






一、引言
在当今数字化时代,人工智能技术的发展日新月异,大模型作为其中的关键突破,正深刻地改变着我们的生活和工作方式。大模型以其强大的语言理解和生成能力,在自然语言处理、图像识别、语音交互等多个领域展现出卓越的性能。从智能聊天机器人到自动化内容创作,从精准的医疗诊断到高效的金融风险评估,大模型的应用无处不在。然而,大模型的发展也带来了一系列新的问题和挑战,如计算资源的巨大消耗、数据隐私与安全问题等。因此,深入了解大模型的技术原理、应用场景和面临的挑战,对于推动人工智能技术的健康发展具有重要意义。
二、大模型是什么?
2.1 大模型定义与发展历程
2.1.1 大模型的定义
大规模预训练语言模型(Large - scale Pre - trained Language Models, LPLMs),简称为大模型,是基于 Transformer 架构的自监督学习系统。它通过对海量无标注文本数据的学习,获得通用的语义表征能力,其本质是在超大规模的参数空间中对自然语言的概率分布进行建模,从而实现对开放域任务的泛化性迁移。通过在大规模的数据集上训练,大模型能够捕捉到自然语言中的复杂语义关系和上下文信息,从而实现对语言的更准确理解和更自然的生成。
2.1.2 大模型发展历程
大模型的发展经历了多个阶段。早期的自然语言处理模型受限于计算资源和数据规模,表现出的能力相对有限。随着深度学习技术的兴起,尤其是 2017 年 Transformer 架构的提出,为大模型的发展奠定了基础。Transformer 架构通过自注意力机制,能够更好地处理长序列数据,极大地提升了模型的性能。随后,一系列具有代表性的大模型相继涌现。例如,OpenAI 的 GPT 系列,从最初的 GPT 到 GPT - 2、GPT - 3 以及 GPT - 4,参数规模不断扩大,性能也不断提升。
2.2 大模型的技术原理
2.2.1 基于 Transformer 的序列建模
大模型采用 Transformer 架构,其中核心为多头自注意力机制。多头自注意力机制允许模型在处理输入序列时,同时关注不同位置的信息,从而构建深度堆叠网络,与传统的循环神经网络(RNN)相比,它突破了序列长度的限制,能够更有效地处理长文本。大模型在处理一篇长篇新闻报道时,可以更好地捕捉句子之间、段落之间的语义关联。在Transformer 架构中,另一重要组成部分为位置编码技术。位置编码通过为每个词元赋予特定的编码,使得模型能够感知词元在序列中的位置,从而准确理解文本的顺序和语义。
2.2.2 参数规模定律
模型的性能与参数量、数据量和计算量呈现幂律关系。随着参数量、数据量和计算量的不断增加,模型的性能也会显著提升。这一规律驱动着模型规模从最初的亿级参数向如今的万亿级参数扩展。
2.2.3 预训练与微调
大模型的训练通常分为预训练和微调两个阶段。在预训练阶段,模型在大规模的无标注数据上进行训练,通过设计合适的预训练任务,让模型学习到通用的语言知识和模式。在微调阶段,模型在特定的有标注数据集上进行训练,以适应具体的下游任务。例如,在情感分析任务中,将带有情感标签的文本数据用于微调大模型,使其能够准确判断文本的情感倾向。通过预训练和微调的结合,大模型能够在不同的任务上取得较好的性能。
三、大模型的应用领域
3.1 自然语言处理领域
3.1.1 对话
大模型被广泛应用于智能客服、聊天机器人等对话系统中。能够理解用户的问题,并以自然流畅的语言进行回答。大模型在对话与文本生成领域的突破,正在重构人机交互与内容生产的范式。未来,随着技术持续迭代,对话系统将向情感智能、自主决策方向演进,而文本生成则会深入垂直领域,实现从 “工具” 到 “生产力” 的价值跃迁。
3.1.2 文本生成
包括新闻写作、故事创作、诗歌生成等。大模型可以根据给定的主题和要求,生成高质量的文本内容。通过语义嵌入技术分析 200 万篇文献,自动生成实验方法描述与结果分析;结合领域知识图谱,自动生成符合 USPTO 标准的专利权利要求书。DeepSeek 通过领域知识深度融合与生成技术持续创新,正在重塑文本生产范式。从科研创新到商业应用,其生成能力已触及知识工作的核心环节。未来随着生成质量与效率的持续提升,将催生更多依赖文本智能的新兴产业形态。
3.2 医疗健康领域
DeepSeek-Medic 通过对比学习优化医学影像分析,在 CT 扫描中肺结节检测准确率达 94.7%,漏检率降低 65%。基于患者基因序列与电子病历,生成靶向用药方案,某三甲医院试点使化疗副作用发生率下降 32%。对于健康方面,结合可穿戴设备数据,实时监测慢性病患者指标,预警准确率达 92%,急诊就诊率减少 40%。在医疗诊断、病历分析、药物研发等方面发挥着重要作用。大模型可以分析大量的医疗数据,如病历、影像资料等,帮助医生进行疾病的诊断和预测。
3.3 AI+
AI+法律:通过自然语言处理(NLP)技术,快速解析法律文本(如案例、法规、合同),辅助律师或法官精准定位关键信息;基于预训练模型,AI 可生成合同、起诉状等标准化文书模板,并根据案件细节自动填充内容。
AI+金融:用于风险评估、投资决策、客户服务等。大模型可以分析金融市场数据、企业财务报表等信息,为投资者提供决策建议。
AI+教育:可以实现个性化学习、智能辅导等功能。根据学生的学习情况和特点,为学生提供个性化的学习计划和辅导。
AI+交通:智能交通、实施路况预测、基于大模型的自动驾驶,推动智能汽车发展。
四、为什么是deepseek
4.1 从量化基因到 AI 革命:DeepSeek 的进化密码
在人工智能技术革命的浪潮中,中国企业 DeepSeek(深度求索)以其突破性的技术表现和全球化布局,成为 2025 年最受瞩目的科技新星。自成立以来,DeepSeek 通过 “低成本 + 高性能 + 开源” 的创新模式,不仅重塑了全球 AI 产业格局,更推动了中国在技术认知、地缘战略和产业协同等多维度的跳跃式发展。DeepSeek 的进化史,本质是量化思维在 AI 领域的成功迁移。其通过数据敏感性、算法效率和数学建模能力的重构,不仅实现了技术突破,更揭示了一条 “低成本、高性能、可解释” 的 AI 发展路径。未来,随着量化思维与 AI 技术的深度融合,DeepSeek 有望成为连接金融智慧与人工智能的 “数字桥梁”,为全球科技革命注入新的方法论启示。
4.2 技术突破,实现“弯道超车”
DeepSeek 的核心竞争力源于其对算法、算力和数据的系统性优化。公司成立于 2023 年,由量化资管巨头幻方量化孵化,早期便聚焦于大模型的轻量化与高效化研发。2024 年,其第二代 MoE 模型 DeepSeek-V2 以仅 GPT-4 百分之一的成本实现性能对标,标志着中国在大模型领域首次实现对西方的 “弯道超车”。
2025 年,DeepSeek-R1 模型的发布成为关键转折点。该模型采用 6710 亿参数架构,通过动态子网激活技术降低硬件依赖,在数学推理、代码生成等任务中性能超越 OpenAI 的 O1 模型,且训练成本仅为 560 万美元,不到国际同类模型的十分之一。deepseek R1 基于 V3 架构,结合监督微调与强化学习,实现 “纯 RL 训练” 的技术突破;支持文本、图像、语音的多维度输入,在金融、医疗等垂直场景中展现出强泛化能力;完成海光 DCU、华为昇腾等国产芯片的全栈兼容,推动算力自主可控。
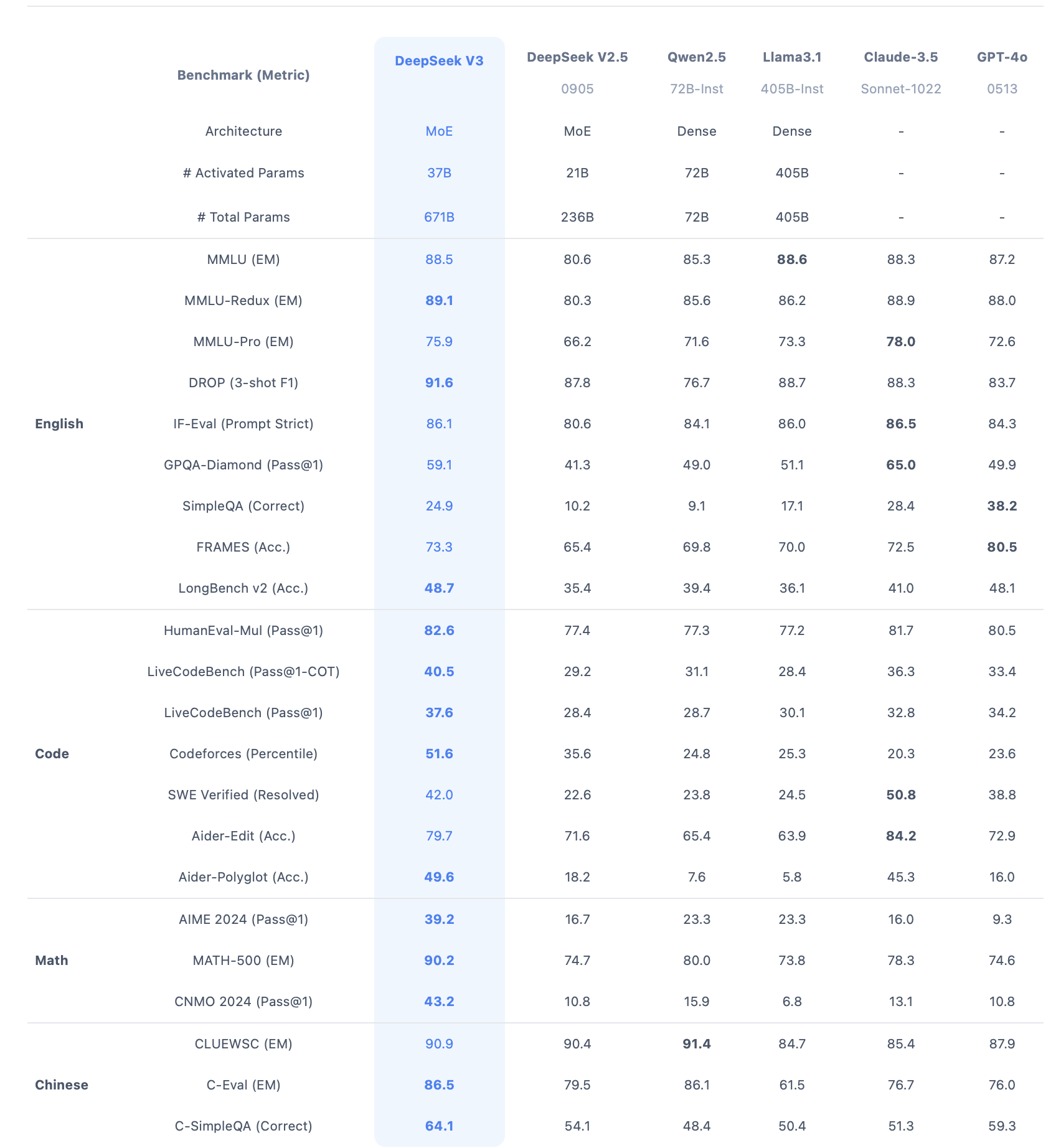
图1 deepseek与各大模型性能对比
4.3 解锁 DeepSeek:各领域应用的无限可能
DeepSeek 的技术优势迅速转化为场景落地能力,其应用版图覆盖政务、教育、工业、交通等多个领域:
- 政务智能化:深圳、广州等城市率先在政务云部署 DeepSeek-R1,实现智能导诉、政策解读等服务的自动化,案件处理效率提升 40%;
- 教育创新:中国人民大学、华东师范大学等高校接入 “满血版” 模型,辅助科研计算、代码修正,数学系学生借助其 “思维链” 技术实现数学证明的快速推导;
- 工业协同:吉利、比亚迪等车企将 DeepSeek 融入车载系统,解决模糊意图理解与主动服务难题,推动智能座舱的体验升级;
- 通信领域:亚信科技与清华 AIR 联合评测显示,DeepSeek 在网络故障监控、配置生成等场景中表现优异,助力自智网络向 L4 + 演进。
4.4 从技术突围到生态领航:DeepSeek 的全球进击
DeepSeek 的崛起不仅是中国 AI 技术突破的缩影,更是全球科技权力重构的象征。其以效率革命打破西方技术垄断,以开源共享推动普惠发展,以场景创新重塑产业边界。在可预见的未来,DeepSeek 将继续扮演 “技术颠覆者” 与 “生态构建者” 的双重角色,为中国在全球 AI 竞争中赢得主动权,也为人类智能文明的共同进步贡献中国方案。
五、如何使用deepseek?
5.1 通过网页使用
使用浏览器打开:DeepSeek
点击 “开始对话”

5.2 通过手机APP使用
1. 安卓手机:在手机的应用商店搜索 deepseek,点击下载,或打开DeepSeek后,点击“获取手机APP”

2.苹果手机:打开App Store,搜索 deepseek或从浏览器下载(参考上方安卓手机下载方式)
5.3 本地部署
本地部署方式有很多种,这里我们主要使用ollama,并会介绍多种界面工具。
5.3.1 ollama介绍
ollama是专注于简化大语言模型部署和使用的开源框架,采用 Go 语言编写,旨在为开发者提供高效、灵活的工具来构建和运行基于 LLM 的应用程序,也让普通用户能快速、简单地在自己电脑上下载、管理、运行大语言模型。
5.3.2 ollama安装
5.3.2.1 下载ollama
打开ollama官网:https://ollama.com
点击Download
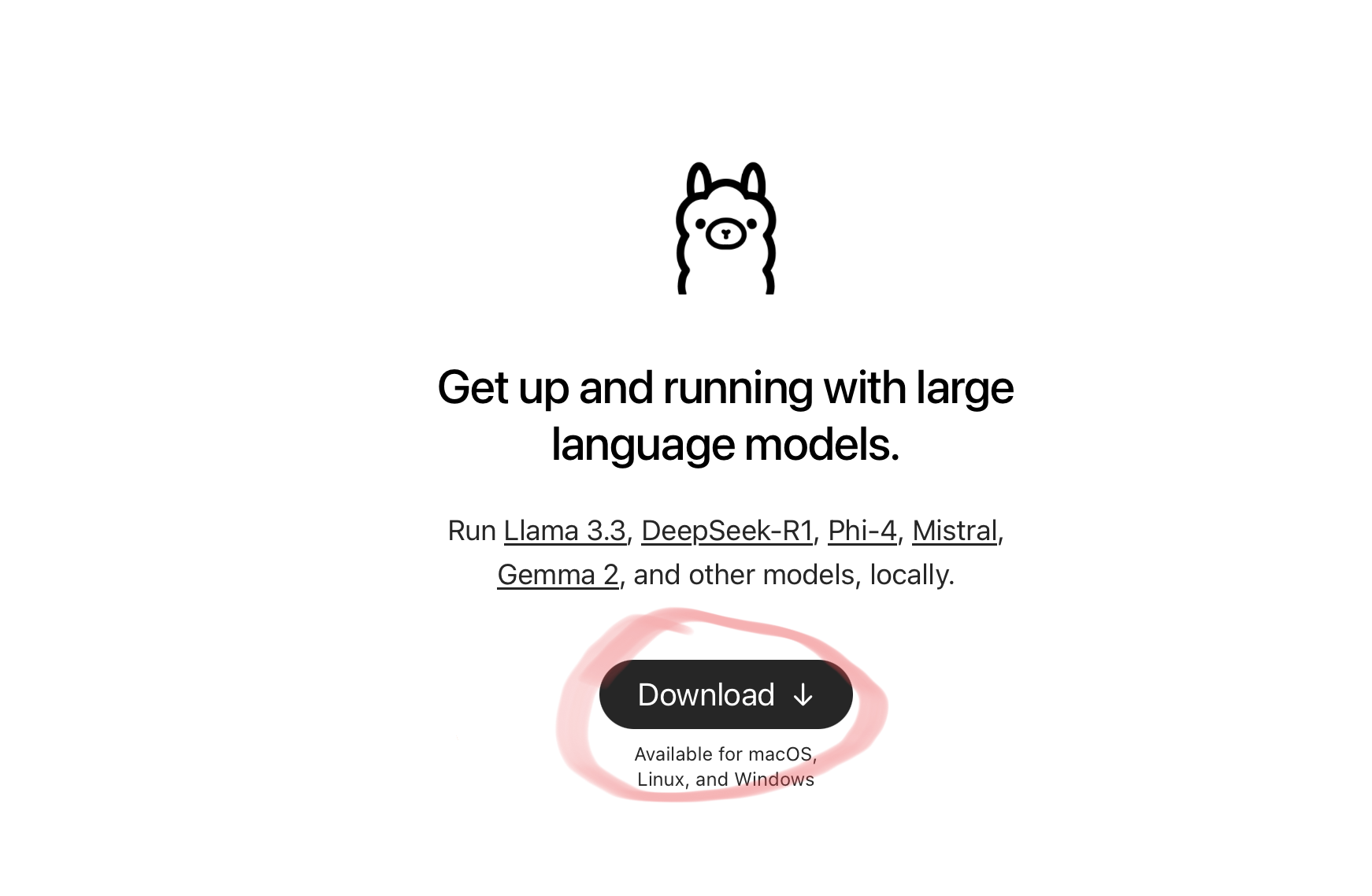
选择自己需要的版本(红色圈内),点击下载(蓝色圈内)。下载速度较慢
5.3.2.2 安装ollama
点击Install,等待下载安装即可。
5.3.3 本地部署deepseek-r1蒸馏模型
8G显存推荐8b(80亿参数)及以下,16G显存推荐14b(140亿参数)模型及以下。要选择合适的模型,一味追求更多参数反而会丢失体验(生成时间较长)
5.3.3.1 蒸馏模型
模型蒸馏是一种模型压缩和优化技术,其核心思想是将一个复杂的大模型(教师模型)的知识传递给一个较小的模型(学生模型)。在这个过程中,学生模型学习模仿教师模型的行为,从而在保持一定性能的前提下,实现模型的轻量化和加速。例如,在图像识别任务中,教师模型可能具有非常深的网络结构和大量的参数,能够准确地识别各种图像。通过模型蒸馏,学生模型可以学习到教师模型对图像特征的提取和分类方式,在减少参数和计算量的同时,依然能够达到较好的图像识别准确率。
5.3.3.2 选择模型
打开网页:deepseek-r1
除671b模型,其余均为基于Llama和Qwen的DeepSeek-R1中提炼的密集模型。
选择模型(红色圈内),复制命令行代码(蓝色圈内的绿色圈可以直接复制)
以部署1.5b(15亿参数)模型为例:

5.3.3.3 部署模型(Windows)
首先打开Windows PowerShell。下载的同时要保持ollama在后台运行。
步骤:点击开始,输入powershell,点击(蓝色圈内)
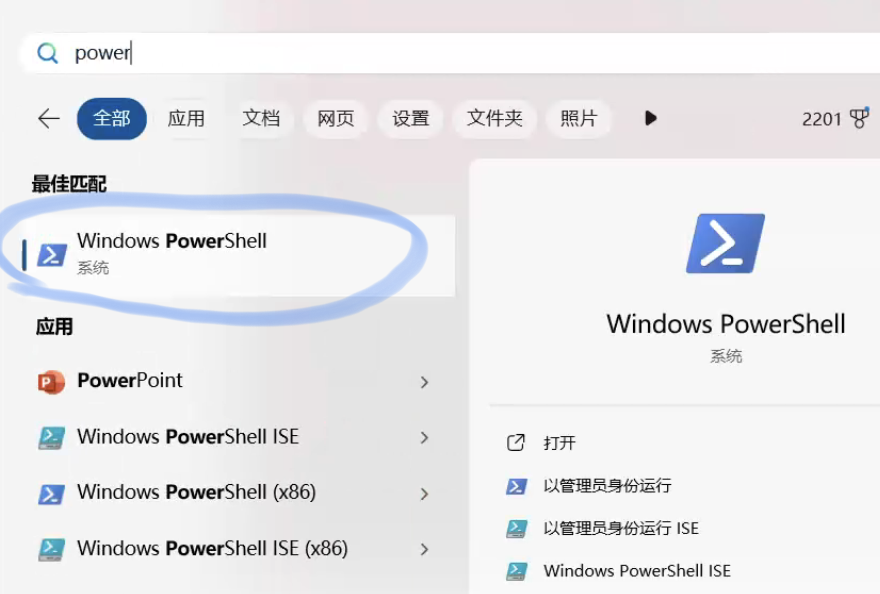
输入刚刚在5.3.3.2复制的代码
ollama run deepseek-r1:1.5b其中,1.5b就是刚刚选择的蒸馏模型(15亿参数)。点击回车,等待下载。
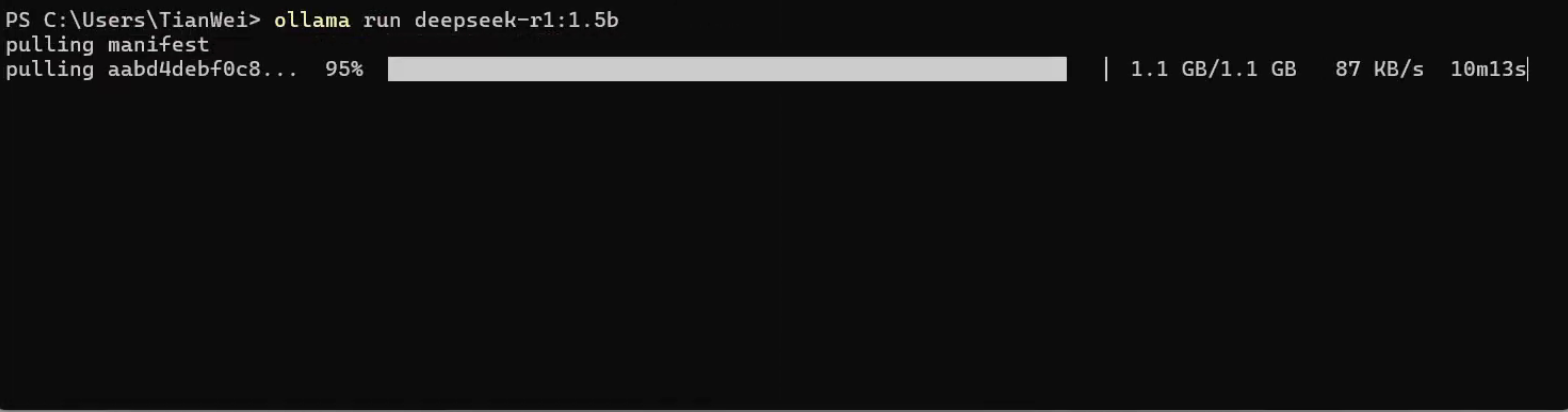
下载完成后,可以直接通过命令行使用模型
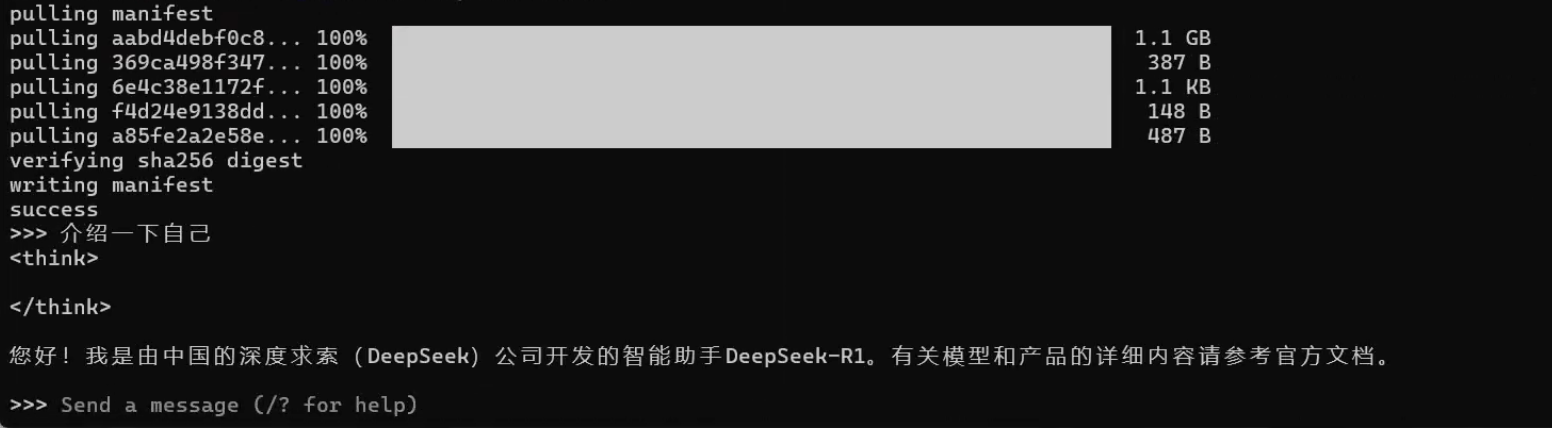
若关闭了powershell,可以在powershell中输入以下命令,即可继续通过命令行的方式使用deepseek
ollama run deepseek-r1:1.5b 5.3.3.4 部署模型(MacOS)
5.3.3.4 部署模型(MacOS)
点击“终端”

输入刚刚在5.3.3.2复制的代码
ollama run deepseek-r1:1.5b
点击回车,等待下载。
下载完成后,即可通过终端使用deepseek
5.3.3.5 查看已部署的模型
在PowerShell中运行以下代码
ollama list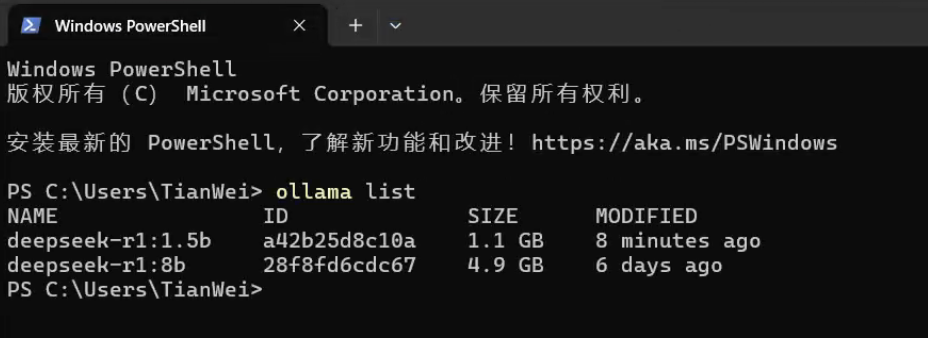
5.3.3.6 卸载已部署的模型(非部署步骤)
在PowerShell中运行以下代码,即可卸载不需要的模型
ollama rm deepseek-r1:1.5b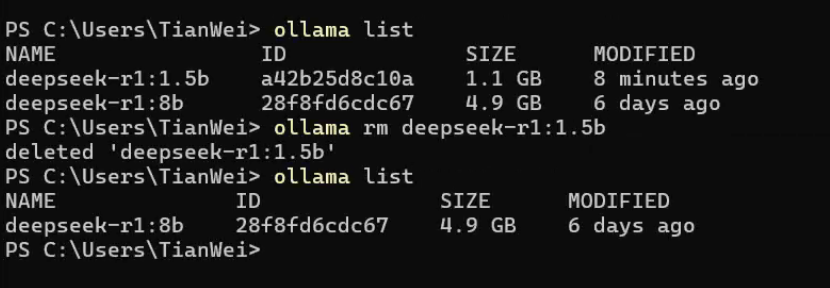
5.3.4 通过chatbox使用deepseek-R1:1.5b
5.3.4.1 介绍
Chatbox 是一款用户友好的 AI 聊天工具,可作为桌面客户端应用程序,也有网页版,还支持 iOS 和 Android 移动端应用。项目包含社区版(开源,GPLv3 许可证)和官方版(闭源,免费)
5.3.4.2 下载chatbox
打开chatbox官网Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
1. 点击红色圈内的“免费下载”开始下载
2. 打开下载的安装包,点击下一步
3.选择安装位置,即可开始安装。
4.打开刚刚安装好的ChatBox,此时会弹出一个对话框,点击红色圈内的 Use My Own API Key / Local Model
5.选择Ollama API
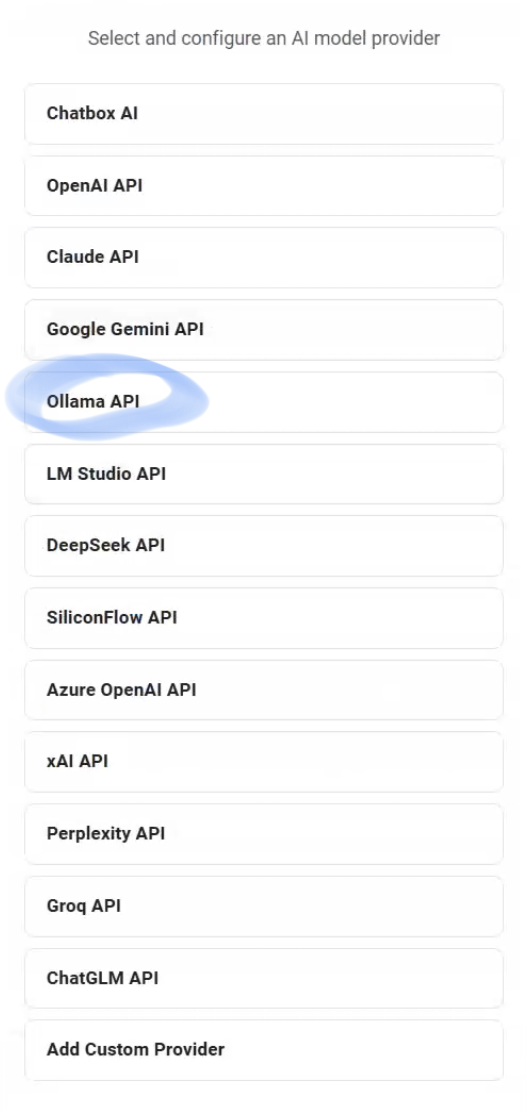
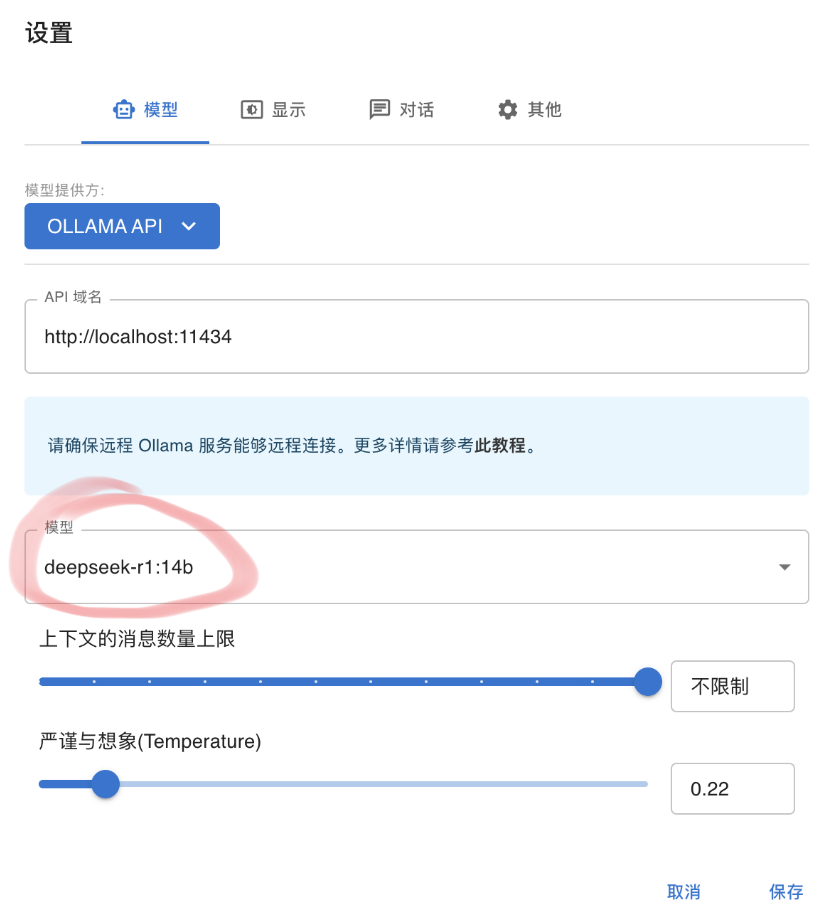
6.选择模型(红色圈),点击保存。
7.使用模型(红色圈内输入问题)和切换模型(蓝色圈内)

5.3.4.3 通过局域网跨设备使用本地部署模型
1. 在windows上(已本地部署的设备)配置环境变量
右键单击“此电脑”,点击属性
点击“高级系统设置”
点击“环境变量”
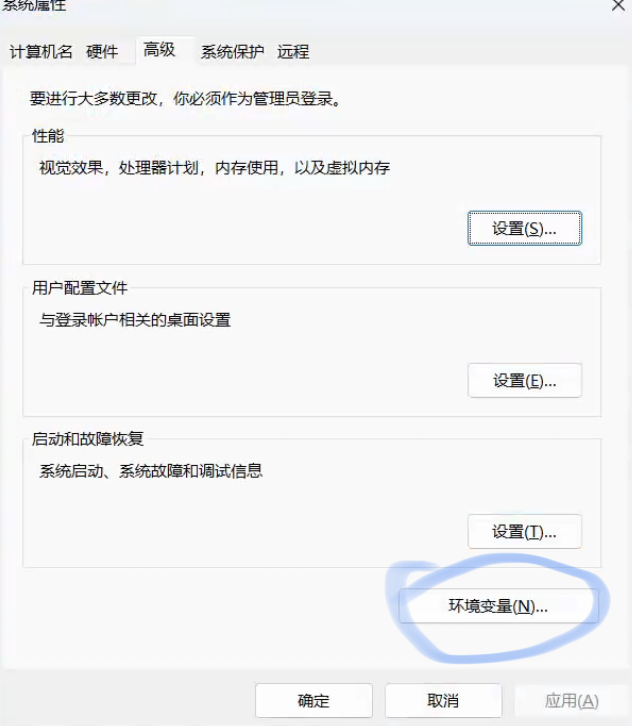
点击新建
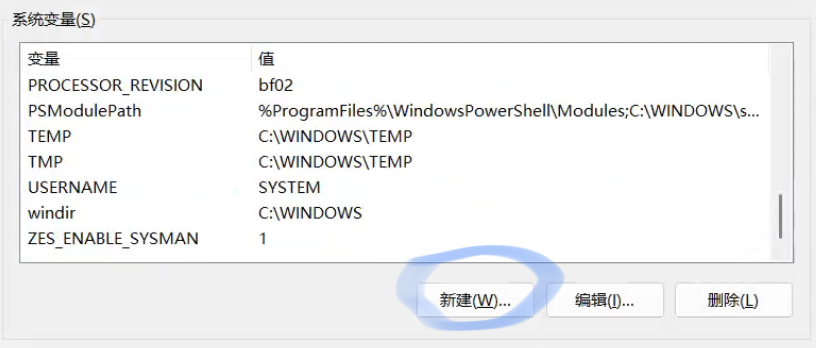
输入以下内容:
变量 OLLAMA_HOST,值:0.0.0.0
变量 OLLAMA_ORIGINS,值: *2. 在MacOS上配置环境变量(重启电脑后该配置会失效)(已在MacOS上部署)
打开终端,输入:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"点击回车,然后重启ollama。
3.在未部署的设备上使用已部署的设备上的模型
打开chatbox,点击设置(蓝色圈内)
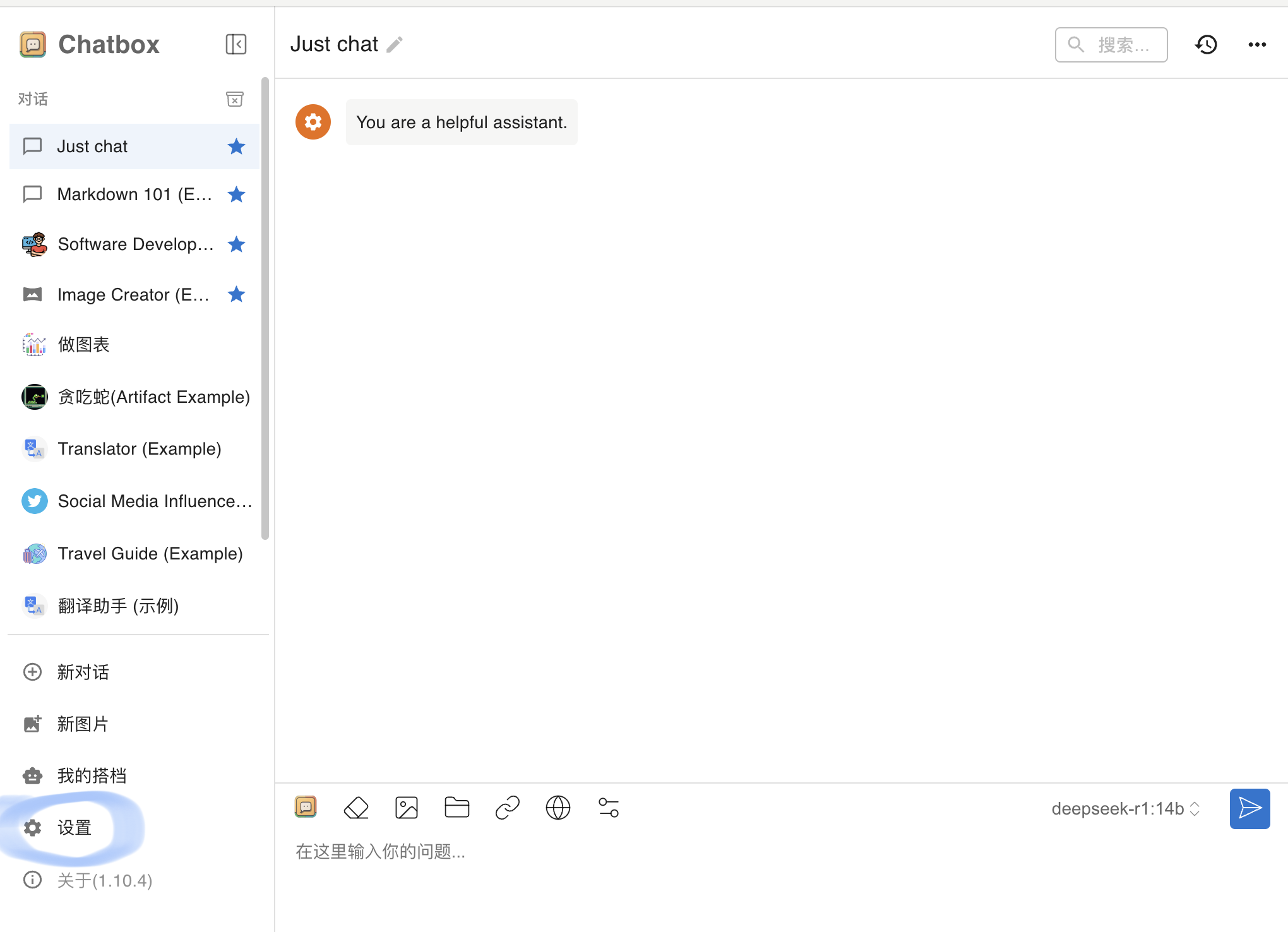
4.将蓝色圈内的IP地址更换为已部署了大模型的设备的局域网IP地址
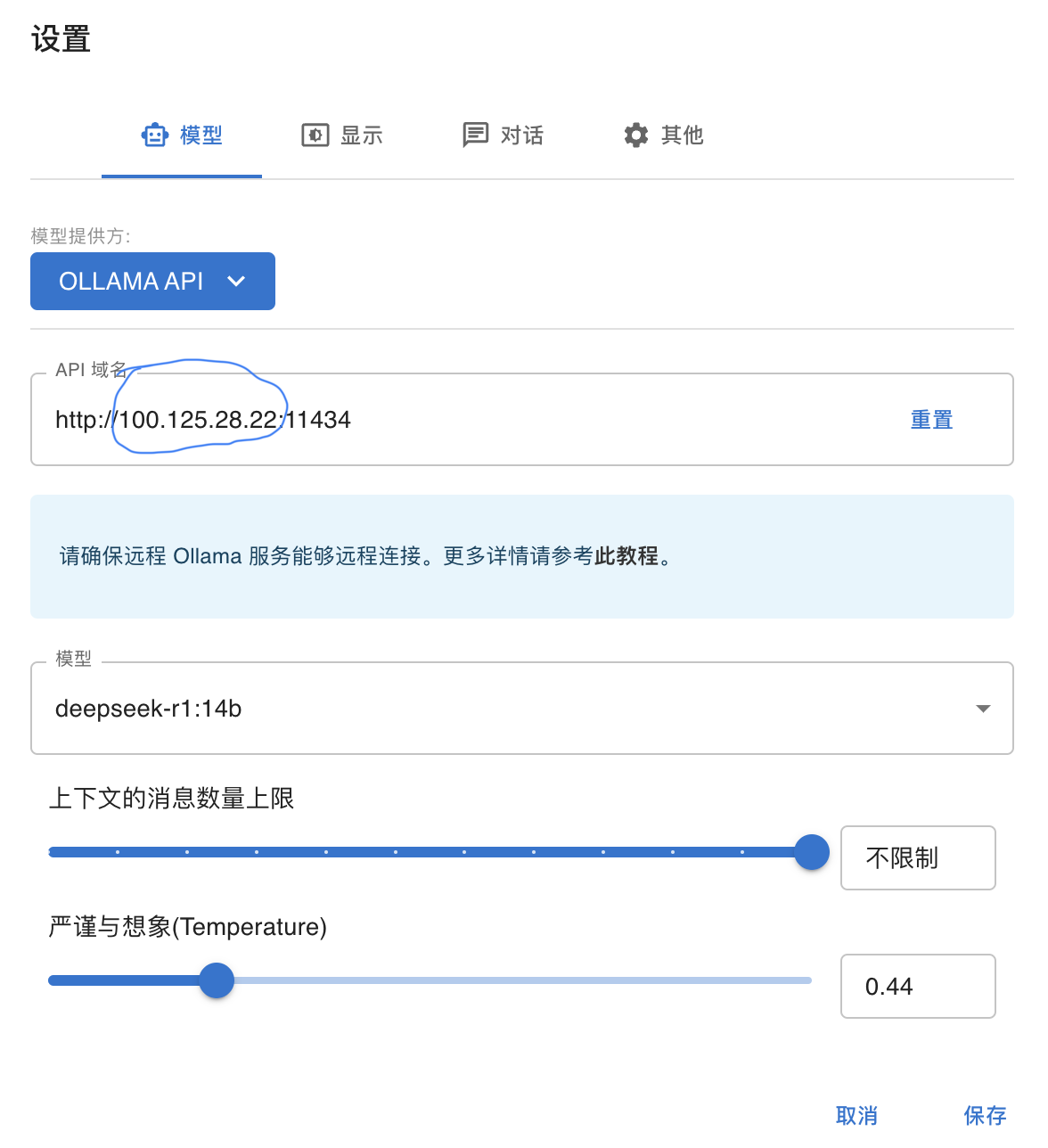
5.更换模型(蓝色圈内)
5.3.5 通过Cherry Studio使用模型并投喂知识库
1. 打开网页Cherry Studio 官方网站 - 全能的AI助手
点击下载客户端
安装过程省略。
2. 打开Cherry Studio
点击设置
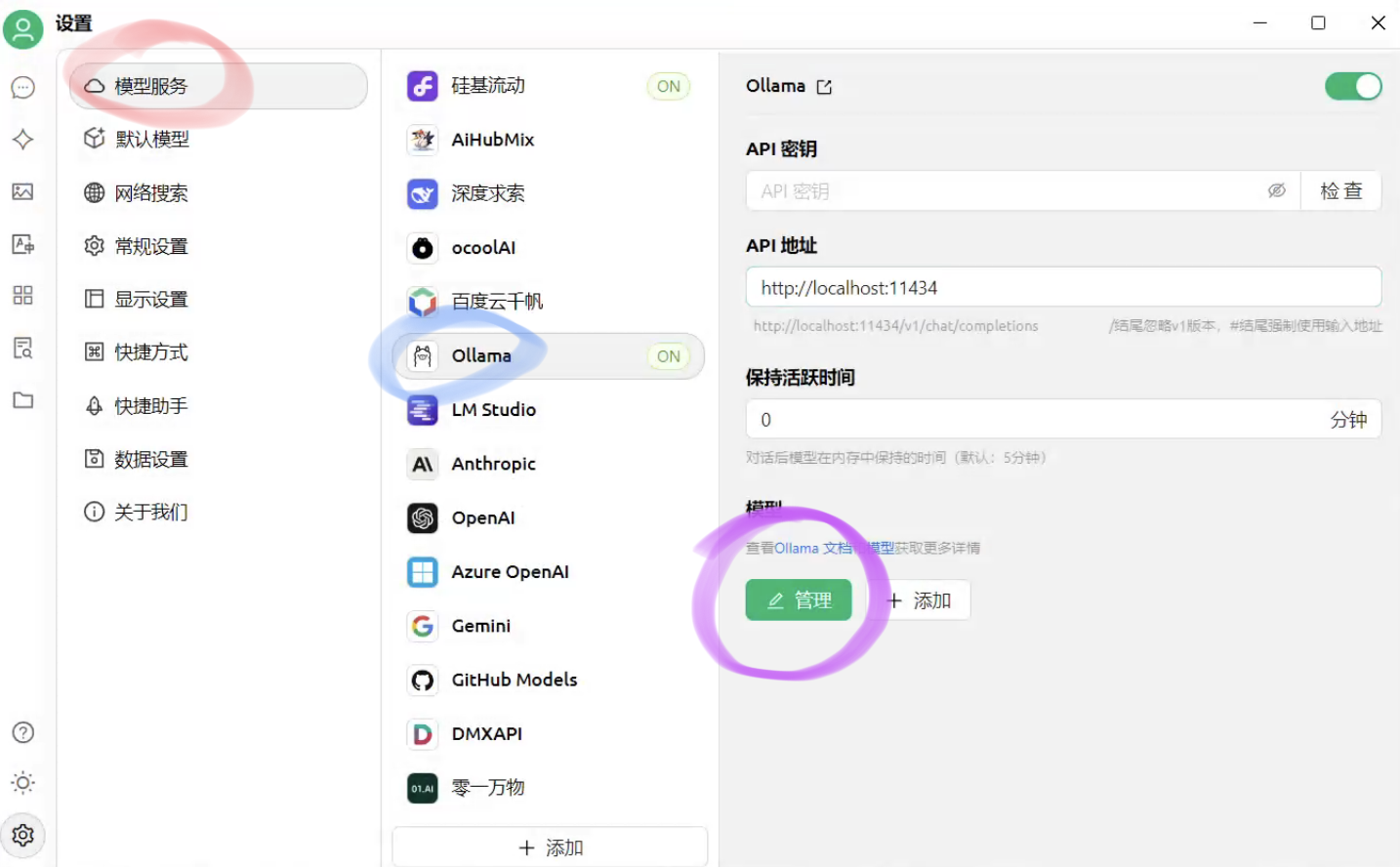
3.添加模型
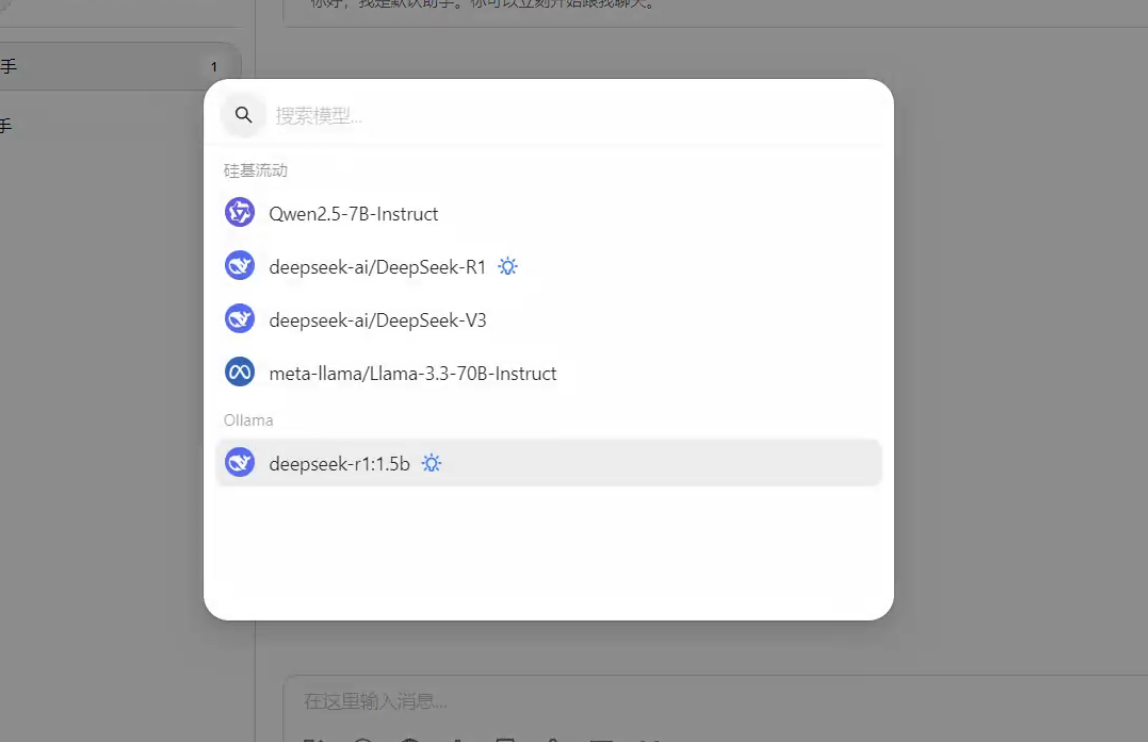
先点击红色圈,再点击蓝色圈,最后点击绿色圈
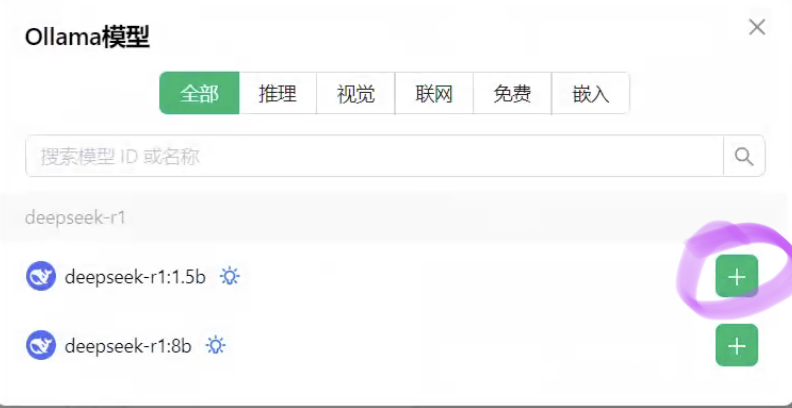
添加模型:
4.选择模型并使用
先点击红色圈,再点击蓝色圈
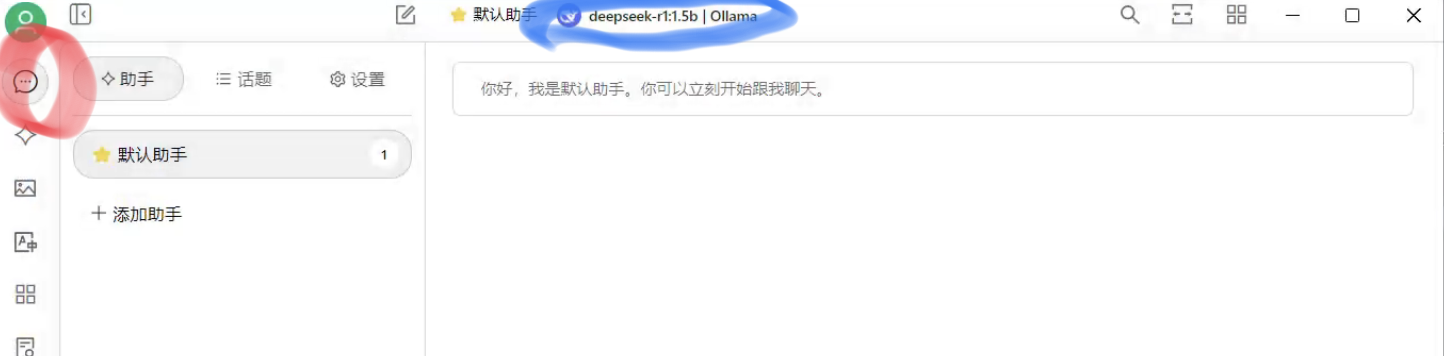
选择下面的模型(Deepseek-r1:1.5b),即可使用。
5.投喂知识库
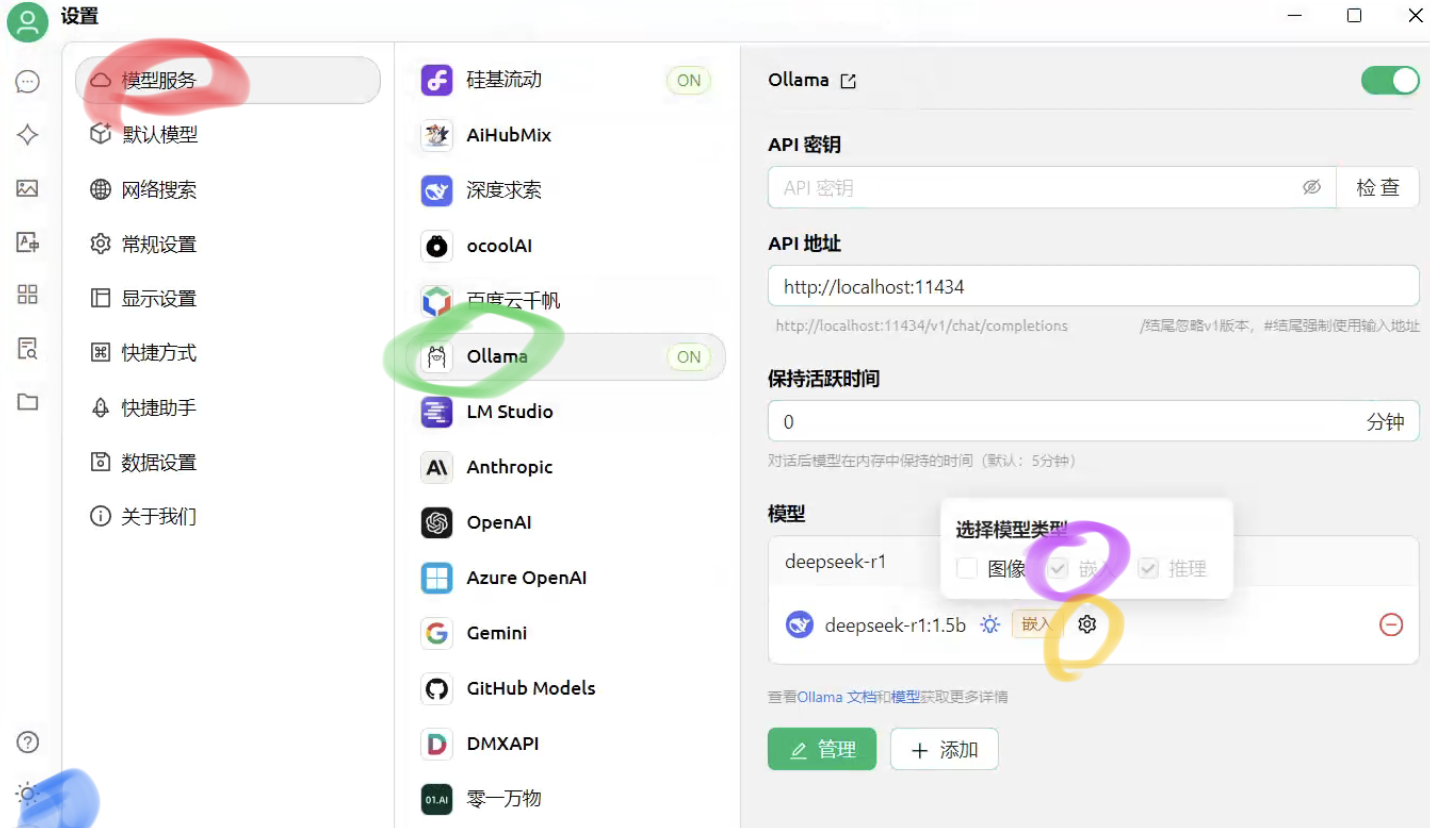
5.1 先打开模型的嵌入
步骤:1.打开设置。2.选择模型服务。3.选择Ollama。4.点击设置,勾上嵌入
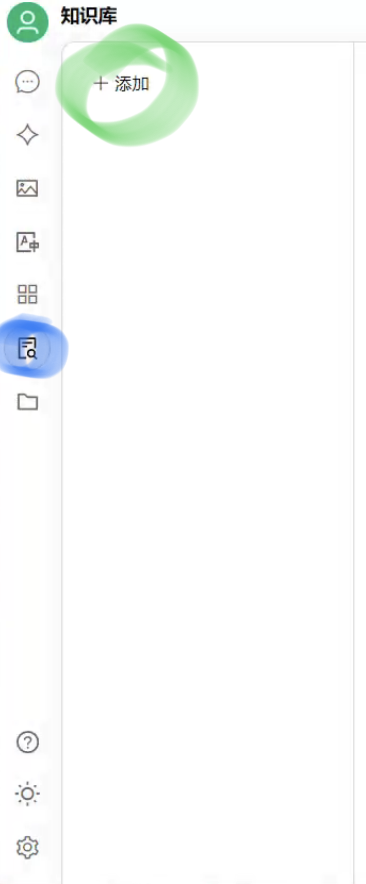
5.2 点击黑色圈位置(知识库)
先点击知识库,再点击添加
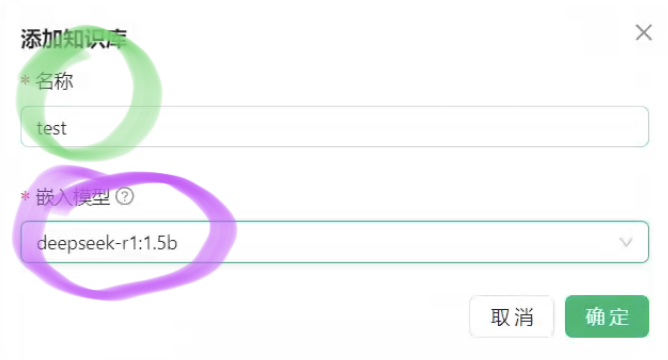
5.3 输入名称和嵌入的模型,点击确定
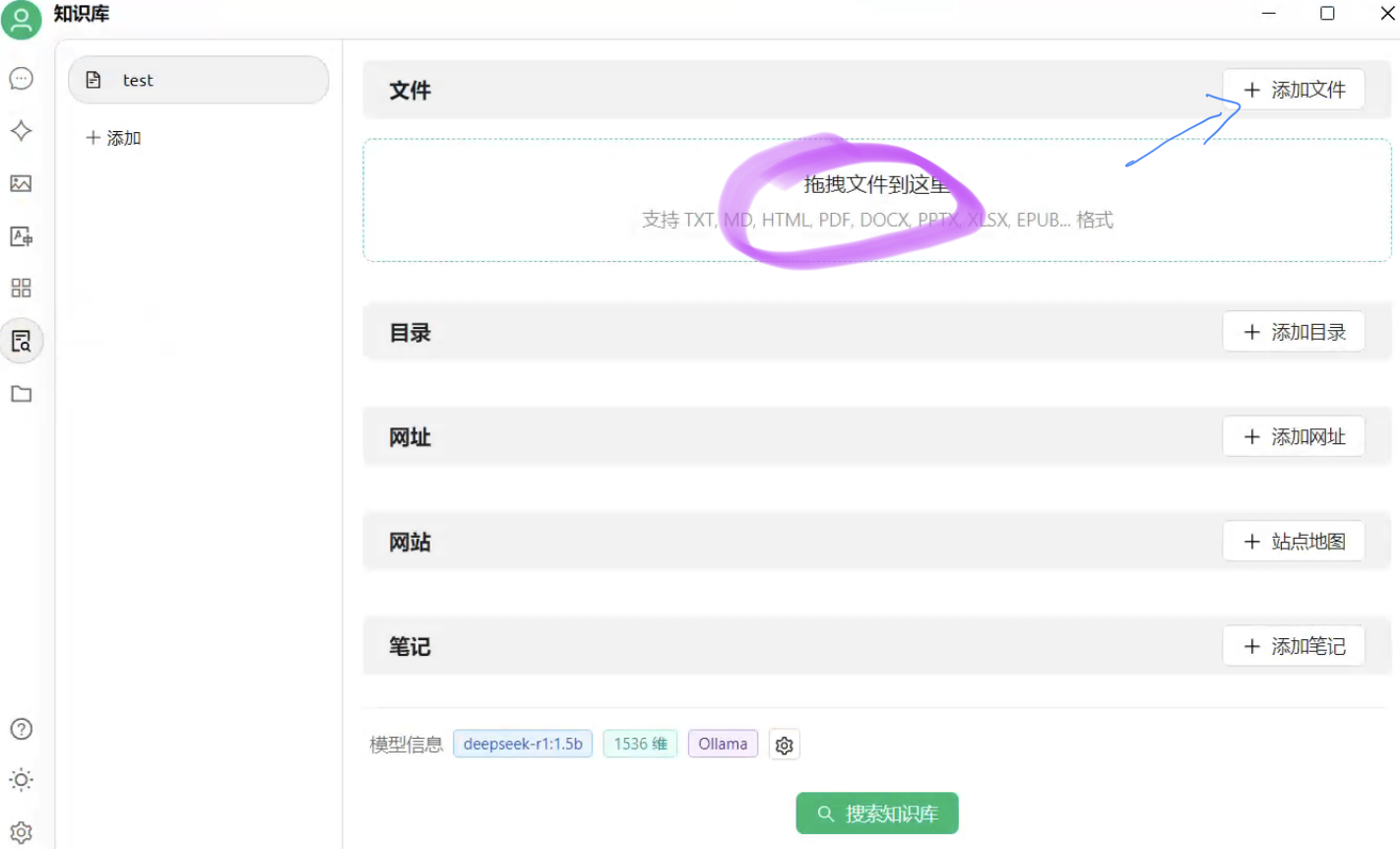
5.4 添加文件
点击添加文件或者直接拖拽
六、基于本地文件微调大模型
6.1 大模型微调:从通用能力到领域专家的进化之路
6.1.1 什么是大模型微调?
大模型微调(Fine-tuning)是指在预训练大模型基础上,通过特定任务数据进一步优化模型参数,使其适应目标场景的技术过程。这一技术突破了传统 “一刀切” 的模型适配模式,推动 AI 从通用智能向垂直领域深度渗透。
6.1.2 有什么微调方法?
6.1.2.1 传统微调技术
1. 全量微调:直接使用目标任务数据训练模型,适合数据量大且任务差异显著的场景(如从文本生成转向代码开发)。
2. 增量微调:在预训练模型上叠加新任务层,保留原有知识,适用于多任务学习。
6.2.1.2高效微调技术
1. LoRA(Low-Rank Adaptation):通过低秩矩阵分解冻结大部分参数,仅训练新增的低秩层。可以减少可训练参数 99%,显存占用降低 75%,支持在消费级 GPU 上微调千亿参数模型。
2. Adapter:在模型各层插入小型神经网络模块(如 100-200 个神经元),保留原架构,微调速度提升 3 倍,适合快速迭代场景(如电商推荐系统)。
3. Prefix Tuning:在输入前添加可训练的前缀向量,引导模型关注特定任务。
6.2.1.3 知识蒸馏与提示工程
1. 知识蒸馏:将大模型的输出作为小模型的软标签,实现轻量化部署。
2. 提示工程:通过设计特定输入模板,无需修改模型参数即可激活目标能力。
6.2 大模型微调工具
6.2.1 LLaMA-Factory
6.2.1.1 什么是LLaMA-Factory?
LLaMA-Factory 是一个专注于大模型全生命周期管理的开源框架,旨在通过技术整合与流程简化,降低大型语言模型(LLM)的开发门槛。其核心目标在于构建一个集训练、微调、推理和部署于一体的生态系统,支持研究人员和开发者快速实现模型的定制化需求。平台基于 PyTorch 和 Hugging Face Transformers 构建,通过优化算法与硬件适配,显著提升了长序列训练效率,尤其在 NVIDIA A100 等高端 GPU 上表现突出。
6.2.2 安装LLaMA-Factory
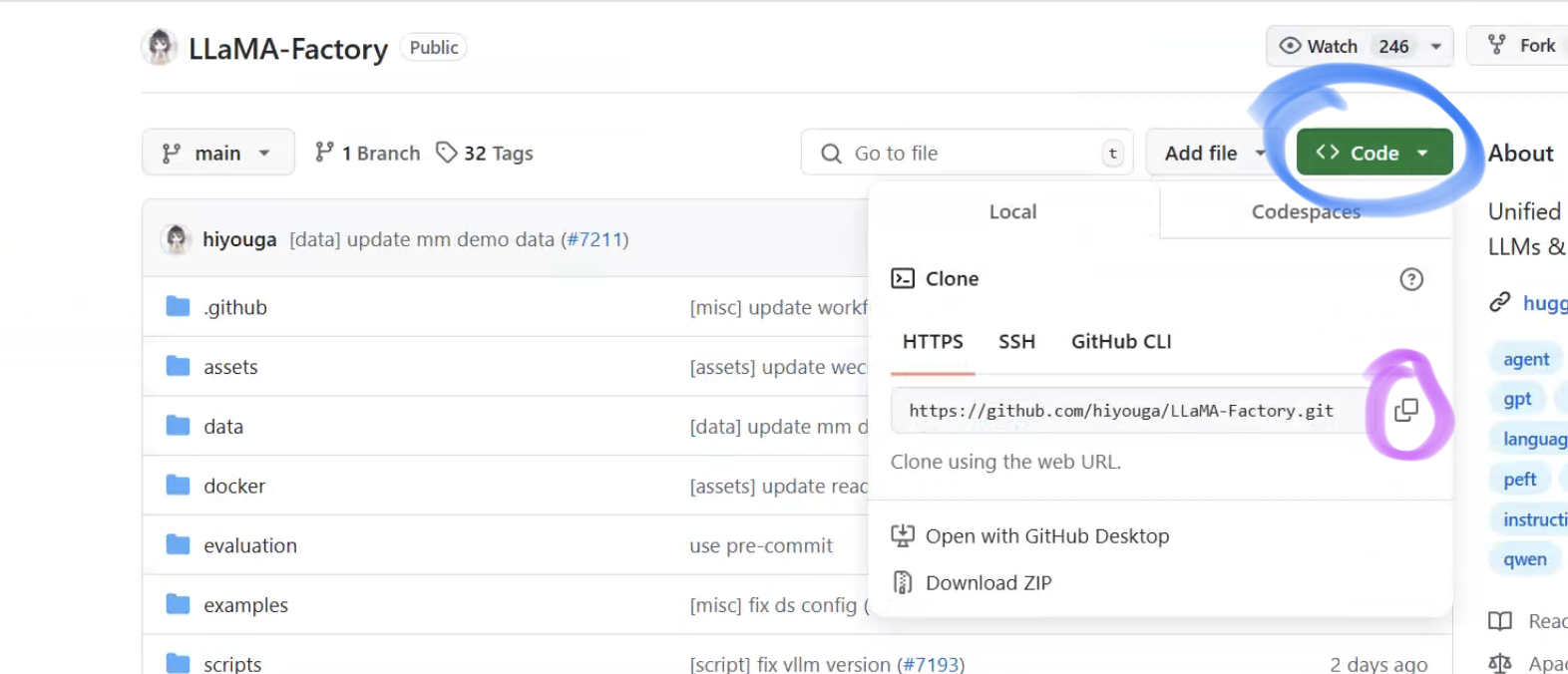
GitHub:hiyouga/LLaMA-Factory:100+ LLMs和VLMs的统一高效微调(ACL 2024)
1.打开上面的网页,点击Code,复制链接
2.打开终端,输入以下代码,点击回车,即可开始下载。
git clone https://github.com/hiyouga/LLaMA-Factory.git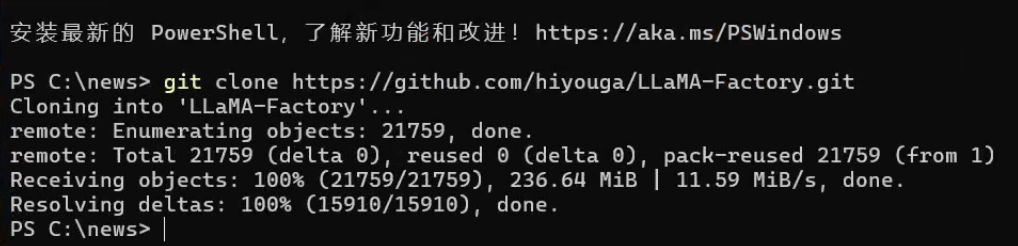
3. win+r 输入cmd(默认已经安装好了Anaconda和cuda)
4.创建一个空环境:
conda create -n lm python==3.105.进入到创建的环境
conda activate lm6.下载pytorchPyTorch 插件
7.选择适合自己cuda的版本,复制下面的代码到cmd(终端)中。
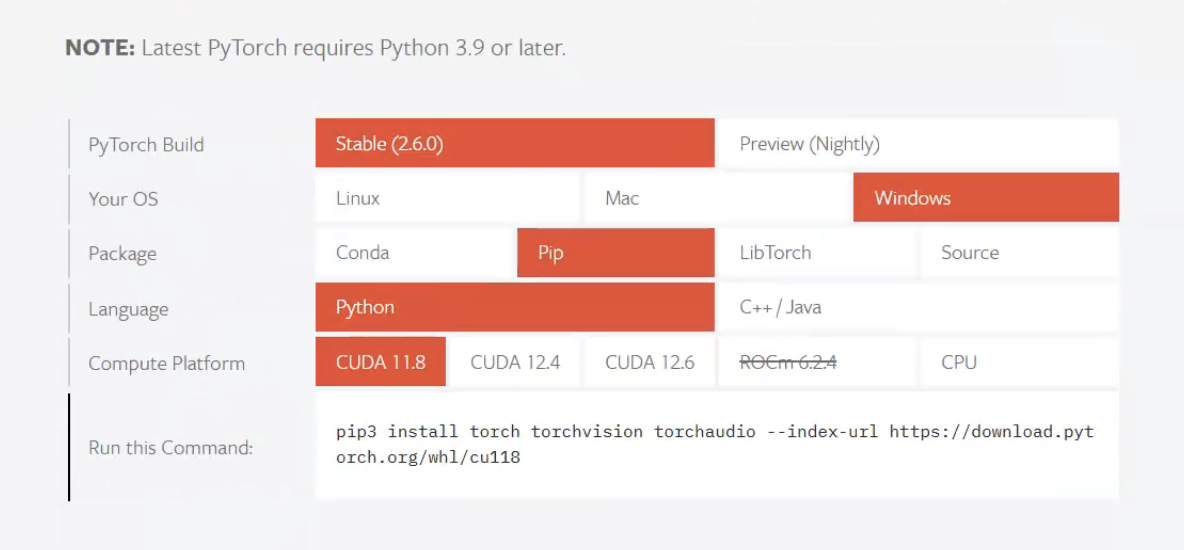
验证是否安装成功:
pythonimport torch
torch.__version__输出以下内容代表安装成功。

输入 exit()退出python
8.下载完成后,继续安装环境所需要的包
为什么先安装pytorch呢?因为官方环境的pytorch版本低,cuda环境也可能与自己电脑上的不同,所以先安装pytorch
先cd 到llama-factory的文件夹中,示例:(不区分大小写)
C:\news\llama-factory9. 复制以下文本到终端
pip install -r requirements.txt为了防止漏掉包,再执行以下官方提供的命令
pip install -e ".[torch,metrics]"10. 下载bitsandbytes
python -m pip install bitsandbytes --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui11. 运行llama-factory
llamafactory-cli webui6.2.3 hugging face下载蒸馏模型
使用以下代码下载1.5b模型
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git6.2.4 数据集设置
数据集格式为:(保存为.json文件)
[
{
"instruction": "",
"input": "",
"output": ""
},
{
"instruction": "",
"input": "",
"output": ""
}
]
找到下面文件,使用记事本打开
LLaMA-Factory\data\dataset_info.json新增一个数据集
"数据集名称": {
"file_name": "文件名.json",
"file_format": "json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
},
"task _type": "sft"
},6.2.5 使用llama-factory进行微调
1. 选择模型(这里选择DeepSeek-R1-1.5B-Distill)
2. 选择模型路径(绝对路径)
3. 选择量化等级(节省显存,缺点是精度会降低)
4. 选择数据集路径
5.选择数据集(上一节的数据集名称)
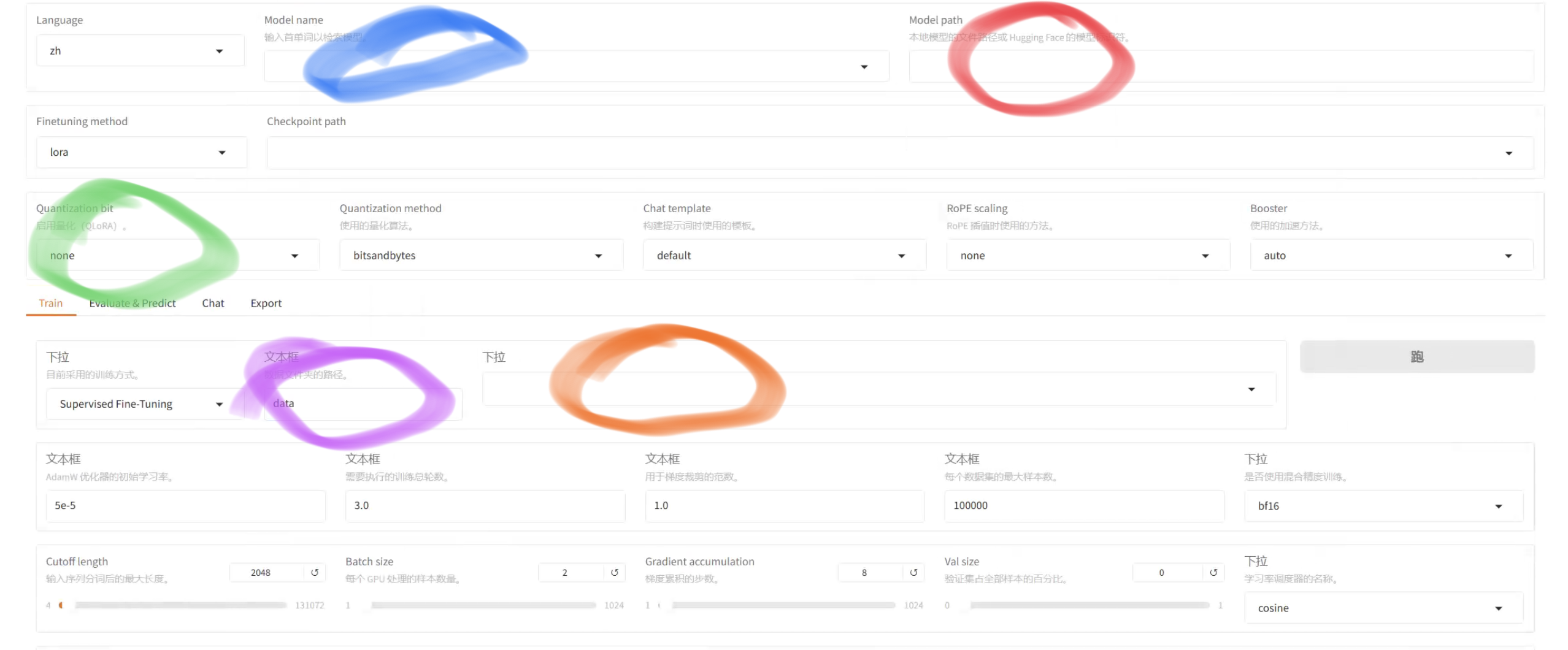
设置好后点击开始
6.2.6 模型保存
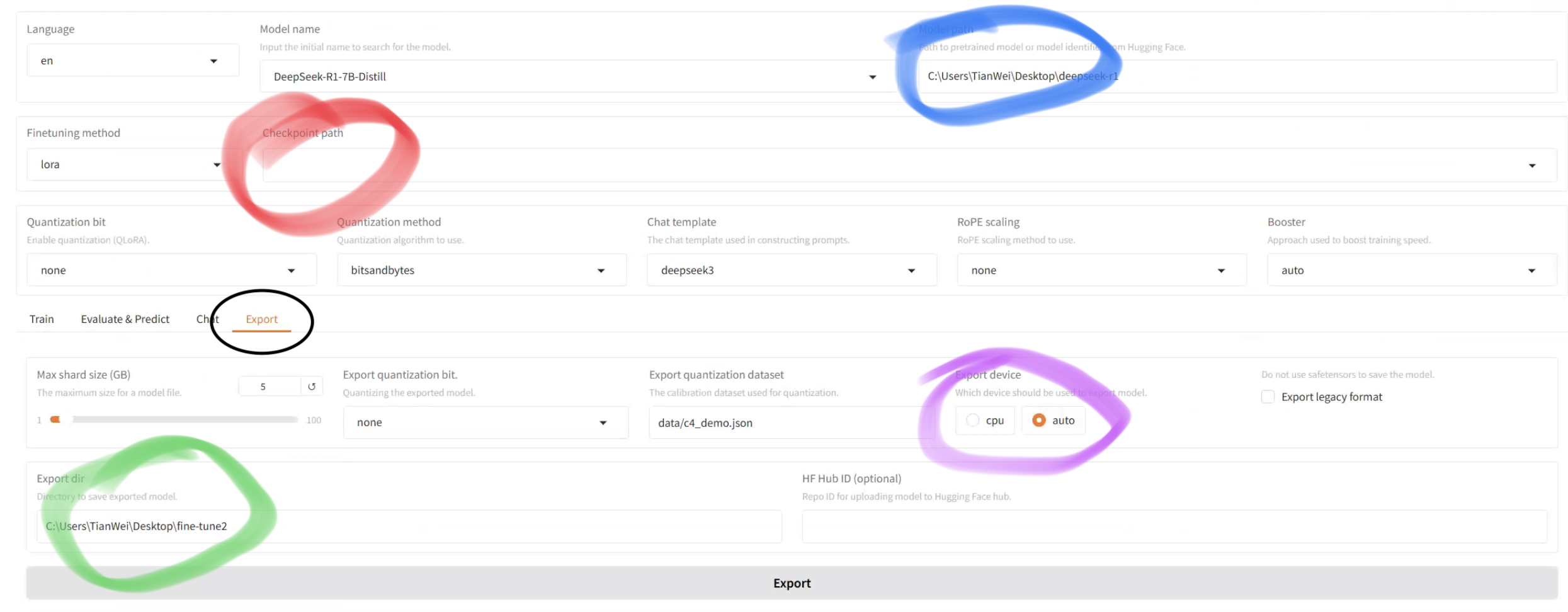
微调完成后,使用llama-factory进行保存。先选择黑色圈中的Export
1. 选择路径(原模型路径)
2.选择检查点(训练的文件)
3.选择导出路径
4. 选择导出设备为Auto
6.2.7 转换为 ollama 支持的格式
克隆 llama.cpp 项目:
-
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp转换格式
-
python3 convert.py --input 微调后的路径 --output 转换后的路径在ollama中运行导出的模型
-
ollama run 导出模型的路径
七、DeepSeek 赋能科研创新:从文献分析到成果转化的全流程加速
在人工智能技术深度渗透科研领域的当下,DeepSeek凭借其高效的多模态处理能力与行业定制化方案,正在重塑科研工作的范式。其核心价值在于将复杂AI技术转化为可操作的科研工具,覆盖从选题构思到成果发表的全链条,为科研人员提供智能化助力。
7.1 文献检索与知识整合的革命 DeepSeek
支持PDF、PPT等多格式文档的智能提取,结合知识图谱技术自动识别研究领域的关键概念与趋势。基于海量学术数据库,DeepSeek可自动生成文献综述矩阵,识别研究空白。通过学科知识图谱与研究热点追踪,生成创新性选题方向。
7.2 实验设计与数据分析的智能化升级
基于已有的研究数据,DeepSeek可辅助推导研究假设,并提供实验设计的优化建议,R1模型的数学推理能力可验证论文中的公式推导逻辑。支持结构化与非结构化数据的混合处理,如社会科学领域的访谈录音文本化分析、环境科学中的监测数据可视化。
7.3 论文写作与发表的全流程支持
根据用户指令自动生成符合学术规范的段落,涵盖引言、方法、结论等部分。支持LaTeX公式智能转换,自动调整参考文献格式,并通过语义级查重系统检测学术不端行为,识别准确率达96%。支持62种语言实时互译,结合多模态处理能力,实现科研成果的全球化传播。例如,DeepSeek与飞书多维表格集成,可批量生成跨语言报告,提升国际合作效率。
7.4 跨学科协作与资源整合
通过与高校、科研机构合作,DeepSeek构建了覆盖68个学科的学术语料库。北京理工大学(珠海)基于该平台开发经济监督模型,推动人工智能与社会科学的深度融合,依托开源架构,科研人员可自定义模型参数,适配特定研究场景。
7.5 技术优势与未来展望
混合专家模型(MoE)与动态子网激活技术,使计算成本仅为国际同类模型的1/10,支持长序列推理与多任务并行,通过本地化部署方案保障敏感数据安全,已在医疗、金融等领域实现私有云适配。与飞书、华为云等平台深度集成,提供开箱即用的科研工具链,降低技术使用门槛。 未来,DeepSeek将进一步探索量子计算协同与具身智能,推动AI在科研领域的深度渗透。通过持续优化算法与扩展应用场景,其目标是成为科研工作者的"数字协作者",使复杂研究流程如日常对话般高效自然。

















 3422
3422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









