






MetaFormer is Actually What You Need for Vision
Weihao Yu, Mi Luo, Pan Zhou
CVPR 2022
transformer在视觉任务中显示出巨大的潜力。一种普遍的看法是,他们基于注意力的token混合器起到了很大作用。然而,最近的工作表明,transformer中基于注意力的模块可以被空间MLP取代,所得到的模型仍然表现得很好。基于这一观察,我们假设transformer的通用体系结构对模型的性能更加重要,而不是特定的token混合器模块。为了验证这一点,我们特意用一个简单得令人尴尬的空间池化运算符替换了transformer中的注意模块,以仅执行最基本的token混合。令人惊讶的是,我们观察到名为PoolFormer的派生模型在多个计算机视觉任务上取得了相当有竞争力的表现。例如,在ImageNet 1K上,PoolFormer实现了82.1% 的top-1准确率,准确率在参数量减少35%/52%、MAC减少48%/60%的情况下,超过了经过良好调整的transformer类似MPL的基线DeiT-B/ResMLP-B24 0.3%/1.1%。PoolFormer的有效性验证了我们的假设,并促使我们提出“MetaFormer”的概念,这是一种从transformer抽象而来的通用体系结构,但不指定token混合器。基于大量的实验,我们认为MetaFormer是最近在视觉任务上取得更好结果的关键因素。这项工作需要未来更多致力于改进MetaFormer的研究,而不是专注于Token混合器模块。此外,我们建议的PoolFormer可以作为未来MetaFormer架构设计的开始基线。
问题
- 特定的token混合模块(tokens mixer)是不必要的
- 基于注意力的transformer参数量太大,太过冗余
- transformer的通用体系结构对模型的性能更加重要,而不是特定的token mixer
方法
1. MetaFormer
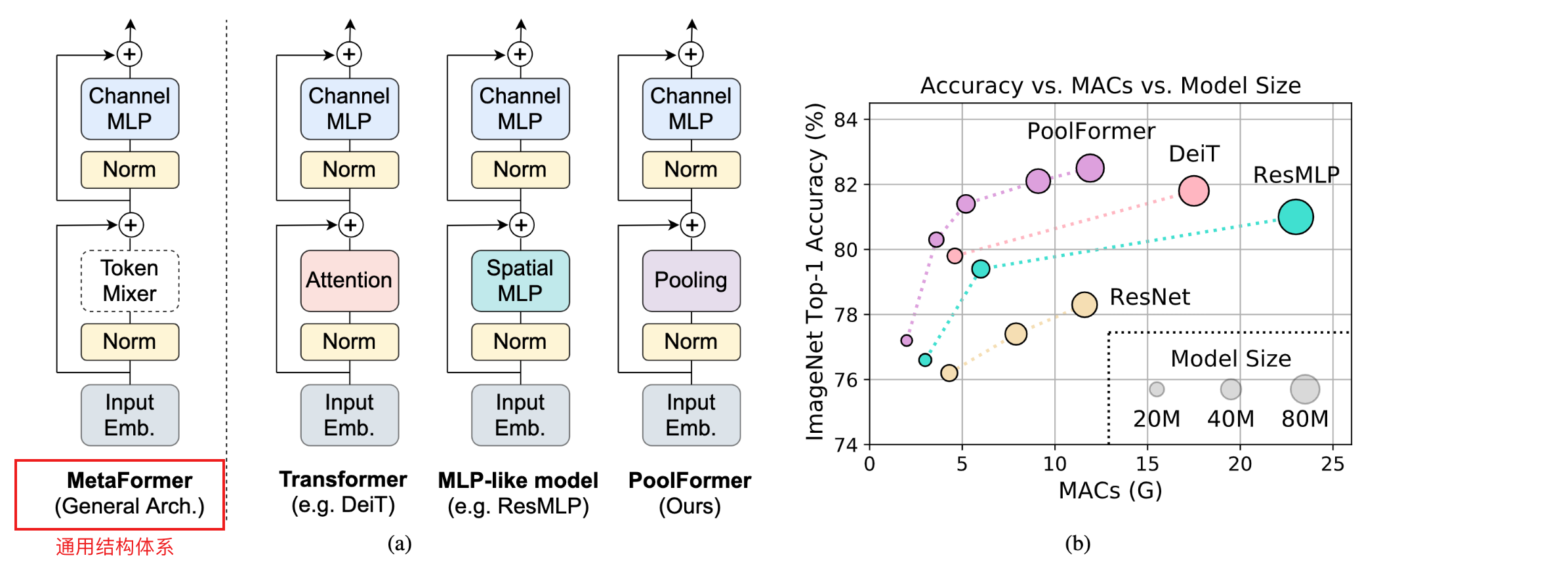
-
首先对输入input作处理,进行input embedding,例如ViTs的patch embedding

-
第一个子模块主要包括一个token mixer来交流token间的信息,通用表达式如下,TokenMixer可以是Attention可以是Spatial MLP可以是Pooling等等,主要的作用是混合token的信息

-
第二个子模块主要由具有非线性激活层的双层MLP组成,通用表达式如下

2. PoolFormer

- 特意选择了池化操作符作为token mixer,pooling没有可学习的参数,它只是让每个token能平均地聚合其附近的token,以此来验证是MetaFormer这套通用体系结构在发挥作用,而不是多样的token mixer
- 总所周知的是,自注意力和空间MLP的计算复杂度是token的平方倍,更不用说长序列;相反的,在没有任何可学习参数的情况下,pooling仅需线性复杂度的计算量
- 采用层级结构,类似CNN的四阶段的
实验

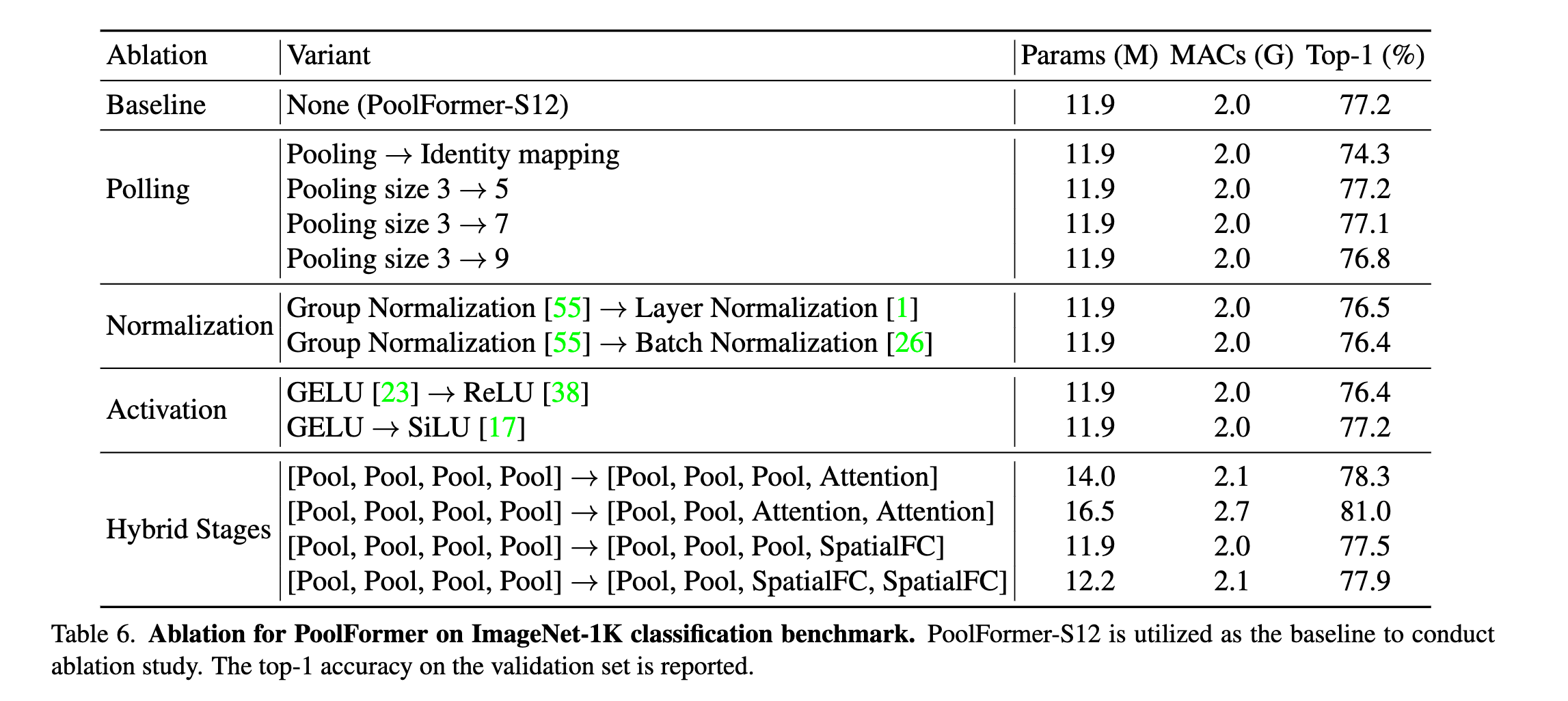
总结
- 这篇文章证明了transformer中真正有效的不是attention里面的token mixer,而是这一套体系结构
- 这篇文章用一个简单的pooling取代了最耗时的attention,表现却非常的好。
- 文章的实验可以看出,pool+attention的方案效果是最好的,在metaformer的体系结构下,组合Pooling与其他token mixer技术可能是一个提升模型性能的有价值的研究方向。














 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









