






zomi课程:
课程内容大纲 — AI System (chenzomi12.github.io) https://chenzomi12.github.io/chenzomi12/AISystem: AISystem 主要是指AI系统,包括AI芯片、AI编译器、AI推理和训练框架等AI全栈底层技术 (github.com)https://github.com/chenzomi12/AISystem
https://chenzomi12.github.io/chenzomi12/AISystem: AISystem 主要是指AI系统,包括AI芯片、AI编译器、AI推理和训练框架等AI全栈底层技术 (github.com)https://github.com/chenzomi12/AISystem
I. 分布式1
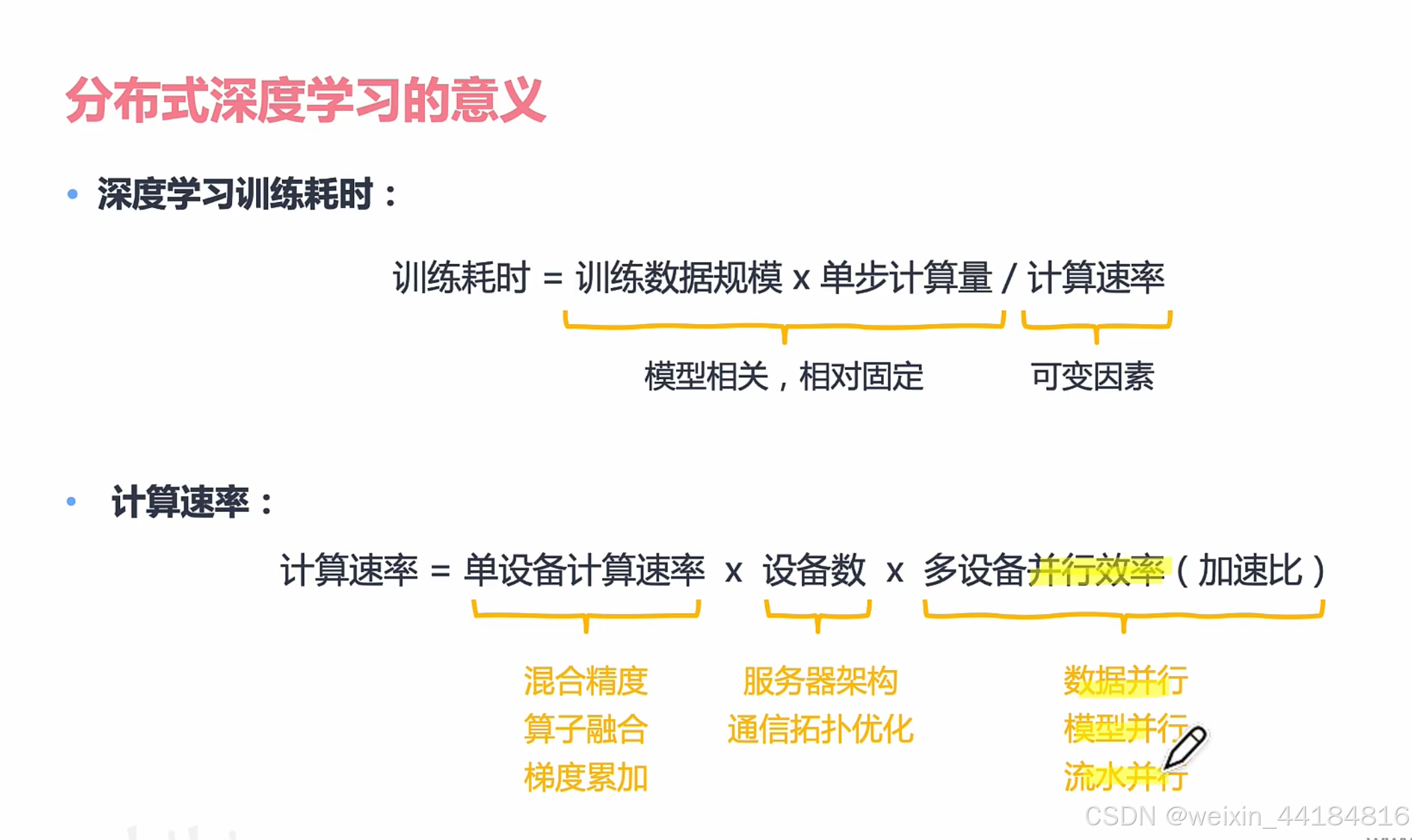
1.简介
总体结构
2. DP
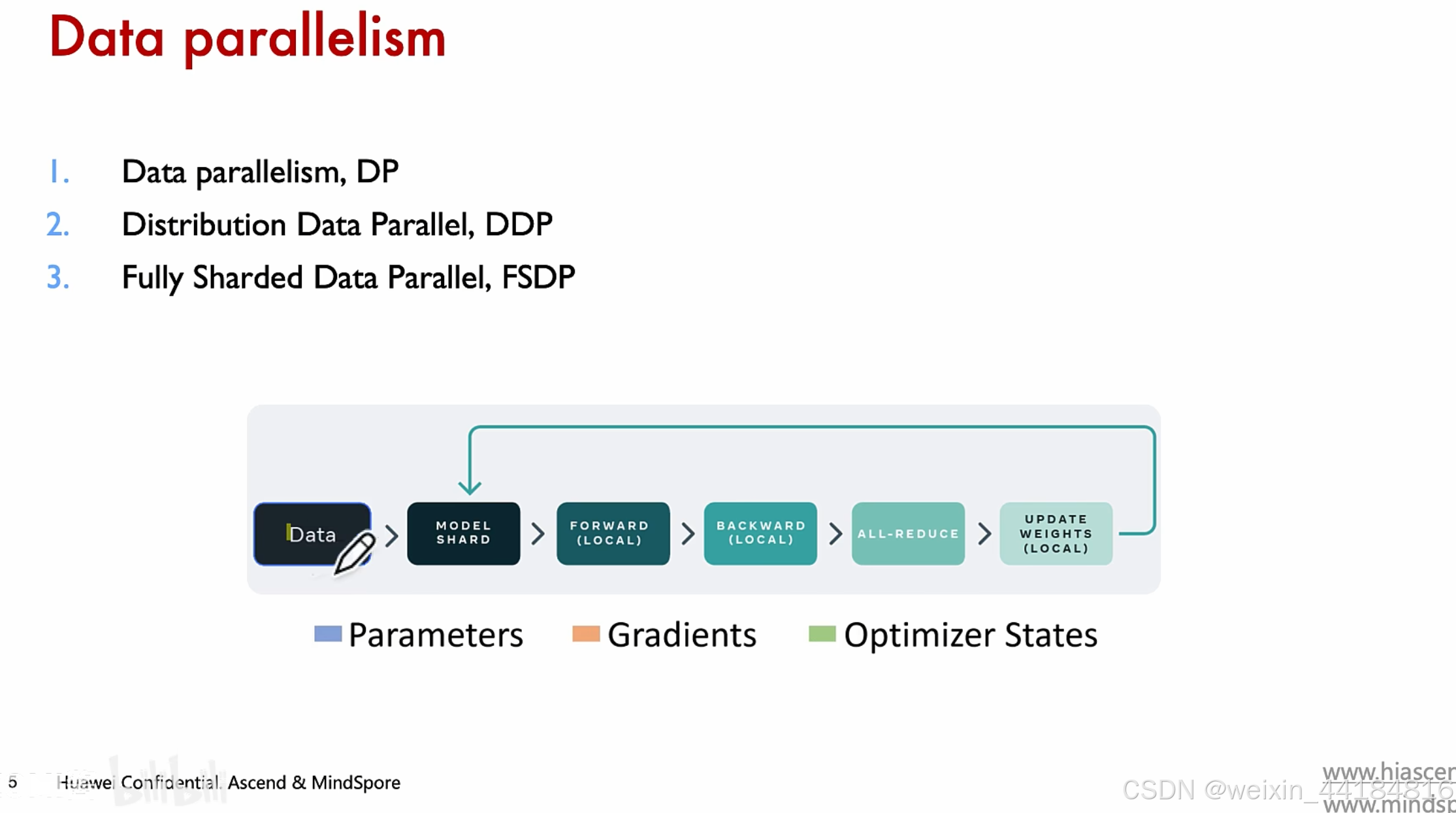
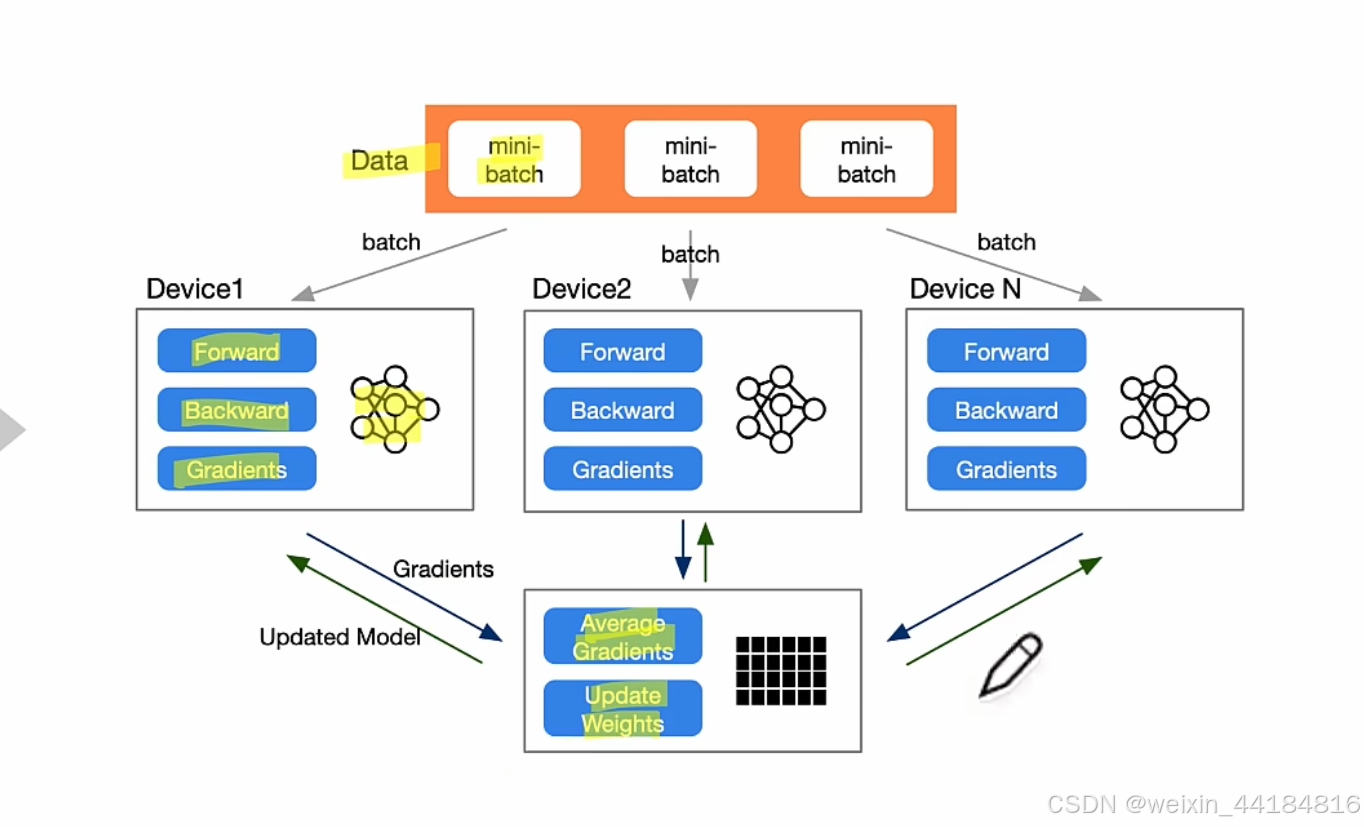
dp 数据并行
ddp 梯度并行
fsdp 优化器并行:网络模型的参数 + 优化器的状态
梯度并行,

p: parameter, 参数
os:optimizer states 优化器状态
g:gradient 梯度
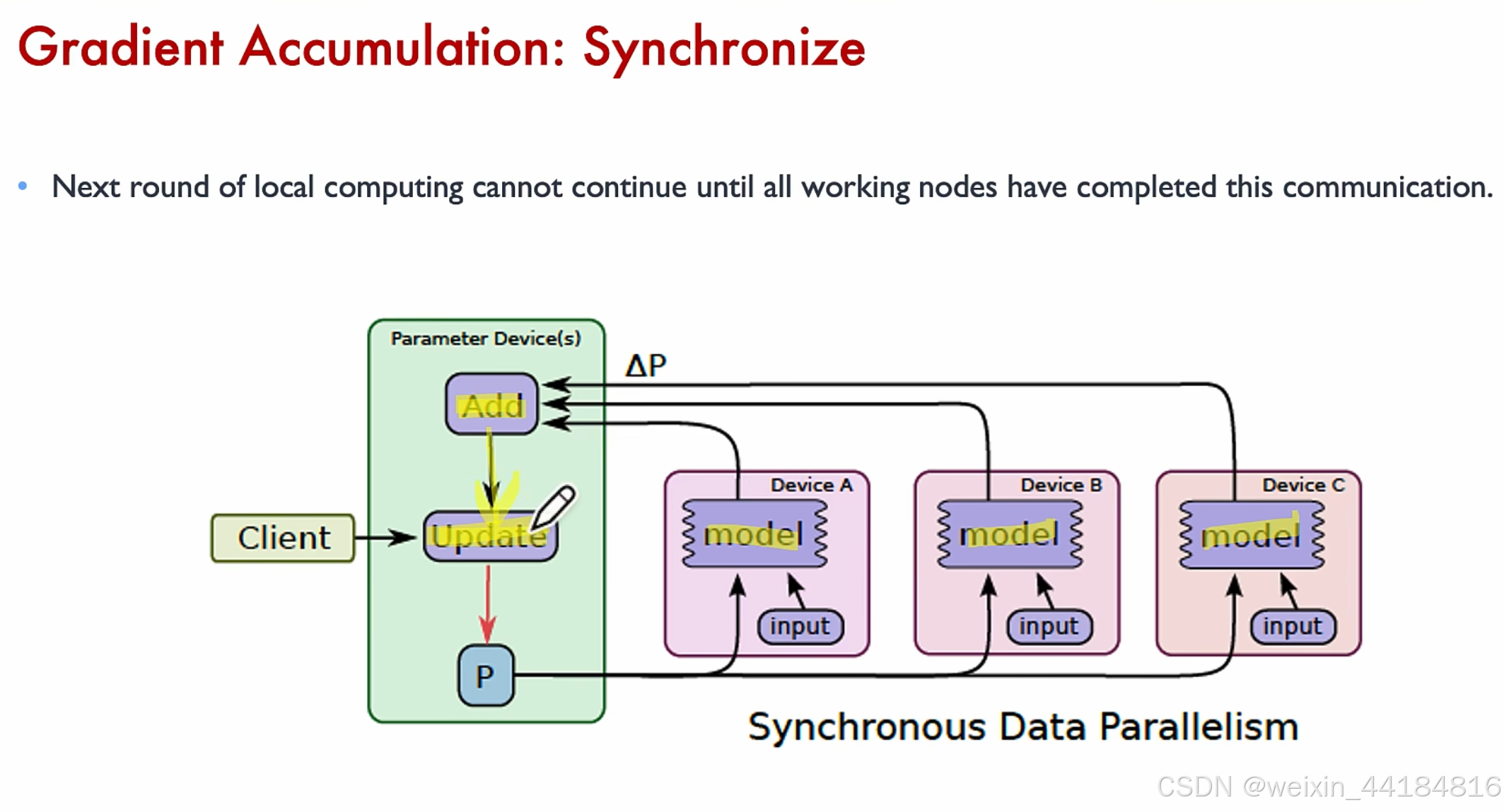
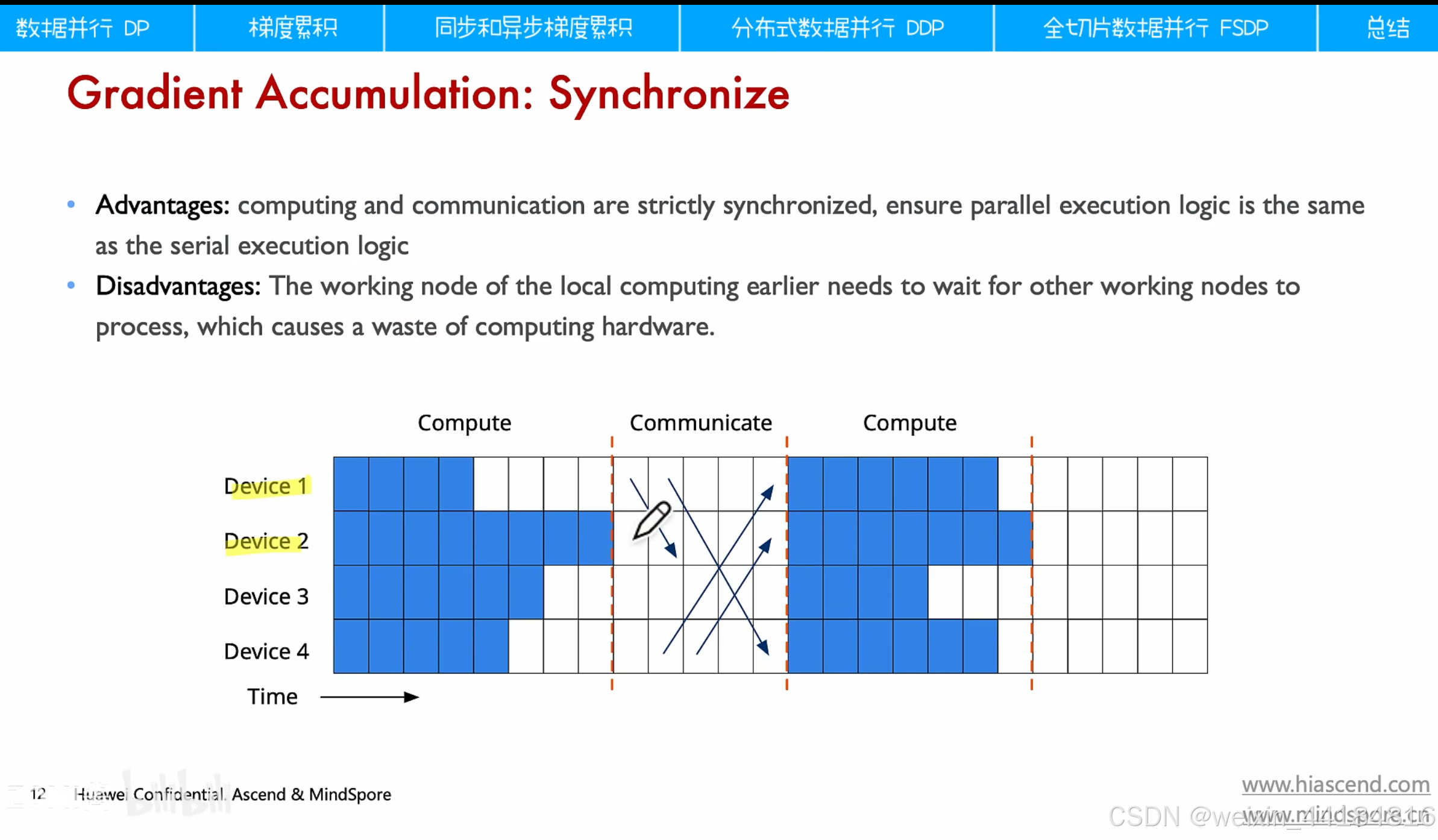
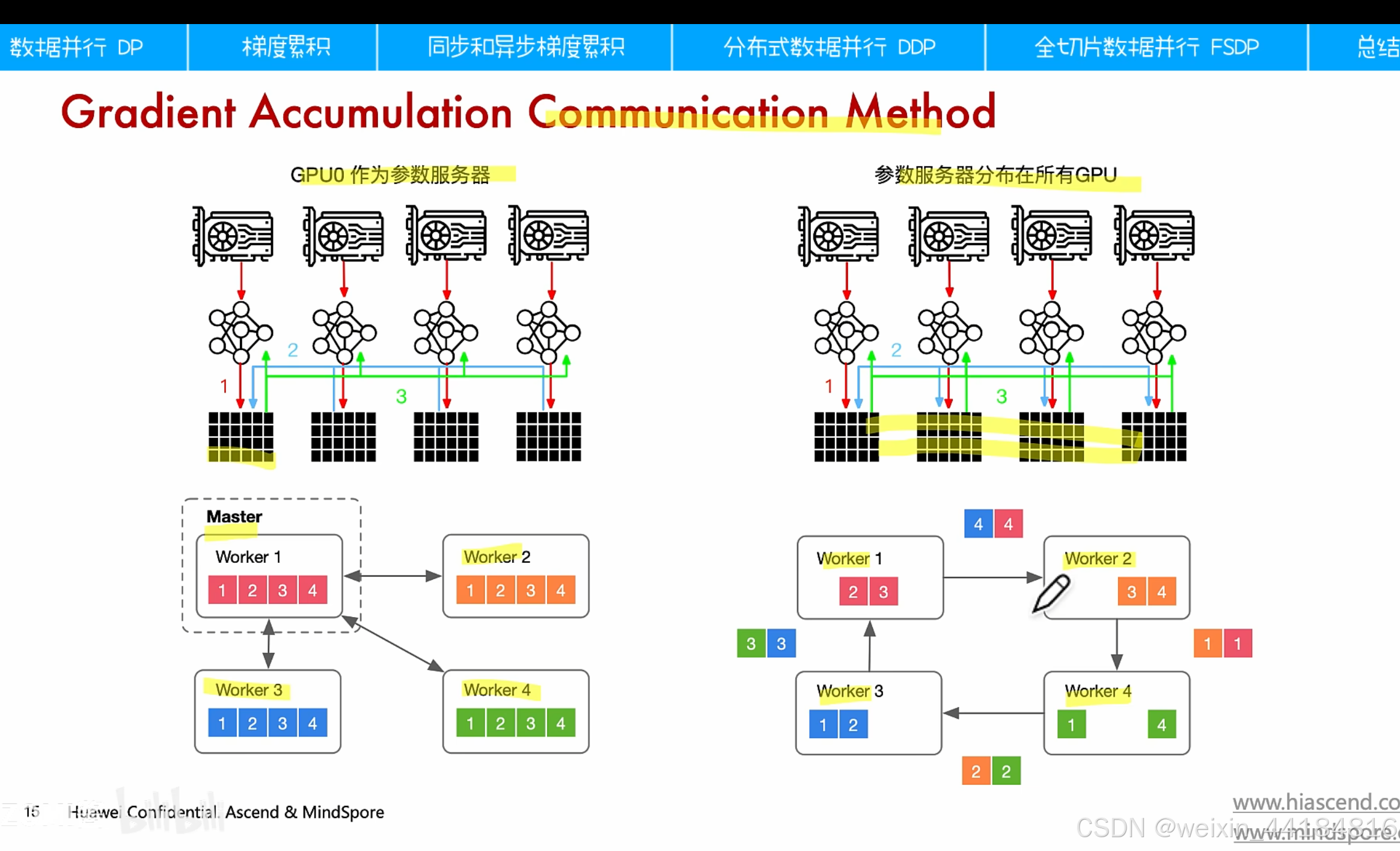
2.1 梯度累计:how,when?
1.同步梯度累计 vs 异步梯度累计
难以收敛

ddp
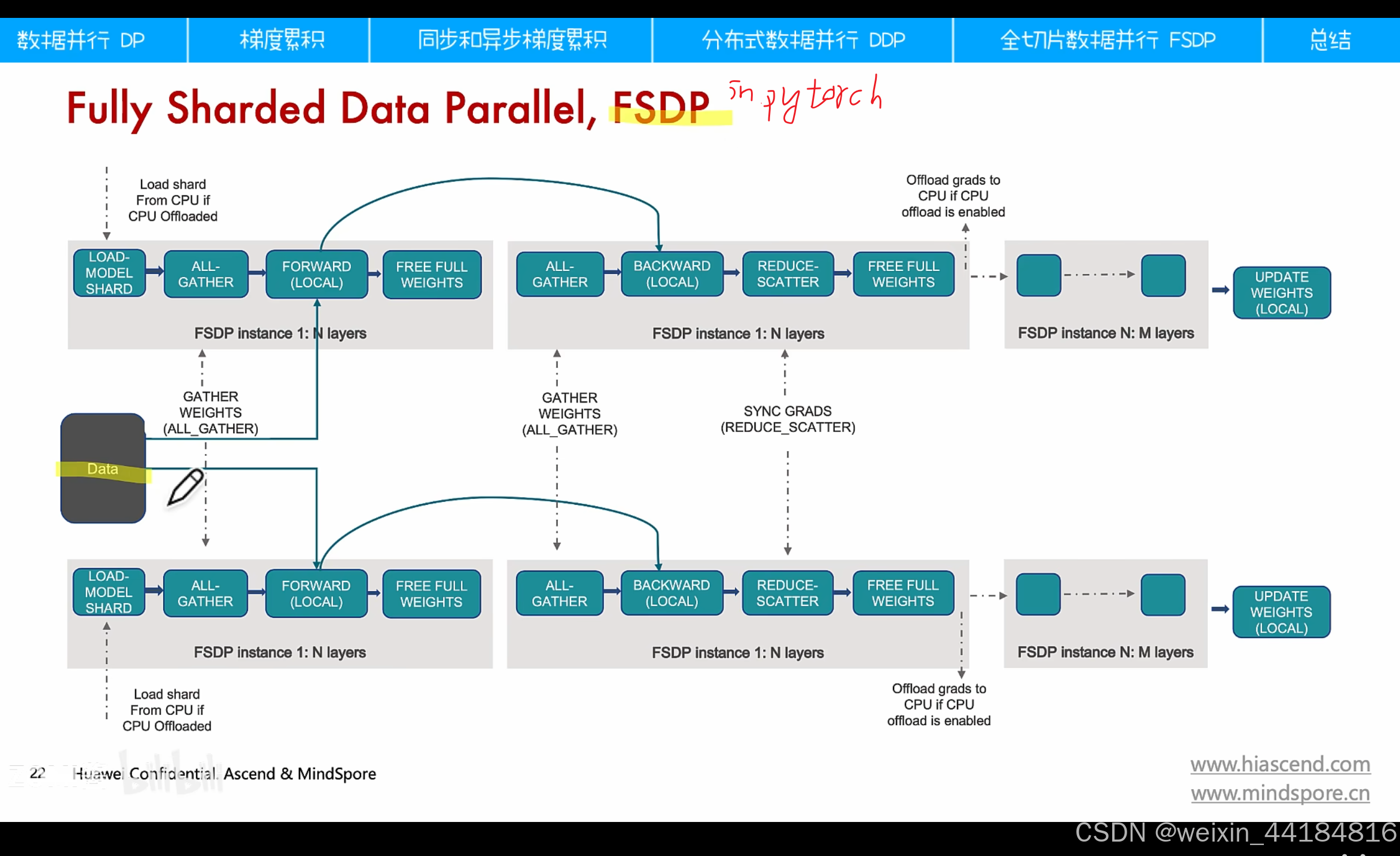
fsdp
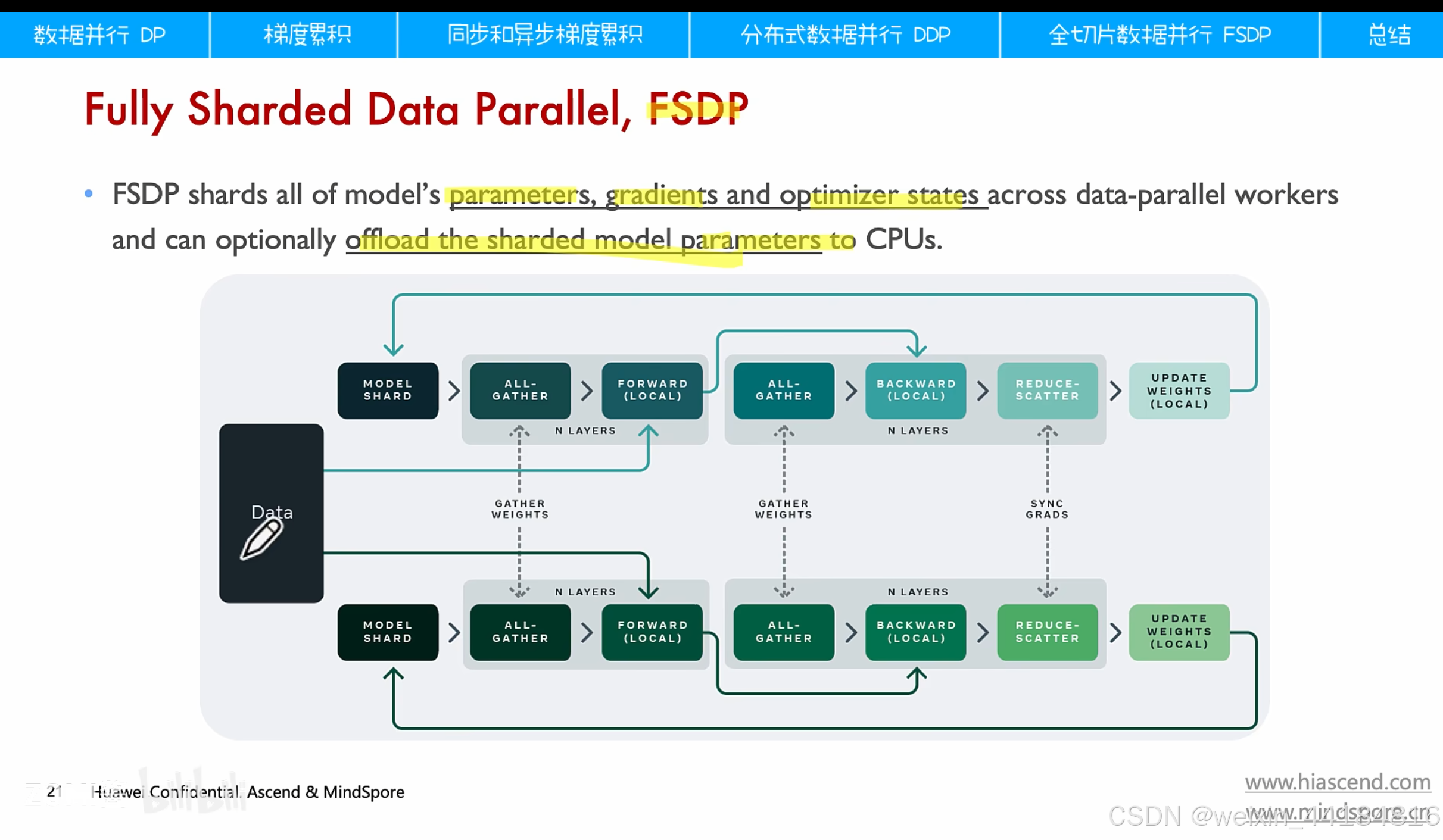
计算顺序: forward, backward, reduce-scatter, update weights , model shard, all-gather
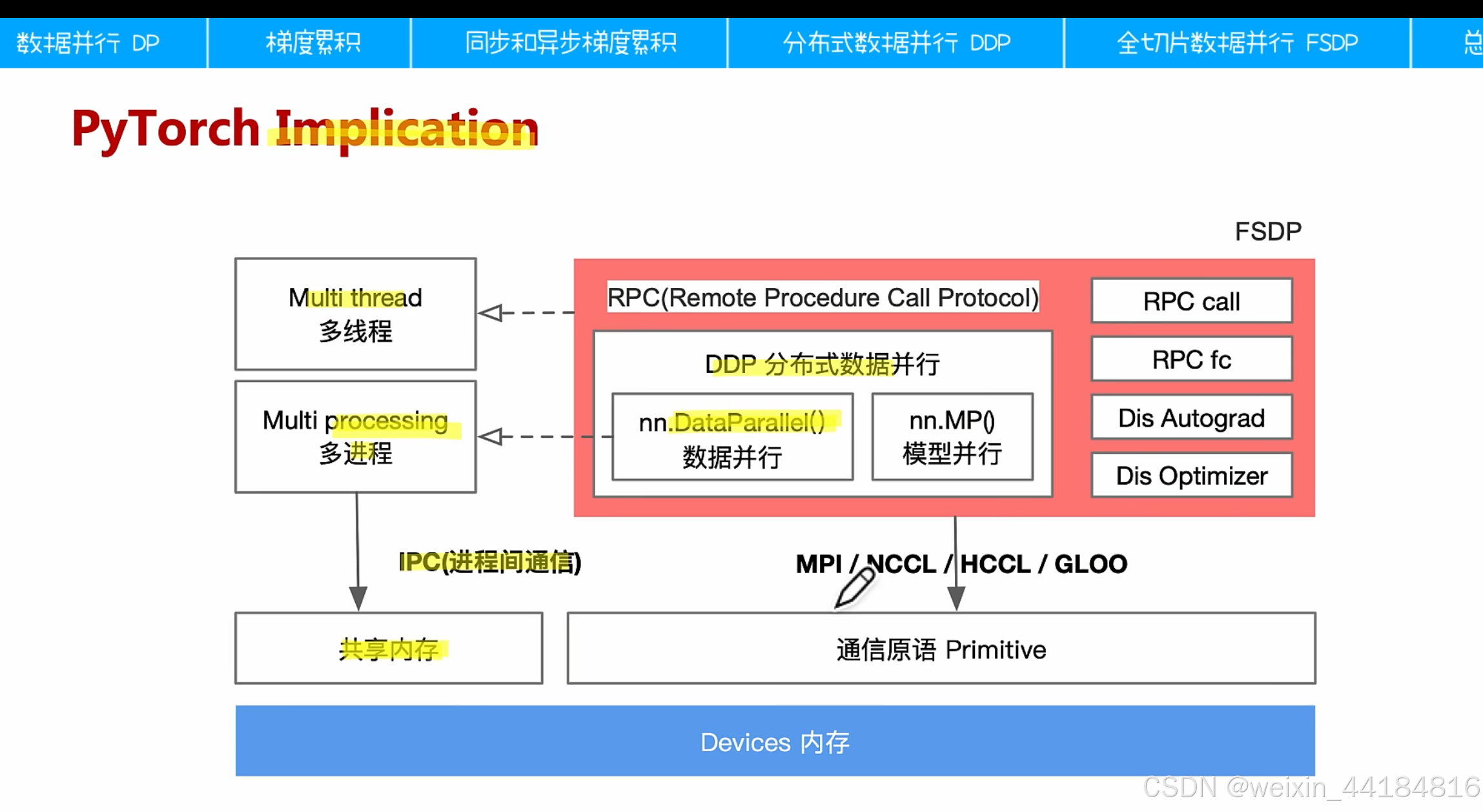
dp:多进程
ddp:多线程
FSDP:RPC, RPC call, RPC fc, Dis Autograd, Dis Optimizer
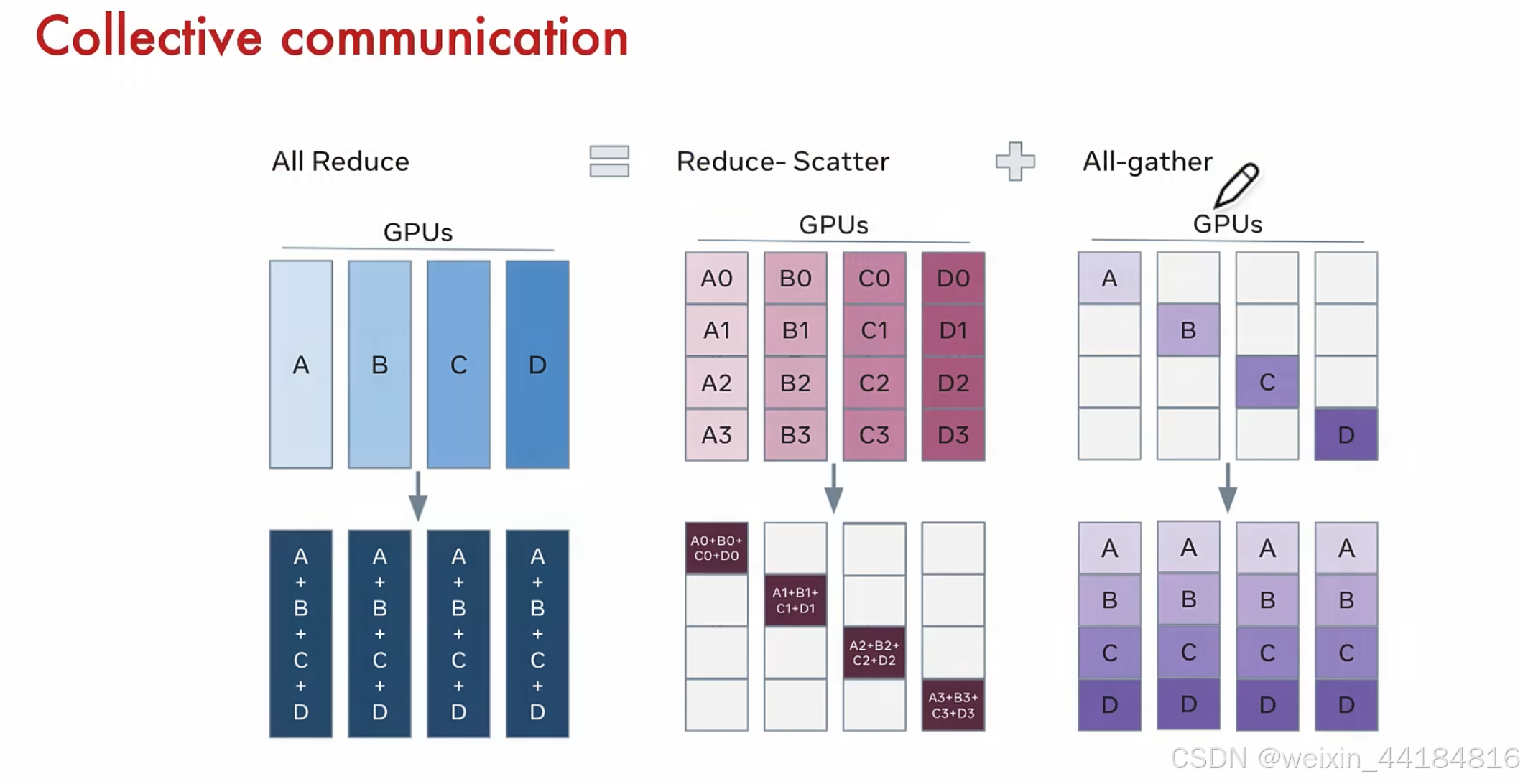
通信库:MPI,NCCL,HCCL,LCCL,GLOO
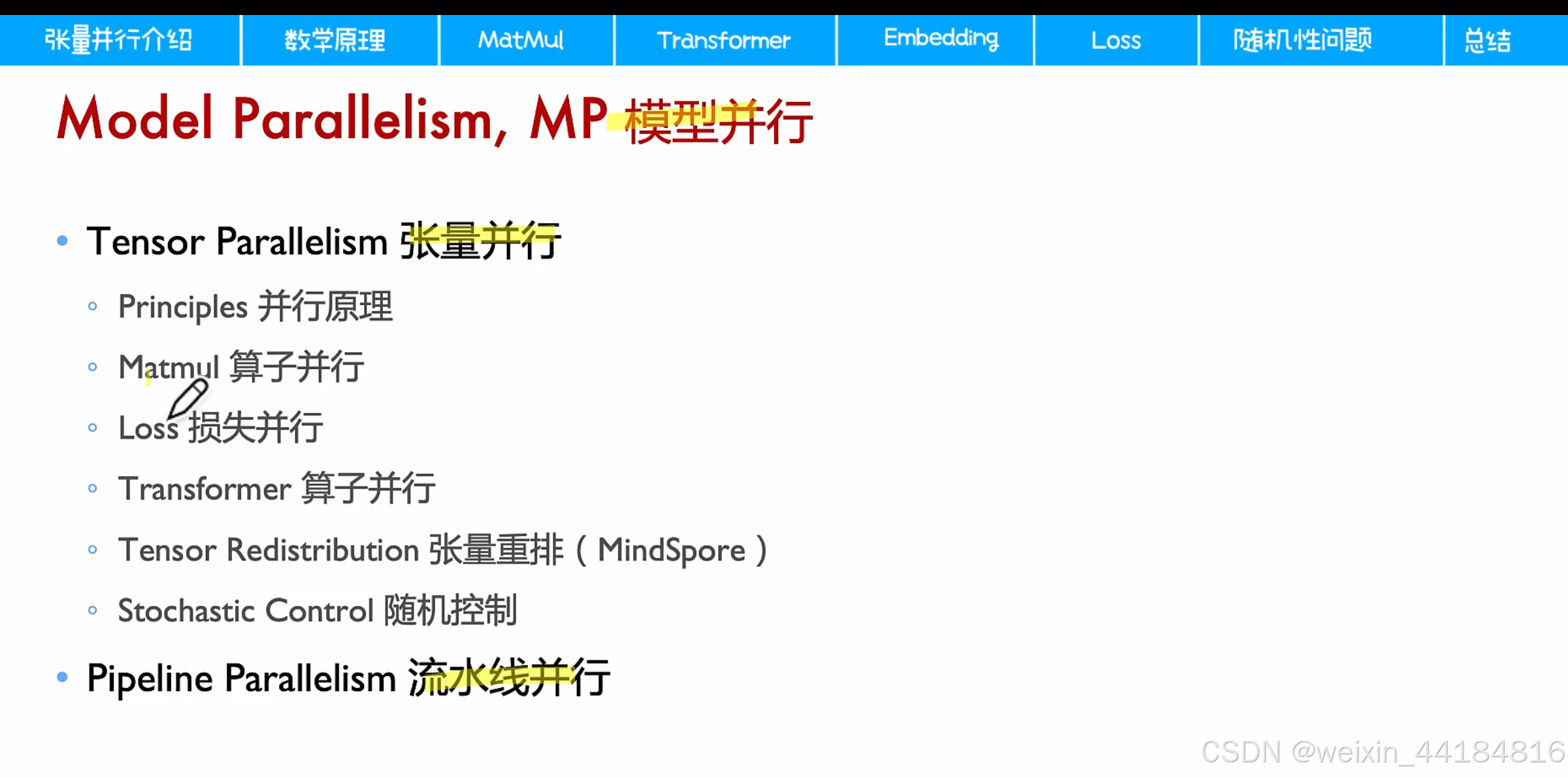
3.模型并行-张量并行tp

x不用切分,a列切,拼接不涉及计算,多列合并

x要切分,a行切,求和,多行合并
4.MLP并行/MatMul并行
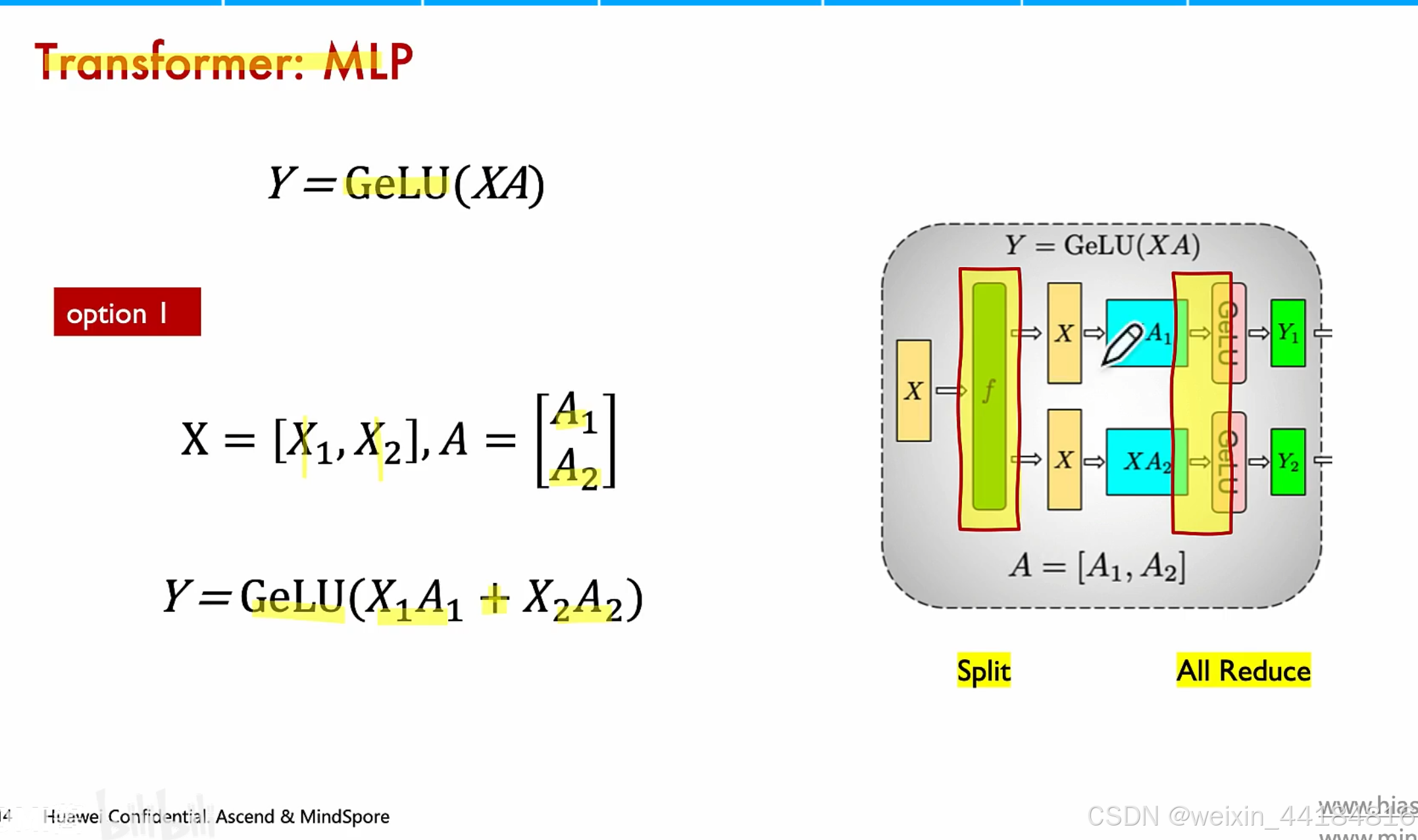
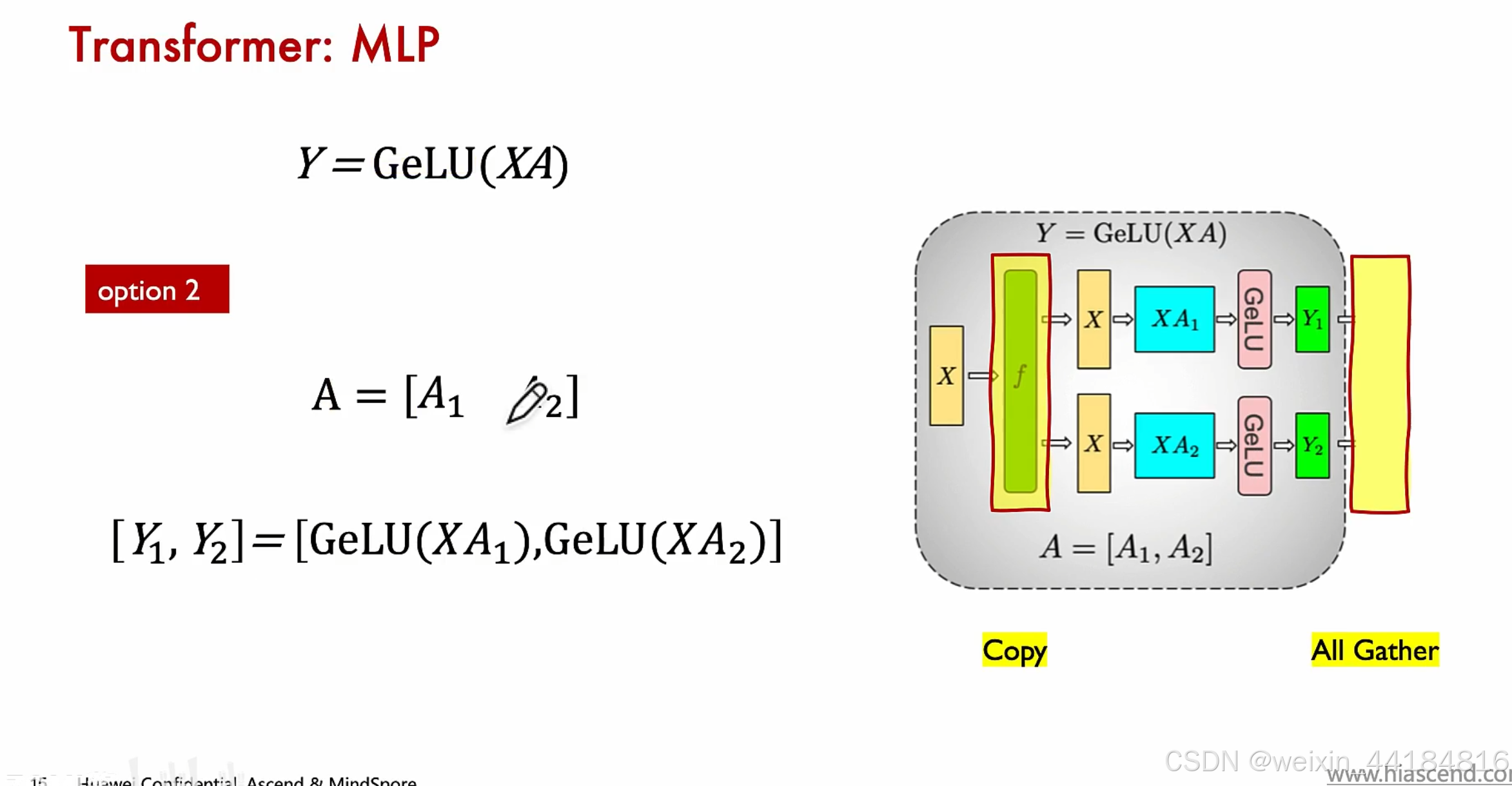
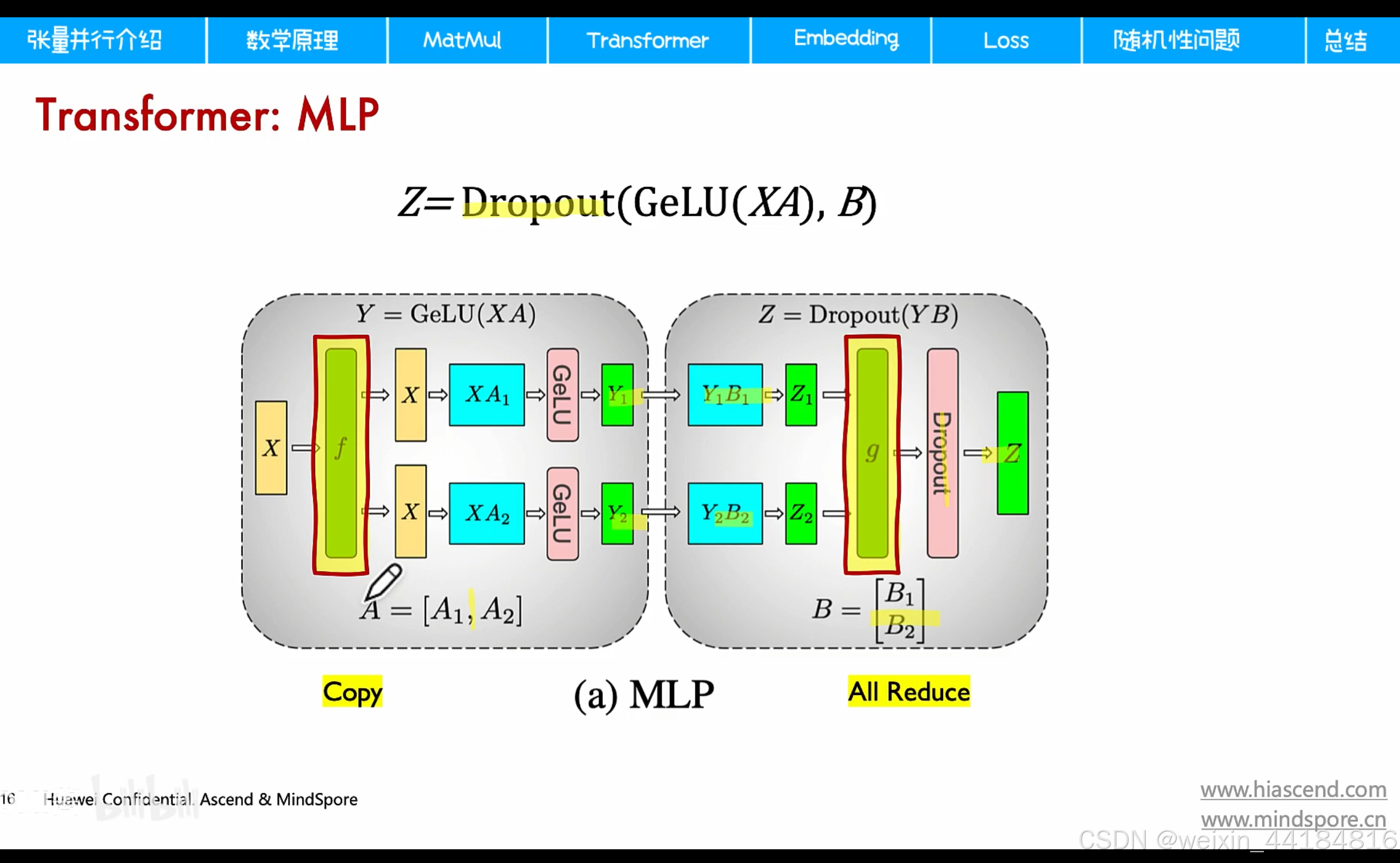
两次矩阵乘,分别乘以 A,B,A列切,B行切
通讯操作:copy,allreduce
3. self-attention 并行/Transformer
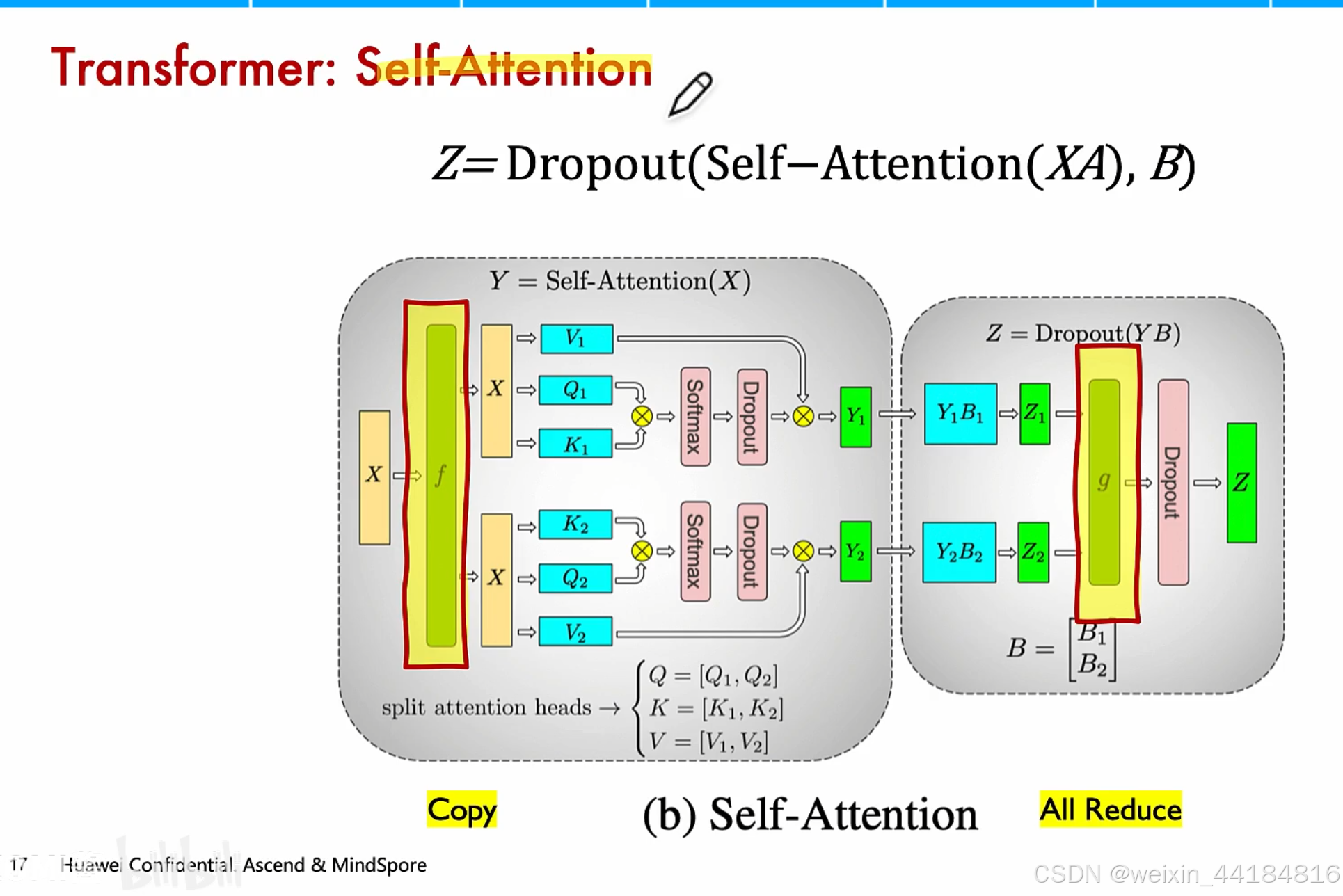
补充:QKV拆分策略---- 取决attention类型 ---> 权重切分
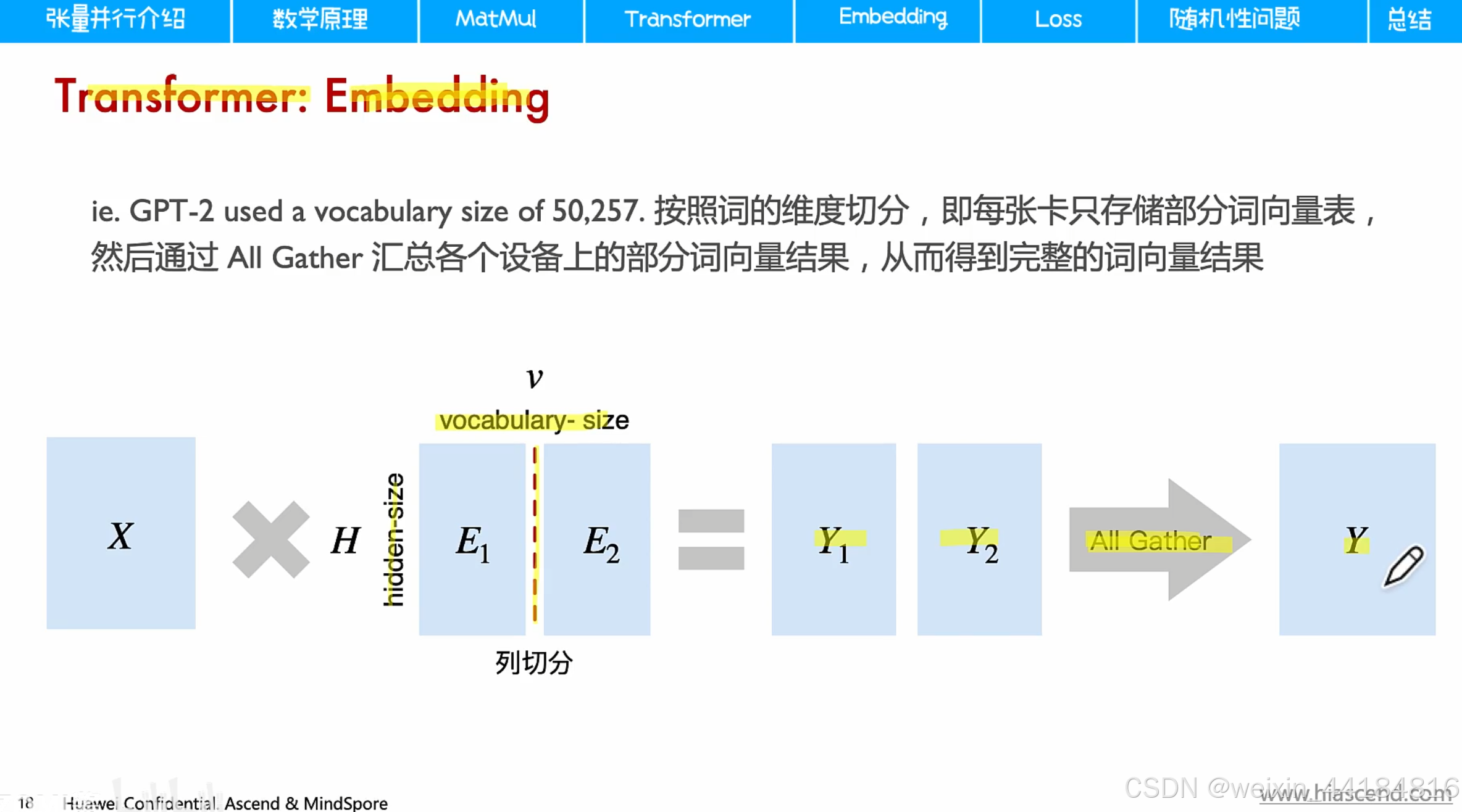
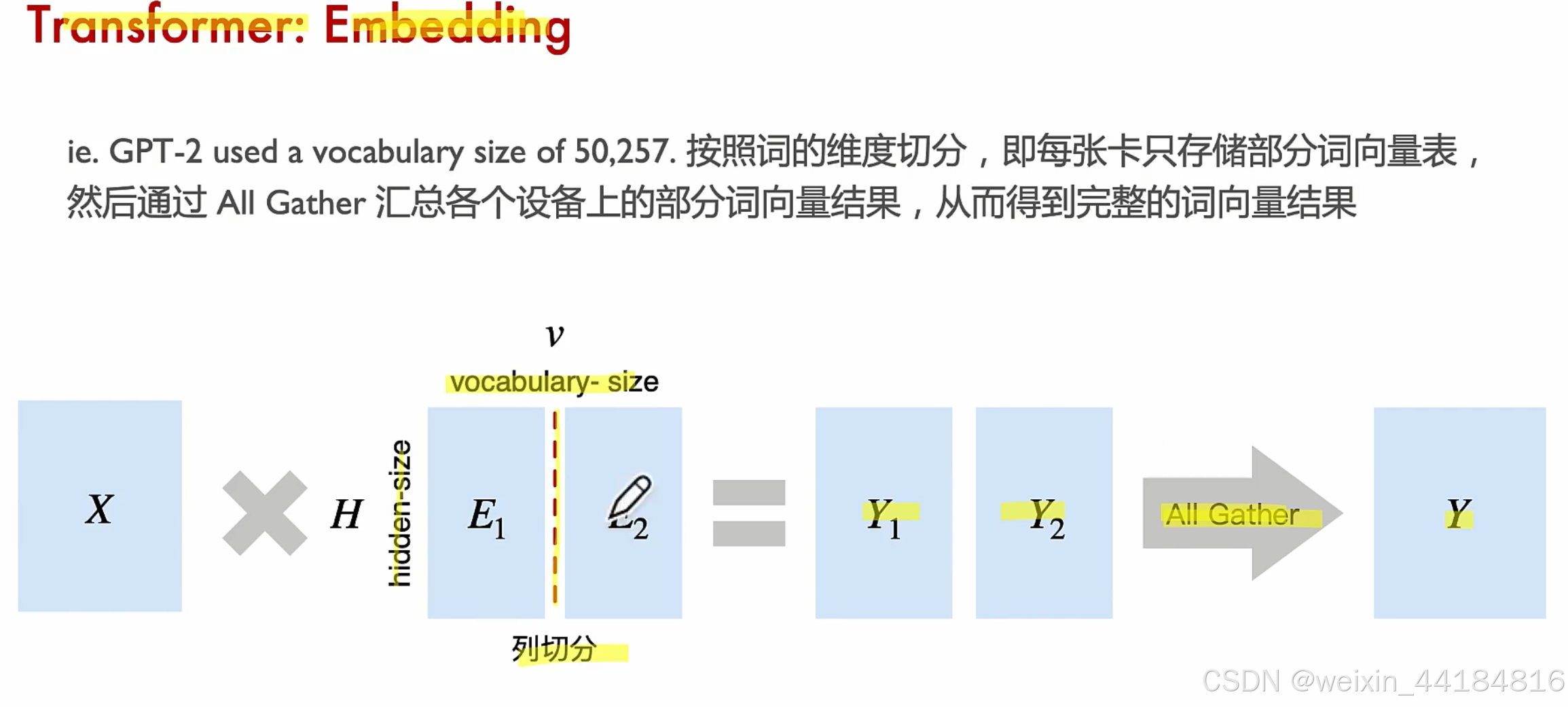
1. Embedding并行
嵌入矩阵维度: hidden size * vocabulary-size
vocabulary size == 词表大小 == 5万多维
5000* 4096 *2 /(1024*1024) = 40G ?
词表5万维,hidden size 4096维,如果用logit大小衡量词汇,会太大,用隐藏大小表示词汇/token,实际上是10倍左右的降维。
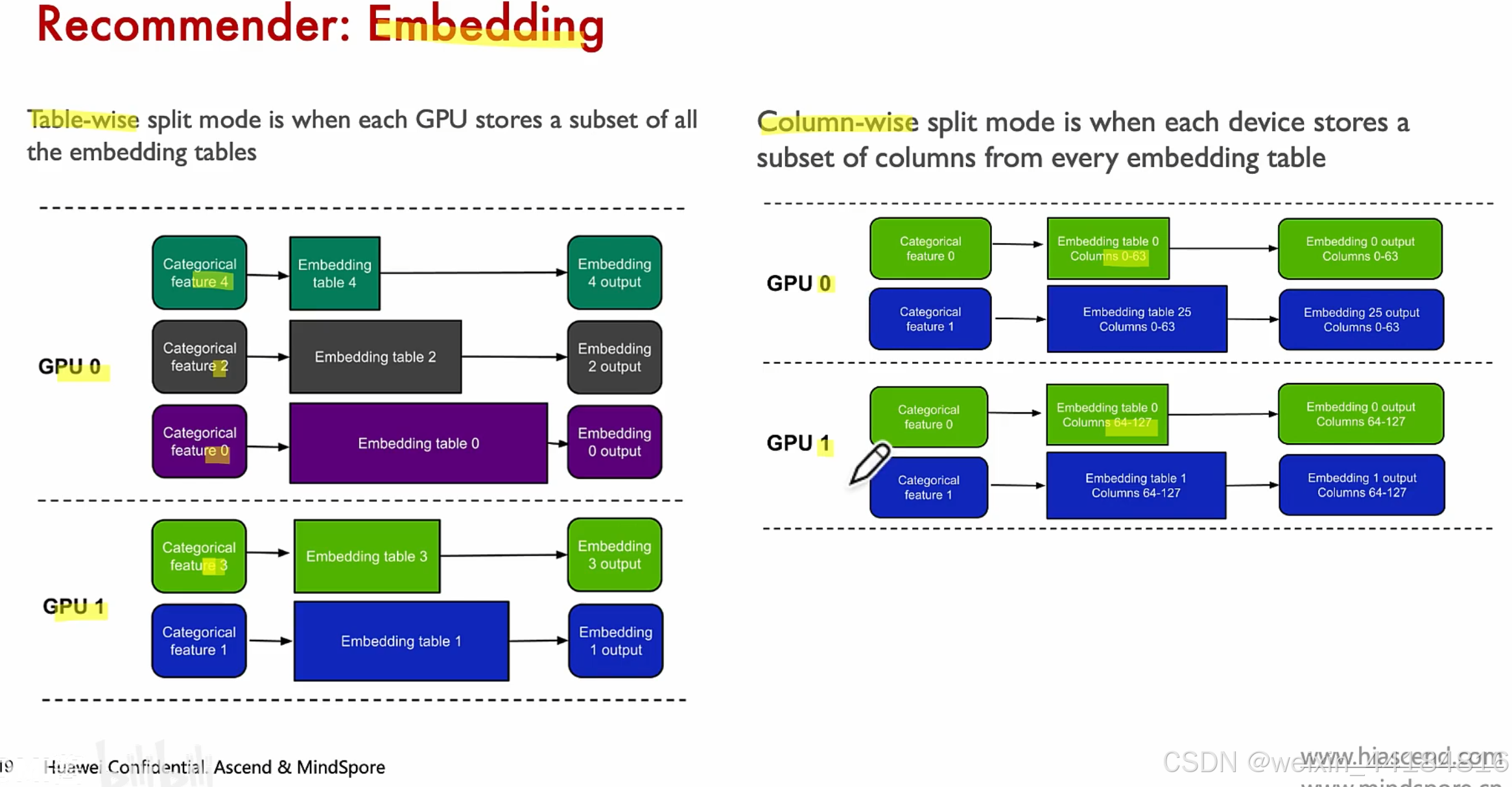
推荐模型-嵌入
table-wise:按特征切分 --- 特征完整
column-wise: 特征混合,按列切分 -- 特征表可以切分
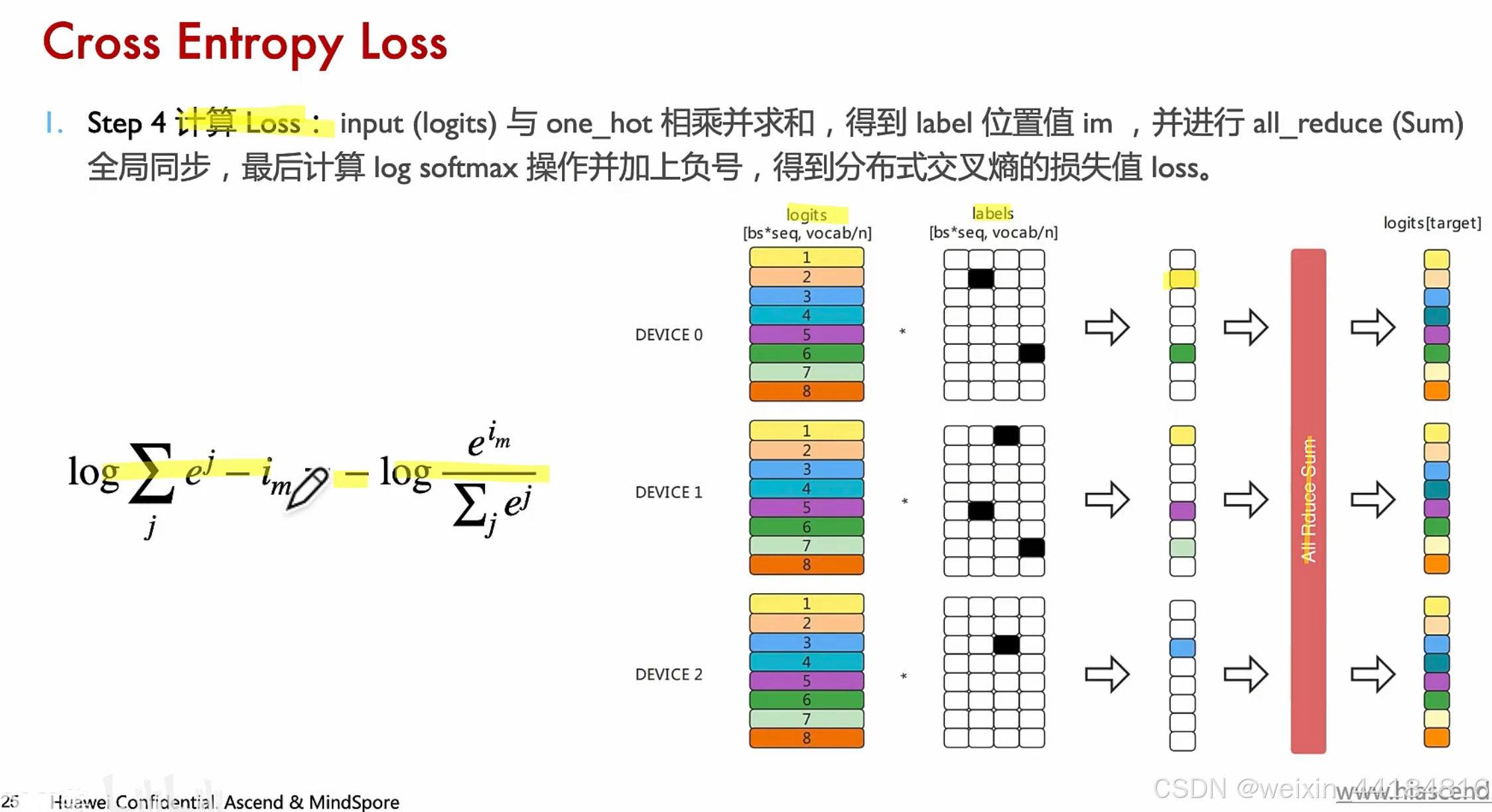
5. 交叉熵并行
label大小 == 对应词表大小 == logit大小 == 对应标签大小, 注意,这两者大小一致
词表5万维,hidden size 4096维,如果用logit大小衡量词汇,会太大,用隐藏大小表示词汇/token,实际上是10倍左右的降维。
每层输出的大小 [bs * seq_len, vocab_size] -------> 需要:大词表拆分 ---> 而且是按列/类别维度切分/vocab size维度 ----> 因为 vocab_size 是5万级别,bs和seq_len一般都是1000级别

logits矩阵维度 == labels矩阵(0-1) 维度 == [ bs*seq_len, vocab_size]== [224*1000,50000]
------> 在下图都是按列切分
------> labels==真值 == 0-1编码 == 1行1个黑块 ---> 将 0-1编码向量按列切分开
step1:词表维度拆分

step2:softmax并行,
最大值同步,全局最大值
all reduce max

step3:求分母, softmax结果
n: device 数目
all reduce max vs sum?

step4:求loss
2. LM head的并行
将1个维度拆分为2个维度
也可以将两个维度相乘,还原为1个维度,也可以理解为维度合并
补充:Stochastic control
embedding,
多卡时,嵌入矩阵拆分,要多个随机种子
dropout, truncatedNormal, StandardNormal, Mltinomial, StandardLaplace, Gmm
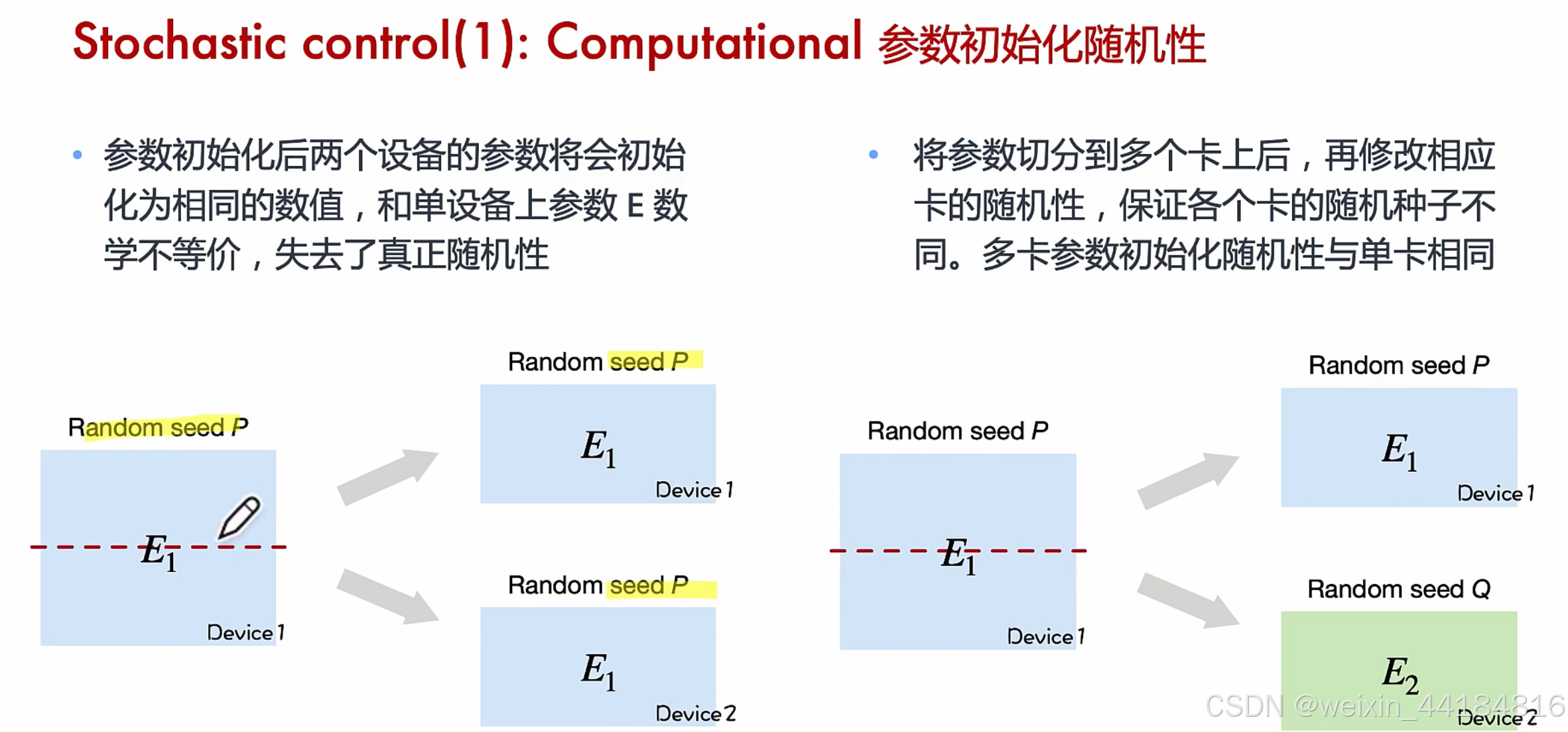
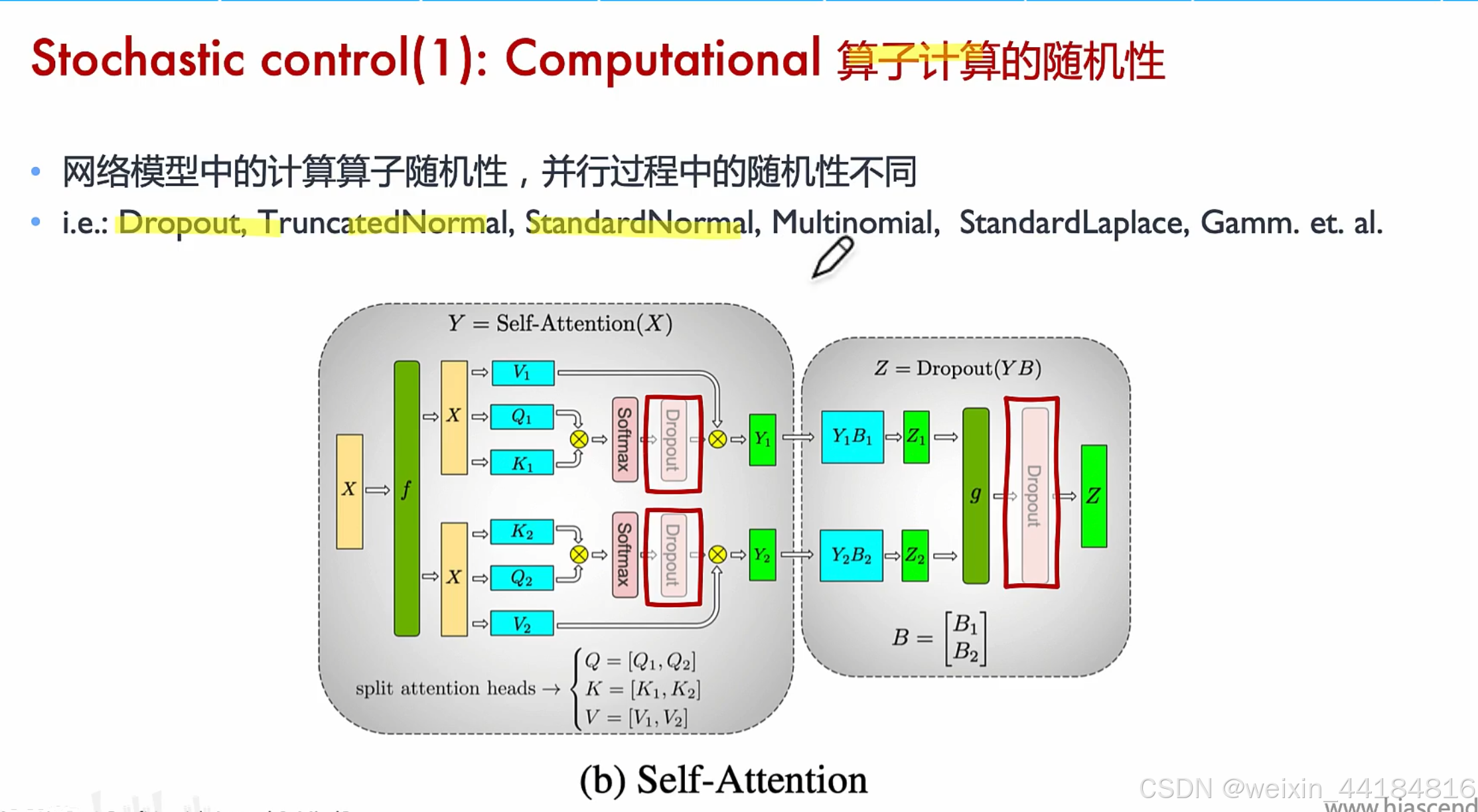
如果将dropout拆分到多卡,需要多个种子,
如果是all reduce的第二个dropout,只需一个种子
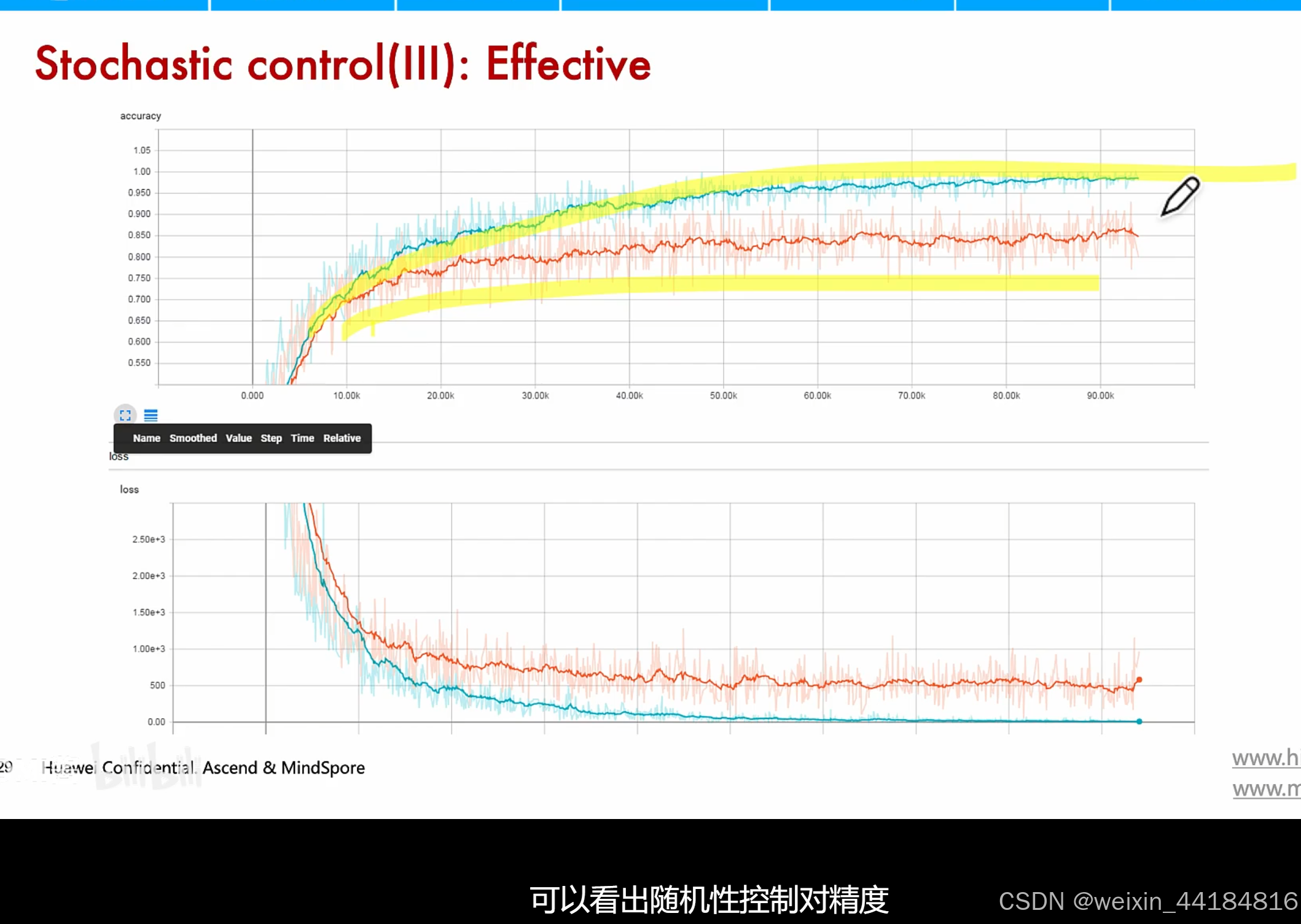
补充:单机内tp,多机间dp


















 6844
6844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









