







文章目录
前言
亲爱的家人们,创作很不容易,若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力,谢谢大家!有问题请私信或联系邮箱:fn_kobe@163.com
近年来,大模型技术成为全球科技领域的热点,从 ChatGPT 到各类新兴AI模型,每一次技术突破都会引发广泛关注。近期,AI 领域的“新宠”无疑是DeepSeek R1。本文将深入探讨其背后的大规模强化学习技术及基本原理,并展望大模型技术的未来发展方向。
1、DeepSeek R1核心技术创新
DeepSeek R1的成功,主要归因于其强化学习方法突破。不同于传统监督学习,DeepSeek R1通过大规模强化学习实现强推理能力,并在多个任务中展现卓越泛化能力。
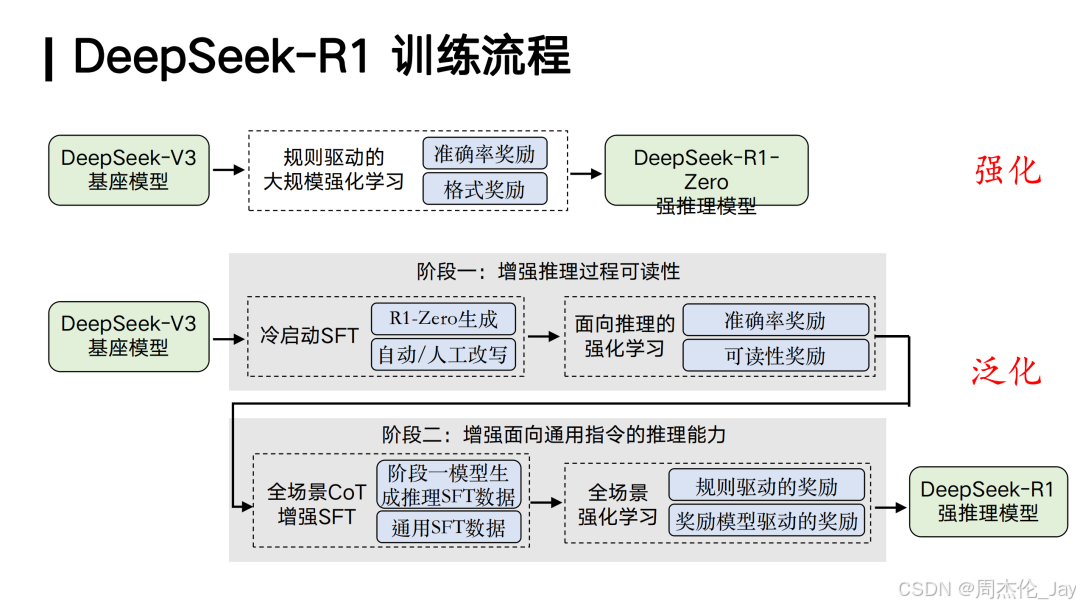
①规则驱动强化学习
DeepSeek R1一个关键贡献是其基于规则(rule-based)方法,确保强化学习在大规模训练中有效扩展(Scaling)。这项技术突破使得 DeepSeek能够以相对有限的算力,复现OpenAI o1级别的推理能力,并通过开源分享技术细节,为行业带来新的可能性。
②强推理能力跨任务泛化
DeepSeek R1采用两阶段训练策略:
第一阶段:在DeepSeek V3基座模型上,生成包含深度推理能力的监督微调(SFT)数据,结合通用SFT数据进行微调。
第二阶段:进一步通过强化学习训练,使模型具备更强泛化能力,在推理任务上表现出色。
这种训练方式使得 DeepSeek R1不仅在数学、代码等领域表现优异,还能泛化到更复杂的推理任务,如写作、逻辑推理等,增强大模型的实际应用价值。
2、DeepSeek R1影响与价值
DeepSeek R1的发布,相当于让全球AI领域迎来又一次“ChatGPT时刻”。其开源和高效能的特性,使全球用户能够低成本体验深度推理能力,这与OpenAI o1的封闭策略形成鲜明对比。
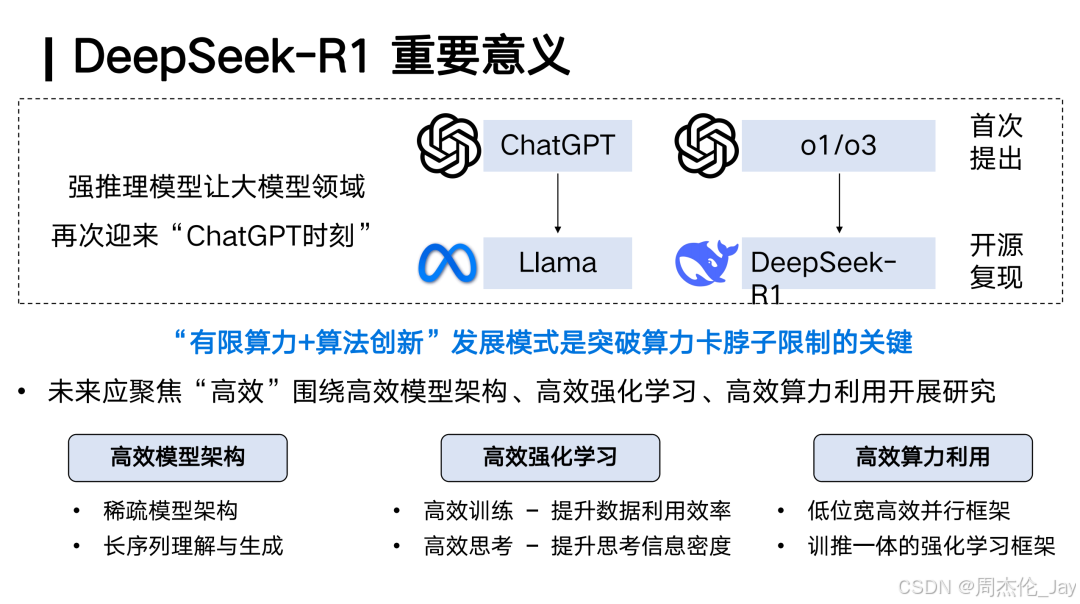
①低成本高效能 DeepSeek R1展示如何在 1/10 或更低的算力成本下,达到GPT-4/GPT-4o级别能力。这一突破不仅降低AI发展技术门槛,还为算力受限研究团队提供新可能性。
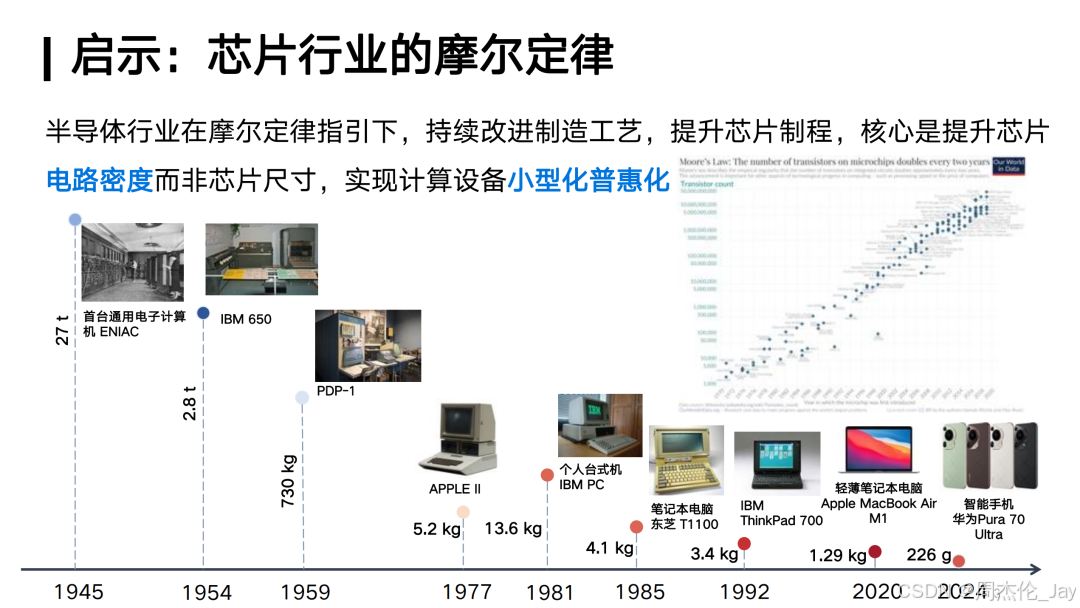
②AI能力密度的提升DeepSeek通过创新算法和软硬件协同优化,使大模型的能力密度(Densing Law)持续提升——即每100天模型能力翻倍,同时所需算力减半。这一趋势类似于芯片行业的摩尔定律,推动AI计算更高效、更普惠。
3、未来AI发展三大趋势
DeepSeek R1的成功为AI领域提供重要启示,未来AI发展可能聚焦在以下三个方向:
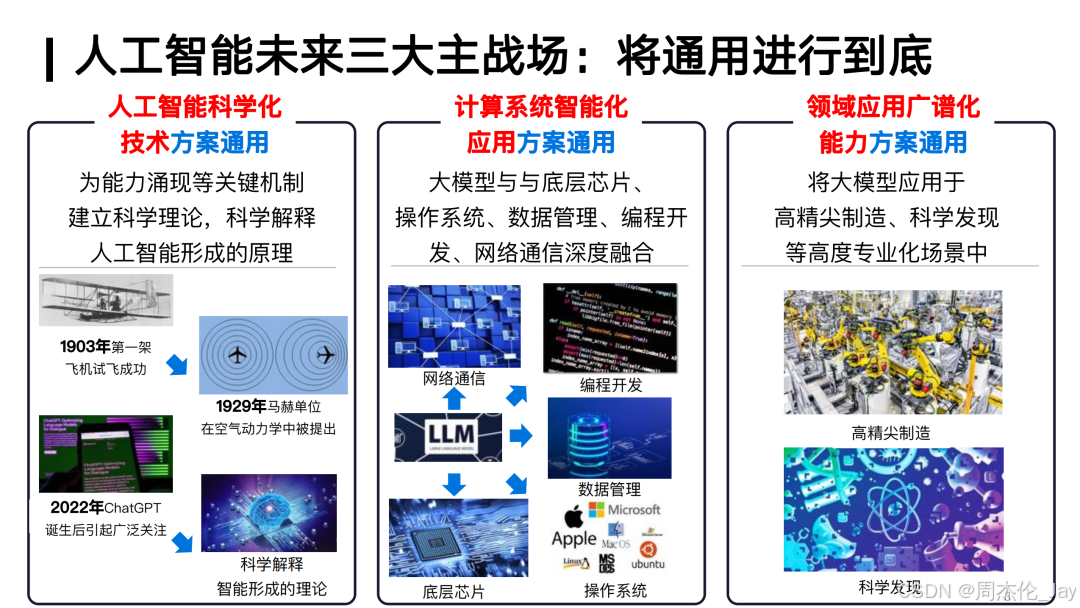
①更高效人工智能架构:未来AI模型需要探索 更节能、高效的架构,例如MoE(Mixture of Experts)等稀疏激活方法,提升算力利用率。
②计算系统的智能化:降低AI计算成本,优化模型推理效率,使大模型在不同场景下都能高效应用。
③AI在多领域的广谱化应用:AI不仅在NLP、计算机视觉等领域取得突破,还将在科学研究、医疗、工程等领域发挥更大作用。
4、问答
4.1、DeepSeek R1技术亮点
DeepSeek R1之所以成功,主要有以下两大技术突破:
高效算力利用:DeepSeek V3通过底层算力优化和软硬件协同,成功在1/10或更低的算力成本下达到GPT-4/GPT-4o级别能力。这种优化机制极大降低训练成本,使得AI研究变得更加可及。
开源策略:相比OpenAI o1的封闭和高定价策略,DeepSeek R1选择完全开源,让全球研究者都能使用并研究其技术,从而在行业内迅速崭露头角。
4.2、为什么DeepSeek R1在此时爆发?
中国 AI 快速追赶:国内团队从ChatGPT复现到GPT-4 级别能力的时间已缩短至半年左右,说明AI发展速度正在加快。
极低成本的突破:DeepSeek R1不仅成功复现OpenAI o1级别的推理能力,还以更低的成本、更高的效率实现这一目标,这是其竞争优势所在。
4.3、“能力密度”概念
DeepSeek 提出的能力密度(Densing Law),类似于芯片行业的摩尔定律:
每100天AI模型的能力翻倍,同时所需算力减半。
影响因素包括 高质量数据、稀疏激活架构、优化的学习方法等。
这一趋势将推动AI计算更高效,使大模型训练和推理成本持续降低。
4.4、MoE(专家混合)架构是否是AGI最优解?
MoE不是唯一解,但稀疏激活和模块化架构是AI未来发展趋势之一。未来AI架构仍需多样化探索,没有绝对最优的解决方案。
4.5、DeepSeek 对中国AI 发展启示
技术理想主义:DeepSeek团队专注于AGI研究,展现极强的长期主义精神。
持续积累与执行力:DeepSeek的成功并非一蹴而就,而是长期积累结果。
国内 AI 需要更多创新团队:政府和企业应支持更多具备长期创新能力的团队,推动AI原始创新和发展。
5、总结
DeepSeek R1通过强化学习突破算力瓶颈,实现高效推理能力跨任务泛化。其开源模式让全球研究者能够共同推动AI发展,类似于当年 Meta发布LLaMA所带来的行业影响。
从能力密度增长到算力优化策略,DeepSeek R1成功证明,中国AI技术正在缩小与国际最先进AI之间的差距。未来,AI领域的竞争将更加注重 高效性,推动AI迈向更广泛、更普惠的发展道路。



















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











