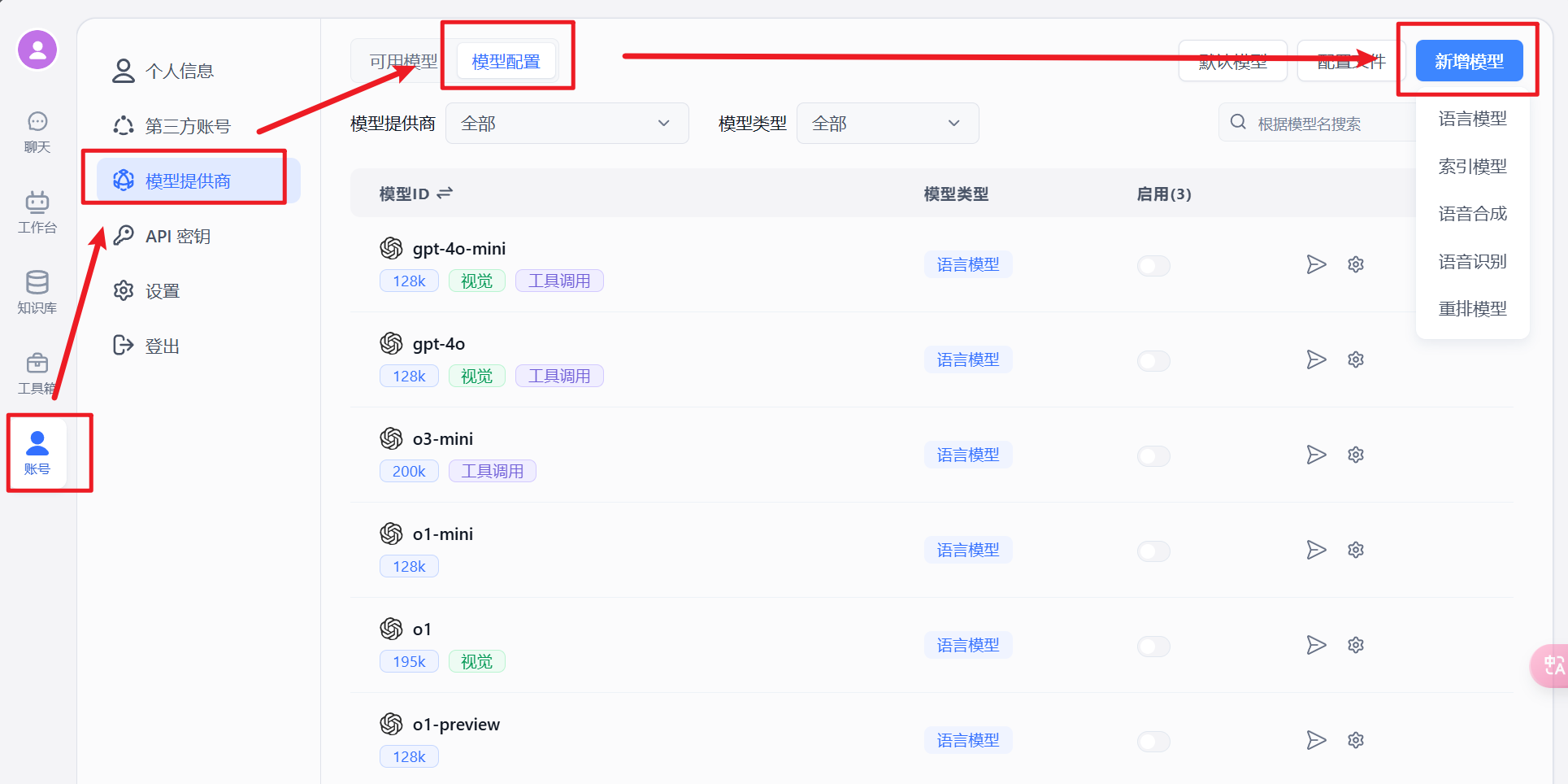
接入 deepseek-r1模型
新增模型 -->【语言模型】具体配置参考 deepseek 官方配置
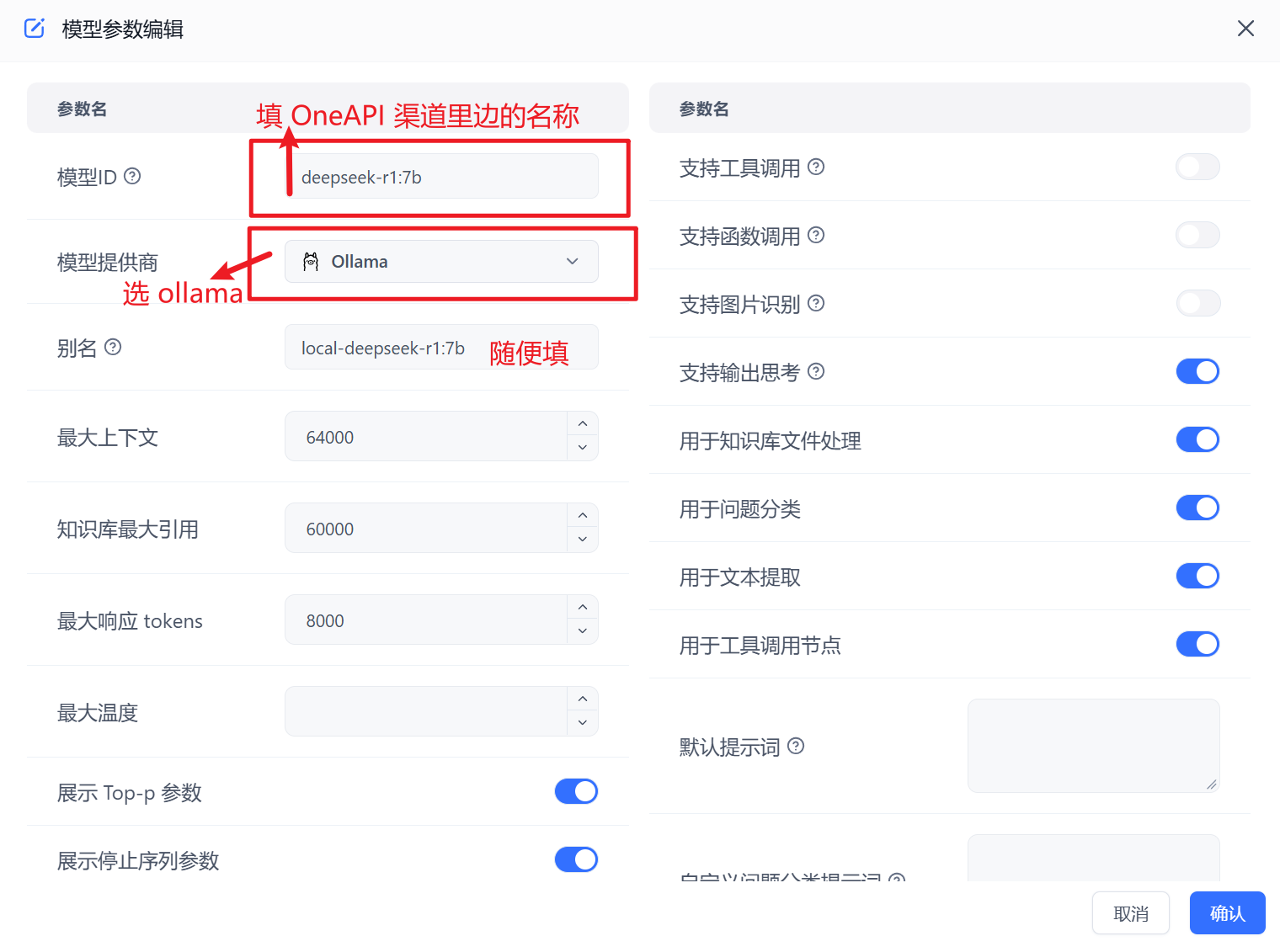
模型 ID 对应 OneAPI 中的模型 ID
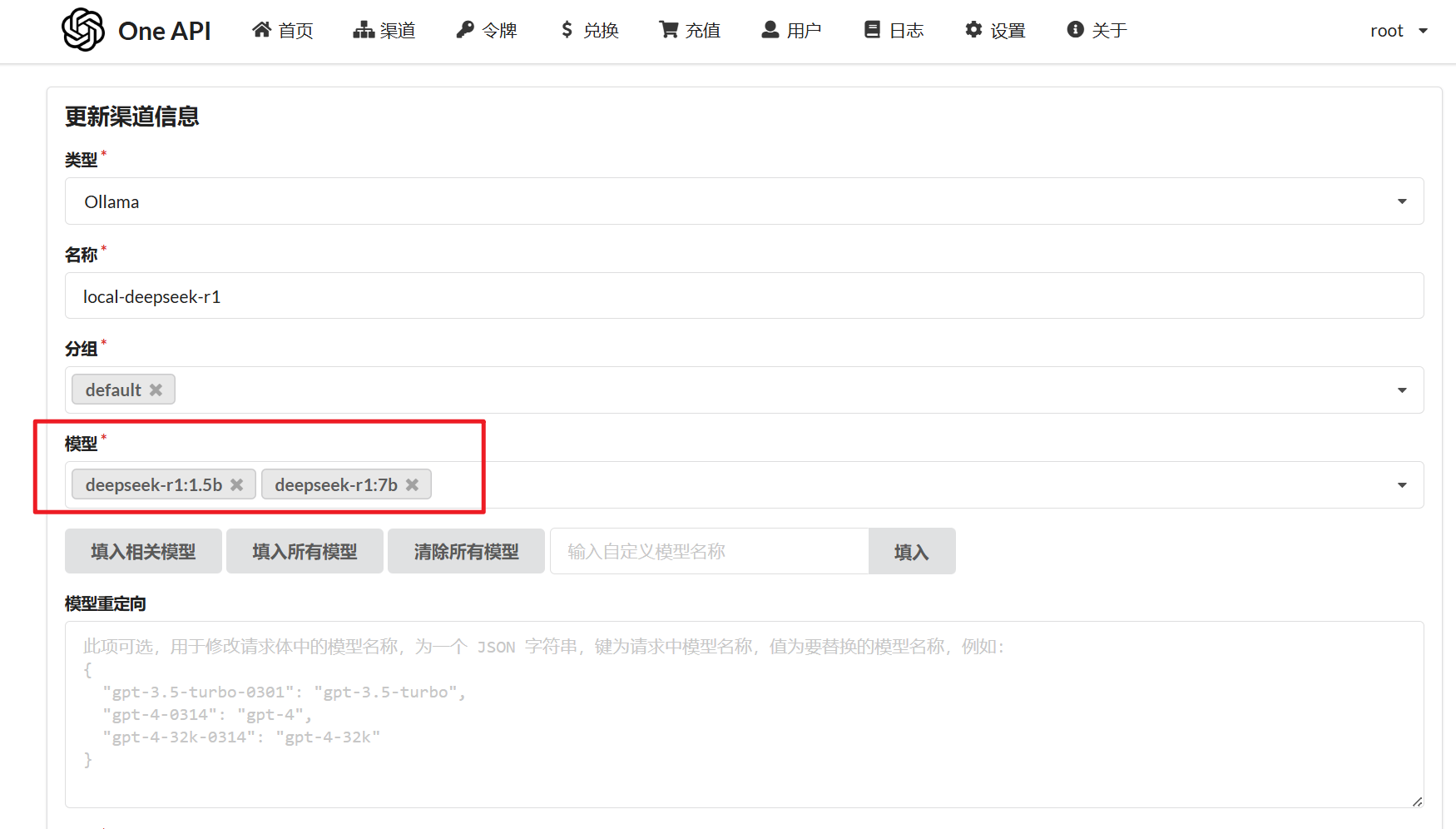
接入 bge-m3 模型
新增模型 -->【语言模型】
整体配置参考 bge-m3 官方配置
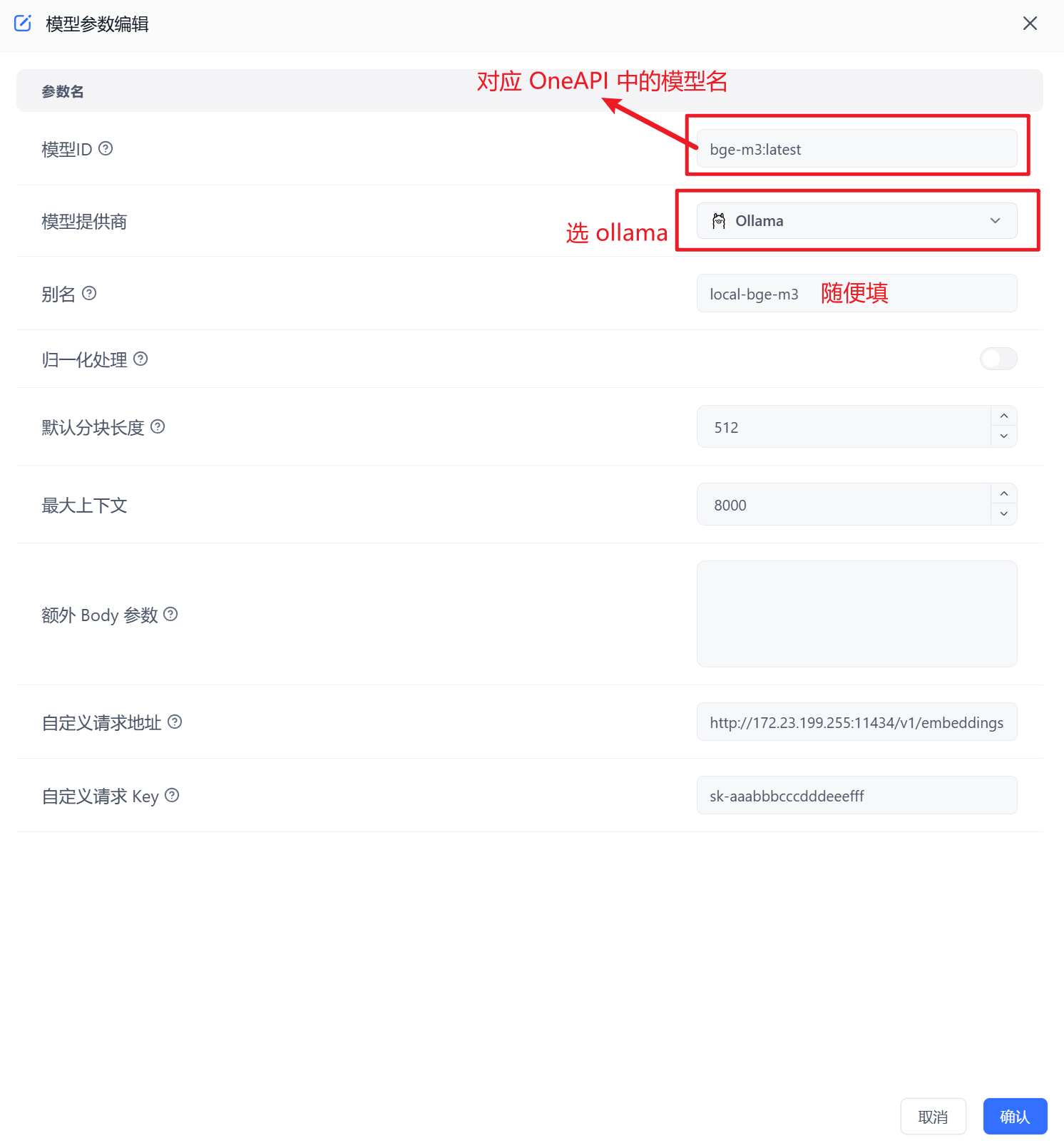
模型 ID 对应 OneAPI 中的模型 ID
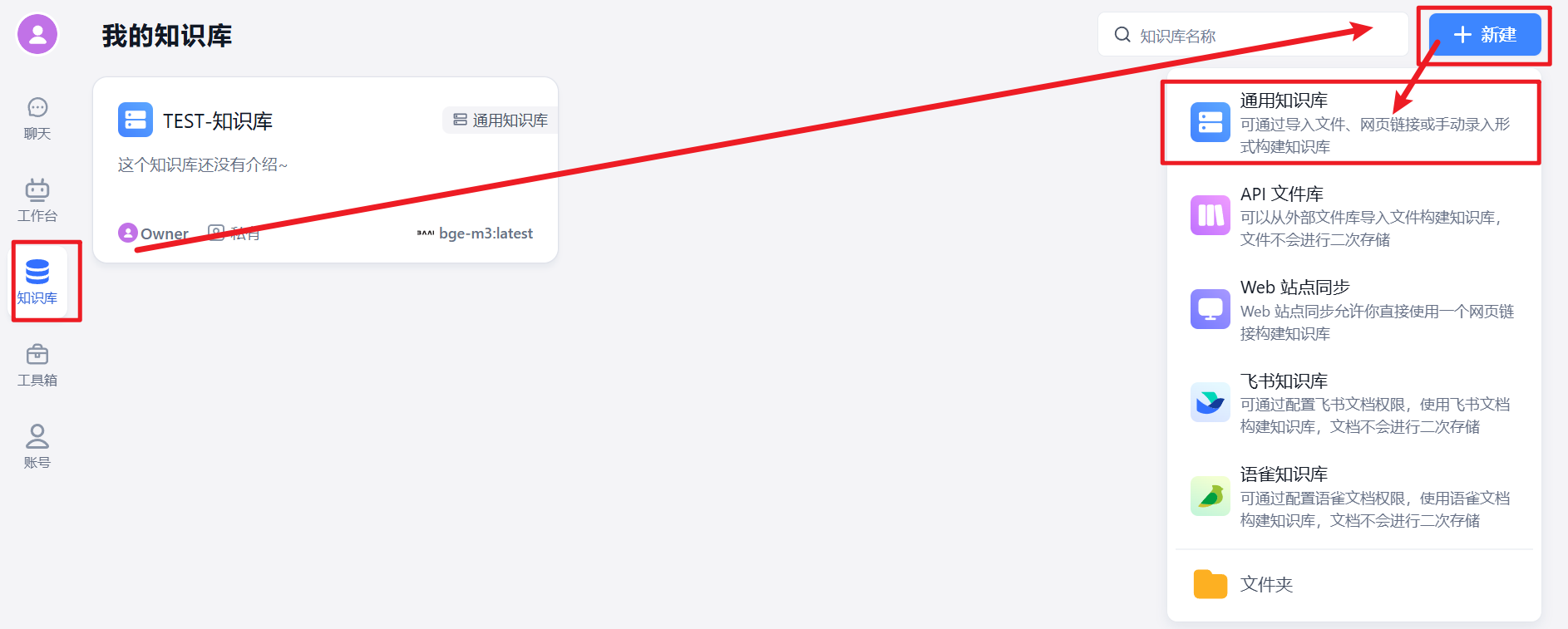
配置知识库
在 FastGPT 界面上,点击【知识库】–>【新建】–>【通用知识库】
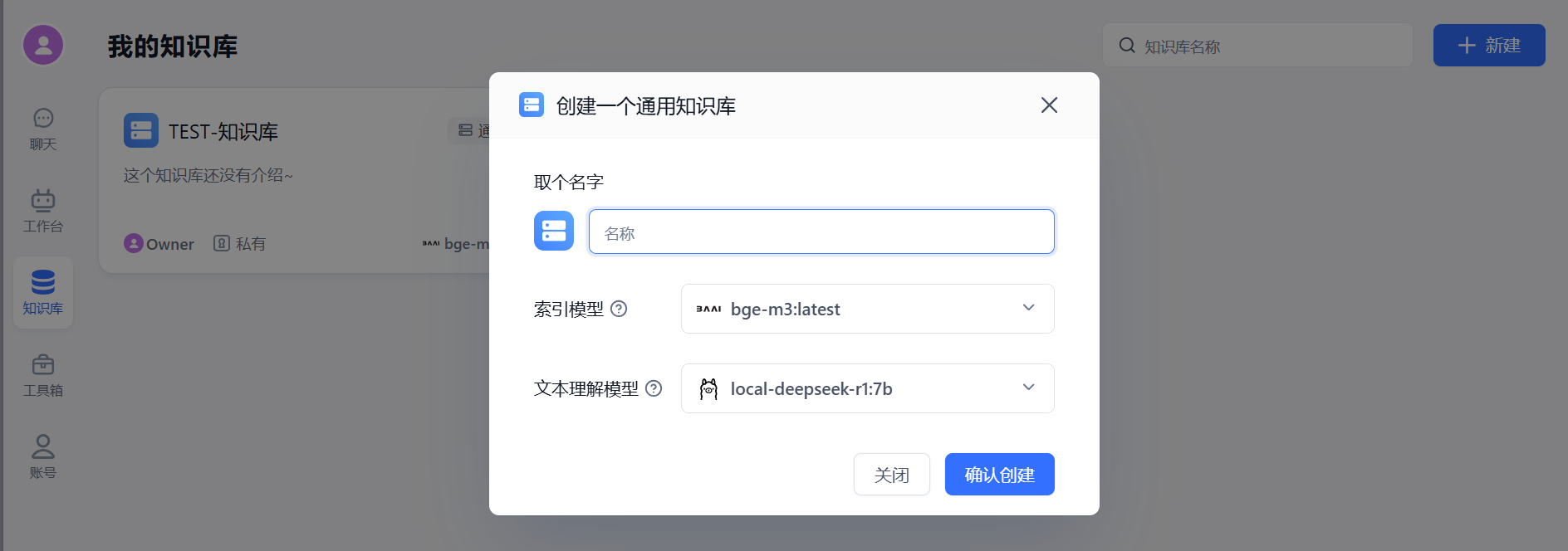
选用对应的向量模型(索引模型)(bge-m3)、语言模型(deepseek-r1:7b)
【新建/导入】–>【文本数据集】–>【本地文件】
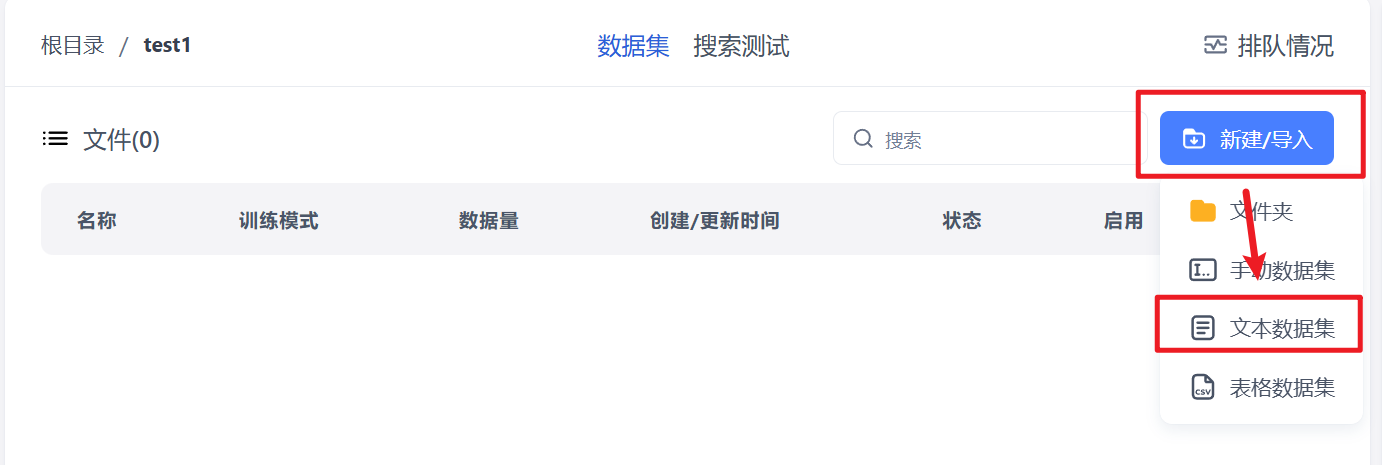
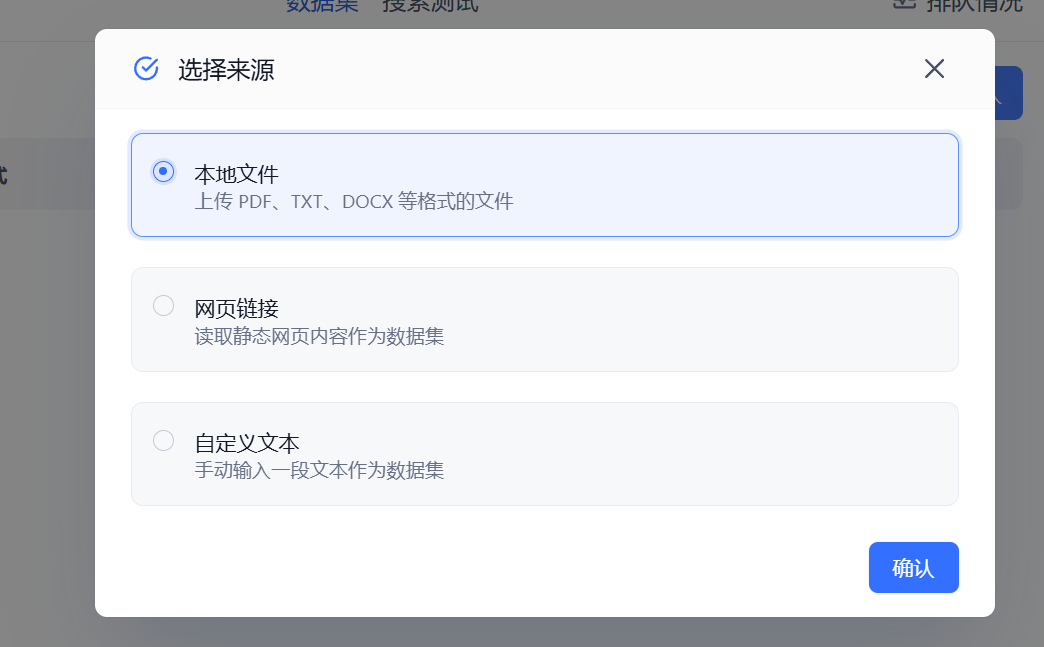
接下来的步骤没图,因为用的是公司内部资料。
实际上照着软件流程走就行了,操作还是很清晰的
上传文件 --> 下一步
处理方式:直接分段、处理参数:自动 -->【下一步】
开始上传
自动运行后,会输出分段结果
如果对分段效果不满意,还可以点击进入对应的数据集,点击【调整训练参数】和【插入】进行更精细的调整
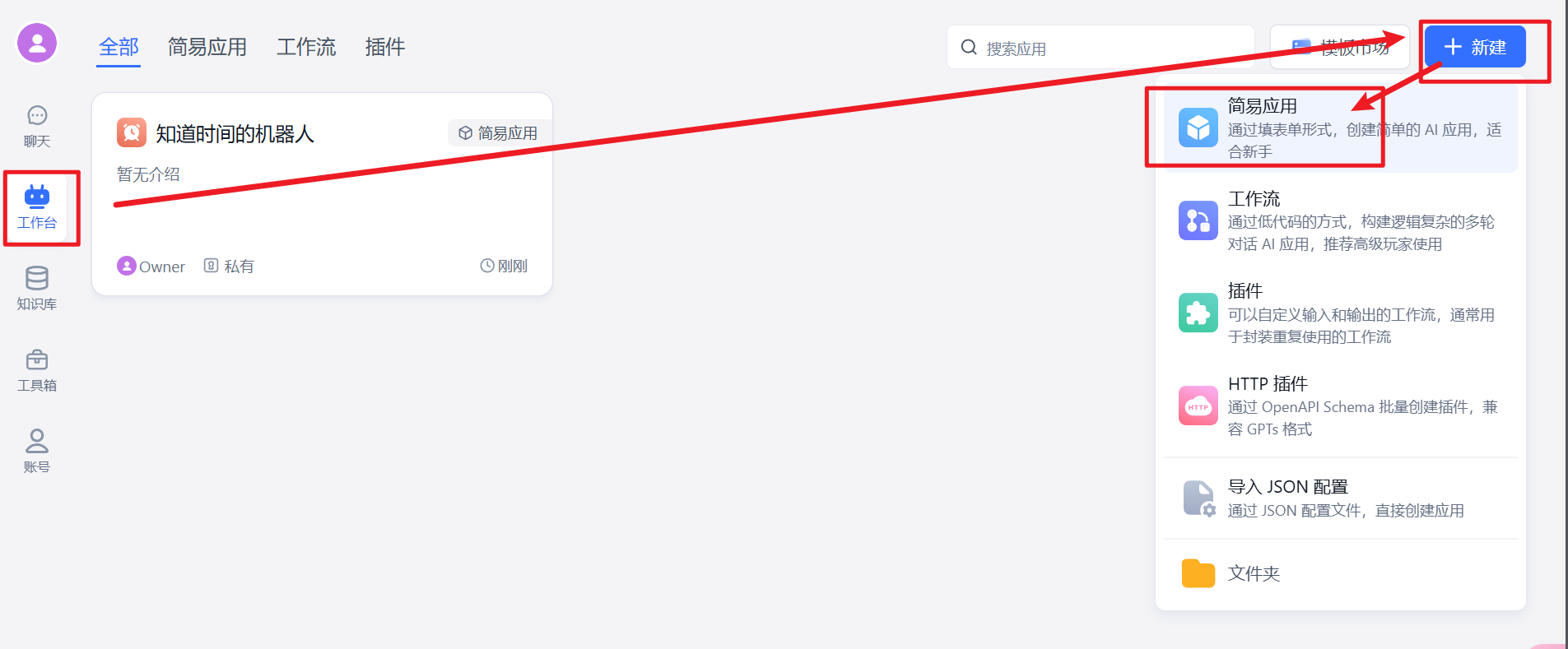
创建 Agent 使用知识库
点击【工作台】–>【新建】–>【简易应用】–>选择模板中的【知识库+对话引导】
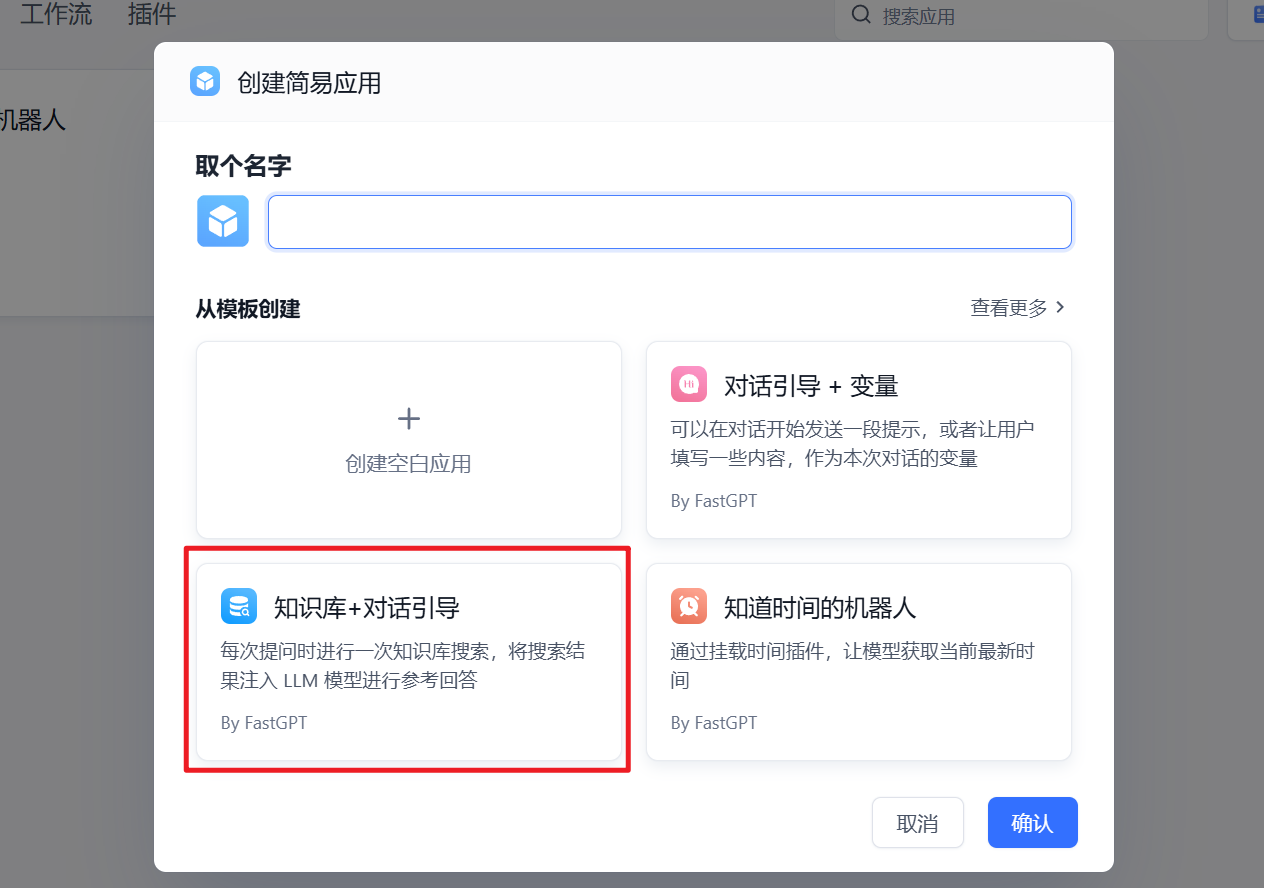
必要的配置
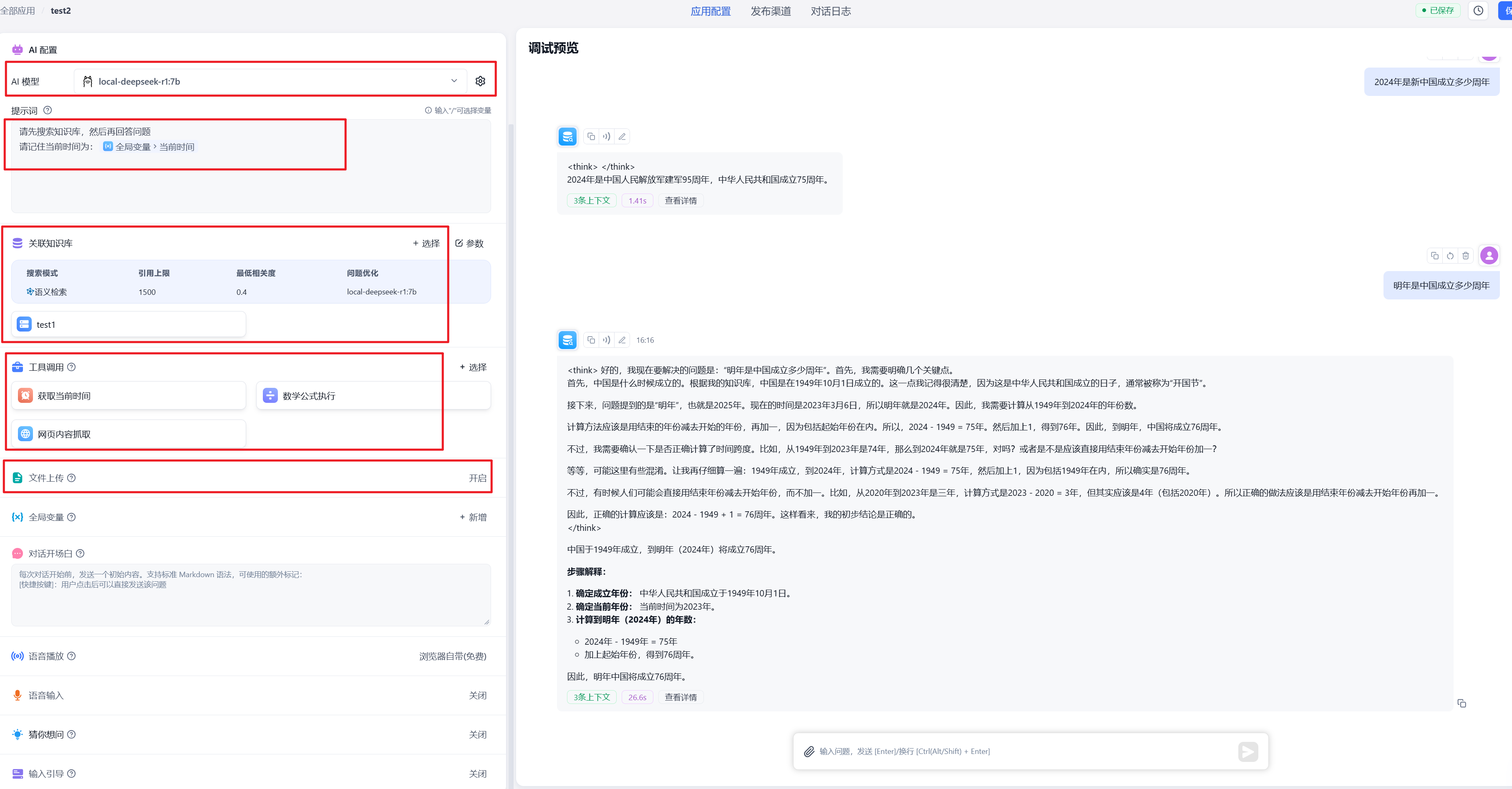
- AI 模型:选择之前接入的 deepseek-r1:7b 模型
- 提示词:可说明当前时间(从全局变量中获取)、要从知识库中查询
- 关联知识库:选择刚才配置的知识库(其实还可以多选知识库,但这样提示词中应该提示不同场景对应不同知识库)
- 工具调用,常用的有:当前时间、数学公式执行、网页内容抓取
- 文件上传:开启
右侧聊天窗口可进行测试
测试完成,点击右上角【保存】–>【保存并发布】,即可生成对应配置的聊天界面

之后可在【聊天】界面、或者调用 API 进行对话

















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









