






Marchine leariing
机器学习就是自动找函式

告诉机器要找的函式用
Supervised Learning
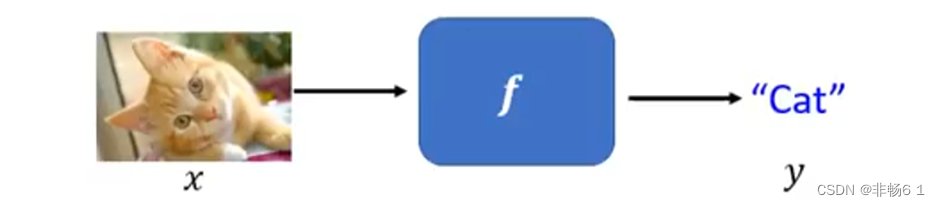
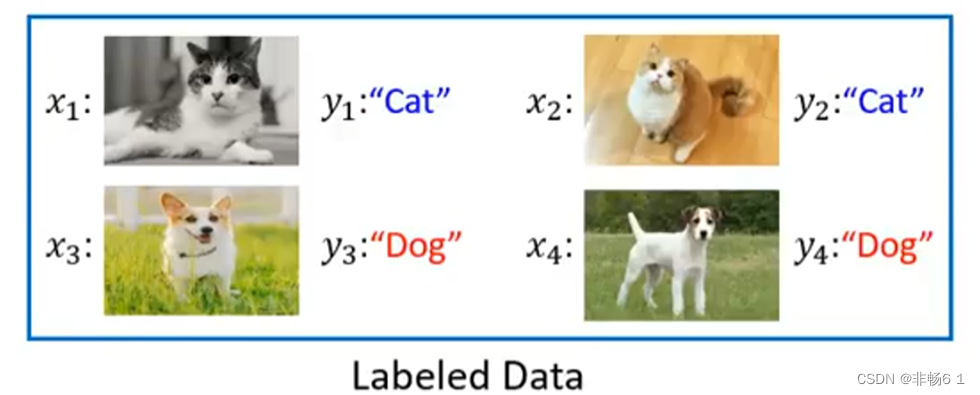
函式的Loss ——评价函式的好坏
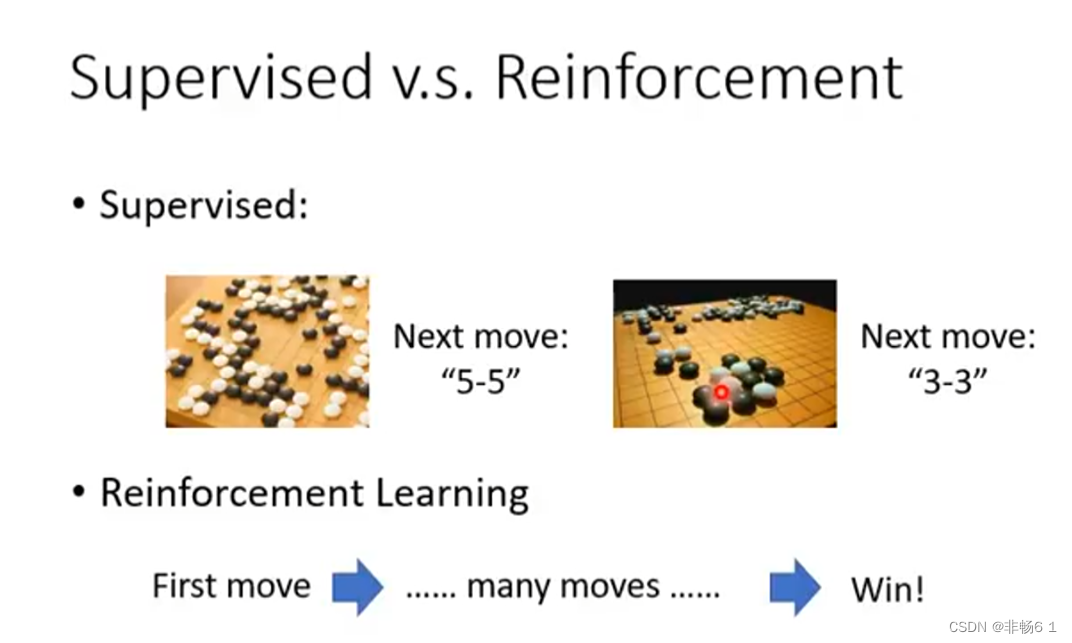
Reinforcement就是让机器自己下象棋,输赢自己尝试,没像监督学习那样有人为规定
给函式寻找范围: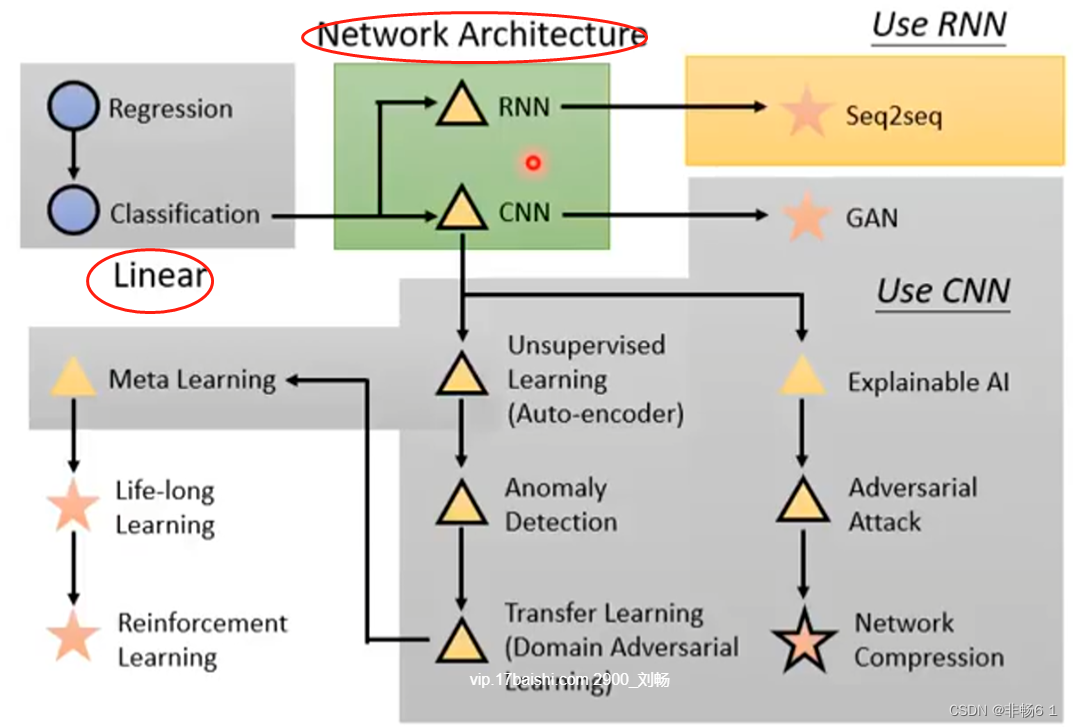
函式寻找方法——Gradient Descent
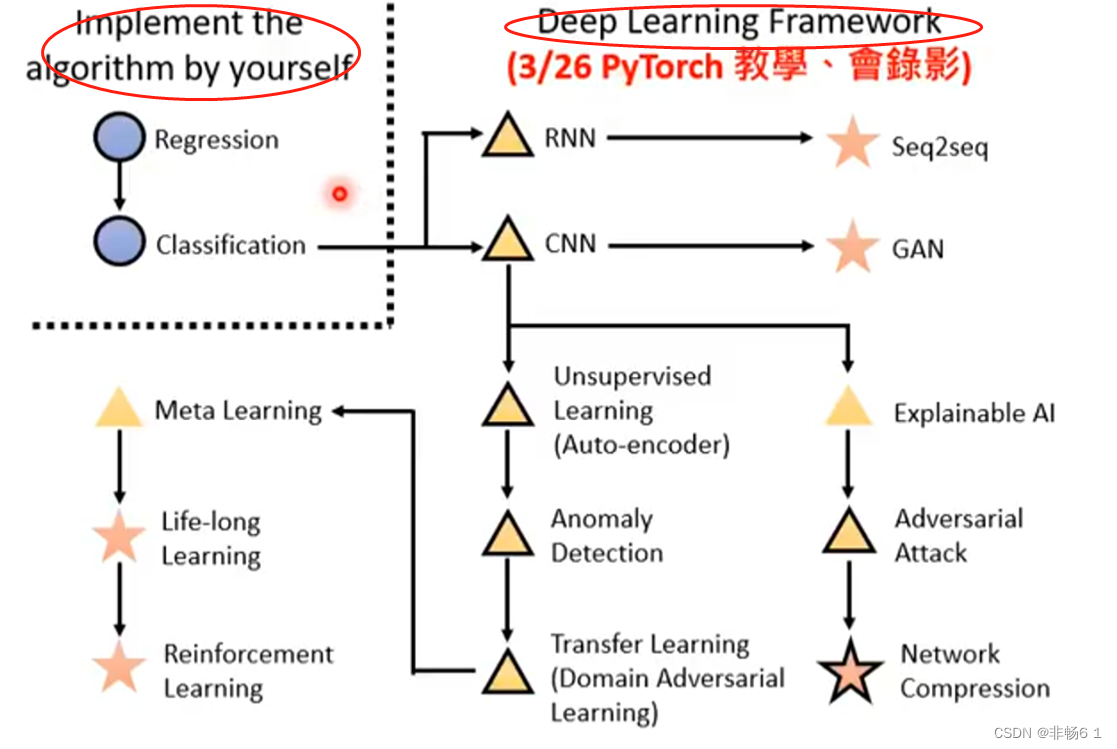 AI前沿研究
AI前沿研究
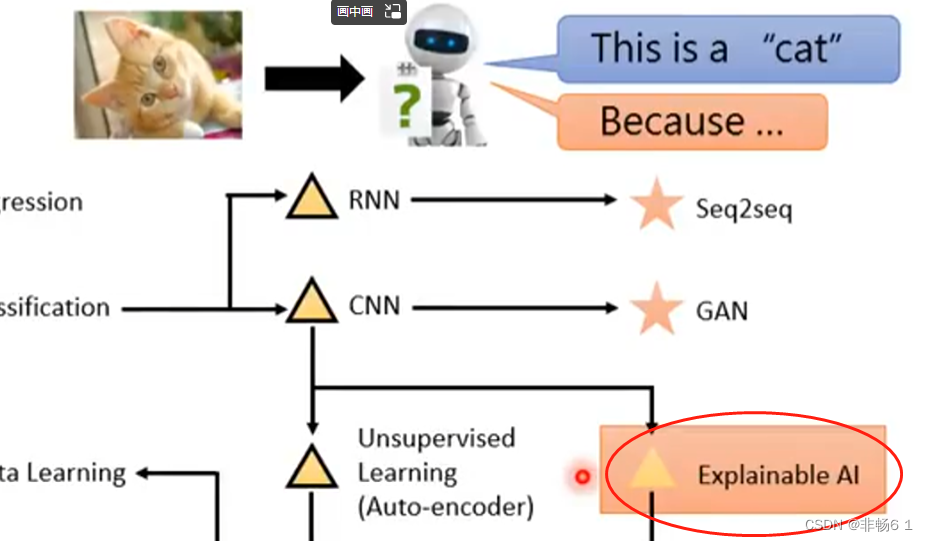
机器会识别图片中的猫,并解释为什么这是一只猫,这就是Explainable AI
人类如果恶意攻击影像辨识系统,会发生什么事,这就是Adversarial Attack
影像辨识系统可能得到很高的正确率,这个正确率来自巨大的马勒,将这个马勒缩小,这就是Network compression
猫狗分类,若放卡通人进去,机器也会将卡通人硬分类成动物,放很怪的东西进去,如何让机器自己知道自己不知道,这就是Anomaly Detection
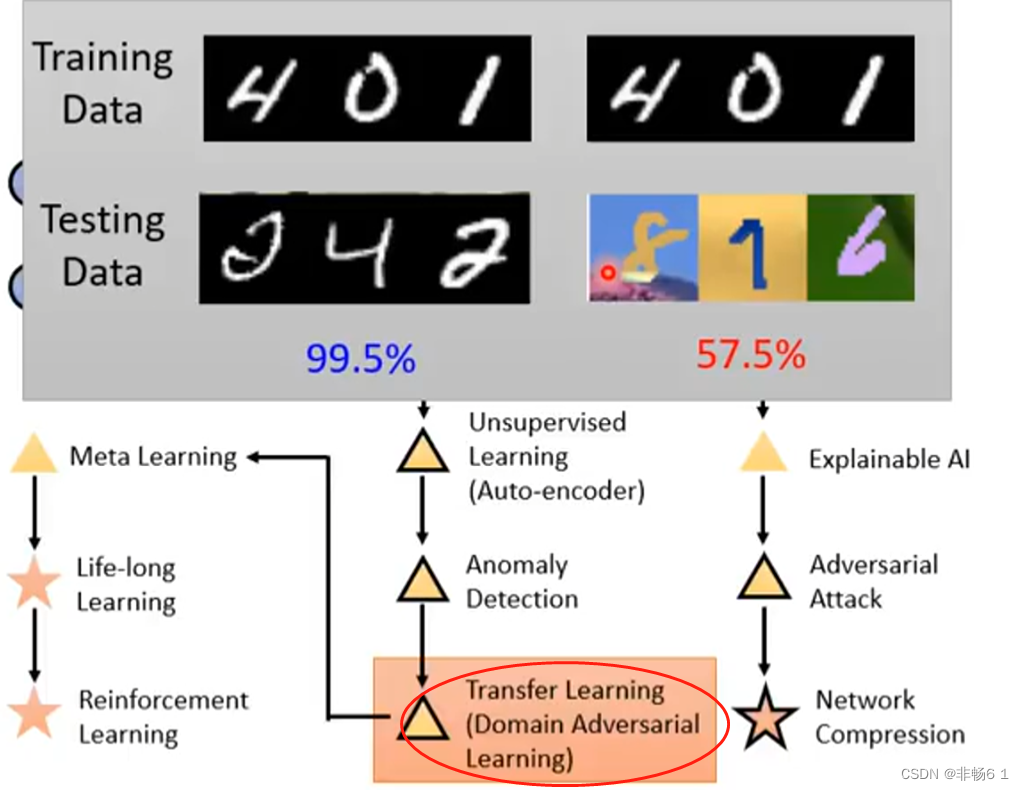
当训练集和测试集不一样时,如何让机器学到东西,这就时Transfer Learning
让机器知道如何学习,目的是比人让机器学习的更有效这就是Meta learining
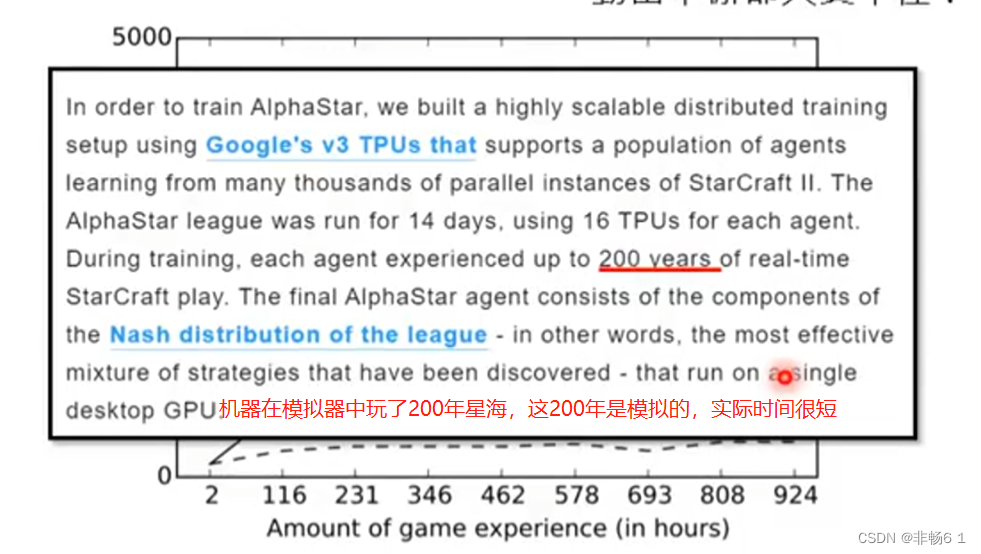
期待机器自己学习,衍生出更有效率的算法
终身学习——life-long learning

机器为什么不能变成天网,难点在哪?
Rule of ML
Regression-case study
能做什么:
Stock Market Forecast
Self-driving car
Recommendation
步骤:


画出Loss- function
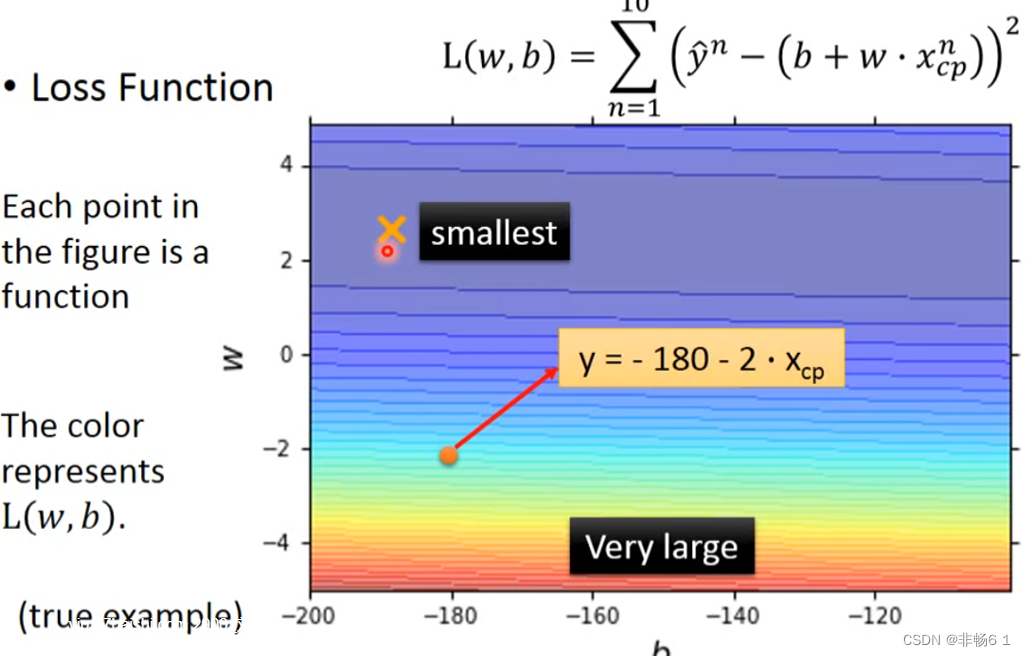

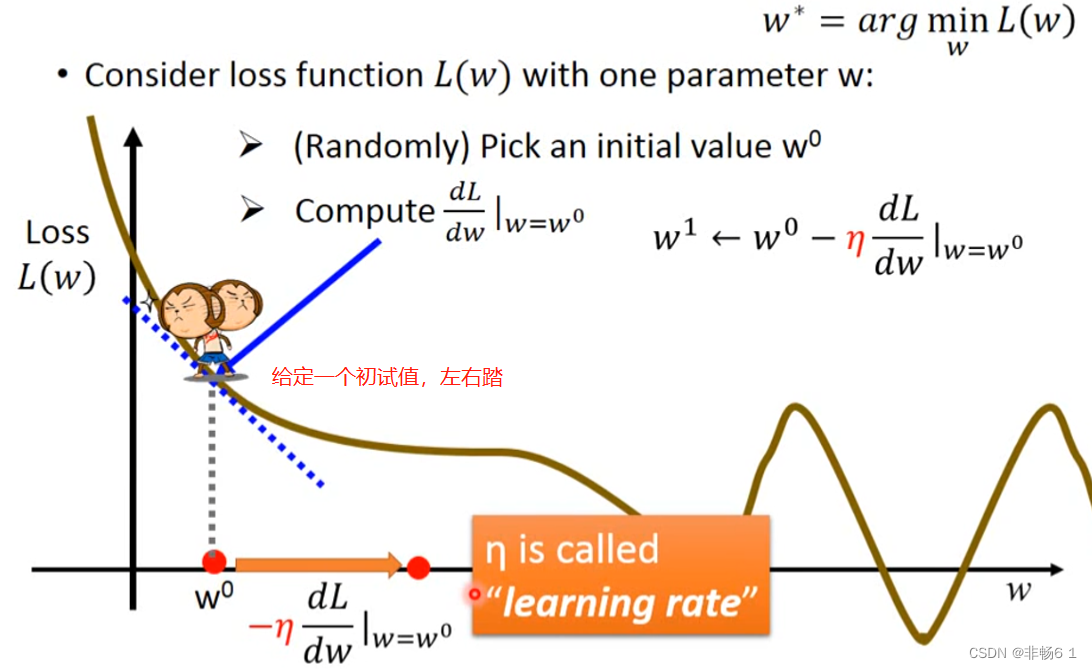
怎么做? 穷举,定值,左右踏

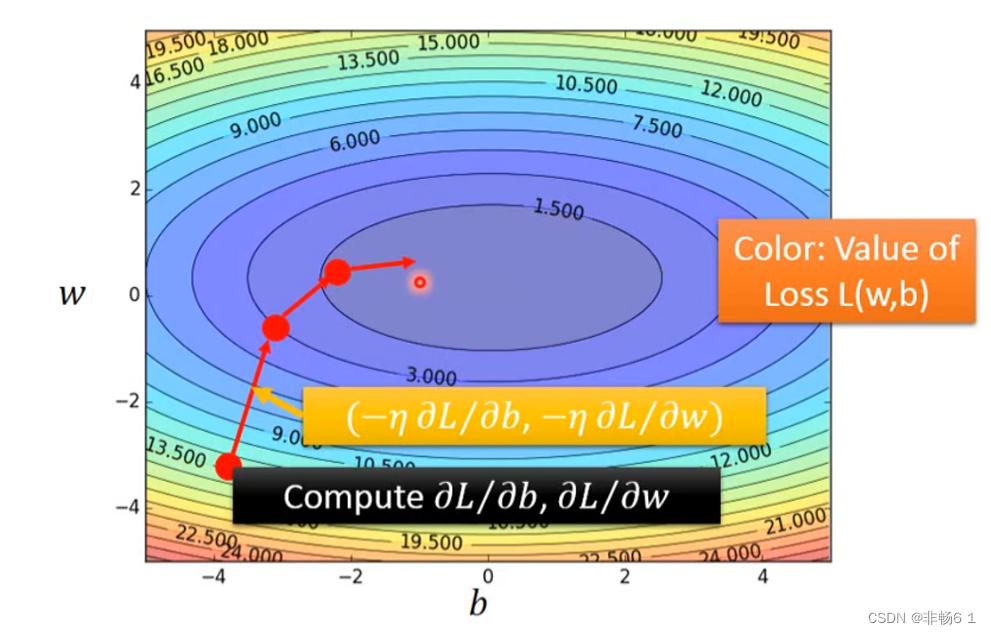
反复进行上面这个步骤,最后就会找到Loss相对小的w和b




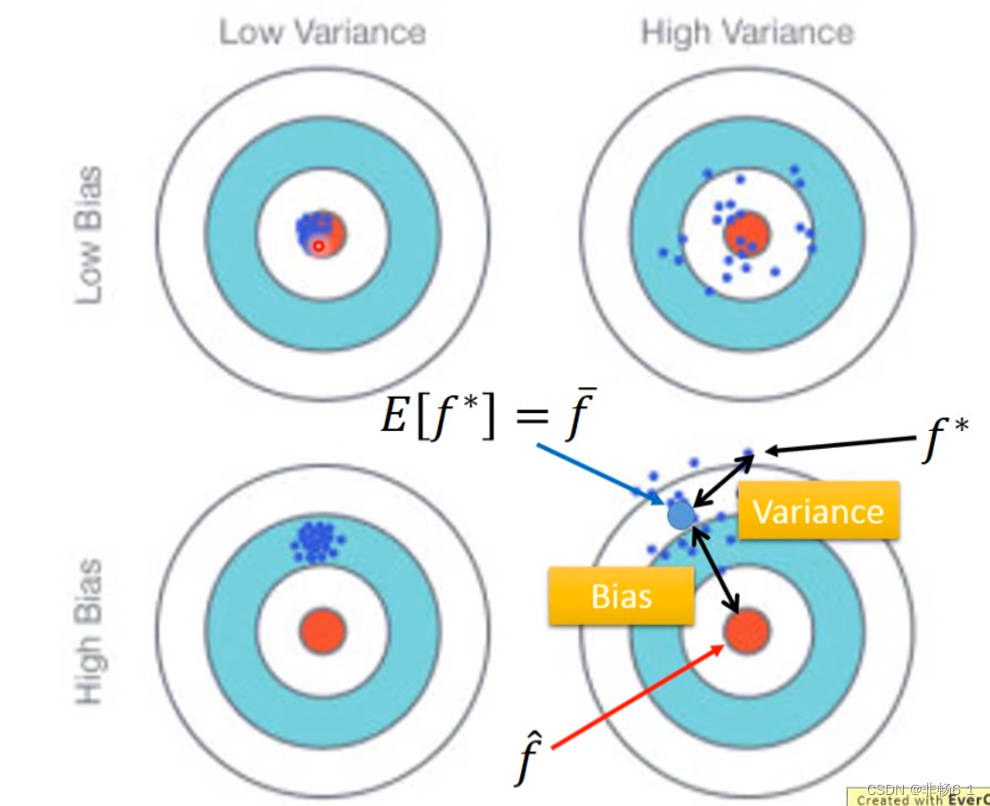
Basic Concep


















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









