







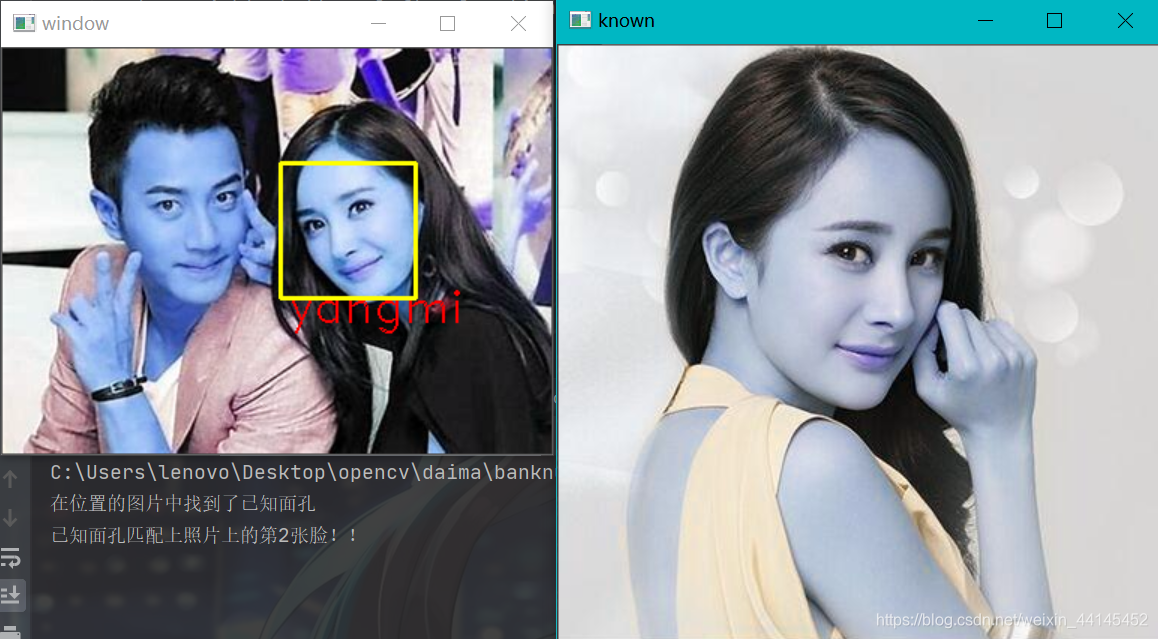
 本文介绍了一种使用Python和face_recognition库实现的人脸检测方法。该方法能够在已知的人脸图像基础上,在未知的群像照片中找到并标记出特定人物(如杨幂)。通过加载图像文件,获取人脸编码和位置信息,进而实现精确匹配与标注。
本文介绍了一种使用Python和face_recognition库实现的人脸检测方法。该方法能够在已知的人脸图像基础上,在未知的群像照片中找到并标记出特定人物(如杨幂)。通过加载图像文件,获取人脸编码和位置信息,进而实现精确匹配与标注。
实验要求:
给一张已知的人脸(杨幂),让你在未知图片中找到杨幂,并且在那张未知图片中把杨幂的脸标记起来


思路:
-
load_image_file方法加载已知图像和待检测图像
-
face_encodings方法分别返回已知人脸的编码信息和待检测图像的编码信息
-
face_locations方法得到多人图中,这几个人的面部位置
-
遍历待检测图片每个人的人脸,以及遍历每个人人脸的位置坐标,提取人脸特征,与已知人脸特征作比对,如果是True的话,返回匹配成功信息
-
在未知图像上对匹配到的人脸进行标记
代码如下:
import face_recognition
from PIL import Image, ImageDraw
import cv2
# 加载一张合照
unknown_image = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/stage1/test_data/test3.jpg')
# 加载一张单人照片
known_image = face_recognition.load_image_file('C:/Users/lenovo/Desktop/opencv/daima/banknum/stage1/test_data/test1.jpg')
results = []
known_face_encodings = face_recognition.face_encodings(known_image)[0]
# face_encodings返回的是列表类型,我们只需要拿到一个人脸编码即可
unknown_face_encodings = face_recognition.face_encodings(unknown_image)
# 得到多人图片两个人的面部位置
face_locations = face_recognition.face_locations(unknown_image)
for i in range(len(face_locations)): # face_locations的长度就代表有多少张脸
top, right, bottom, left = face_locations[i] # 取出每张脸的四个位置坐标
face_image = unknown_image[top:bottom, left:right]
face_encoding = face_recognition.face_encodings(face_image) # 把单个的人脸特征提取出来
if face_encoding:
result = {}
matches = face_recognition.compare_faces([unknown_face_encodings[i]], known_face_encodings, tolerance=0.39)
if True in matches:
print('在位置的图片中找到了已知面孔')
result['face_encoding'] = face_encoding
result['is_view'] = True
result['location'] = face_locations[i]
result['face_id'] = i+1
results.append(result)
if result['is_view']:
print('已知面孔匹配上照片上的第{}张脸!!'.format(result['face_id']))
view_face_locations = [i['location'] for i in results if i['is_view']]
if len(view_face_locations) > 0: # 表示找到了至少大于0个的匹配特征
for location in view_face_locations:
top, right, bottom, left = location # 取出每张脸的四个位置坐标
start = (left, top)
end = (right, bottom)
cv2.rectangle(unknown_image, start, end, (0, 255, 255), thickness=2)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(unknown_image, 'yangmi', (left+6, bottom+16), font, 1.0, (0, 0, 255), thickness=1)
cv2.imshow('known', known_image)
cv2.imshow('window', unknown_image)
cv2.waitKey()
运行结果:

















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









