






转自公众号DeepPrompting
阅读有关LLM的文章,可以看到如“我们使用标准Transformer架构”之类的短语。但“标准”是什么定义,自原始文章以来是否有变化?
有趣的是,尽管 NLP 领域已经经历了 5 年的高速增长,但 Vanilla Transformer 仍然坚持林迪效应,即事物越旧,未来存在的时间就越长。
“Lindy Effect(林迪效应)是一个源自纽约市林迪熟食店的概念,指的是一种非易腐性事物(如技术、观念或文化现象)的未来寿命与其当前年龄成正比的观念。简而言之,某物存在的时间越长,它可能继续存在的时间就越长。
这个概念在讨论技术、书籍、思想甚至社会结构时变得流行。例如,一本已经出版了100年的书可能会再保持100年的畅销,而一本新出版的书可能没有这么长的未来。”
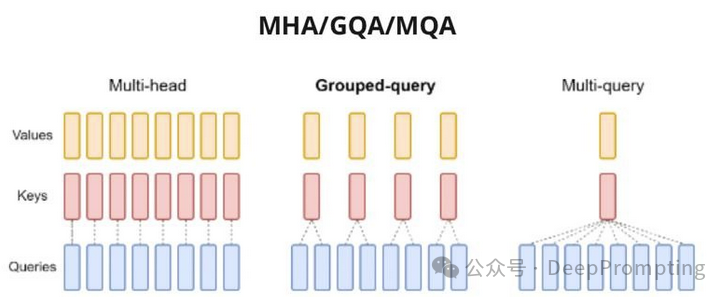
下面总结图中的5大变化:
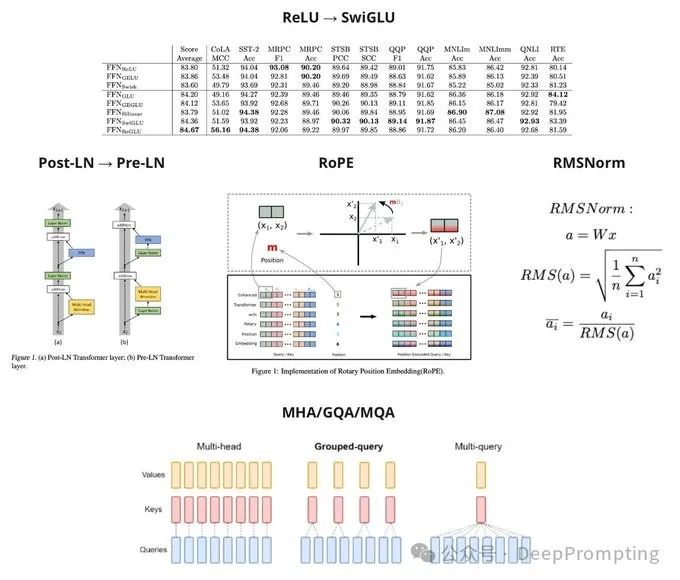
(1)以语言模型(即仅解码器)LLaMa-2 为例,让我们看看 LLM 的主要架构改进:— Post LayerNorm → Pre LayerNorm (https://arxiv.org/abs/2002.04745)。这使得收敛更加稳定。现在,这个过程的进行方式是原始嵌入简单地通过解码器块,并且来自 FFN 和 Attention 的“调整”被添加到其中--Residual Connection方式。
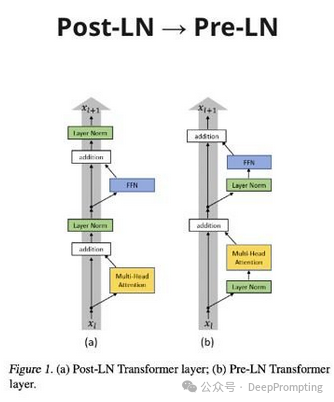
(2) — 绝对位置嵌入 → RoPE (https://arxiv.org/abs/2104.09864)。该方法本身是根据位置将令牌嵌入旋转一定角度。而且效果很好。此外,该方法还进行了许多修改,以将上下文扩展到非常大的数字。
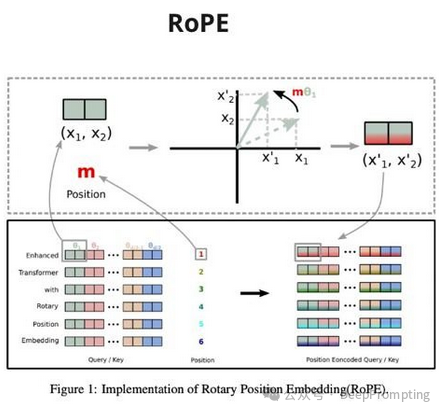
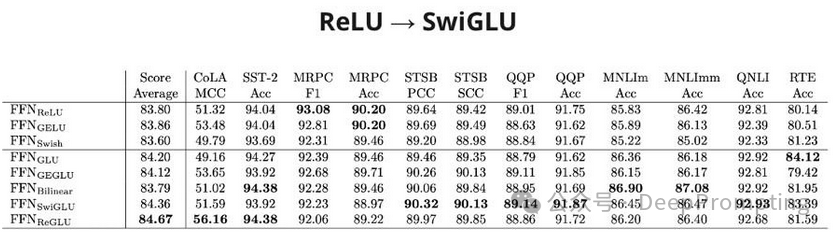
(3) — ReLU 激活 → SwiGLU (https://arxiv.org/abs/2002.05202)。门控线性单元(SwiGLU 所属的一系列方法。它添加了矩阵逐元素乘法的运算,其中一个矩阵已通过 sigmoid,从而控制从第一个矩阵传递的信号强度)添加了一点 提高多项任务的质量。
(4)LayerNorm → RMSNorm (https://arxiv.org/abs/1910.07467)。RMSNorm 在计算上更简单,但具有相同的质量。

(5)注意力修改(https://arxiv.org/abs/2305.13245),例如,每组 Q 矩阵一次使用一对 K-V 矩阵。这种改进主要已经影响了推理的优化。但也有大量旨在降低运算二次复杂度的方法。
















 2197
2197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











