







损失函数
损失函数介绍
解决一个机器学习问题主要有两部分:数据和算法。
算法又有三个部分组成:假设函数、损失函数、算法优化。
损失函数: 用于计算损失的函数。在机器学习中,通常把模型关于单个样本预测值与真实值的差称为损失,损失越小,模型越好。
主要的损失函数:
logLoss (对数损失函数,LR)
hinge loss (合页损失函数,SVM)
exp-loss (指数损失函数,AdaBoost)
cross-entropy loss (交叉熵损失函数,Softmax)
quadratic loss (平方误差损失函数,线性回归)
absolution loss (绝对值损失函数, )
0-1 loss (0-1损失函数)
常见的损失函数
1.对数损失函数(Logloss)
logLoss (对数损失函数,也叫binary cross entropy,二元交叉熵损失,
LR)
logLoss (log 损失函数)的函数标准形式:
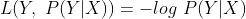
适用于:逻辑回归
逻辑回归目标函数:
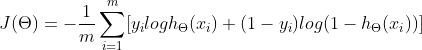
2. hinge loss 合页损失函数
适用于:SVM
SVM目标函数:
第一种

通过拉格朗日乘子法转化并求解之后,得到的式子为:

第二种:包含有hinge loss的解释方式,其通过最小化下面的目标函数
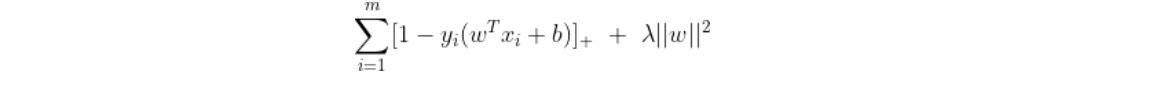
而上面的式子中,第1项是经验损失或者经验风险第二项为系数为
λ
\lambda
λ的w的L2范数,为正则化项,对于第1项经验损失,函数
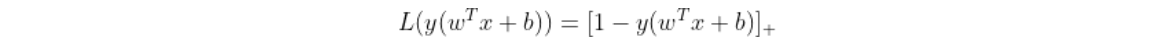
称为合页损失函数(hinge loss function)。下标“+”表示下面取正值的函数:

3. exp-loss 指数损失函数
适用于:AdaBoost
Adaboost 算法采用调整样本权重的方式来对样本分布进行调整,即提高前一轮个体学习器错误分类的样本的权重,而降低那些正确分类的样本的权重,这样就能使得错误分类的样本可以受到更多的关注,从而在下一轮中可以正确分类,使得分类问题被一系列的弱分类器“分而治之”。对于组合方式,AdaBoost采用加权多数表决的方法,具体地,加大分类误差率小的若分类器的权值,减小分类误差率大的若分类器的权值,从而调整他们在表决中的作用。
Adaboost的损失函数为指数损失函数.在Adaboost算法学习的过程中,经过m轮迭代之后,可以得到
f
m
(
x
)
f_m(x)
fm(x):

指数损失函数的标准形式为:
L
(
y
,
f
(
x
)
)
=
e
x
p
[
−
y
f
(
x
)
]
L(y, f(x)) = exp[-yf(x)]
L(y,f(x))=exp[−yf(x)]
4. cross-entropy loss 交叉熵损失函数
适用于:ID3(决策树)、softmax
交叉熵是信息论中的概念,其原来是用来估算平均编码长度的。给定两个概率分布p和q,通过q来表示p的交叉熵为:
H ( p , q ) = − ∑ y p ( y ) l o g q ( y ) H(p,q) = - \sum_{y}p(y)\ log\ q(y) H(p,q)=−y∑p(y) log q(y)
交叉熵刻画的是两个概率分部之间的距离,或可以说其刻画的是通过概率分布q来表达概率分布p的困难程度,p代表正确答案,q代表的是预测值,交叉熵越小,两个概率的分布越接近。
交叉熵损失函数通常使用在softmax上,而softmax通常使用在神经网络的末端,使其预测结果以概率的形式输出。Softmax函数为:
σ
(
Z
)
j
=
e
z
j
∑
k
=
1
K
e
z
k
{\sigma (Z)_j=\frac{e^{z_j}}{\sum_{k=1}^Ke^{z_k}}}
σ(Z)j=∑k=1Kezkezj
其把原始输出
z
j
z_j
zj转化成概率,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离。
5. quadratic loss 平方误差损失函数
适用于:线性回归
在回归问题中,我们常常使用平方误差作为其损失函数,其公式为:
L ( Y , f ( X ) ) = ( f ( X ) − Y ) 2 L(Y,\ f(X))=(f(X)-Y)^2 L(Y, f(X))=(f(X)−Y)2
但更多的是使用其平均值,即
l ( Y , f ( X ) ) = 1 2 m ∑ i = 1 m ( f ( x i ) − y i ) 2 l(Y,f(X))=\frac{1}{2m}\sum_{i=1}^m(f(x_i)-y_i)^2 l(Y,f(X))=2m1i=1∑m(f(xi)−yi)2
线性回归中常常添加正则化:
加入L1正则化为Lasso回归:
L ( Y , f ( X ) ) = 1 2 m ∑ i = 1 m [ f ( x i ) − y i ] 2 + λ ∑ j = 1 n ∣ w j ∣ L(Y,f(X))=\frac{1}{2m}\sum_{i=1}^{m}[f(x_i)-y_i]^2\ +\ \lambda\sum_{j=1}^n|w_j| L(Y,f(X))=2m1i=1∑m[f(xi)−yi]2 + λj=1∑n∣wj∣
加入L2正则化则为岭回归:
L ( Y , f ( X ) ) = 1 2 m ∑ i = 1 m [ f ( x i ) − y i ] 2 + λ ∑ j = 1 n w j 2 L(Y,f(X))=\frac{1}{2m}\sum_{i=1}^{m}[f(x_i)-y_i]^2\ +\ \lambda\sum_{j=1}^nw_j^2 L(Y,f(X))=2m1i=1∑m[f(xi)−yi]2 + λj=1∑nwj2
6. absolution loss (绝对值损失函数)
绝对值损失函数的公式:
L ( Y , f ( X ) ) = ∣ Y − f ( X ) ∣ L(Y,f(X))=|Y-f(X)| L(Y,f(X))=∣Y−f(X)∣
表示预测值与真实值的距离。
7. 0-1 loss (0-1损失函数)
L ( y , f ( x ) ) = { 0 i f y = f ( x ) 1 i f y ≠ f ( x ) L(y,f(x)) = \left\{\begin{matrix} 0 \ \ \ if\ \ y=f(x)& \\ & \\ 1 \ \ \ if\ \ y\neq f(x)& \end{matrix}\right. L(y,f(x))=⎩⎨⎧0 if y=f(x)1 if y=f(x)















 4653
4653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









