






深度学习自然语言处理 原创作者:cola
随着各种各样增强版LLaMA的出现,Mixture-of-Expert(MoE)类模型越来越受大家关注。而LLaMA-MoE正是基于LLaMA系列和SlimPajama的MoE模型。它显著的一个好处是减小了模型大小,降低了训练代价。通过以下两个步骤进行构建:
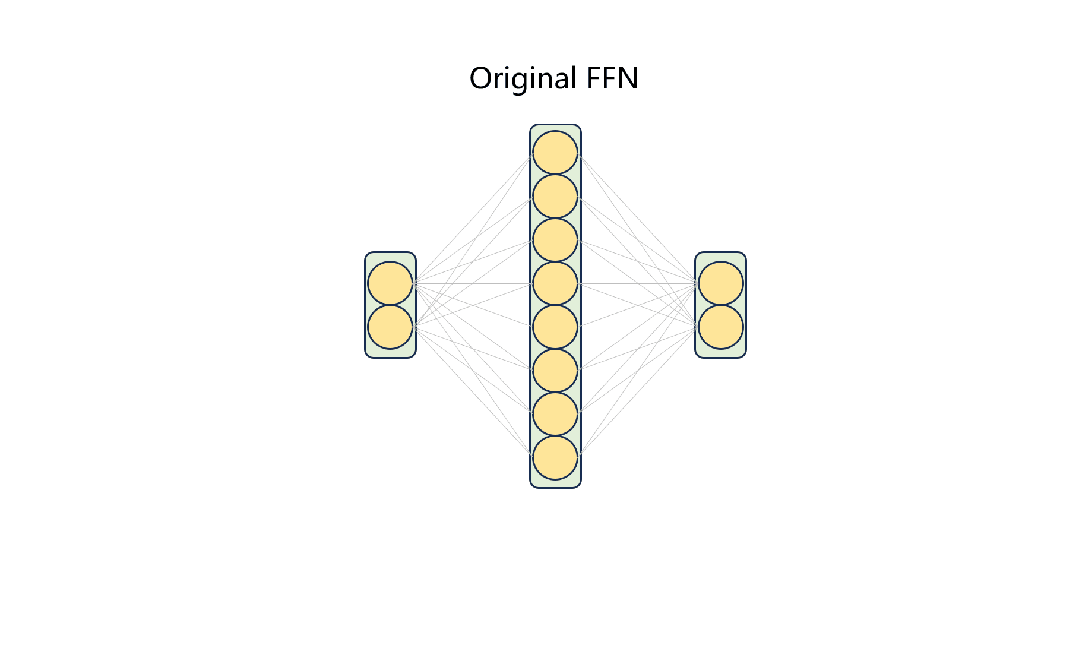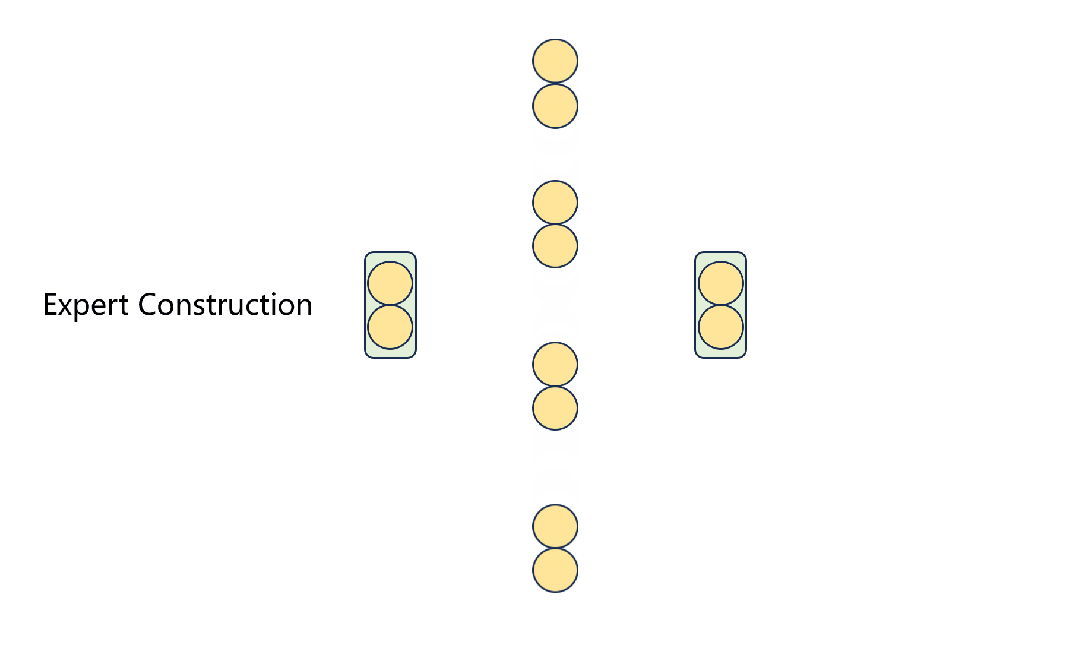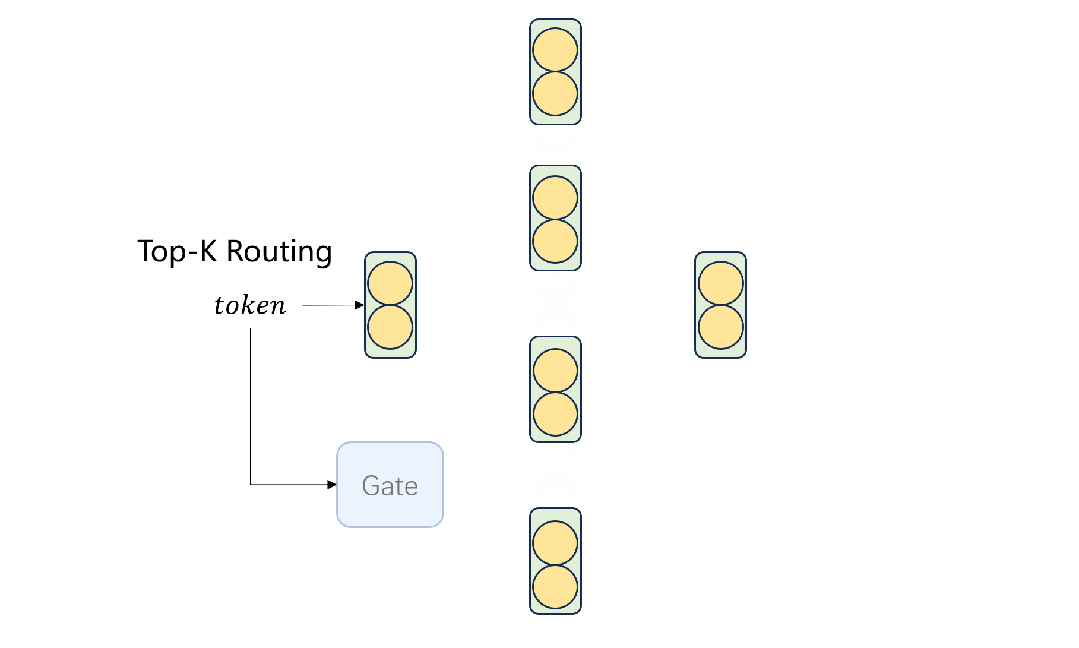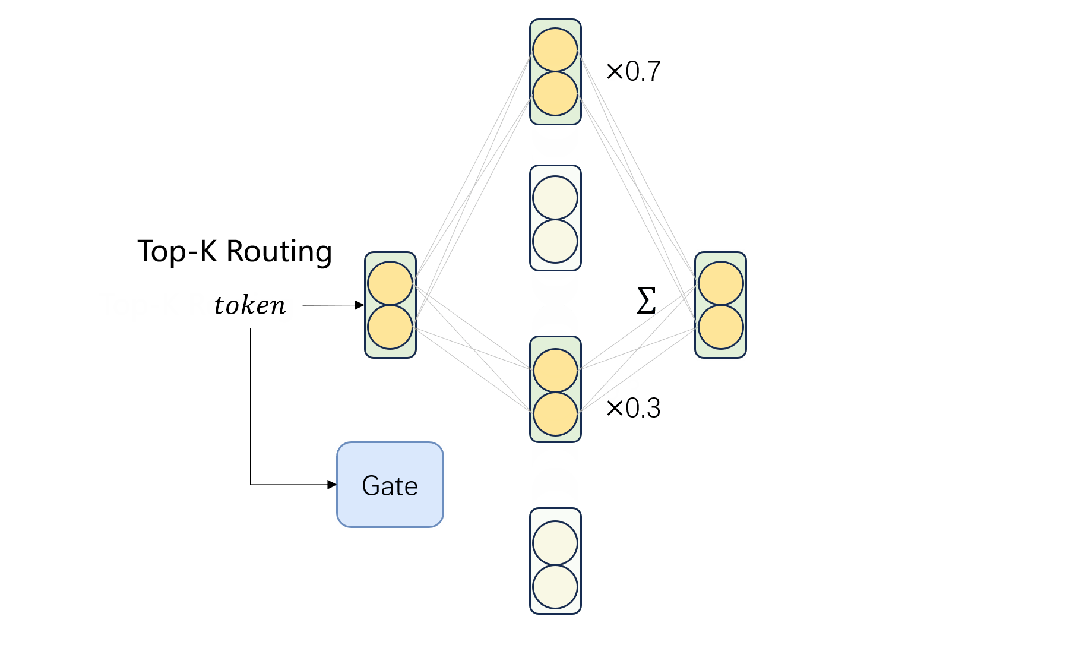
在这些阶段之后,模型可以保持其语言能力并将输入传递给特定的专家。同时,只有部分参数被激活。目前模型的权重以及构建和训练过程的代码都已经公开:https://github.com/pjlab-sys4nlp/llama-moe
在这些阶段之后,模型可以保持其语言能力并将输入传递给特定的专家。同时,只有部分参数被激活。目前模型的权重以及构建和训练过程的代码都已经公开:
https://github.com/pjlab-sys4nlp/llama-moe
大规模训练是实现灵活、强大的神经语言模型的有效和有希望的方法。在深度学习中,规模的放大是增强性能效能的关键催化剂。这表明,由于计算成本的原因,巨大的模型大小可能是不可持续的。因此本文研究了在激活参数固定的情况下扩展模型大小。换句话说,我们专注于稀疏激活模型,将模型大小与计算成本解耦。然而,训练一个巨大的稀疏模型的成本仍然不可忽视。
本文研究从现有的LLM中建立稀疏的MoE模型。基于LLaMA,将transformer解码器块中的前馈网络(FFNs)转换为专家网络,然后继续训练转换后的LLaMA-MoE-v1模型。LLaMA-MoE-v1主要表现出三个特点:
主要面临的挑战有两个:首先,如何从现有LLM中的FFNs中有效地构建专家。其次,将网络结构从密集改为稀疏将会导致性能的下降,如何在可接受的计算成本下提高MoE模型的性能至关重要。
针对上述问题,提出了一种简单的随机划分策略,将FFN的参数划分为互不重叠的专家。考虑在总共N个专家中激活k个专家,中间层的dropout率为(N−k)/N,随后我们将专家的输出按N/k的倍数缩放。继续训练转换后的MoE模型和一个额外的门网络,该网络的域权重比例与激活的参数相对应。这样,LLaMA-MoE-v1可以快速收敛到一个合适的水平。本文用200B个token继续训练每个LLaMA-MoE-v1模型。
一个标准的专家混合层(MoE)由
个专家网络
和一个门控网络
激活top-k专家并将输入token分配给相应的专家。一般情况下,选取的专家数量
是固定的,远小于总专家数量
,呈现出MoE模型的稀疏激活方式。形式上,给定输入嵌入
表示第
个专家网络的输出,MoE层的输出是
个选定专家的输出之和:
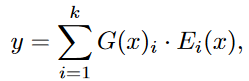
一个标准的专家混合层(MoE)由个专家网络和一个门控网络,激活top-k专家并将输入token分配给相应的专家。一般情况下,选取的专家数量是固定的,远小于总专家数量,呈现出MoE模型的稀疏激活方式。形式上,给定输入嵌入表示第个专家网络的输出,MoE层的输出是个选定专家的输出之和:其中,top-k由确定,表示哪些专家接受输入。我们在LLaMA-MoE-v1中实现了一个带负载平衡的token级噪声top-k门控机制。
其中,top-k由
确定,表示哪些专家接受输入
。我们在LLaMA-MoE-v1中实现了一个带负载平衡的token级噪声top-k门控机制。
如图1所示,通过首先将FFNs划分为多个专家,并将每个token路由到top-k个专家,从LLaMA-2-7B构建LLaMA-MoE-v1。随后,通过持续的预训练来恢复MoE模型的语言能力。
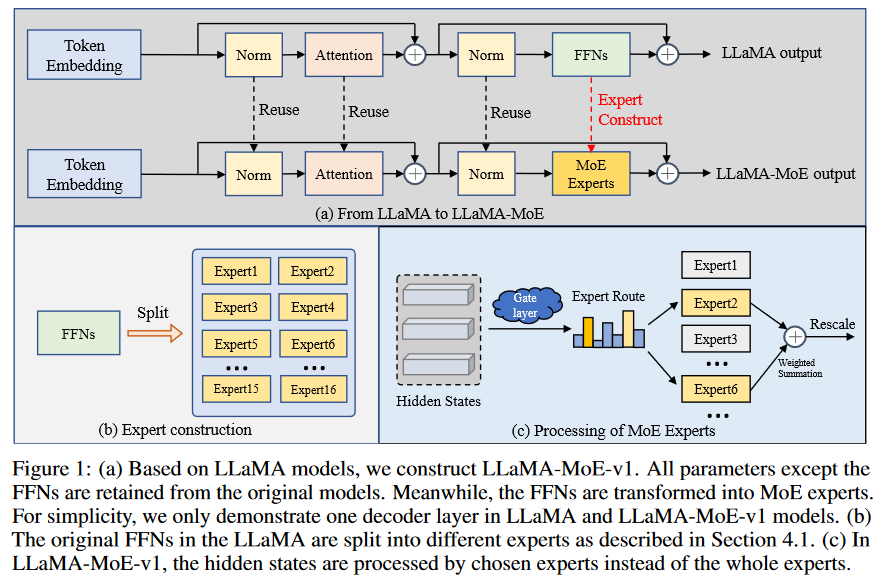
如图1所示,通过首先将FFNs划分为多个专家,并将每个token路由到top-k个专家,从LLaMA-2-7B构建LLaMA-MoE-v1。随后,通过持续的预训练来恢复MoE模型的语言能力。
从LLaMA中的前馈网络开始,它使用SwiGLU作为激活函数。LLaMA中的每个FFN层由三部分组成:向上投影权重
,门投影权重
,向下投影权重
。给定输入
, FFN的输出
为:
![]()
从LLaMA中的前馈网络开始,它使用SwiGLU作为激活函数。LLaMA中的每个FFN层由三部分组成:向上投影权重,门投影权重,向下投影权重。给定输入, FFN的输出为:其中每一层专家网络由一个前馈层实现。具体来说,给定一个专家大小为,选择指数为,第层专家网络可为:其中,给定输入, 第层专家网络的输出为:根据FFN中中间神经元是否在不同专家之间共享,实现了神经元独立和神经元共享两组构建方法。
其中每一层专家网络由一个前馈层实现。具体来说,给定一个专家大小为
,选择指数为
,第
层专家网络
可为:
![]()
从LLaMA中的前馈网络开始,它使用SwiGLU作为激活函数。LLaMA中的每个FFN层由三部分组成:向上投影权重,门投影权重,向下投影权重。给定输入, FFN的输出为:其中每一层专家网络由一个前馈层实现。具体来说,给定一个专家大小为,选择指数为,第层专家网络可为:其中,给定输入, 第层专家网络的输出为:根据FFN中中间神经元是否在不同专家之间共享,实现了神经元独立和神经元共享两组构建方法。
其中,
![]()
从LLaMA中的前馈网络开始,它使用SwiGLU作为激活函数。LLaMA中的每个FFN层由三部分组成:向上投影权重,门投影权重,向下投影权重。给定输入, FFN的输出为:其中每一层专家网络由一个前馈层实现。具体来说,给定一个专家大小为,选择指数为,第层专家网络可为:其中,给定输入, 第层专家网络的输出为:根据FFN中中间神经元是否在不同专家之间共享,实现了神经元独立和神经元共享两组构建方法。
给定输入
, 第
层专家网络
的输出
为:
![]()
从LLaMA中的前馈网络开始,它使用SwiGLU作为激活函数。LLaMA中的每个FFN层由三部分组成:向上投影权重,门投影权重,向下投影权重。给定输入, FFN的输出为:其中每一层专家网络由一个前馈层实现。具体来说,给定一个专家大小为,选择指数为,第层专家网络可为:其中,给定输入, 第层专家网络的输出为:根据FFN中中间神经元是否在不同专家之间共享,实现了神经元独立和神经元共享两组构建方法。
根据FFN中中间神经元是否在不同专家之间共享,实现了神经元独立和神经元共享两组构建方法。
通过测量每个中间神经元在剪枝时损失变化
的一阶泰勒展开,将专家构造视为一个结构化剪枝问题。对于每个FFN层,保持一个向量
初始化为零,以记录其中间神经元的重要性。给定批量数据
,重要性向量
更新如下:
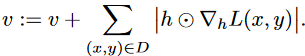
通过测量每个中间神经元在剪枝时损失变化的一阶泰勒展开,将专家构造视为一个结构化剪枝问题。对于每个FFN层,保持一个向量初始化为零,以记录其中间神经元的重要性。给定批量数据,重要性向量更新如下:给定,则有:
给定
,则有:
通过测量每个中间神经元在剪枝时损失变化的一阶泰勒展开,将专家构造视为一个结构化剪枝问题。对于每个FFN层,保持一个向量初始化为零,以记录其中间神经元的重要性。给定批量数据,重要性向量更新如下:给定,则有:
为获得更好的性能,本文研究了LLaMAMoE-v1持续预训练的以下数据采样策略。在动态设置中,数据采样权重每2.5B个token调整一次,总训练预算为30B个token。
由于训练预算有限,进一步探索了两种数据过滤策略以加快模型收敛。在CommonCrawl和C4数据集中过滤掉了50%的广告和15%的不流畅文本。
LLaMA-MoE-v1的训练数据集是SlimPajama,它是对RedPajama数据集进行清洗和去重得到的。该数据集包含627B个token,并包含来自7个领域的数据,包括CommonCrawl, C4, Github, Wikipedia, Books, arXiv和StackExchange。
使用HellaSwag和ARC-c作为分析实验的评估数据集。使用lm-evaluationharness来评估下游任务。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。

如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。
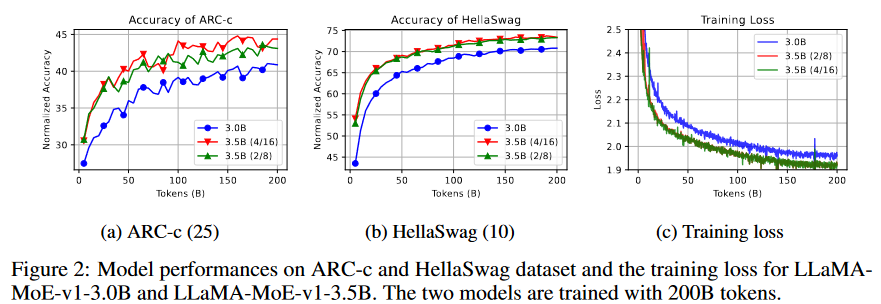
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
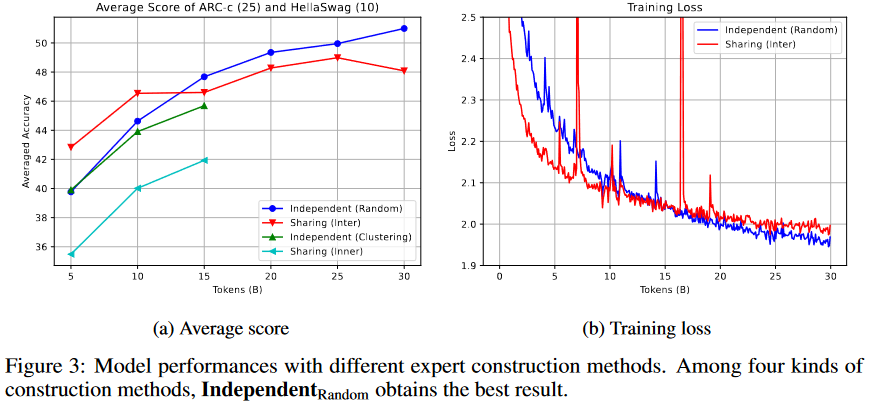
我们还比较了四种构建方法。如图3(a)所示,
在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
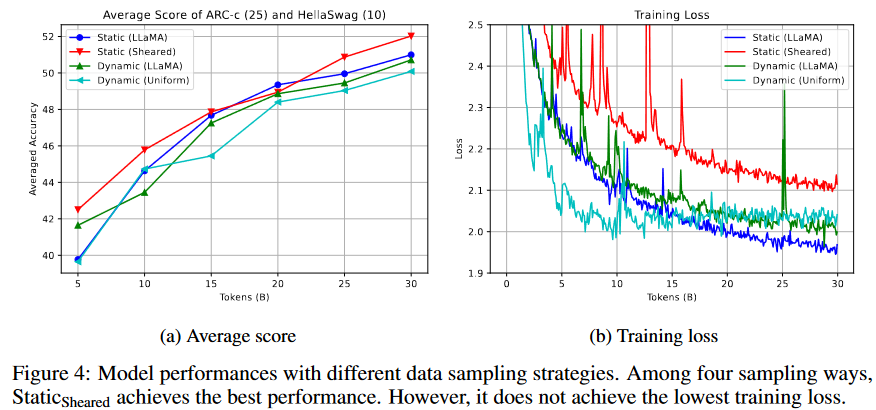
如图4(a)所示,
在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
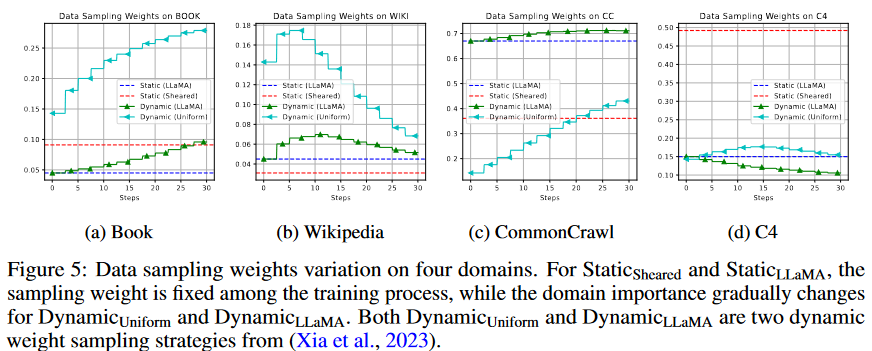
从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
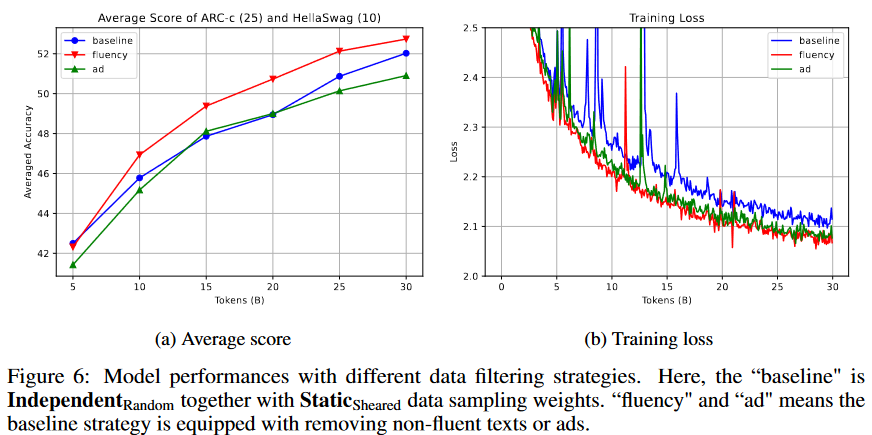
进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
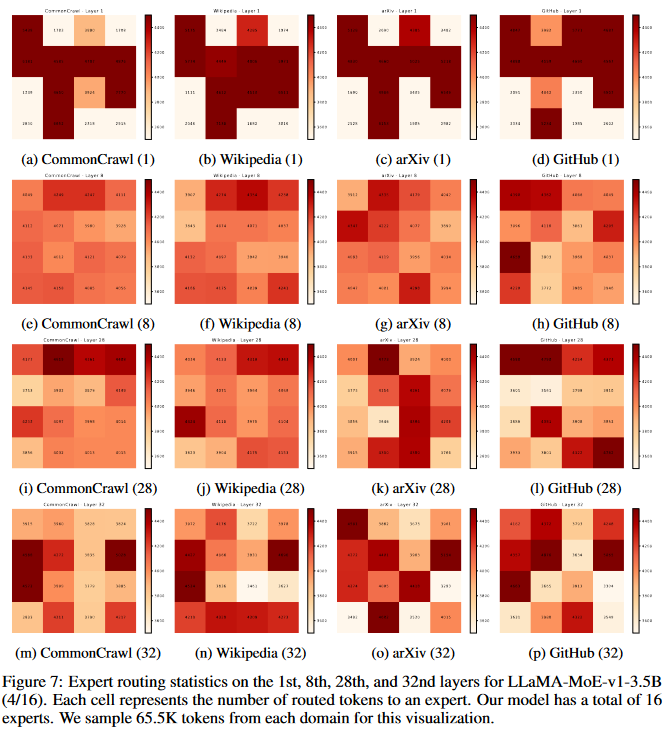
如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
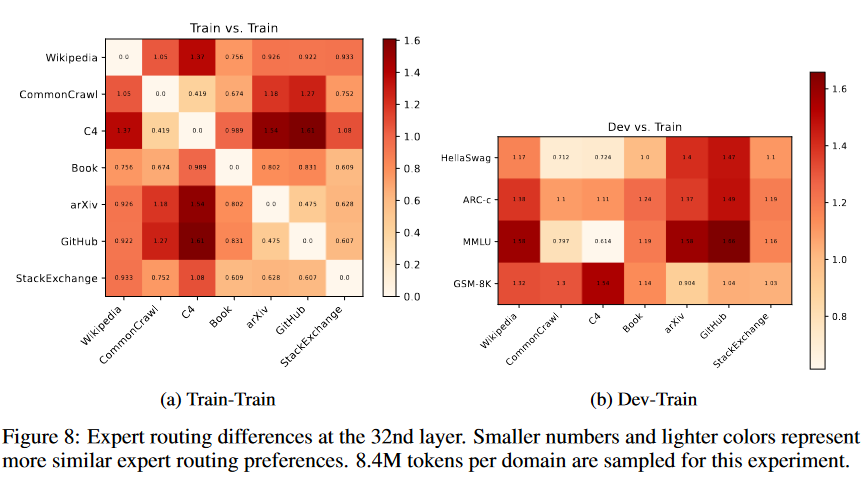
为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。
如表2所示,LLaMA-MoE-v1-3.5B(2/8)与LLaMA-MoE-v1-3.5B(4/16)的平均结果相近,后者稍好一些。然而,LLaMA-MoE-v1-3.5B明显超过了具有相似激活参数的开源模型。在图2 (a)和(b)中,我们展示了模型在ARC-c和HellaSwag上的性能,并发现这些数据集上的结果随着训练过程的进行而逐渐增长。对于训练损失,如图2 (c)所示,LLaMA-MoE-v1-3.0B和LLaMA-MoE-v1-3.5B分别收敛到约1.95和1.90。由于这两个模型激活的参数相对较小,因此最终损失高于LLaMA-2 7B。我们还比较了四种构建方法。如图3(a)所示,在取得了最佳平均分数。损失值的变化如图3(b)所示。然而,我们发现,模型应该至少训练15~20B个token才能正确地得出结论。如图4(a)所示,在token预算内超过了其他方法,而动态数据采样权重比静态权重差。然而,图4(b)中的静态剪切损失比其他方法大,这表明持续的预训练损失可能与下游任务性能相关性较小。从图5中,我们发现C4的采样权重与静态剪切相比走向相反的方向,因为估计的剪切LLaMA-2.7B参考损失低于LLaMA2-7B(2.033 vs. 2.075)。进一步过滤广告和那些不流畅的数据,结果如图6所示。流畅性和广告过滤都获得了比基线更低的训练损失。然而,广告过滤在下游任务中表现较差。我们认为被过滤的广告数量过多,不能带来更多的知识和信息,需要通过细粒度阈值调整来改进过滤标签器。如图7所示,深度层比浅层有更多的选择。这可能表明浅层可能捕获更多的共同特征,而深层则更多地关注特定于任务的特征。基于这一发现,对后一层的FFNs进行专家划分可能会带来进一步的改进。为研究领域之间的潜在相关性,对token的数量进行归一化,并计算L2距离以表示专家选择差异。如图8a所示,CommonCrwal和C4数据集的专家偏好相似,而GitHub与arXiv和StackExchange的专家偏好相似。














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









