







1 GAN
Source
GAN — What is Generative Adversarial Networks GAN? | by Jonathan Hui | Medium
Key Takeaways
-
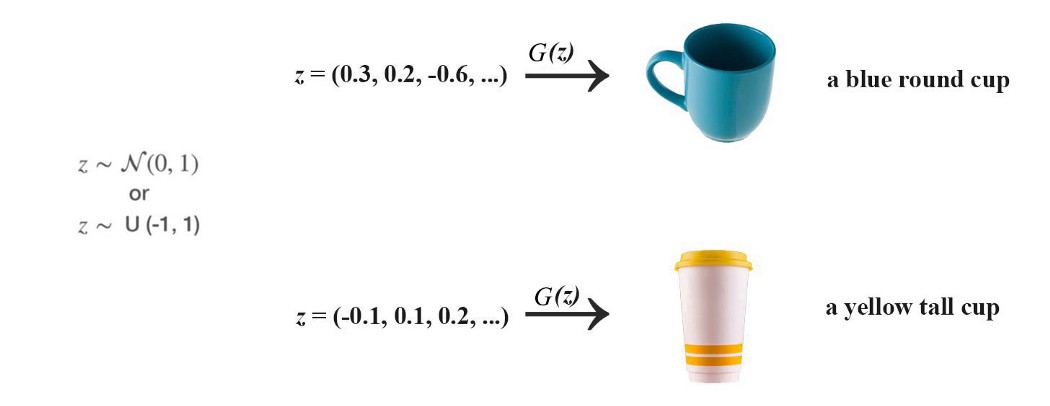
正态分布或均匀分布中抽样噪声 z z z,以 z z z作为输入,生成器生成图像 x x x( x = G ( z ) x=G(z) x=G(z))
-
z z z contains factors that determine the type and the style of the content generated
-
we don’t control the semantic meaning of z z z. We let the training process to learn it. 比如不设定 z z z的哪个byte决定头发颜色,如果想要知道 z z z中某些factor的含义,可以利用生成图片进行插值来验证。
-
利用random noise z z z 生成的图片(PG-GAN)

-
逐渐改变 z z z 中的某一特定维度并可视化其语义

2 StyleGAN
Source
StyleGAN 和 StyleGAN2 的深度理解 - 知乎 (zhihu.com)
GAN — StyleGAN & StyleGAN2. Do you know your style? Most GAN models… | by Jonathan Hui | Medium
Key Takeaways
- Latent Factor:可以理解为每个因子控制一个要素,和解耦有关。
- Disentanglement:解耦的特征中,每一个维度都表示具体的、不相干的意义。
- In GAN, the distribution of z z z should resemble the latent factor distribution of the real images
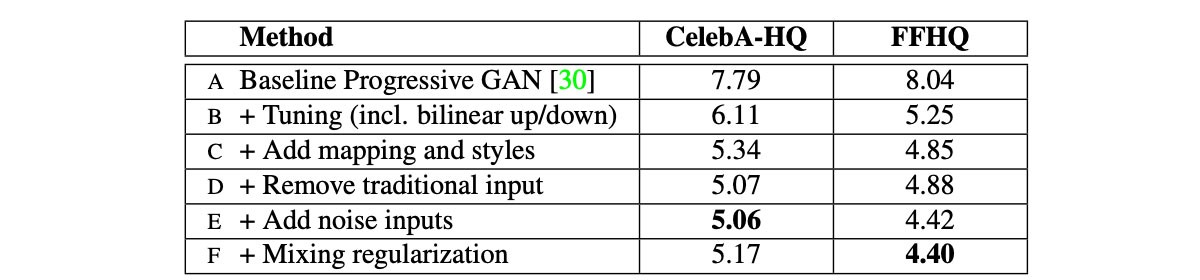
2.1 5 Methods(Experiments A-F)
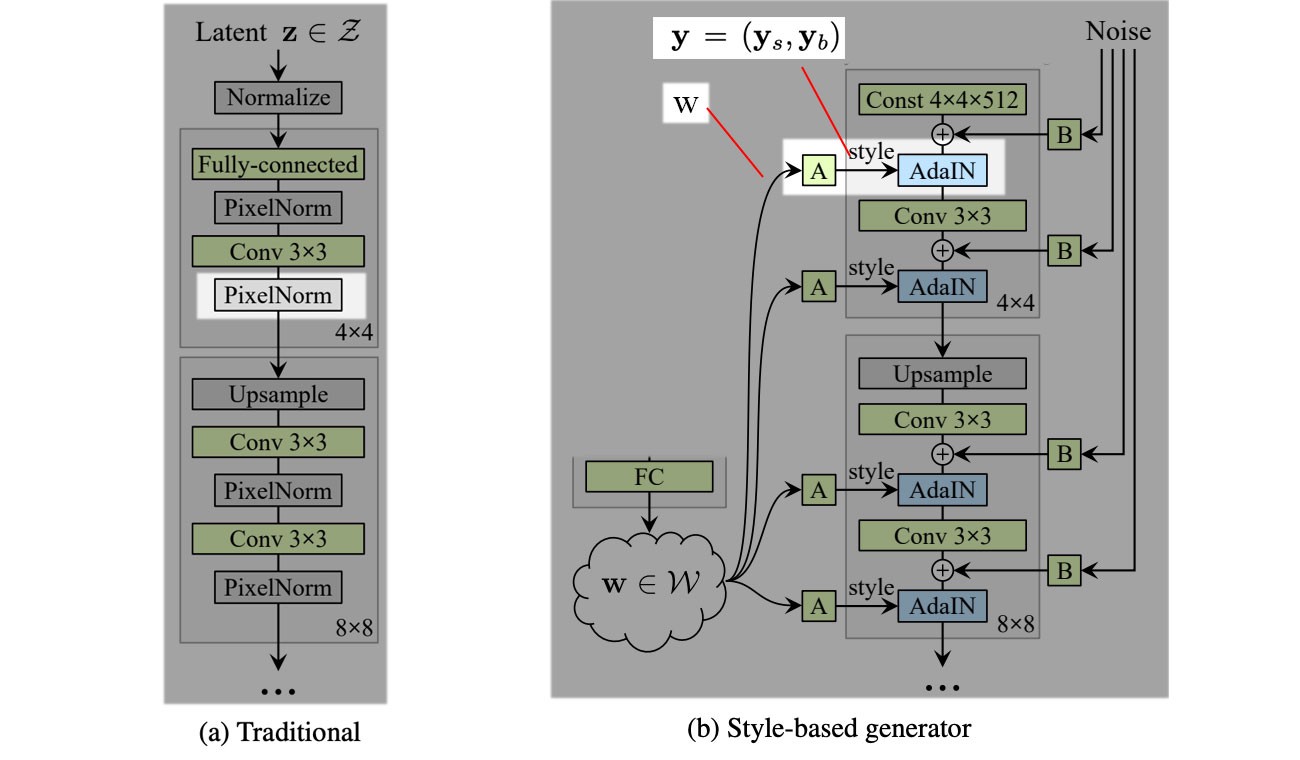
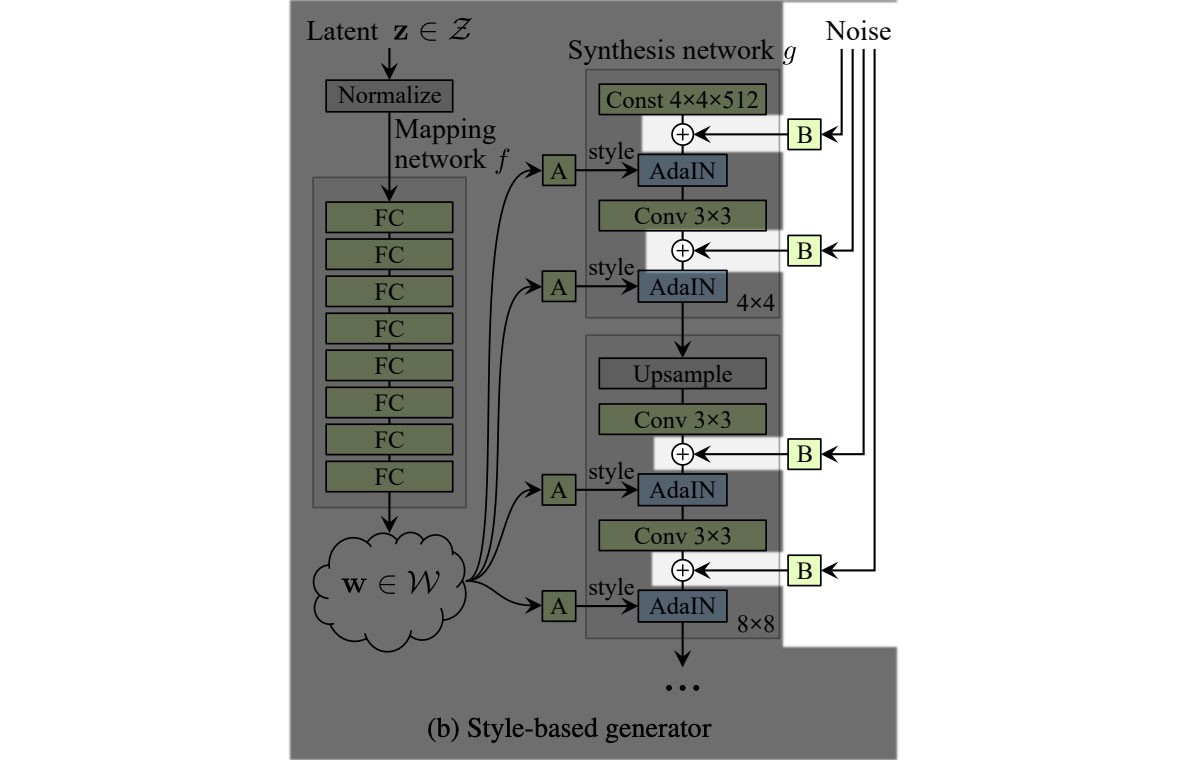
2.2 Style-based generator
文章后续只将关键idea实验设为标题。
A. Baseline Progressive GAN
B. + Tuning(incl. bilinear up/down, hyperparameter tuning)
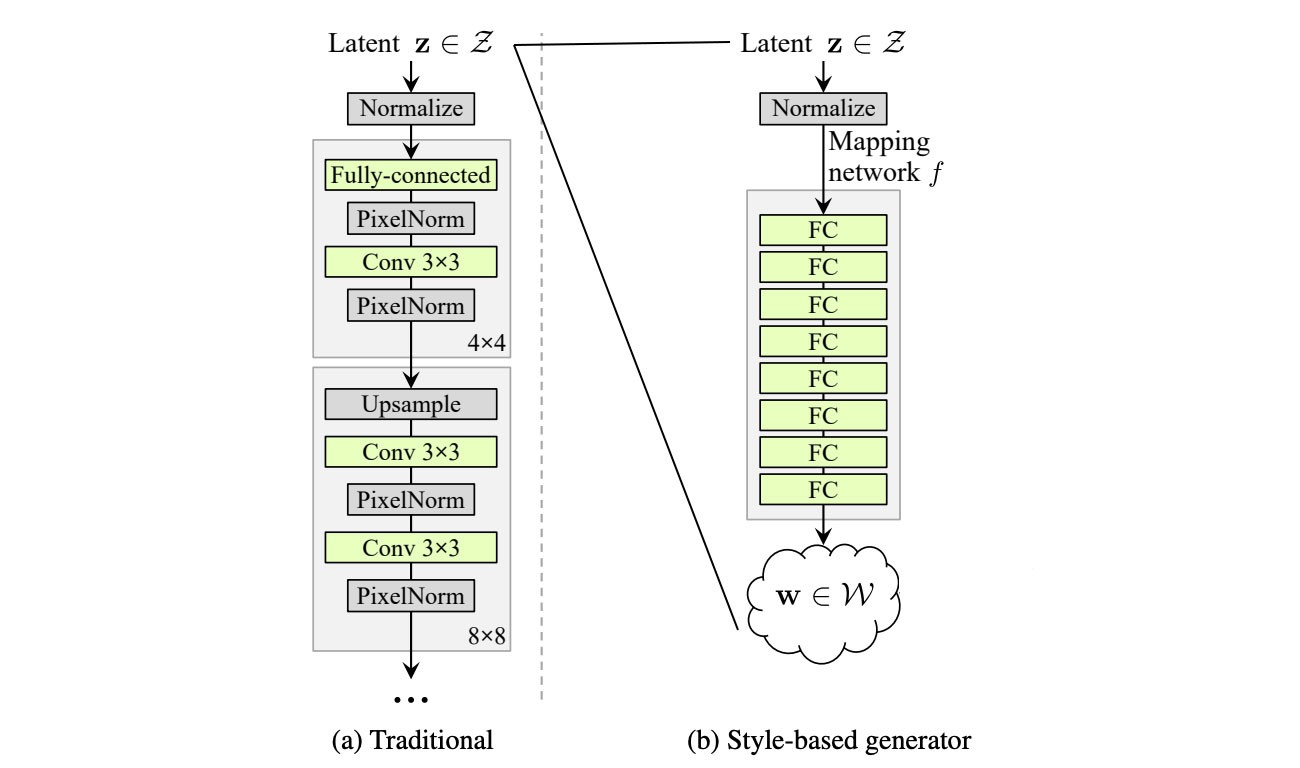
💡C. + Add mapping and styles
Mapping
-
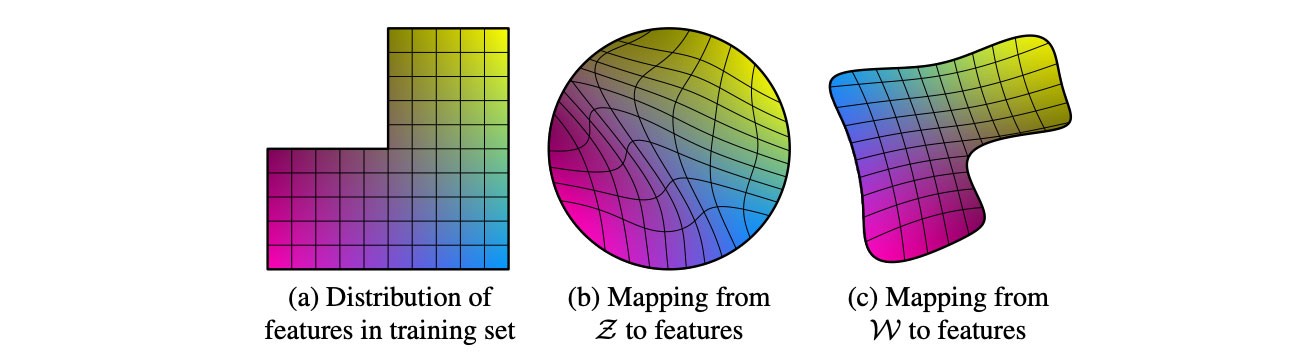
空间 z z z 解耦程度越高,模型性能越好
-
将空间 z z z map 到 512维的latent space w w w
Styles
-
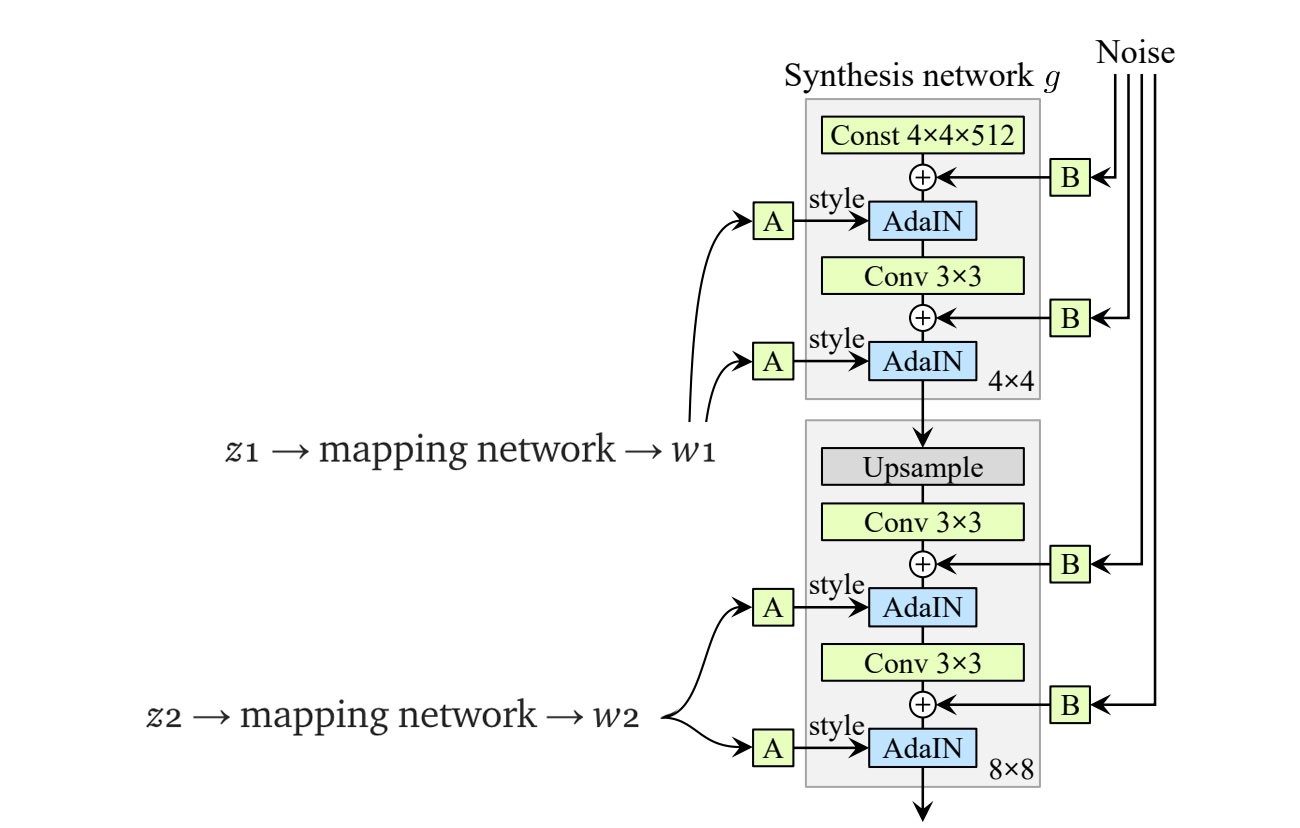
相比于普通GAN的latent z z z只传入网络的第一层,StyleGAN利用单独学习的仿射变换操作 A A A 将 w w w 送到每一层(不同层负责不同的分辨率)
-
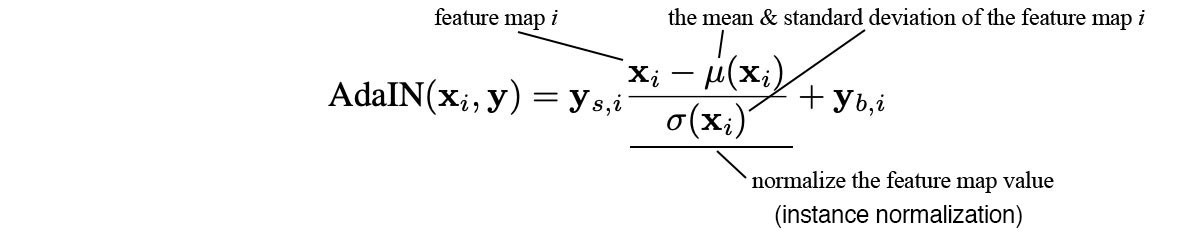
AdaIN (adaptive instance normalization)替换PixelNorm以添加“Style”。首先对于特征进行常规的实例归一化,然后利用风格信息值 y s y_s ys和 y b y_b yb作为scale和bias(模型从 w w w中计算学得),来给空间特征图添加“风格”。The normalized feature influences the amount of style applied to a spatial location.
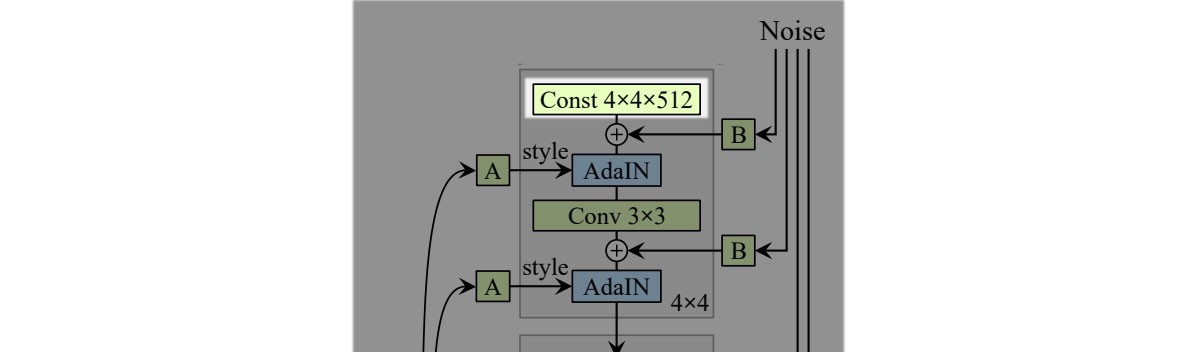
D. + Remove traditional input
-
a learned constant matrix with dimension 4×4×512
💡E. + Add noise inputs
-
SytleGAN通过创造随机扰动(stochastic variation)将噪声引入空间数据,可以为生成图像添加局部细节(发丝、胡渣、雀斑、皮肤毛孔)。
-
using uncorrelated Gaussian noise, learn a separate scaling factor for each feature map and multiple it with the noise matrix before adding it to the output of the previous layer.

🚀Generator Summary
-
“Style”解决了图像的关键属性,应用于全局特征图。


- Coarse styles —— low resolution( 4 2 4^2 42- 8 2 8^2 82)—— pose,hair,face shape
- Middle styles —— middle resolution( 1 6 2 16^2 162- 3 2 2 32^2 322)—— facial features,eyes
- Fine styles —— high resolution( 6 4 2 64^2 642- 102 4 2 1024^2 10242) ——
-
“Noise”引入了像素水平的局部变化,并利用随机扰动(stochastic variation)生成特征的局部变体。

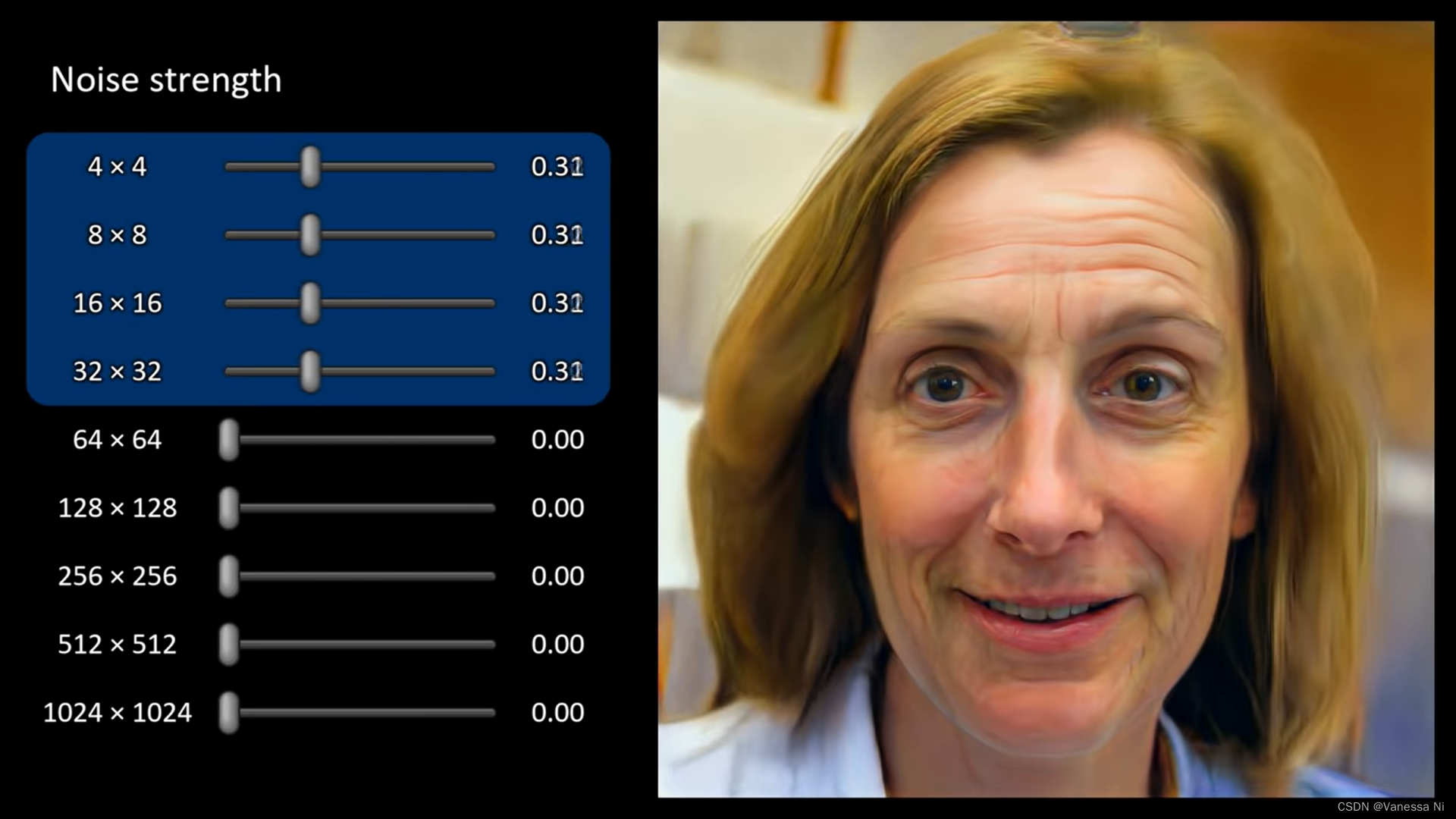
- Coarse noise —— low resolution( 4 2 4^2 42- 3 2 2 32^2 322) —— large-scale curling of hair
- Fine noise —— high resolution( 6 4 2 64^2 642- 102 4 2 1024^2 10242) —— finer details, texture
- No noise —— featureless “painterly” look
💡2.3 F. + Style Mixing & Mixing regularization
-
混合正则化的含义就是,达到一定的空间分辨率后,改用不同的latent factor z 2 z_2 z2来derive(推导)出新的风格。
-
使用生成Source B图像的latent factors z b z_b zb 来得出coarse spatial resolutions的风格( 4 2 4^2 42- 8 2 8^2 82),使用Source A的latent factors z a z_a za来得出fine resolution的风格。生成的图像将具有来自Source B的high-level style,如姿势、发型、脸型和眼镜,而所有的颜色和更精细的面部特征则与Source A相近。

-
使用Source B来得出middle resolutions的风格,则继承Source B的较小尺度的面部特征、发型、眼睛睁闭,而Source A的姿势、一般脸型和眼镜则被保留下来。
-
最后一栏显示从Source B复制fine styles(high resolutions),主要影响颜色方案和微观结构。

💡2.4 Truncation trick in W
-
z z z和 w w w的低概率密度区域可能没有足够的训练数据来进行准确的学习,所以在生成图像时,我们可以避开这些区域,以多样性(variation)的代价来提升图片质量(quality)。可以对 z z z和 w w w进行截断(Truncation)。
-
StyleGAN中对 w w w进行截断,ψ为style scale(风格标度)。
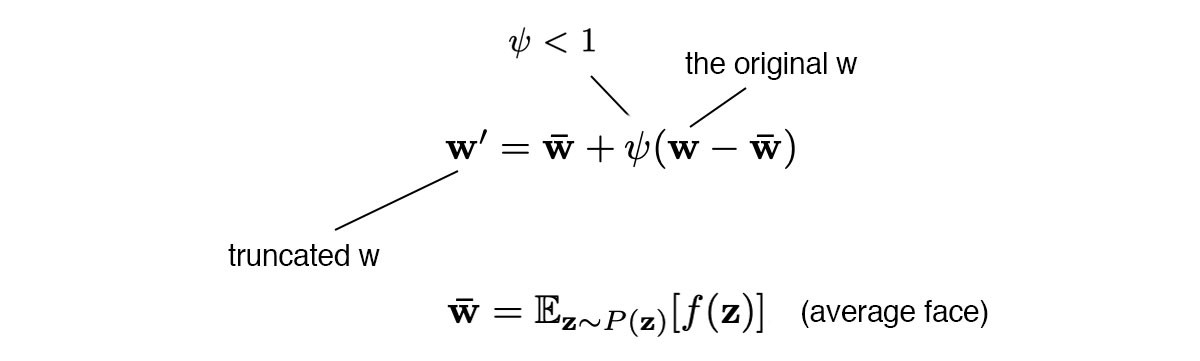
-
但是截断操作只在低分辨率层进行(如 4 2 4^2 42- 3 2 2 32^2 322,ψ=0.7)。这确保高分辨率的细节不受影响。当ψ=0时,模型生成average face。当调整ψ时,可以看到视角、眼镜、年龄、颜色、头发长度、性别的flipped过程。

Perceptual path length
-
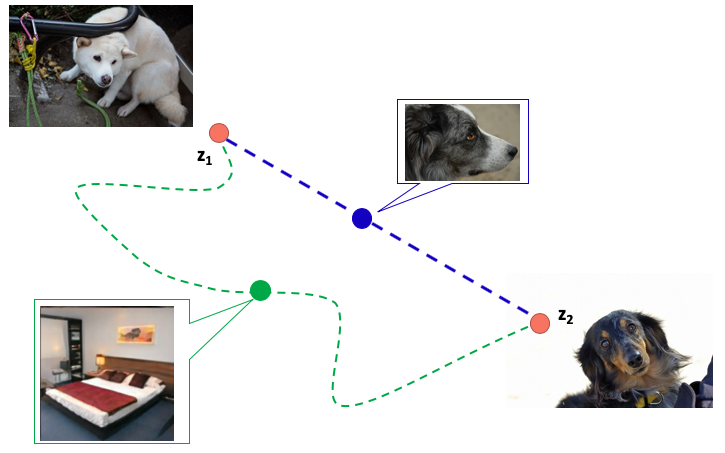
图像生成其实是学习从一个分布到目标分布的迁移过程,我们希望学到最快的路径,假设特征充分解耦, z 1 z_1 z1和 z 2 z_2 z2之间可以进行线性插值得到想要的结果。
-
通过训练好的生成模型可以得到给定图像的latent code,例如寻找图像 x x x在 G G G中的latent code,设初始latent code为 z z z生成的初始图像是 p p p,通过 p p p和 x x x之间的差距设置损失函数,通过损失不断迭代更新 z z z,最后得到 x x x的latent code。
-
Perceptual path length是一个指标,判断生成器是否选择了最近的路线。用训练过程中相邻时间节点上的两个生成图像的距离来表示。

3 StyleGAN2
Source
Key Takeaways
-
StyleGAN生成的图像中会有水滴伪影,intermediate feature maps很明显,几乎所有 6 4 2 64^2 642分辨率的特征图都有这个问题,高分辨率下会变得更糟。

-
把锅甩给了AdaIN
5 Methods(Experiments A-F)

A. Baseline StyleGAN
B. + Weight demodulation
-
StyleGAN模型图(未经修改的)
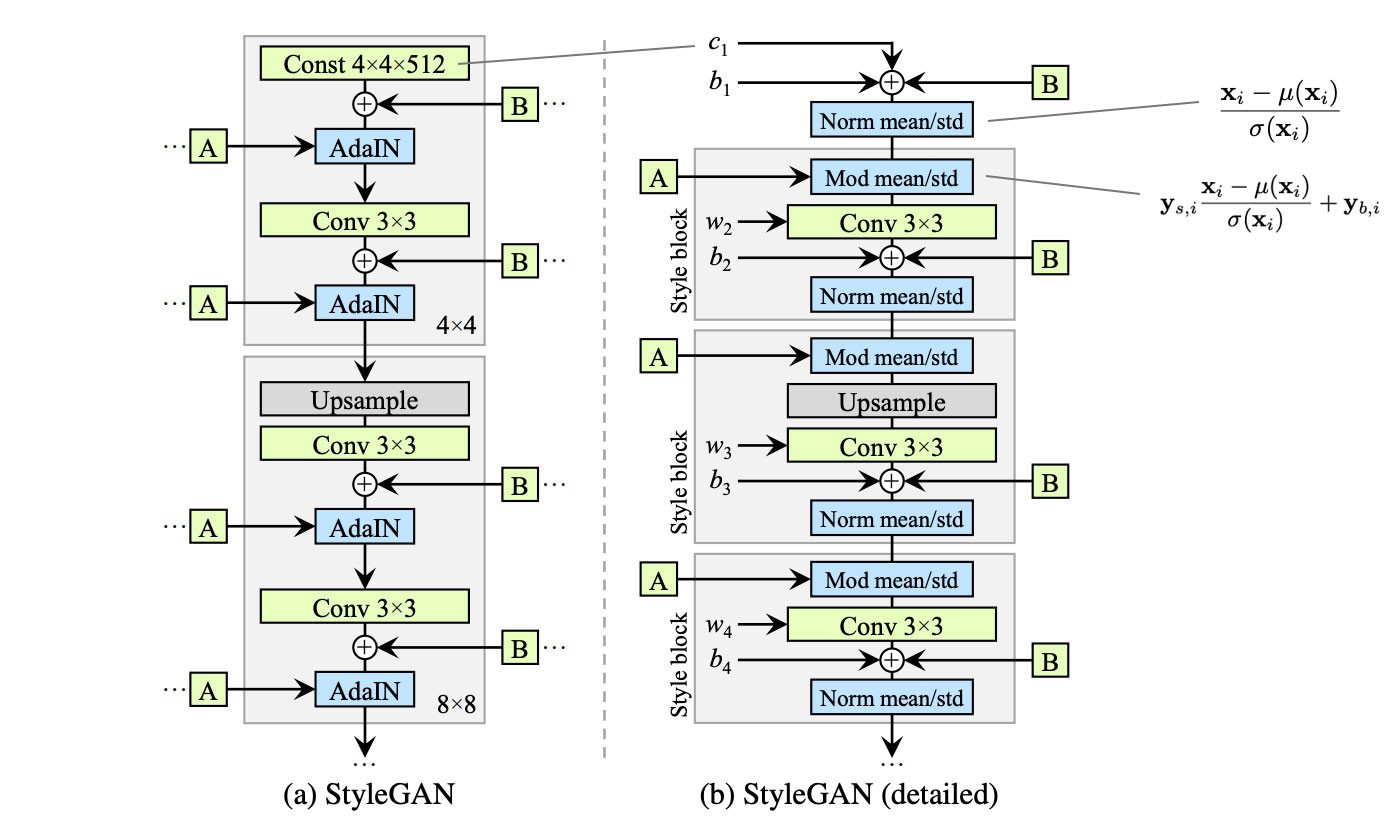
-
实验得出的一些改动:一、简化常数在开始时的处理方式。二、对特征进行归一化时不取mean。三、将噪声模块移到样式模块之外。
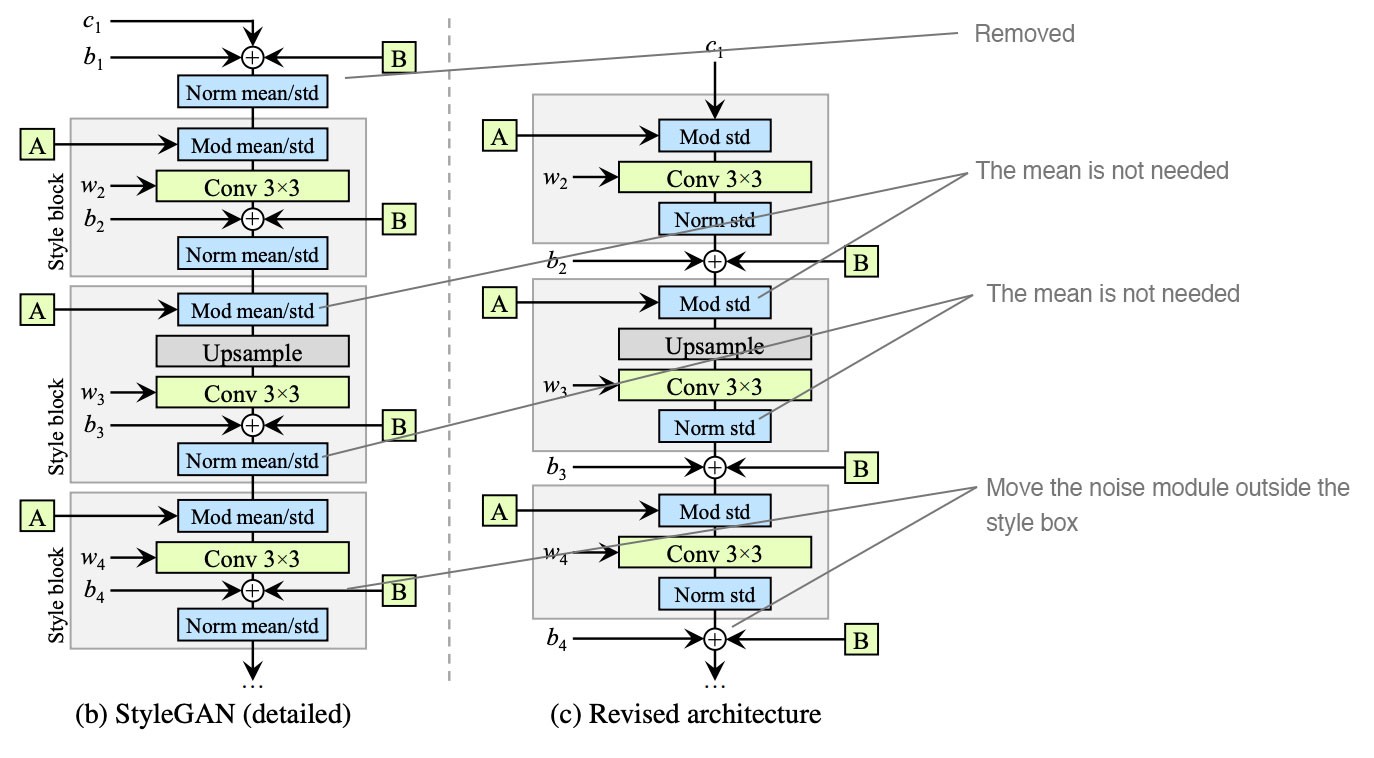
-
Weight demodulation让训练更稳定,数学上和实例归一化不同,但是将输出特征图归一化为具有标准单位的标准偏差,达到了和其他归一化方法类似的目标。
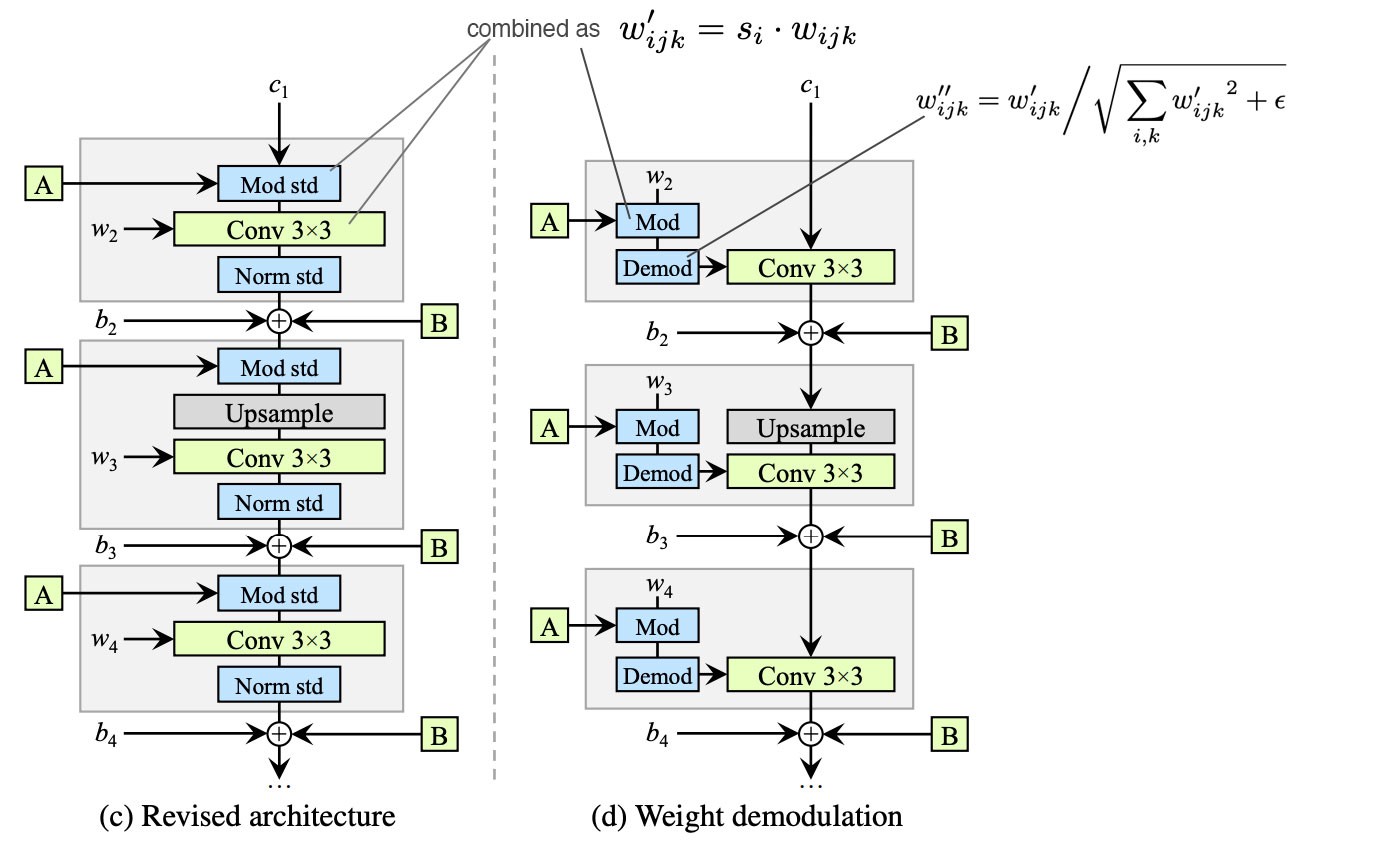
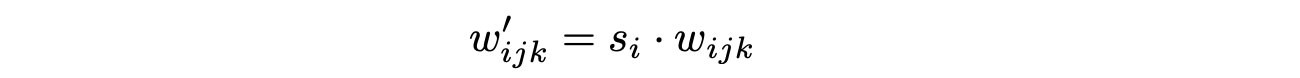
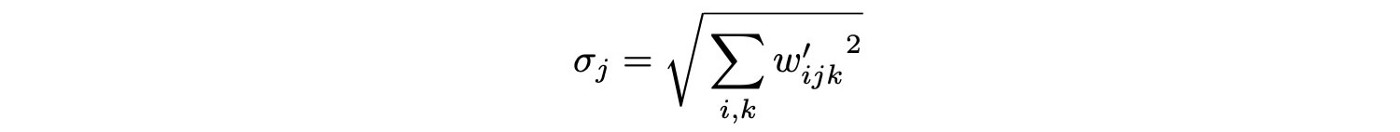
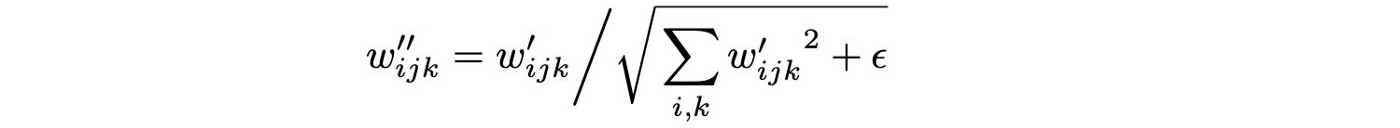
C. + Lazy regularization
- 每16mini-batches add 一次regularization性能保持一致,还减少了计算消耗。
D. + Path length regularization
-
不论latent factor的值是多少,latent space中的相同位移应该在图像空间中产生相同的幅度变化。于是添加一个正则化项。具体需要read code。
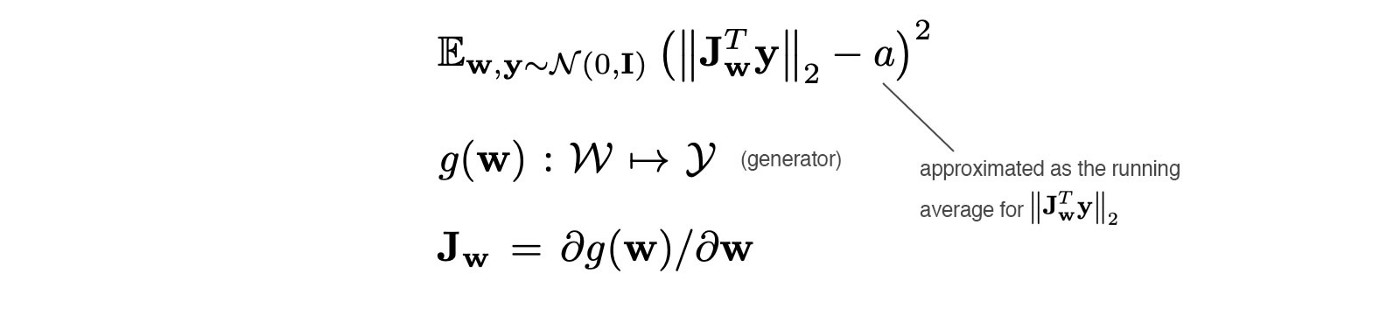
E. + No growing
-
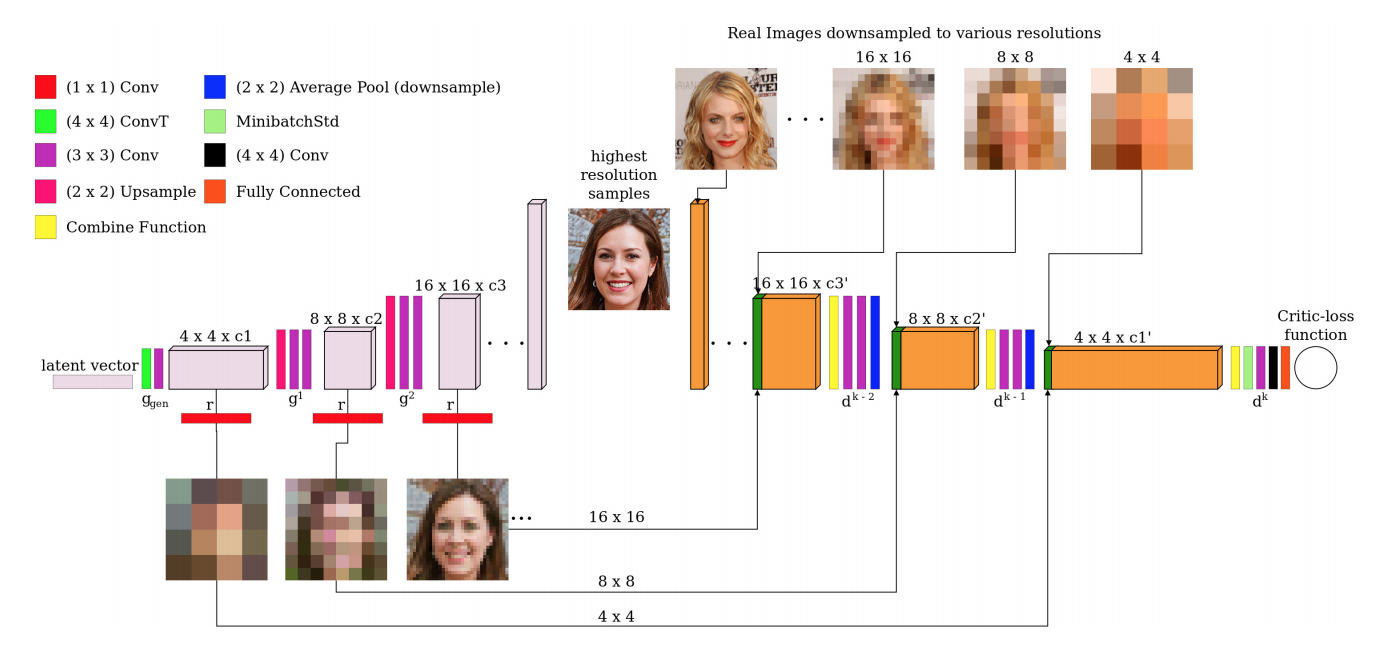
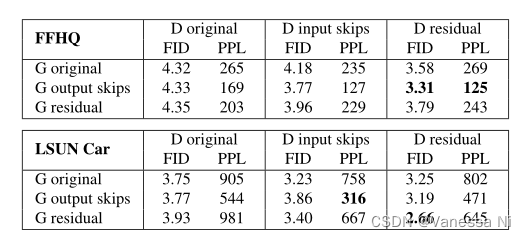
StyleGAN利用Progressive growth的思想来稳定高分辨率图像的训练(PG-GAN)。StyleGAN2利用skip connection,并结合resnet的残差概念(residual)。
-
使用双线性滤波对前几层进行上/下采样,并尝试学习下一层的残差值来代替。
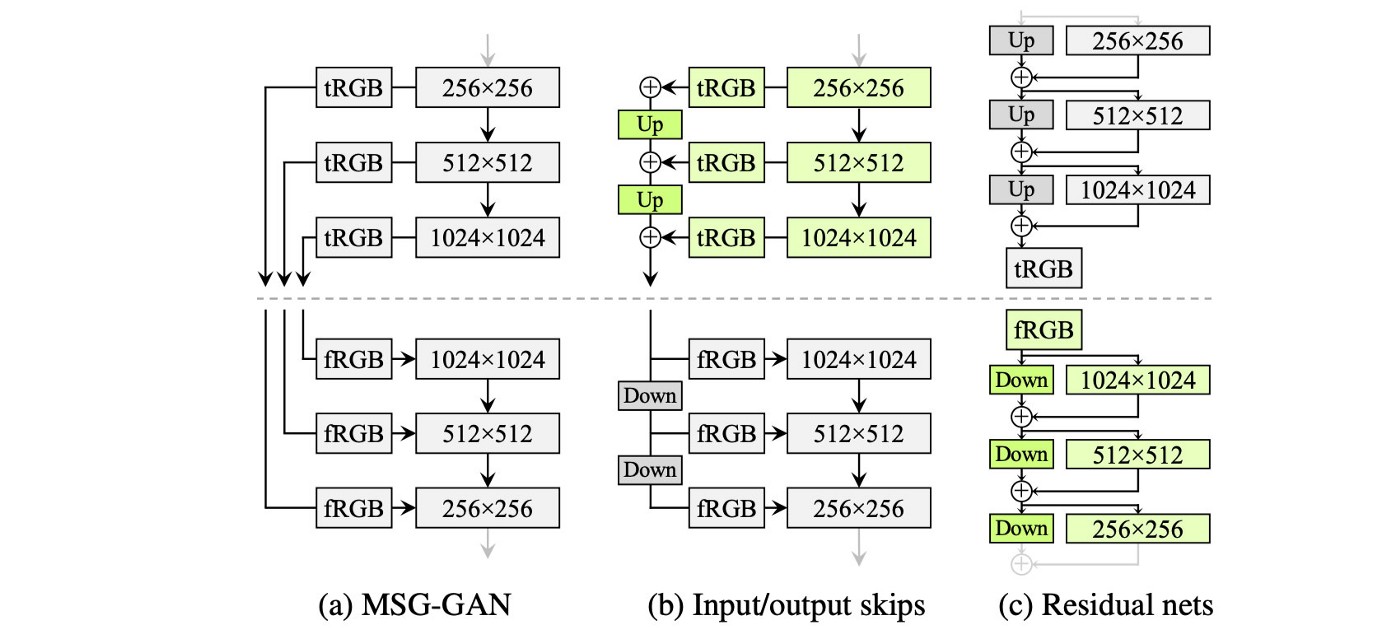
-
MSG-GAN的设计就类似,简单来说就是skip connection+residual设计更新生成器、鉴别器整体框架。
F. + large Network
-
在开始时,低分辨率的层应该占主导地位。然而,随着更多的训练迭代,高分辨率层的贡献应该占主导地位。
-
在具体的1024×1024层中,高分辨率层的贡献并没有达到应有的程度。作者怀疑这些层的容量不够大。事实上,当高分辨率层的特征图数量增加一倍时,它的影响就会明显改善(右图)。
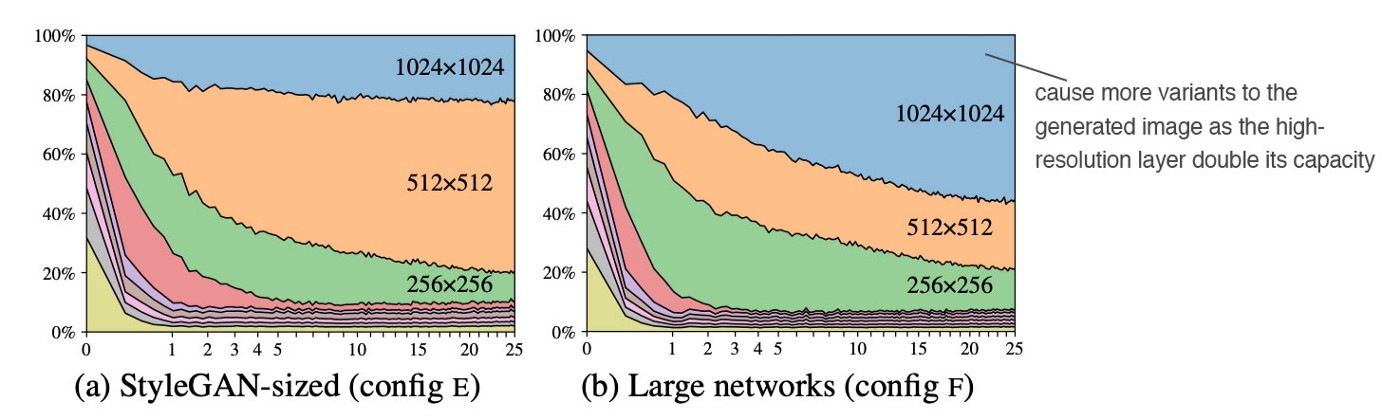
简单来说这种tricks没卡加不起,nvidia不缺卡啊。


















 2536
2536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











