




目录
1. 动机&贡献
1.1 动机
- ViT展示着超高的性能和鲁棒性,但是现有的方法对其改进需要在大规模的数据集上进行重新训练和微调。
- CNN卷积神经网络在特征上有着空间自相关性,但是随着网络结构的加深,这种自相关依赖会降低。同时在ViT网络结构上也有着相同的现象。
- 此外,在非信息区域(如背景)中,具有极高或极低空间自相关分数的图像块可能会妨碍识别性能,并削弱网络对受损输入的鲁棒性。
1.2 贡献
- 显著提升了ViT的鲁棒性和准确率,在标准分类任务(ImageNet-1K) 上表现突出,Top-1 Accuracy 达到 94.9%,为新的state-of-the-art(SOTA)性能。在多个鲁棒性评估基准上也取得了很好的成绩:ImageNet-A:Top-1 = 63.6%,ImageNet-R:Top-1 = 79.2%,ImageNet-C:mCE(mean Corruption Error)= 13.6%。
- 即插即用,无需额外的昂贵微调或训练,还能提高推理效率。
2. 方法
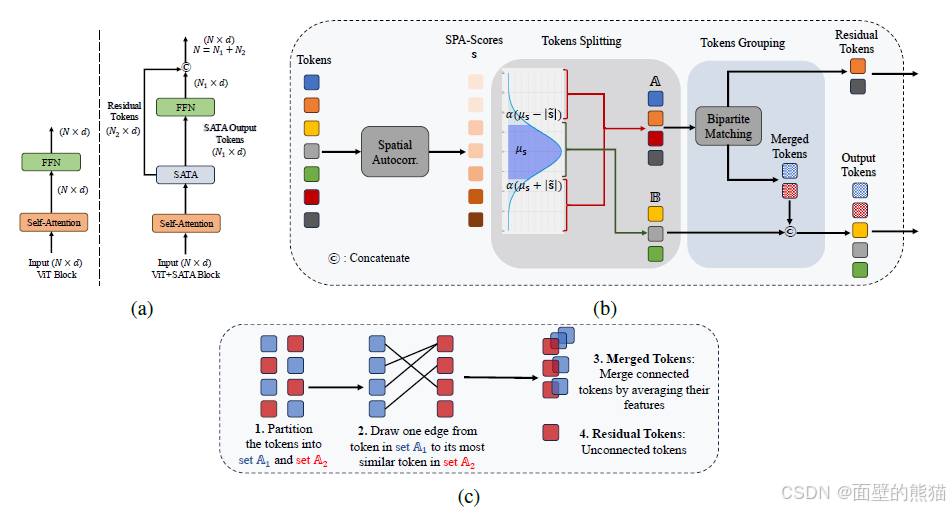
2.1 空间自相关分数计算
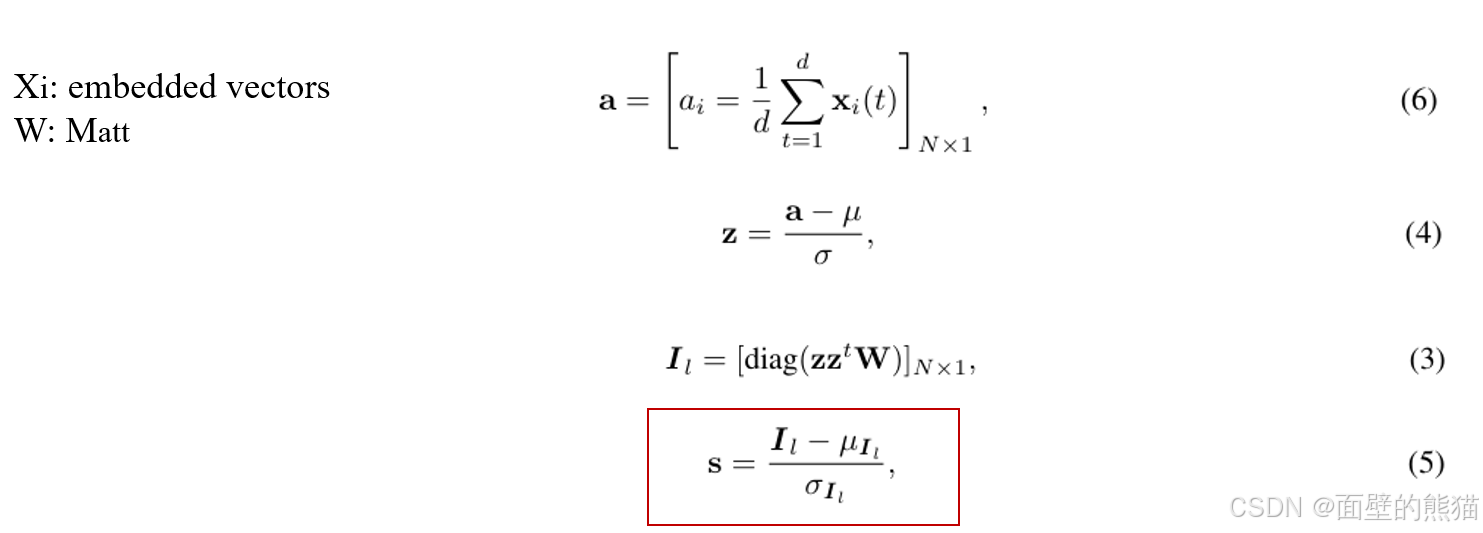
这里的计算方法,参考莫兰指数计算。
这里a是一个token级别的拥有全局属性的Nx1的矩阵。
μ和σ代表着a的均值和方差,z其实就是a的标准化结果。
I l I_{l} I
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1242
1242



 到【灌水乐园】发言
到【灌水乐园】发言








