






文章目录
前言
目标:在ubuntu20.04的noetic的ros环境下,利用mindyolo进行对已知大小的二维码进行识别并进行定位。
环境:mindspore == 2.0.0, cuda-nvcc == 11.6, cuda-version == 11.6, cudatoolkit == 11.6, cudnn ==8.0.0.
1 利用conda安装mindspore和cuda环境
首先安在NVIDIA驱动,可以使用nvidia-smi命令后再安装下列环境。
conda create --name mindspore python=3.7
source activate mindspore
conda install mindspore=2.0.0 -c mindspore -c conda-forge
conda install -c nvidia cuda-nvcc=11.6
conda install cudatoolkit=11.6 -c https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda install cudnn=8.8.0 -c https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
export PATH=/home/robot/anaconda3/envs/mindspore/bin:$PATH
export LD_LIBRARY_PATH=/home/robot/anaconda3/pkgs/cudatoolkit-11.6.2-hfc3e2af_12/lib:$PATH
\$LD_LIBRARY_PATH
以上环境安装成功后,可能会有一些其他库也需要安装,运行的时候会弹出报错,利用pip或者conda安装就好。
2 安装mindyolo目标检测算法
我这里推荐源码安装,因为能安装最新的版本,目前我使用的是0.3.0版本。
git clone https://github.com/mindspore-lab/mindyolo.git
cd mindyolo
pip install -r requirements.txt # 安装依赖,注意版本
pip install -e .
3 制作数据
3.1 采集数据
在ros环境下创建mindyolo功能包,并在其src文件下创建capture_image.cpp文件,将下列代码写入:
#include <ros/ros.h>
#include <stdlib.h>
#include <image_transport/image_transport.h>
#include <opencv2/highgui.hpp>
#include <cv_bridge/cv_bridge.h>
#include <string>
#include <fstream>
// 全局变量,用于存储上次保存的图像文件名中的整数部分
int last_saved_index = 0;
// 获取上次保存的图像文件名中的整数部分
void get_last_saved_index(const std::string& filename) {
std::ifstream file(filename);
std::string line;
if (file.is_open()) {
while (std::getline(file, line)) {
// 解析文件名,获取整数部分
// 假设文件名格式为 xxxxxxx.jpg,其中 xxxxxxx 表示整数部分
std::size_t found = line.find_last_of("/");
std::size_t found2 = line.find_last_of(".");
std::string index_str = line.substr(found + 1, found2 - found - 1);
int index = std::stoi(index_str);
if (index > last_saved_index) {
last_saved_index = index;
}
}
file.close();
}
}
void pic_callback(const sensor_msgs::ImageConstPtr &img_msg) {
ros::Time time = img_msg->header.stamp;
std::string filename_prefix = "/home/robot/catkin_ws/src/mindyolo/VOC2007/JEPGImages/";
// 获取上次保存的图像文件名中的整数部分
get_last_saved_index(filename_prefix + "last_saved.txt");
// 构建新的文件名
std::string filename_suffix = std::to_string(last_saved_index + 1);
std::string filename = filename_prefix + filename_suffix + ".jpg";
cv_bridge::CvImageConstPtr ptr;
ptr = cv_bridge::toCvCopy(img_msg, "bgr8");
printf("%s\n", filename.c_str());
cv::imwrite(filename, ptr->image);
// 将本次保存的整数部分写入文件,以备下次使用
std::ofstream last_saved_file(filename_prefix + "last_saved.txt");
last_saved_file << filename_suffix;
last_saved_file.close();
}
int main(int argc, char **argv) {
ros::init(argc, argv, "img_save");
ros::NodeHandle n;
ros::Subscriber sub_image = n.subscribe(argv[1], 1, pic_callback);
ros::spin();
return 0;
}
记得在CMakeLists.txt文件里添加编译环境。
add_executable(capture_image src/capture_image.cpp)
target_link_libraries(capture_image ${catkin_LIBRARIES} ${OpenCV_LIBS})
回到ros的catkin_ws工作空间使用catkin_make即可。
catkin_make
source ~/catkin_ws/devel/setup.sh
rosrun mindyolo capture_image /camera/left/image_raw #/camera/left/image_raw是你照相机的话题
运行后就可以在目录“/home/robot/catkin_ws/src/mindyolo/VOC2007/JEPGImages/"获得照片。
需要更改目录的话,请更改capture_image.cpp代码里的filename_prefix。
3.2 使用labelimg标注数据
安装labelimg
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
然后准备我们需要打标注的数据集。这里我建议新建一个名为VOC2007的文件夹,里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;再创建一个名为Annotations存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别
具体标注操作方式详见:https://blog.csdn.net/didiaopao/article/details/119808973?spm=1001.2014.3001.5506
3.3 生成voc数据集
在目录/home/robot/mindyolo/examples/code/VOC2007下创建getvoc.py文件:
#getvoc.py
#-*- coding:utf-8 -*-
import os
import random
import numpy as np
xml_file_path = "/home/robot/mindyolo/examples/code/VOC2007/Annotations"
target_path = "/home/robot/mindyolo/examples/code/VOC2007/ImageSets/Main"
# perception
trainval = 0.9 # (num of trainval set) / (num of all samples)
train = 0.8 # (num of train set) / (num of trainval set)
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
elif os.path.splitext(file_path)[1] == '.xml':
tmp = os.path.splitext(file_path)[0]
# Extract the numeric part of the file name
file_name = os.path.basename(tmp)
numeric_part = ''.join(filter(str.isdigit, file_name))
list_name.append(int(numeric_part))
file_list = []
listdir(xml_file_path, file_list)
num_of_files = len(file_list)
num_of_trainval = int(trainval * num_of_files)
num_of_train = int(train * num_of_trainval)
# divide samples in trainval and test
trainval_list = np.sort(random.sample(file_list, num_of_trainval))
test_list = np.sort(np.setdiff1d(file_list, trainval_list))
# divide trainval in train and value
train_list = np.sort(random.sample(list(trainval_list), num_of_train))
value_list = np.sort(np.setdiff1d(trainval_list, train_list))
print(trainval_list)
print(test_list)
print(train_list)
print(value_list)
# Save lists to text files
file = open(target_path + '/trainval.txt', 'w')
for var in trainval_list:
file.write(str(var) + '\n')
file.close()
file = open(target_path + '/test.txt', 'w')
for var in test_list:
file.write(str(var) + '\n')
file.close()
file = open(target_path + '/train.txt', 'w')
for var in train_list:
file.write(str(var) + '\n')
file.close()
file = open(target_path + '/val.txt', 'w')
for var in value_list:
file.write(str(var) + '\n')
file.close()
注意:
我采集的图片是放在了ros工作空间下,这里将数据集复制到了mindyolo下,使用的时候注意文件路径就好,例如xml_file_path和target_path需要修改。
并且,需要在VOC2007文件目录下创建ImageSets文件夹和ImageSets/main文件夹,因为我的程序里面没有直接创建,需要注意一下。
运行脚本就可以在同目录下生成VOC文件了
python3 getvoc.py
3.4 转为yolo格式
在/home/robot/mindyolo/examples/code目录下(和刚刚的VOC2007一个目录就行),这个code目录是我自己创建的,git官方库是没有的,这里是为了方便管理,
这是我的code目录
├── convert_shwd2yolo.py
├── SHWD
│ ├── annotations
│ ├── images
│ ├── labels
│ ├── train.cache.npy
│ ├── train.txt
│ └── val.txt
├── VOC2007
│ ├── Annotations
│ ├── getvoc.py
│ ├── ImageSets
│ ├── JPEGImages
│ └── predefined_classes.txt
├── yolov7-tiny_300e_mAP375-d8972c94.ckpt
└── yolov7-tiny_shwd.yaml
创建voc数据转化yolo数据脚本convert_shwd2yolo.py
#convert_shwd2yolo.py
import os
from pathlib import Path
import argparse
import shutil
import xml.etree.ElementTree as ET
import collections
import json
from tqdm import tqdm
category_set = ['tb0', 'tb1', 'tb2', 'tb3', 'tb4']
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_item_id = 0
annotation_id = 0
image_index = 0
def addCatItem(name):
global category_item_id
category_item = collections.OrderedDict()
category_item['supercategory'] = 'none'
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_item_id += 1
def addImgItem(image_id, size):
file_name = str(image_id).zfill(8) + '.jpg'
if not size['width']:
raise Exception('Could not find width tag in xml file.')
if not size['height']:
raise Exception('Could not find height tag in xml file.')
image_item = collections.OrderedDict()
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
image_item['id'] = image_id
coco['images'].append(image_item)
def addAnnoItem(image_id, category_id, bbox):
global annotation_id
annotation_item = collections.OrderedDict()
annotation_item['segmentation'] = []
# segmentation
seg = []
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_item['id'] = annotation_id
annotation_item['ignore'] = 0
annotation_id += 1
coco['annotations'].append(annotation_item)
def xxyy2xywhn(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
x = round(x, 6)
w = round(w, 6)
y = round(y, 6)
h = round(h, 6)
return x, y, w, h
def xml2txt(xml_path, txt_path):
in_file = open(xml_path, encoding='utf-8')
out_file = open(txt_path, 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in category_set or int(difficult) == 1:
continue
cls_id = category_set.index(cls)
xmlbox = obj.find('bndbox')
x1, x2, y1, y2 = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
# clip x2, y2 to normal range
if x2 > w:
x2 = w
if y2 > h:
y2 = h
# xyxy2xywhn
bbox = (x1, x2, y1, y2)
bbox = xxyy2xywhn((w, h), bbox)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bbox]) + '\n')
def xml2json(image_index, xml_path):
bndbox = dict()
size = dict()
size['width'] = None
size['height'] = None
tree = ET.parse(xml_path)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# elem format: <folder>, <filename>, <size>, <object>
for elem in root:
if elem.tag == 'folder' or elem.tag == 'filename' or elem.tag == 'path' or elem.tag == 'source':
continue
elif elem.tag == 'size':
# add image information, like file_name, size, image_id
for subelem in elem:
size[subelem.tag] = int(subelem.text)
addImgItem(image_index, size)
elif elem.tag == 'object':
for subelem in elem:
if subelem.tag == 'name':
object_name = subelem.text
current_category_id = category_set.index(object_name)
elif subelem.tag == 'bndbox':
for option in subelem:
bndbox[option.tag] = int(option.text)
bbox = []
bbox.append(bndbox['xmin'])
bbox.append(bndbox['ymin'])
bbox.append(bndbox['xmax'] - bndbox['xmin'])
bbox.append(bndbox['ymax'] - bndbox['ymin'])
# add bound box information, include area,image_id, bbox, category_id, id and so on
addAnnoItem(image_index, current_category_id, bbox)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--root_dir', default='', type=str, help='root directory of data set')
opt = parser.parse_args()
# generate directory structure
root_dir = opt.root_dir
#print(root_dir)
new_dir = os.path.join(root_dir, '..', 'SHWD')
os.makedirs(os.path.join(new_dir, 'images', 'train'))
os.makedirs(os.path.join(new_dir, 'images', 'val'))
os.makedirs(os.path.join(new_dir, 'labels', 'train'))
os.makedirs(os.path.join(new_dir, 'labels', 'val'))
os.makedirs(os.path.join(new_dir, 'annotations'))
train_txt_yolo = open(os.path.join(new_dir, 'train.txt'), 'w')
val_txt_yolo = open(os.path.join(new_dir, 'val.txt'), 'w')
images_path = os.path.join(root_dir, 'JPEGImages')
labels_path = os.path.join(root_dir, 'Annotations')
#print(images_path)
#print(labels_path)
train_set_txt = os.path.join(root_dir, 'ImageSets', 'Main', 'trainval.txt')
with open(train_set_txt, 'r', encoding='utf-8') as f:
for line in tqdm(f.readlines(), desc='train_set'):
stem = line.strip('\n')
old_path = os.path.join(images_path, stem + '.jpg')
print(os.path.exists(old_path))
if not os.path.exists(old_path):
old_path = os.path.join(images_path, stem + '.JPG')
# copy train_set image to new path
new_images_path = os.path.join(new_dir, 'images', 'train')
shutil.copy(old_path, new_images_path)
# rename image_file to continuous number
old_name = Path(old_path).name
new_stem = str(image_index).zfill(8)
os.rename(os.path.join(new_images_path, old_name), os.path.join(new_images_path, new_stem + '.jpg'))
# write the relative path of image to train.txt
train_txt_yolo.write('./images/train/' + new_stem + '.jpg' + '\n')
# convert xml file to txt file
xml_path = os.path.join(labels_path, stem + '.xml')
txt_path = os.path.join(new_dir, 'labels', 'train', new_stem + '.txt')
xml2txt(xml_path, txt_path)
image_index += 1
val_set_txt = os.path.join(root_dir, 'ImageSets', 'Main', 'test.txt')
with open(val_set_txt, 'r', encoding='utf-8') as f:
for line in tqdm(f.readlines(), desc='val_set'):
stem = line.strip('\n')
old_path = os.path.join(images_path, stem + '.jpg')
#print(old_path)
if not os.path.exists(old_path):
old_path = os.path.join(images_path, stem + '.JPG')
# copy val_set image to new path
new_images_path = os.path.join(new_dir, 'images', 'val')
shutil.copy(old_path, new_images_path)
# rename image_file to continuous number
old_name = Path(old_path).name
new_stem = str(image_index).zfill(8)
os.rename(os.path.join(new_images_path, old_name), os.path.join(new_images_path, new_stem + '.jpg'))
# write the relative path of image to val.txt
val_txt_yolo.write('./images/val/' + new_stem + '.jpg' + '\n')
# convert xml file to txt file
xml_path = os.path.join(labels_path, stem + '.xml')
txt_path = os.path.join(new_dir, 'labels', 'val', new_stem + '.txt')
xml2txt(xml_path, txt_path)
# convert xml file to json file
xml2json(image_index, xml_path)
image_index += 1
for categoryname in category_set:
addCatItem(categoryname)
train_txt_yolo.close()
val_txt_yolo.close()
# save ground truth json file
json_file = os.path.join(new_dir, 'annotations', 'instances_val2017.json')
json.dump(coco, open(json_file, 'w'))
注意:
category_set = [‘tb0’, ‘tb1’, ‘tb2’, ‘tb3’, ‘tb4’]需要更换成自己的标签
如果遇到报错,解决后记得把生成的文件删除后重新运行,否则会报错文件已经存在。
执行脚本convert_shwd2yolo.py,我这里使用的是绝对路径,使用的时候一定要注意更换路径。
python /home/robot/mindyolo/examples/code/convert_shwd2yolo.py --root_dir /home/robot/mindyolo/examples/code/SHWD
4 训练权重
根据自己需求调整配置文件yolov7-tiny_shwd.yaml
__BASE__: [
'../../configs/yolov7/yolov7-tiny.yaml',
]
per_batch_size: 1 # 16 * 8 = 128 因为我用的4060ti训练,调的比较小,这里是指同时多少张图片进行训练。
img_size: 2048 # image sizes,因为我的摄像机是2048*1536分辨率
#weight: ./yolov7-tiny_pretrain.ckpt
weight: ./examples/code/yolov7-tiny_300e_mAP375-d8972c94.ckpt #预训练权重需要自行下载。
strict_load: False
conf_thres: 0.6 ##这里是指:只显示高于0.6置信度的结果
iou_thres: 0.5 ##这里是指:只显示有0.5的重合度,就是同一个结果。
data:
dataset_name: shwd
train_set: ./examples/code/SHWD/train.txt
val_set: ./examples/code/SHWD/val.txt
test_set: ./examples/code/SHWD/val.txt
nc: 5##一定要换成自己的类别数量
# class names
names: [ 'tb0', 'tb1', 'tb2', 'tb3', 'tb4']##这里一定要换成自己的标签
optimizer:
lr_init: 0.001 # initial learning rate
在官网https://github.com/mindspore-lab/mindyolo/blob/master/MODEL_ZOO.md下载需要的预训练权重,我这里使用的是yolov7-tiny_300e_mAP375-d8972c94.ckpt
使用mindyolo进行训练,生成的权重默认在/home/robot/mindyolo/runs目录下,指令是:
#在mindyolo目录下执行
python train.py --config ./examples/code/yolov7-tiny_shwd.yaml --device_target GPU
使用推理进行测试效果,注意路径更换–config后面是配置文件的路径,–weight是权重的路径,–image_path是图片的路径
python demo/predict.py --config ./examples/code/yolov7-tiny_shwd.yaml --weight=./weight/yolov7-tiny_shwd-300_27.ckpt --image_path ./examples/code/SHWD/images/train/00000000.jpg --device_target GPU
效果如下:

5 通过ros实时检测(工作还在进行中)
在ros的mindyolo工作空间创建yolo_ros.py文件
#/home/robot/catkin_ws/src/mindyolo目录下:
mkdir node
touch yolo_ros.py
yolo_ros.py代码如下:
import argparse
import ast
import math
import os
import sys
import time
import cv2
import numpy as np
import yaml
from datetime import datetime
import mindspore as ms
from mindspore import Tensor, context, nn
from mindyolo.data import COCO80_TO_COCO91_CLASS
from mindyolo.models import create_model
from mindyolo.utils import logger
from mindyolo.utils.config import parse_args
from mindyolo.utils.metrics import non_max_suppression, scale_coords, xyxy2xywh, process_mask_upsample, scale_image
from mindyolo.utils.utils import draw_result, set_seed
import rospy
from sensor_msgs.msg import Image
from ros_numpy.image import image_to_numpy, numpy_to_image
import sys
sys.path.append('/home/robot/mindyolo')
def get_parser_infer(parents=None):
parser = argparse.ArgumentParser(description="Infer", parents=[parents] if parents else [])
parser.add_argument("--task", type=str, default="detect", choices=["detect", "segment"])
parser.add_argument("--device_target", type=str, default="Ascend", help="device target, Ascend/GPU/CPU")
parser.add_argument("--ms_mode", type=int, default=0, help="train mode, graph/pynative")
parser.add_argument("--ms_amp_level", type=str, default="O0", help="amp level, O0/O1/O2")
parser.add_argument(
"--ms_enable_graph_kernel", type=ast.literal_eval, default=False, help="use enable_graph_kernel or not"
)
parser.add_argument("--weight", type=str, default="yolov7_300.ckpt", help="model.ckpt path(s)")
parser.add_argument("--img_size", type=int, default=640, help="inference size (pixels)")
parser.add_argument(
"--single_cls", type=ast.literal_eval, default=False, help="train multi-class data as single-class"
)
parser.add_argument("--nms_time_limit", type=float, default=60.0, help="time limit for NMS")
parser.add_argument("--conf_thres", type=float, default=0.25, help="object confidence threshold")
parser.add_argument("--iou_thres", type=float, default=0.65, help="IOU threshold for NMS")
parser.add_argument(
"--conf_free", type=ast.literal_eval, default=False, help="Whether the prediction result include conf"
)
parser.add_argument("--seed", type=int, default=2, help="set global seed")
parser.add_argument("--log_level", type=str, default="INFO", help="save dir")
parser.add_argument("--save_dir", type=str, default="./runs_infer", help="save dir")
parser.add_argument("--image_path", type=str, help="path to image")
parser.add_argument("--save_result", type=ast.literal_eval, default=True, help="whether save the inference result")
return parser
def set_default_infer(args):
# Set Context
context.set_context(mode=args.ms_mode, device_target=args.device_target, max_call_depth=2000)
if args.device_target == "Ascend":
context.set_context(device_id=int(os.getenv("DEVICE_ID", 0)))
elif args.device_target == "GPU" and args.ms_enable_graph_kernel:
context.set_context(enable_graph_kernel=True)
args.rank, args.rank_size = 0, 1
# Set Data
args.data.nc = 1 if args.single_cls else int(args.data.nc) # number of classes
args.data.names = ["item"] if args.single_cls and len(args.names) != 1 else args.data.names # class names
assert len(args.data.names) == args.data.nc, "%g names found for nc=%g dataset in %s" % (
len(args.data.names),
args.data.nc,
args.config,
)
# Directories and Save run settings
platform = sys.platform
if platform == "win32":
args.save_dir = os.path.join(args.save_dir, datetime.now().strftime("%Y.%m.%d-%H.%M.%S"))
else:
args.save_dir = os.path.join(args.save_dir, datetime.now().strftime("%Y.%m.%d-%H:%M:%S"))
os.makedirs(args.save_dir, exist_ok=True)
if args.rank % args.rank_size == 0:
with open(os.path.join(args.save_dir, "cfg.yaml"), "w") as f:
yaml.dump(vars(args), f, sort_keys=False)
# Set Logger
logger.setup_logging(logger_name="MindYOLO", log_level="INFO", rank_id=args.rank, device_per_servers=args.rank_size)
logger.setup_logging_file(log_dir=os.path.join(args.save_dir, "logs"))
def detect(
network: nn.Cell,
img: np.ndarray,
conf_thres: float = 0.25,
iou_thres: float = 0.65,
conf_free: bool = False,
nms_time_limit: float = 60.0,
img_size: int = 640,
stride: int = 32,
num_class: int = 80,
is_coco_dataset: bool = True,
):
# Resize
h_ori, w_ori = img.shape[:2] # orig hw
r = img_size / max(h_ori, w_ori) # resize image to img_size
if r != 1: # always resize down, only resize up if training with augmentation
interp = cv2.INTER_AREA if r < 1 else cv2.INTER_LINEAR
img = cv2.resize(img, (int(w_ori * r), int(h_ori * r)), interpolation=interp)
h, w = img.shape[:2]
if h < img_size or w < img_size:
new_h, new_w = math.ceil(h / stride) * stride, math.ceil(w / stride) * stride
dh, dw = (new_h - h) / 2, (new_w - w) / 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(
img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)
) # add border
# Transpose Norm
img = img[:, :, ::-1].transpose(2, 0, 1) / 255.0
imgs_tensor = Tensor(img[None], ms.float32)
# Run infer
_t = time.time()
out = network(imgs_tensor) # inference and training outputs
out = out[0] if isinstance(out, (tuple, list)) else out
infer_times = time.time() - _t
# Run NMS
t = time.time()
out = out.asnumpy()
out = non_max_suppression(
out,
conf_thres=conf_thres,
iou_thres=iou_thres,
conf_free=conf_free,
multi_label=True,
time_limit=nms_time_limit,
)
nms_times = time.time() - t
# logger.info(f"out is: {out}")
result_dict = {"category_id": [], "bbox": [], "score": []}
total_category_ids, total_bboxes, total_scores = [], [], []
for si, pred in enumerate(out):
if len(pred) == 0:
continue
# Predictions
predn = np.copy(pred)
scale_coords(img.shape[1:], predn[:, :4], (h_ori, w_ori)) # native-space pred
box = xyxy2xywh(predn[:, :4]) # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
category_ids, bboxes, scores = [], [], []
for p, b in zip(pred.tolist(), box.tolist()):
category_ids.append(COCO80_TO_COCO91_CLASS[int(p[5])] if is_coco_dataset else int(p[5]))
bboxes.append([round(x, 3) for x in b])
scores.append(round(p[4], 5))
total_category_ids.extend(category_ids)
total_bboxes.extend(bboxes)
total_scores.extend(scores)
result_dict["category_id"].extend(total_category_ids)
result_dict["bbox"].extend(total_bboxes)
result_dict["score"].extend(total_scores)
t = tuple(x * 1e3 for x in (infer_times, nms_times, infer_times + nms_times)) + (img_size, img_size, 1) # tuple
logger.info(f"Predict result is: {result_dict}")
logger.info(f"Speed: %.1f/%.1f/%.1f ms inference/NMS/total per %gx%g image at batch-size %g;" % t)
logger.info(f"Detect a image success.")
return result_dict
def infer(args, img):
# Init
set_seed(args.seed)
set_default_infer(args)
# Create Network
network = create_model(
model_name=args.network.model_name,
model_cfg=args.network,
num_classes=args.data.nc,
sync_bn=False,
checkpoint_path=args.weight,
)
network.set_train(False)
ms.amp.auto_mixed_precision(network, amp_level=args.ms_amp_level)
# Detect
is_coco_dataset = "coco" in args.data.dataset_name
if args.task == "detect":
result_dict = detect(
network=network,
img=img,
conf_thres=args.conf_thres,
iou_thres=args.iou_thres,
conf_free=args.conf_free,
nms_time_limit=args.nms_time_limit,
img_size=args.img_size,
stride=max(max(args.network.stride), 32),
num_class=args.data.nc,
is_coco_dataset=is_coco_dataset,
)
logger.info("Infer completed.")
def draw_image(im, result_dict, data_names, is_coco_dataset=True):
import random
import cv2
from mindyolo.data import COCO80_TO_COCO91_CLASS
category_id, bbox, score = result_dict["category_id"], result_dict["bbox"], result_dict["score"]
seg = result_dict.get("segmentation", None)
mask = None if seg is None else np.zeros_like(im, dtype=np.float32)
for i in range(len(bbox)):
# draw box
x_l, y_t, w, h = bbox[i][:]
x_r, y_b = x_l + w, y_t + h
x_l, y_t, x_r, y_b = int(x_l), int(y_t), int(x_r), int(y_b)
_color = [random.randint(0, 255) for _ in range(3)]
cv2.rectangle(im, (x_l, y_t), (x_r, y_b), tuple(_color), 2)
if seg:
_color_seg = np.array([random.randint(0, 255) for _ in range(3)], np.float32)
mask += seg[i][:, :, None] * _color_seg[None, None, :]
# draw label
if is_coco_dataset:
class_name_index = COCO80_TO_COCO91_CLASS.index(category_id[i])
else:
class_name_index = category_id[i]
class_name = data_names[class_name_index] # args.data.names[class_name_index]
text = f"{class_name}: {score[i]}"
(text_w, text_h), baseline = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)
cv2.rectangle(im, (x_l, y_t - text_h - baseline), (x_l + text_w, y_t), tuple(_color), -1)
cv2.putText(im, text, (x_l, y_t - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 2)
# save results
if seg:
im = (0.7 * im + 0.3 * mask).astype(np.uint8)
return im
class YoloxRos(object):
def __init__(self, args):
self.args = args
set_seed(self.args.seed)
set_default_infer(self.args)
self.network = create_model(
model_name=self.args.network.model_name,
model_cfg=self.args.network,
num_classes=self.args.data.nc,
sync_bn=False,
checkpoint_path=self.args.weight,
)
self.network.set_train(False)
ms.amp.auto_mixed_precision(self.network, amp_level=self.args.ms_amp_level)
self.image_subscriber = rospy.Subscriber('/camera/left/image_raw', Image, callback=self.image_callback, queue_size=1)
self.image_publisher = rospy.Publisher('/image_publish', Image, queue_size=1)
def image_callback(self, msg):
image = image_to_numpy(msg)
result_image = self.process_image(image)
self.image_publisher.publish(numpy_to_image(result_image, encoding='bgr8'))
def process_image(self, img):
is_coco_dataset = "coco" in self.args.data.dataset_name
if self.args.task == "detect":
result_dict = detect(
network=self.network,
img=img,
conf_thres=self.args.conf_thres,
iou_thres=self.args.iou_thres,
conf_free=self.args.conf_free,
nms_time_limit=self.args.nms_time_limit,
img_size=self.args.img_size,
stride=max(max(self.args.network.stride), 32),
num_class=self.args.data.nc,
is_coco_dataset=is_coco_dataset,
)
# 假设图像数据存储在'image'键中
result_image = draw_image(img, result_dict, args.data.names, is_coco_dataset=is_coco_dataset)
return result_image
if __name__ == "__main__":
rospy.init_node('yolox_ros_node')
parser = get_parser_infer()
args = parse_args(parser)
yolox_ros = YoloxRos(args)
rospy.spin()
运行指令:
python yolo_ros.py --config /home/robot/mindyolo/examples/code/yolov7-tiny_shwd.yaml --weight=/home/robot/mindyolo/weight/yolov7-tiny_shwd-300_27.ckpt --device GPU
实验效果,能够实现实时定位,但精度有待提高。
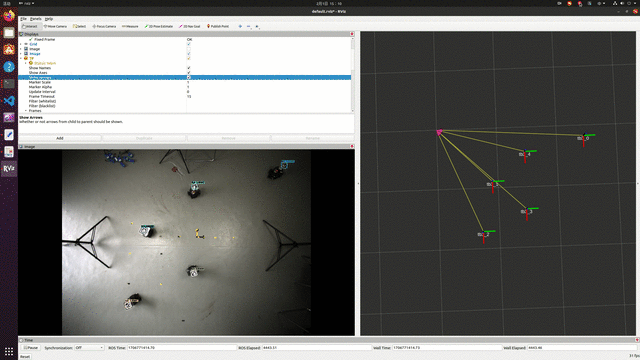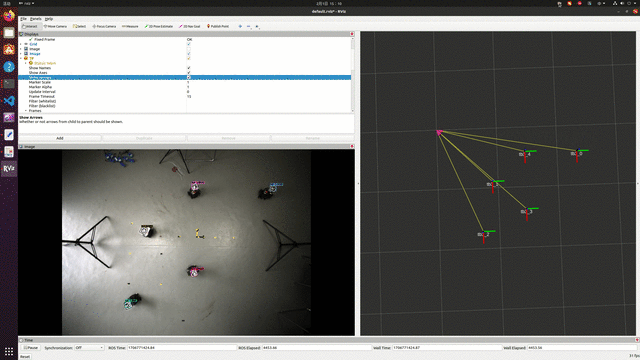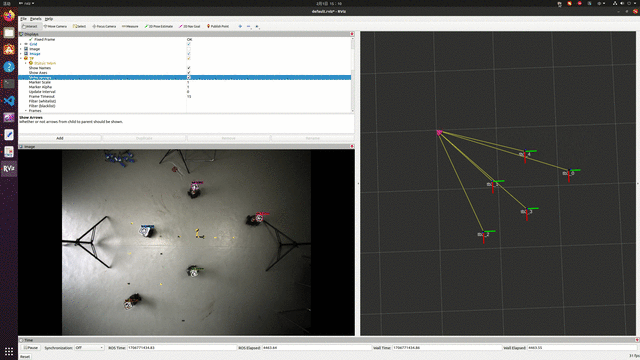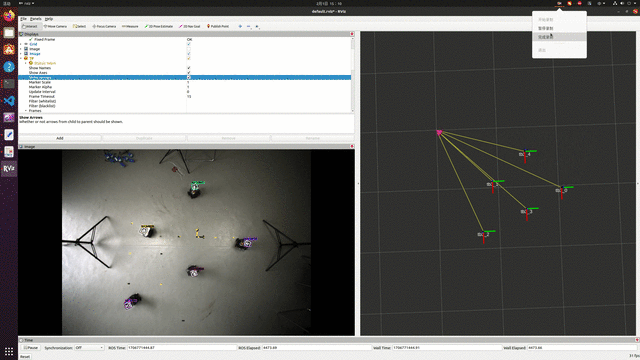
参考资料
[1] mindyolo参考教程:https://github.com/mindspore-lab/mindyolo/blob/master/examples/finetune_SHWD/README.md
















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











