






MINDIE-LLM
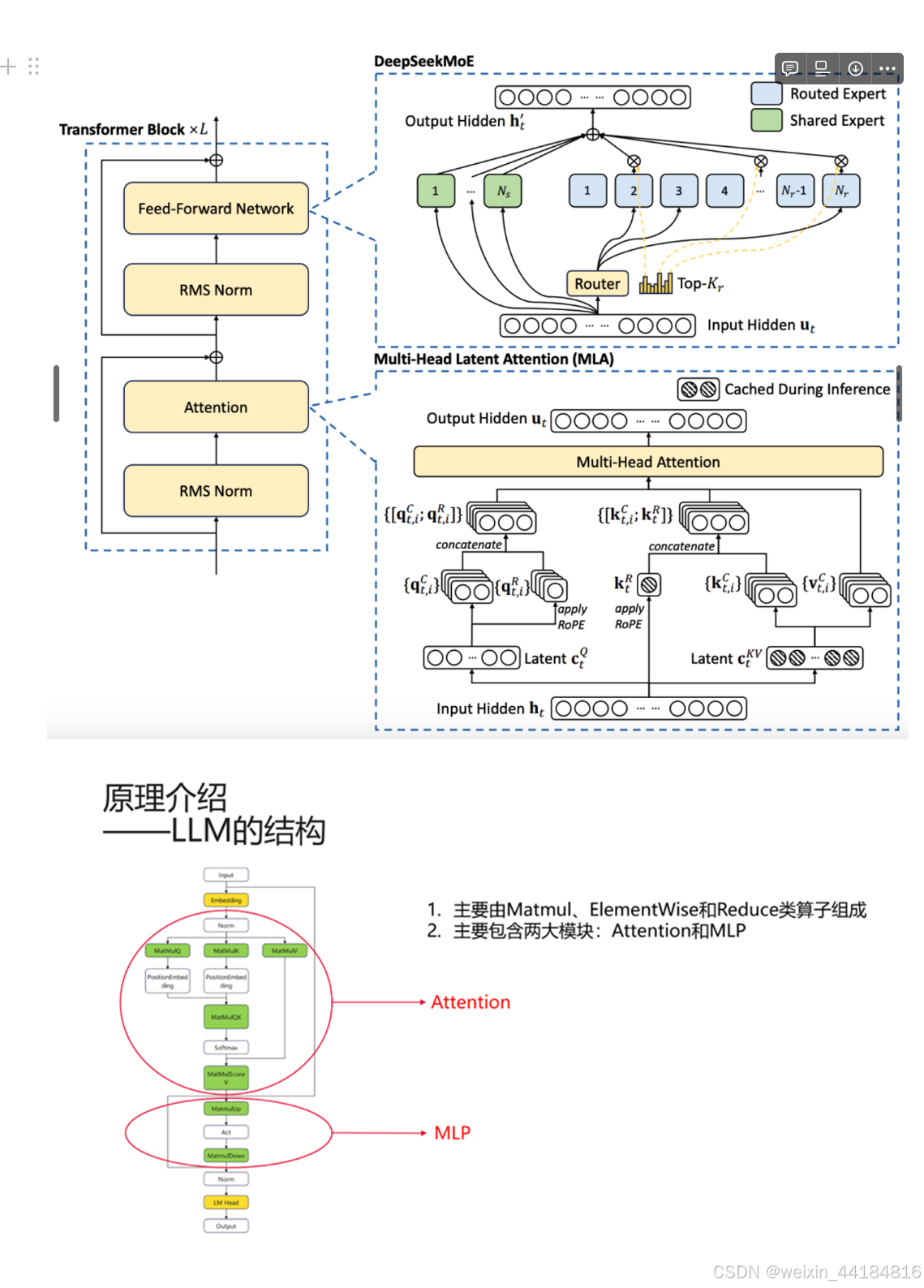
常见的工程技术
test
源语理解对比
- 源语:prefill 与 decode, 首token
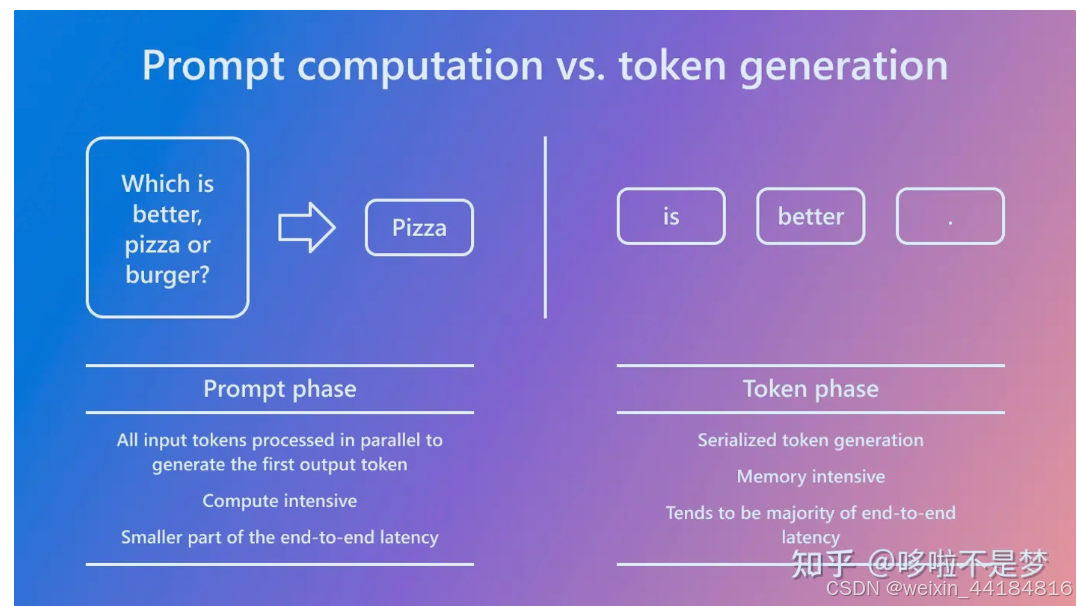
- 7个insight 因此针对这一问题,SplitWise主要针对7个insight做了详细分析,结论先来(详细分析在后~):
- 不同的推理任务中,Prefill和Decode的分布不同
- 在P/D混合部署中,大部分时间消耗在Decode阶段,未充分利用到GPU的算力
- 对大部分的请求,E2E时间消耗在Decode阶段
- Prefill阶段应该限制Batch size从而避免影响性能,相反,Decode阶段应该增大Batch size来获得更高的吞吐
- Prefill阶段算力是瓶颈,Decode阶段内存是瓶颈
- Prefill阶段能充分使用算力,Decode阶段不能
- Decode阶段可以使用性能较弱、成本较低的设备
原文链接:打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率哆啦不是梦-CSDN博客
-
在线gather算子 — 优化的是MLA算子? — IO方面优化??
-
激活函数回顾:
-
sigmoid (0,1)
logistic — sigmoid 二分类 — softmax 多分类
-
tanh [-1,1]
-
ReLU
-
softmax 归一化/概率化处理
-
-
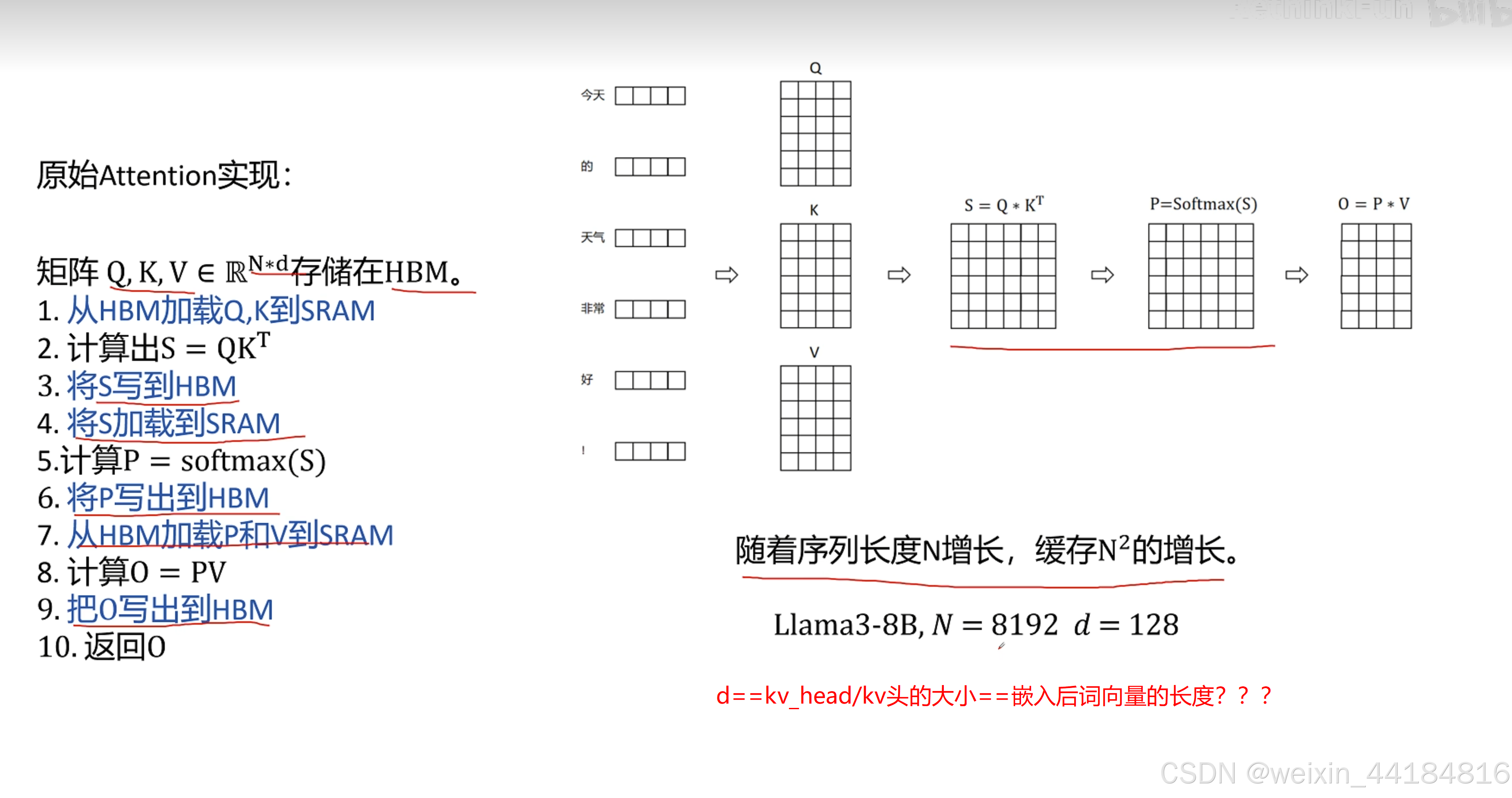
kv_cache为什么不是qkv_cache
-
tokenizer embedding 词表对比
-
吞吐量(throughput)与延迟(latency)
-
通信源语-- wiki笔记里有
-
MLA vs MLP
MLA == atttention == FlashAttention
MLP == FFN == MOE
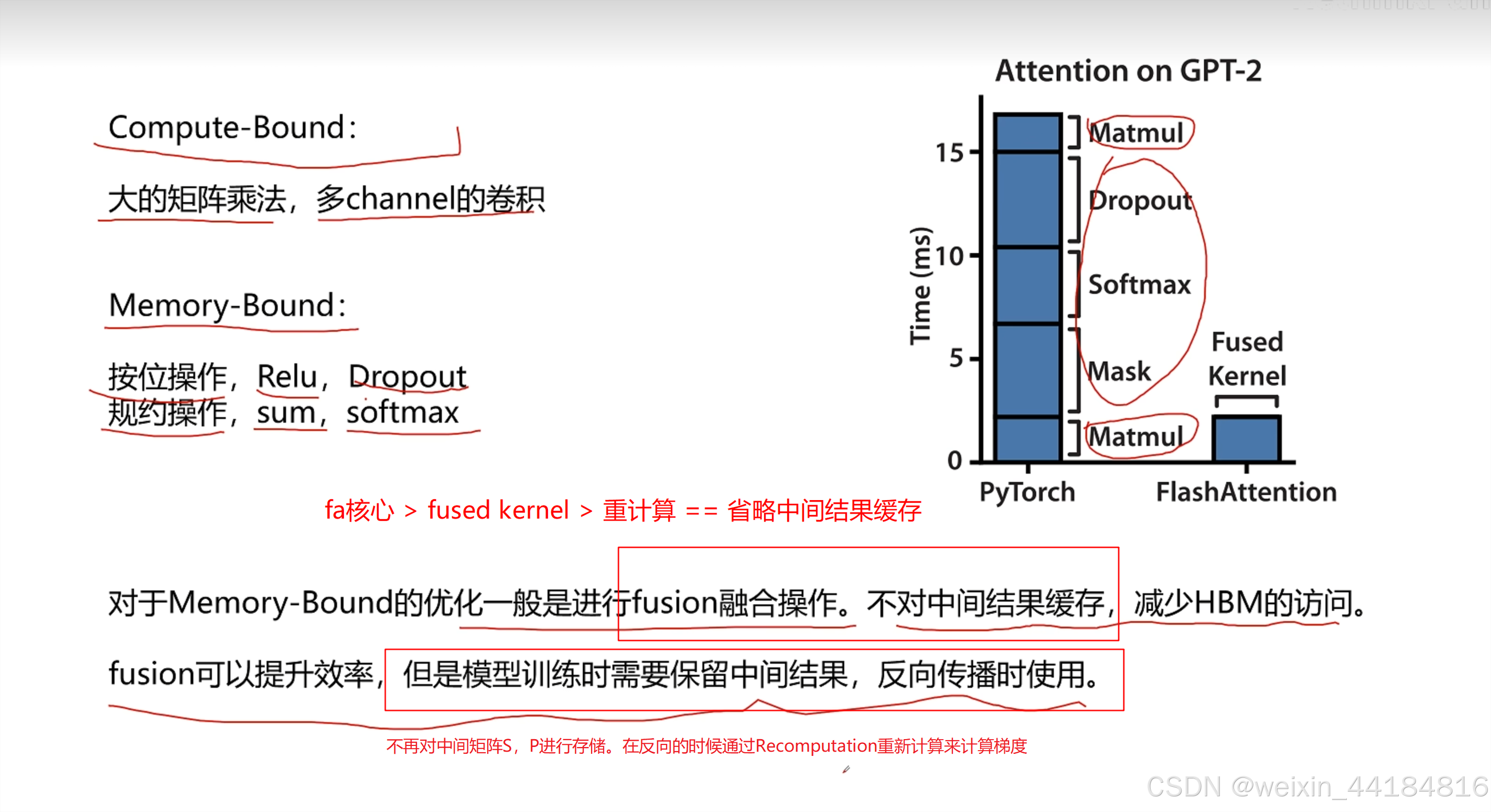
flashed attention
计算换内存,提升少量计算量/计算时间,减少IO/memory bound影响,减少IO时间;大幅减少decode阶段?总计算时间== 提升计算效率
Flash Attention 为什么那么快?原理讲解_哔哩哔哩_bilibili
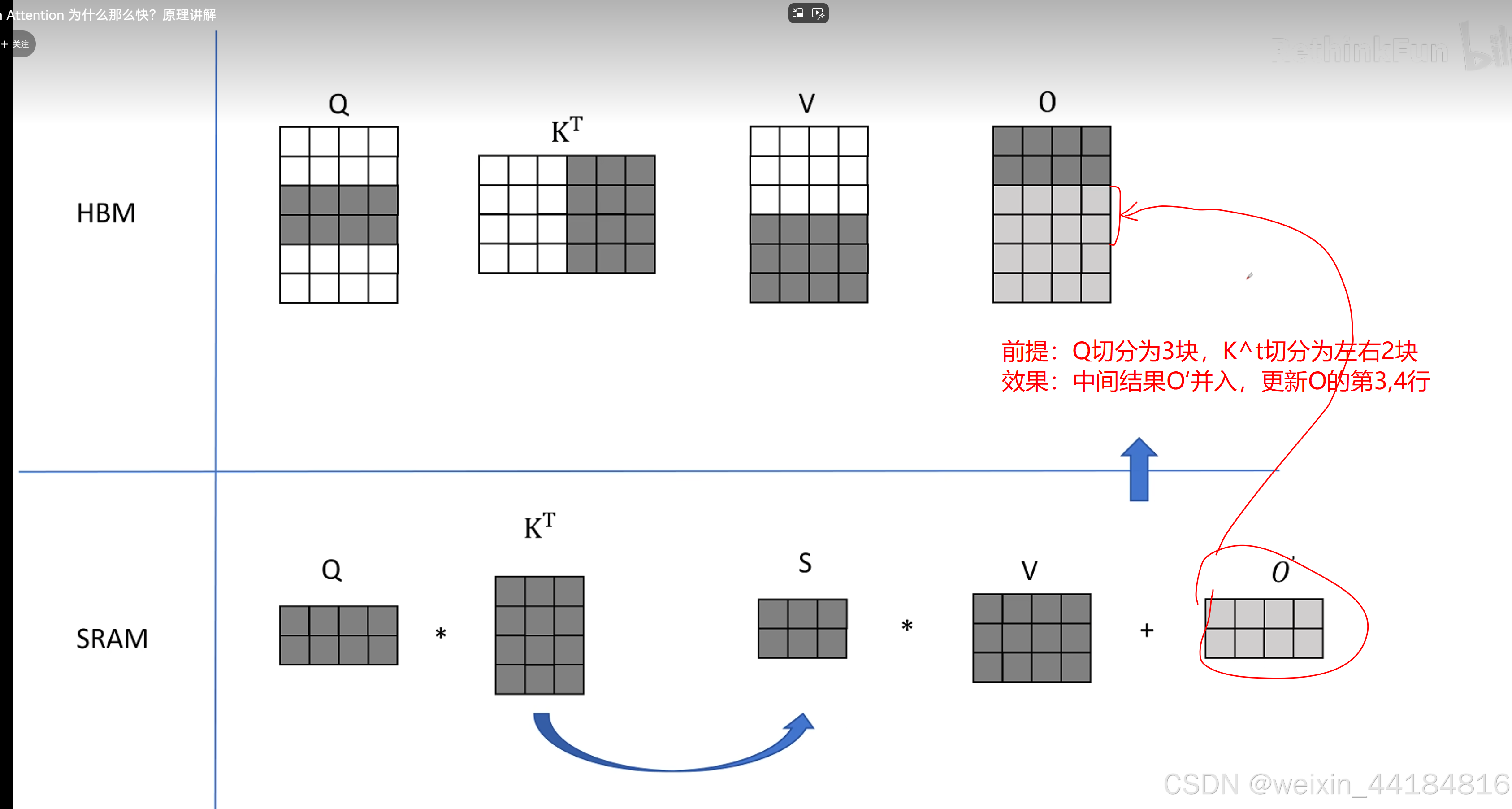

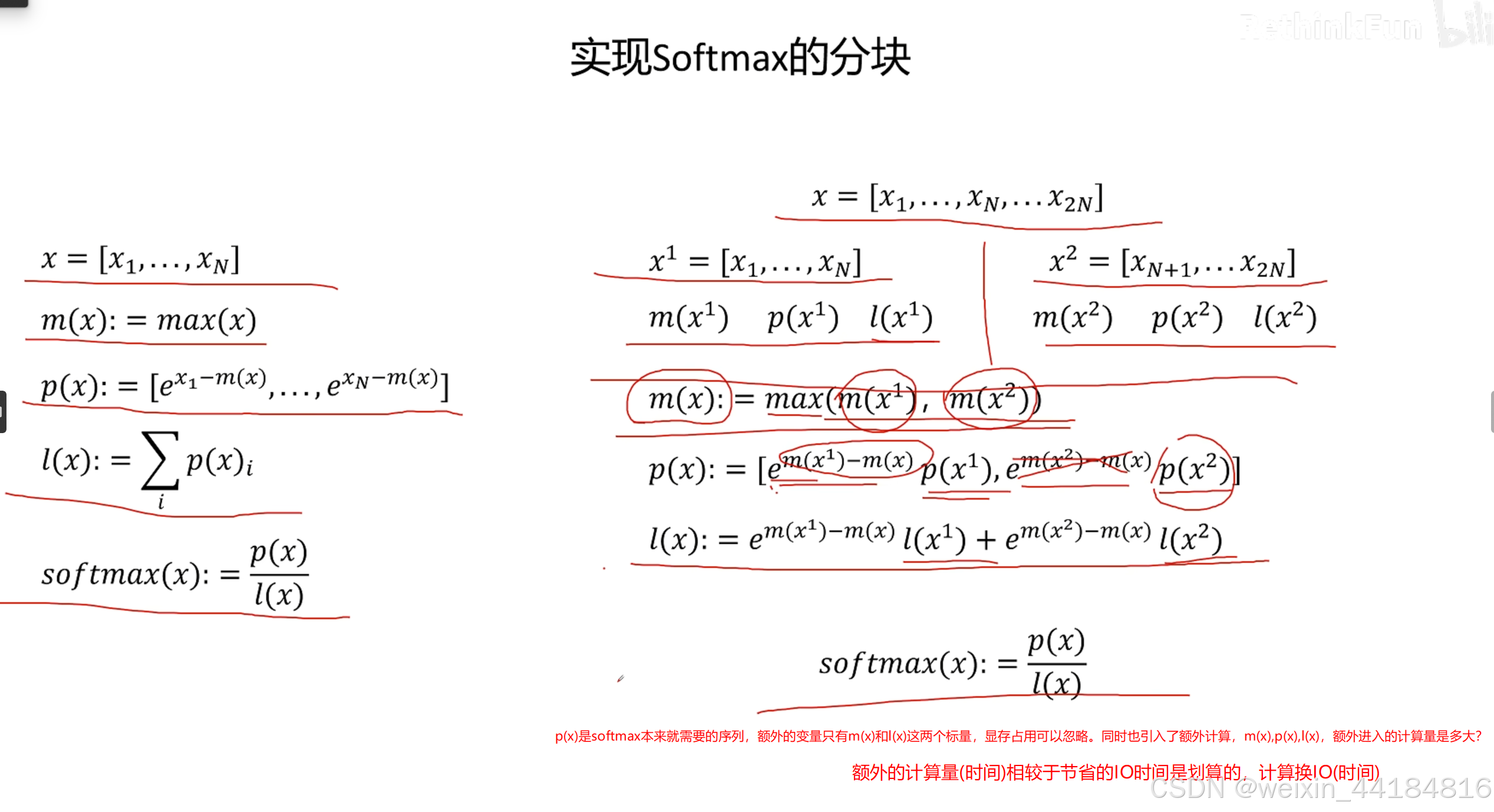

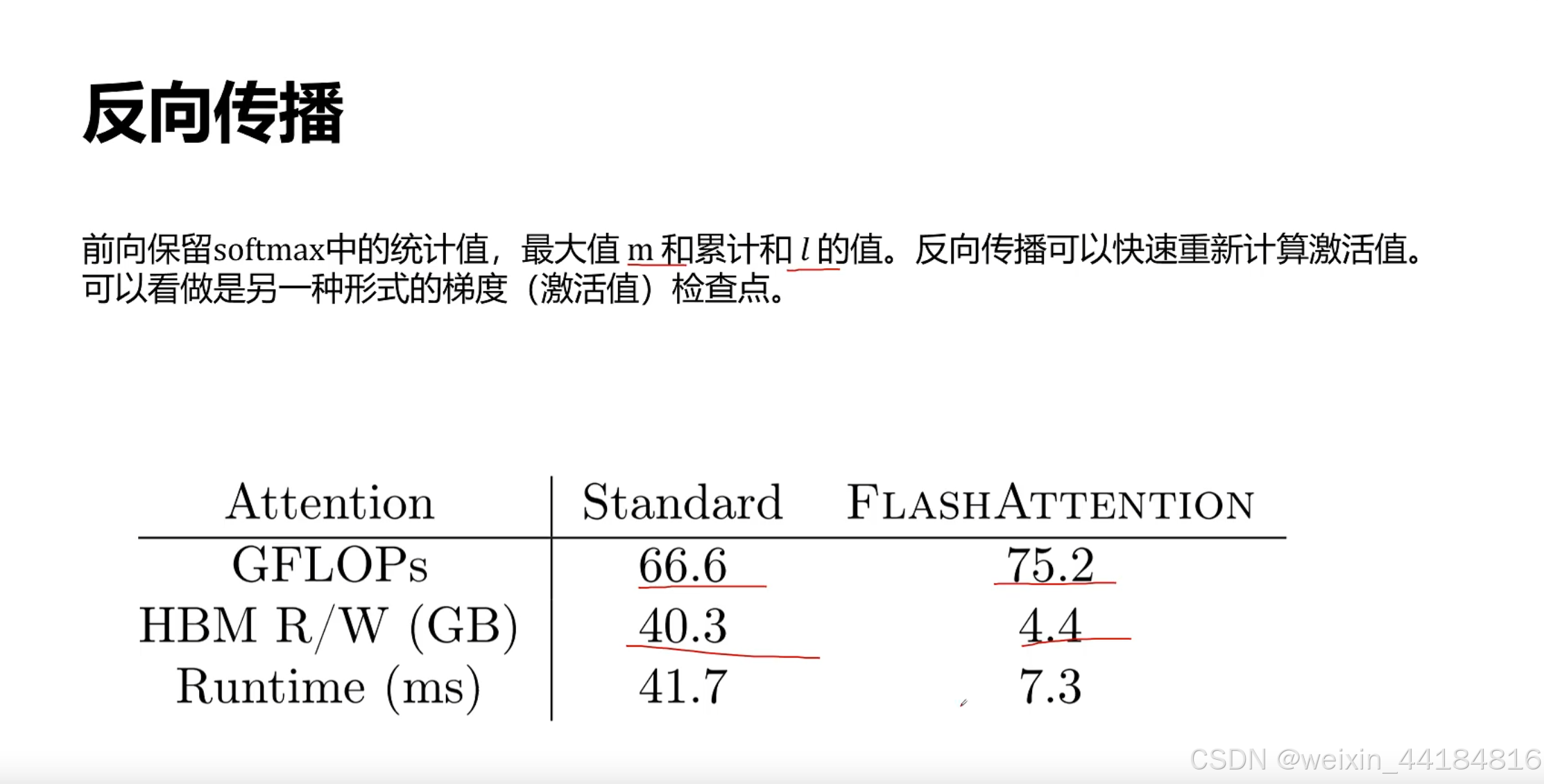

paged attention —
基于kv cache技术,更好的管理kv cache的内存存储, 节省内存空间
维护一个block table :管理物理内存块和逻辑内存块的对应关系,降低内存空间浪费
PagedAttention(vLLM):更快地推理你的GPT - 飞书云文档 (feishu.cn)
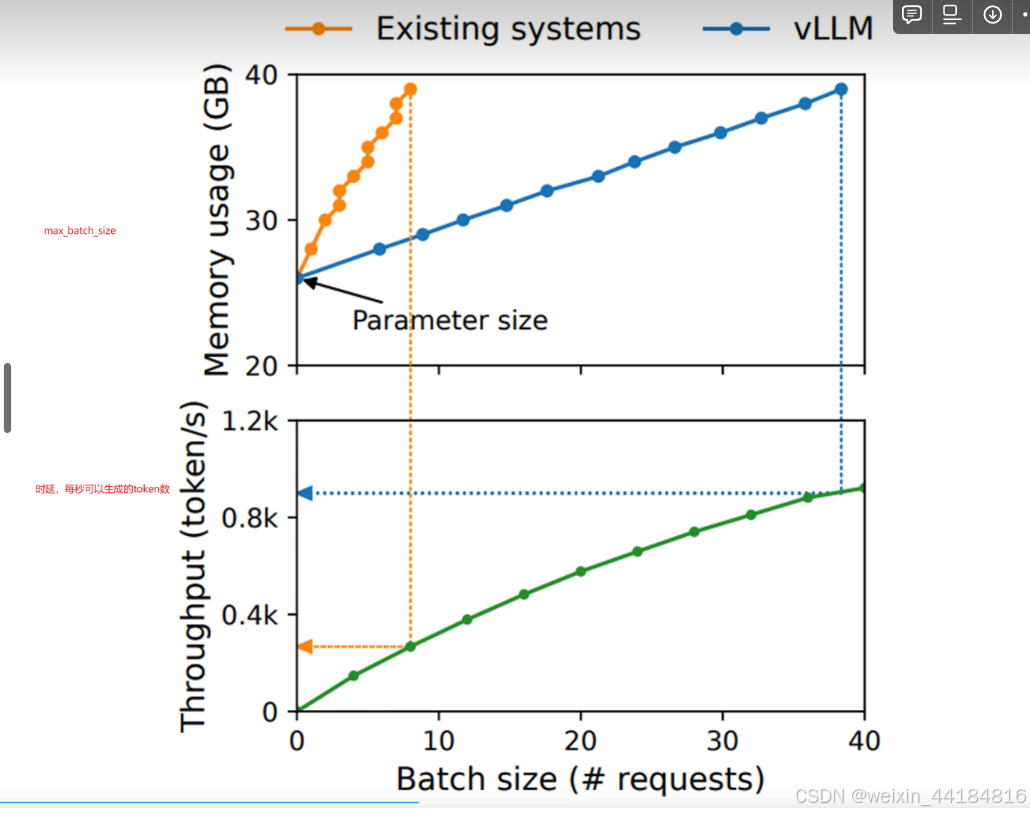
为确保安全共享,PagedAttention跟踪物理块的引用计数并实现 Copy-on-Write 机制。 通过PagedAttention的内存共享机制,极大地降低了复杂采样算法(如ParallelSampling和BeamSearch)的内存开销,使其内存使用量下降了高达55%。这项优化可以直接带来最多2.2倍的吞吐量提升
paged attention 2
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention_哔哩哔哩_bilibili
vLLM源码阅读s1——源码介绍_哔哩哔哩_bilibili
1.block table
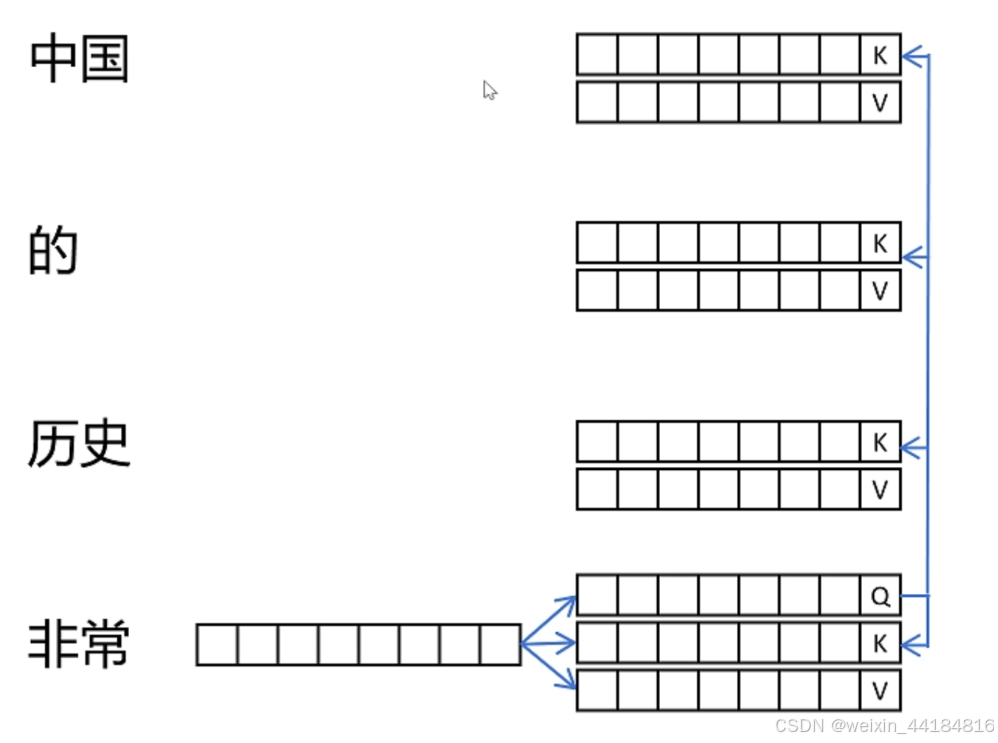
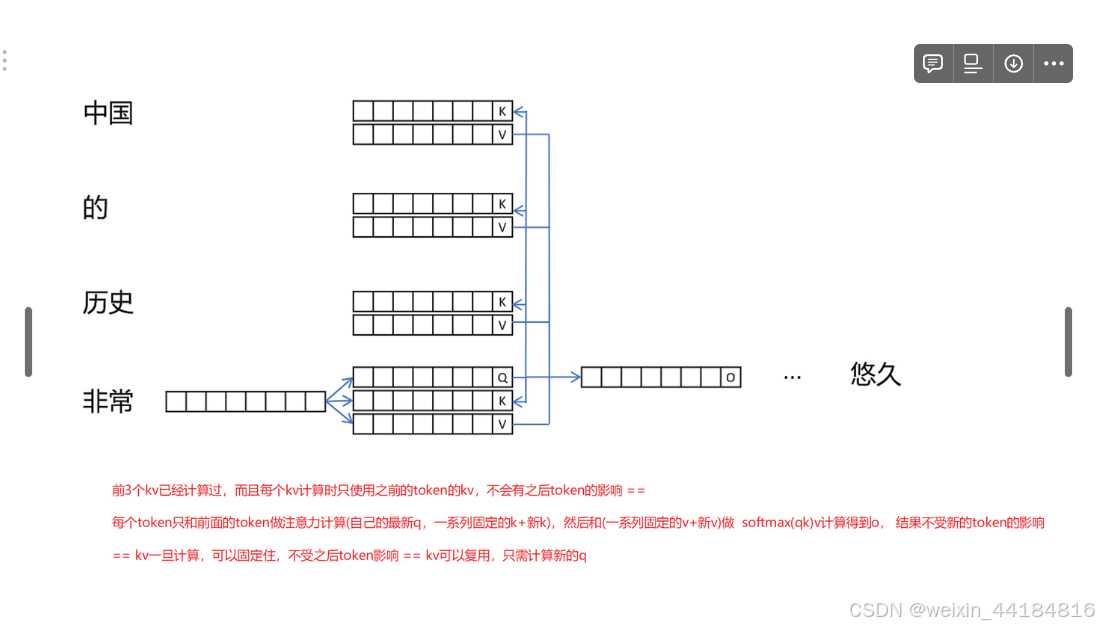
前3个kv已经计算过,而且每个kv计算时只使用之前的token的kv,不会有之后token的影响 ==
每个token只和前面的token做注意力计算(自己的最新q,一系列固定的k+新k),然后和(一系列固定的v+新v)做 softmax(qk)v计算得到o, 结果不受新的token的影响
== kv一旦计算,可以固定住,不受之后token影响 == kv可以复用,只需计算新的q
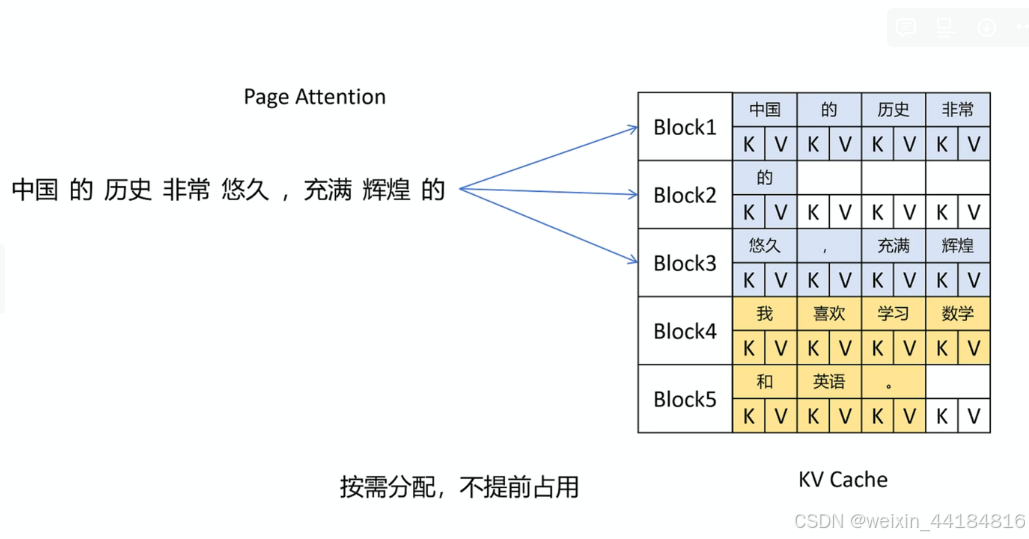
克服内存预分配,而且是按块分配,新生成会填入直到填满后再申请新的block
减少内存碎片
虚拟内存/逻辑kv cache vs 物理内存
映射表/block table
2.内存共享/sharing KV Blocks
1个输入生成多个输出时 == prompt 共用 == 起始位置的kv cache共享/ kv block共享 == 节省显存
block的引用数> 1, copy on write== 先将原先的引用数减1,然后将原来的block内容拷贝一份来写入。然后拷贝的block和原来的block各自开始生成,写入各自的block
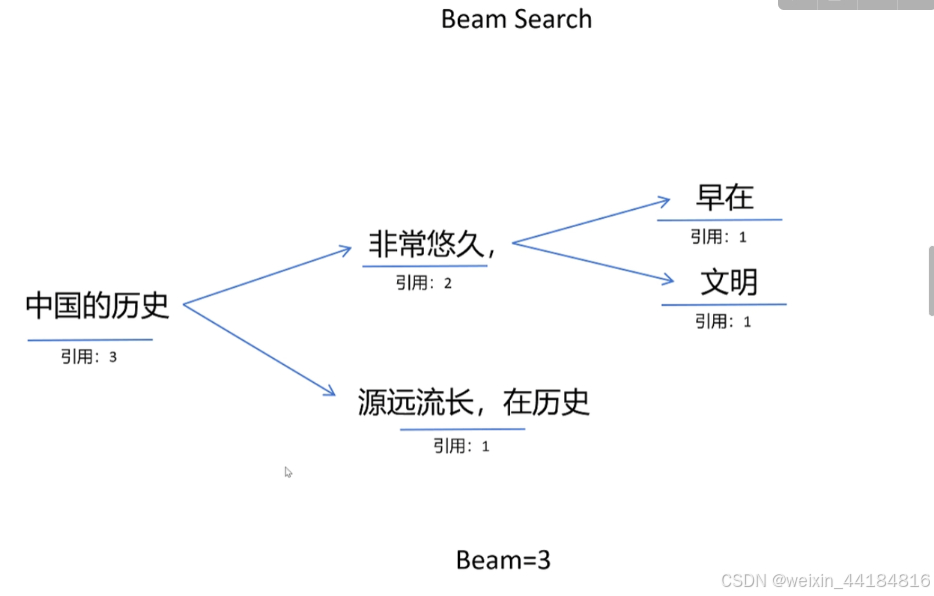
优化beam search

















 5278
5278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









