







What is truly responsible for the success of the transformers and their variants?
答案:通用架构,即MetaFormer。
MetaFormer is Actually What You Need for Vision
目录
Sea AI Lab 与新加坡国立大学共同定义 MetaFormer:
ViT编码器有两个主要组件:
- 第一个是基于注意力的组件,处理混合输入标记的信息;
- 第二个组件包含MLP,具有典型扩展-压缩结构。
历史上注意力模块一直被认为是Transformer能力的核心。出于这个原因大多数研究人员都专注于如何改进注意力模块。尽管如此最近的工作已经证明了 MLP 的能力以及实现可对比结果的能力。这方面引起了人们的怀疑,即 Self-attention 模块并不是所需要的全部。
- 继2017年论文:Attention Is All You Need
- 本次阅读的论文提出了新观点:MetaFormer is Actually What You Need for Vision
现有痛点:
- self-attention and spatial MLP has computational complexity quadratic to the number of tokens to mix.
- spatial MLPs bring much more parameters when handling longer sequences.
Sea AI Lab 与新加坡国立大学共同定义 MetaFormer:
- 假设与特定的注意力模块相比,通用的 Transformer 架构更为基础。
- 为了证明这一点,用“非常简单”的非参数空间平均池化层替换了注意力模块,并在不同的计算机视觉任务上取得了有竞争力的结果,例如图像分类、对象检测、实例分割和语义分割。
- 该模型被命名为PoolFormer,并在性能、参数数量和 MAC(乘积和累加)方面与经典的 Transformer(例如 DeiT)和 MLP-like(例如 ResMLP)模型进行了比较。
- 结果表明这个模型能够在多个视觉任务中达到很好的表现,比如在ImageNet1K数据集中,能够达到82.1%的准确率,超过DeiT-B(Transformer架构)和ResMLP-B24(MLP架构)的同时还能够大幅减小参数量。
核心
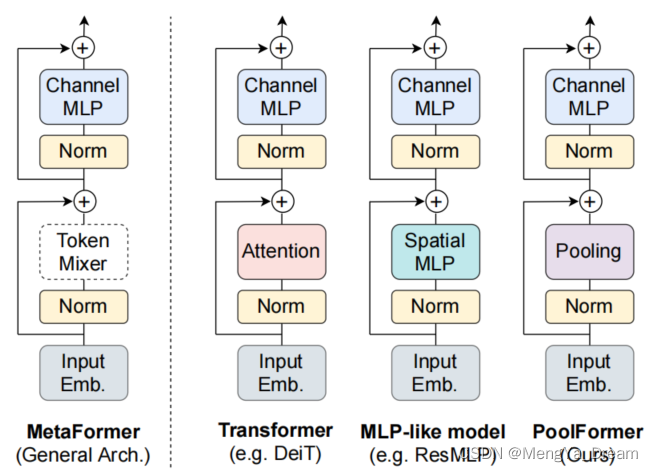
MetaFormer :
- Transformer的通用架构(不指定token mixer)
- The key player in achieving superior results for recent transformer and MLP-like models on vision tasks.
-
compared with specifific token mixers, MetaFormer is more essential for the model to achieve competitive performance .
Token mixer: mixing information among tokens
- 通常普遍认为基于Self-attention的token mixer对Transformer贡献最大。
- 可以利用attention/spatial MLP作为token mixer。
- 一些token mixer可以混合通道,如attention
文章认为这部分的建模能力主要来自于架构,而不是特定的token mixer。
强调Transformer架构的重要性!!!!!!
PoolFormer:
- Pooling: 简单非参数Pooling作为token mixer,得到了可竞争性的效果
- replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing.
- “非常简单”的非参数空间平均池化层替换了注意力模块。
-
It just makes each token averagely aggregate its nearby token features.
-
没有可学习的参数,只是简单将每个token平均的聚合到邻近的token features.
-
自注意力和spatial MLPs的计算复杂度都是和token的数量成平方比,因此自注意力和spatial MLPs通常只能处理几百个token, 而池化操作的复杂度和token的数量是呈线性比的,并且不需要任何可学习的参数,因此使用池化操作作为token mixer得到PoolFormer模块,网络结构如下图,使用了和大多数CNN网络一样的多阶段结构:

- 在此架构中,输入首先由补丁嵌入处理,类似于原始 ViT 实现,由n=C1卷积滤波器强制执行,具有 7×7 窗口和步长值为 4,产生维度为C1 x H的张量/4 x 宽/4。然后将输出传递给一系列 PoolFormer 块。在 PoolFormer 中,注意力模块被一个stride=1的池化块代替,它执行平均池化(简单地使每个token平均聚合到其附近的令牌特征)。在跳过连接之后,第二个块由一个两层 MLP 组成,与原始 Transformer 编码器一样。
- 重复整个过程,构建4个阶段的层次结构,通过池化将图像的原始高度和宽度压缩到H/32和W/32。根据嵌入尺寸(小型或中型),即根据四个嵌入尺寸(C1、C2、C3、C4)定义了两种不同类型的配置。为了更好地理解上图,假设总共有L=12 个PoolFormer 块,阶段 1、2 和 4 将包含L/6=2 个PoolFormer 块,而阶段 3 将包含L/2=6个块。经过消融研究,作者决定使用 Group Normalization 作为归一化技术,GeLu 作为激活函数。
- PoolFormer总共有四个阶段,token的数量分别是
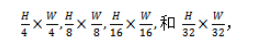
- H和W分别代表输入图片的高度和宽度,Pooling操作代替了Transformer中的self-attention,得到PoolFormer模块,如果总共有L个PoolFormer模块,那么每个阶段的PoolFormer数量分别是L/6,L/6,L/2,L/6个。
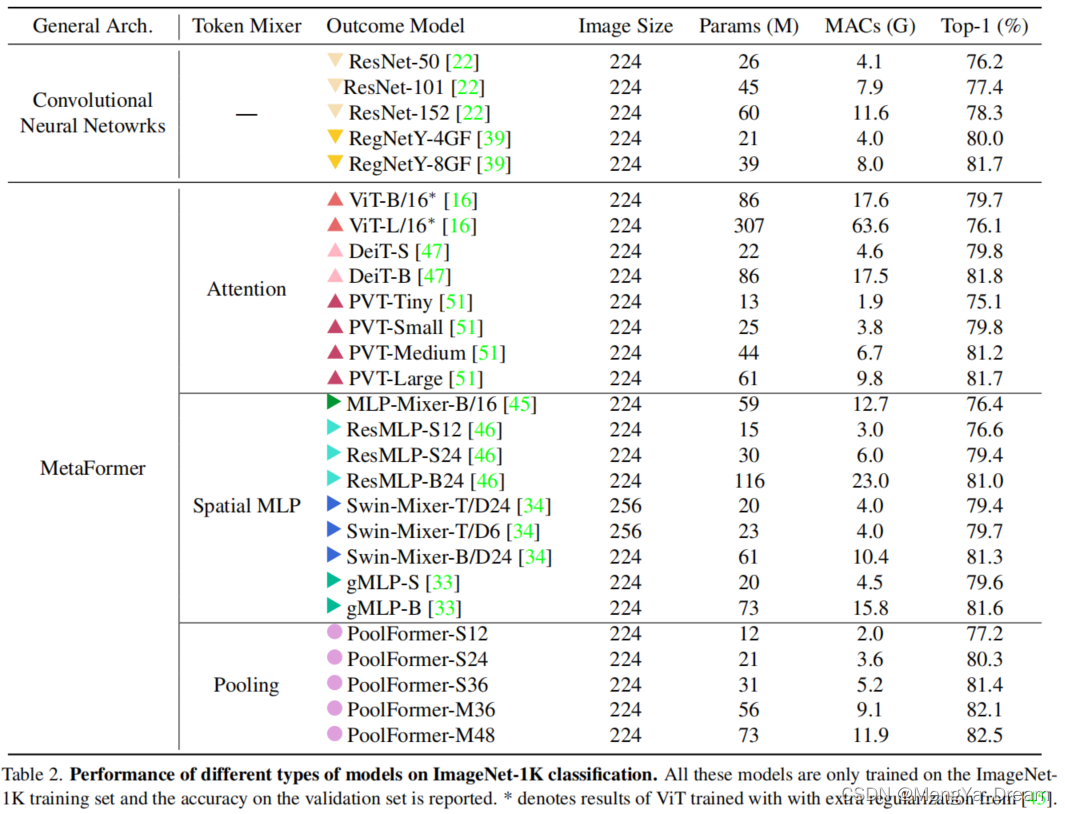
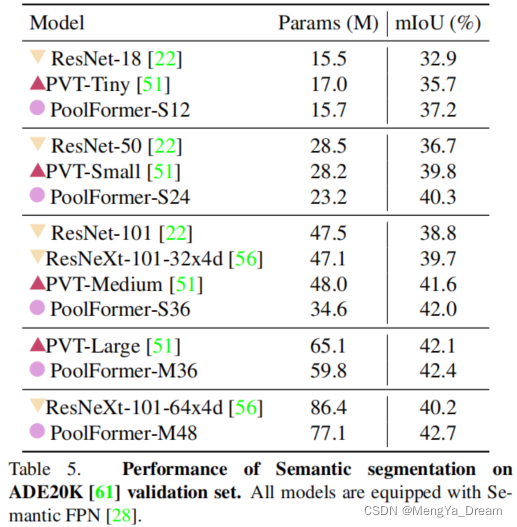
这种非常简单的实现结果令人惊讶。对于图像分类任务,在 ImageNet-1K 数据集上进行测试,PoolFormer 达到了 82.1% 的 top-1 准确率,超过了经典的 Transformer 实现,尤其是 DeiT 0.3%,参数减少了 35%,MAC 减少了 48%,并且类似于 MLP ResMLP 等实现减少了 1.1%,参数减少了 52%,MAC 减少了 60%。在对象检测、实例分割和语义分割任务中表现出类似的性能。
实验结果
图像分类

目标检测

语义分割
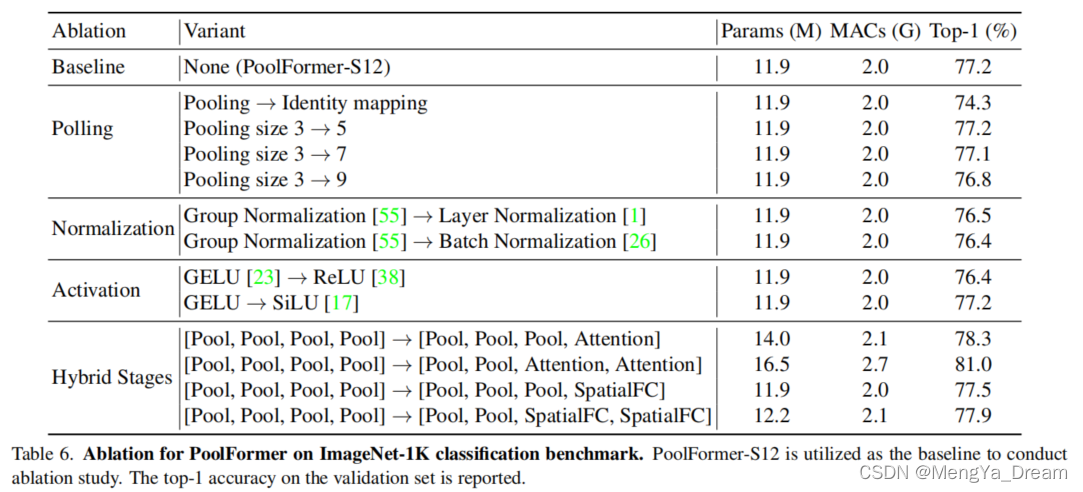
消融实验
【基础知识】Pooling 层主要的作用是下采样,通过去掉 Feature Map 中不重要的样本,进一步减少参数数量。通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
除了 Max Pooing 之外,常用的还有 Average Pooling ——取各样本的平均值。
对于深度为D的 Feature Map,各层独立做 Pooling,因此 Pooling 后的深度仍然为D。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。















 90
90











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











