







在人工智能领域,文本到图像的生成任务一直是研究的热点。近年来,扩散模型和一致性模型因其在图像生成中的卓越性能而受到广泛关注。然而,这些模型在生成速度和微调灵活性上存在局限。为了解决这些问题,康奈尔大学的研究团队提出了一种新的框架——RLCM(Reinforcement Learning for Consistency Models),旨在通过强化学习优化一致性模型,以实现快速且高质量的图像生成。一致性模型通过直接将噪声映射到数据,显著加快了推理速度。在生成质量和推理时间之间提供了更精细的权衡。不过,如何将这些模型更好地适应特定的下游任务,尤其是在文本到图像的生成中,仍是一个挑战。

在强化学习(RL)的背景下,序列决策过程被建模为一个有限视界的马尔可夫决策过程(MDP)。在MDP中,智能体(agent)通过执行动作(action)在状态(state)空间中进行转移,以最大化期望累积奖励。扩散模型和一致性模型作为生成模型,其核心在于通过学习数据分布的概率流,实现新数据点的合成。
强化学习在一致性模型中的应用
RLCM框架将一致性模型的推理过程建模为MDP,并利用策略梯度方法进行优化。该框架的核心思想是将一致性模型的迭代推理步骤视为MDP中的一系列决策,其中每个决策都对应于模型生成过程中的一个步骤。通过定义一个奖励函数,RLCM能够指导模型生成特定任务所需的图像。这种方法不仅提高了模型的训练效率,还加快了推理过程,使得生成的图像质量在仅有少量迭代步骤的情况下就能达到较高水平。
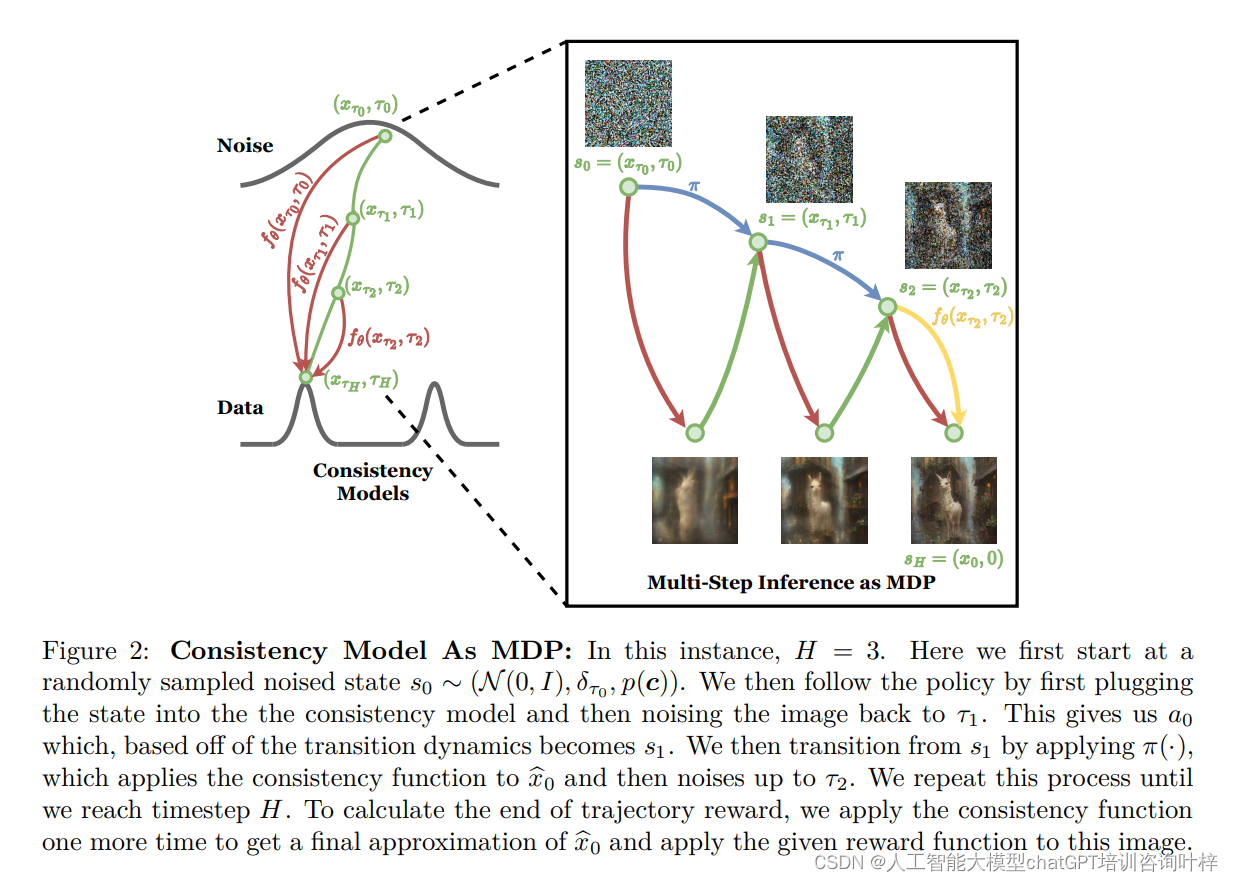
一致性模型的挑战
一致性模型是一种生成模型,它能够将噪声直接映射到数据,从而快速生成图像。尽管它们在推理速度上具有优势,但在生成特定任务需求的图像方面仍存在挑战,比如生成与文本描述高度一致的图像。
一致性模型多步采样过程的算法
输入:
- 一致性模型 π,通常表示为 fθ(·, ·),这里的 θ 表示模型参数。
- 一系列时间点 τ1 > τ2 > ... > τN−1,这些时间点定义了概率流的不同阶段。
- 初始噪声 x_T,这是生成过程的起始点,通常是一个高斯噪声样本。
输出: 生成的图像 x。
算法步骤:

一致性模型的关键特点
- 快速生成: 一致性模型能够快速从噪声生成高质量的图像,因为它们直接学习了从噪声到数据的映射,而不需要逐步去噪。
- 多步推理: 算法中的多步推理过程允许模型在保持快速生成的同时,通过迭代提高图像质量。
- 概率流: 一致性模型基于概率流的概念,这是描述数据生成过程的数学工具。
一致性模型在RLCM框架中的应用
在RLCM框架中,一致性模型的推理过程被建模为一个马尔可夫决策过程(MDP)。在MDP中,每个状态转换对应于算法中的一个步骤,而奖励函数则基于生成图像的质量来定义。通过强化学习,一致性模型可以被微调,以生成更符合特定任务需求的图像。
强化学习的作用
强化学习是一种无模型的学习方法,它通过与环境的交互来学习策略,以最大化累积奖励。在图像生成的背景下,RL可以用来微调一致性模型,使其生成的图像更符合特定的奖励函数,该奖励函数反映了图像的质量、美学和与文本指令的一致性。
RLCM框架
研究者提出的RLCM(Reinforcement Learning for Consistency Models)框架将一致性模型的推理过程建模为一个多步马尔可夫决策过程(MDP)。在这个框架中:
- 状态(State): 表示为图像生成过程中的一个中间状态,包括当前时间点的噪声图像、时间戳和文本提示。
- 动作(Action): 表示为模型在当前状态下的输出,即下一步的噪声图像。
- 奖励函数(Reward Function): 根据生成的图像与文本提示的一致性、图像质量和美学等标准来定义。
- 策略(Policy): 是一个概率分布,它决定了在给定状态下选择哪个动作。
RLCM的优化过程
- 初始化: 从一致性模型的先验分布中采样一个噪声图像作为初始状态。
- 迭代: 在每一步,RLCM根据当前状态通过策略选择一个动作,即生成下一步的噪声图像。
- 奖励: 根据生成的图像计算奖励,奖励反映了图像与任务需求的匹配程度。
- 策略更新: 使用策略梯度方法更新策略,以增加获得高奖励动作的概率。
- 迭代推理: 重复上述步骤,直到生成最终图像。
策略梯度方法
RLCM使用策略梯度方法来优化一致性模型。这种方法通过梯度上升来更新策略,使得期望奖励最大化。它利用了REINFORCE算法,这是一种基于蒙特卡洛采样的策略梯度方法,适用于奖励函数可能是非微分的情况。
实验部分
研究团队通过一系列实验验证了RLCM框架的有效性。实验结果表明,RLCM在文本到图像的生成任务上的表现超过了现有的RL微调扩散模型(DDPO)。RLCM在训练时间和推理时间上都具有显著优势,同时在样本质量和多样性上也展现出了竞争力。RLCM还表现出了良好的泛化能力,能够适应未在训练中见过的新文本提示。

实验设置
实验的目标是展示RLCM在文本到图像生成任务上的效率和质量。为此,研究者选择了以下四个任务进行评估:
- 压缩(Compression):生成文件大小尽可能小的图像。
- 非压缩(Incompression):生成文件大小尽可能大的图像。
- 美学评分(Aesthetic):生成高美学质量的图像。
- 文本图像对齐(Prompt Image Alignment):生成与文本提示语义对齐的图像。
实验执行过程
- 预训练模型:使用Dreamshaper v7和其对应的潜在一致性模型作为基线模型。
- 微调:使用RLCM框架对一致性模型进行微调,以适应上述任务。
- 奖励函数:为每个任务定义了相应的奖励函数,以量化图像质量、美学、压缩性和与文本提示的一致性。
- 策略优化:利用策略梯度算法,通过最大化奖励函数来训练模型。
结果分析
- 性能比较:将RLCM与DDPO(一种RL微调扩散模型的方法)进行比较,发现RLCM在多数任务上的训练和推理速度都更快,同时生成的图像质量也更高。
- 训练时间:RLCM在训练时间上显著优于DDPO,特别是在美学评分任务上,RLCM的训练速度提高了17倍。
- 推理时间:在固定的推理时间预算下,RLCM生成的图像平均奖励分数高于DDPO,表明RLCM在保持图像质量的同时,能更快速地完成推理过程。
- 泛化能力:RLCM在未见过的文本提示上也能生成高质量的图像,显示出良好的泛化能力。

结论
实验结果证明了RLCM框架在文本到图像生成任务中的有效性。RLCM不仅提高了模型的训练和推理速度,还保证了生成图像的多样性和质量。RLCM在未见过的文本提示上的表现,展示了其出色的泛化能力。
论文链接:https://arxiv.org/abs/2404.03673
项目地址:https://rlcm.owenoertell.com/

















 2344
2344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











