






1 介绍
transformer被提出以来,有许多研究认为transformer的优越性能应当归功于token mixer部分。例如原始的transformer是使用attention注意力进行token间的混合。后来有研究发现,将原始transformer的attention部分更换为Spatial MLP,同时其他部分不变,同样能够取得很好的效果,典型的模型有ResMLP。本文则在token mixer部分采用一种十分简单的池化结构,形成一个新的模型PoolFormer,在多种视觉任务上能够取得具有竞争力的性能。并且本文证实,transformer模型的成功与架构有关而非attention,文中将这种具有token mixer和Channel MLP结构的模型抽象为一种架构,称为MetaFormer。原始transformer、类MLP model以及本文的PoolFormer都是MetaFormer的几种特殊结构。
2 相关工作
transformer首先被用于翻译任务,取得很好的性能,随后在各种NLP任务中迅速流行起来。受transformer在NLP中的成功启发,许多研究人员将注意力机制和transformer应用于视觉任务。Chen等人介绍了iGPT,其中transformer被训练为自动回归预测图像上的像素,用于自监督学习。Dosovitskiy等人提出了将硬补丁嵌入作为输入的视觉转换器(ViT)。研究结果表明,在监督图像分类任务中,在大型适当数据集(具有3亿张图像的JFT数据集)上预训练的ViT可以获得优异的性能。DeiT和T2T-ViT进一步证明,仅在ImageNet-1K(约130万张图像)上从头开始预训练的ViT可以实现有希望的性能。许多工作都集中在通过移位窗口、相对位置编码、细化注意力图或结合卷积等来改进transformer的token mixer方法。除了基于注意力的token mixer之外,仅采用MLP作为token mixer仍然可以获得有竞争力的性能。这一发现挑战了基于注意力的token mixer的主导地位。
本文研究了一个根本问题:什么才是transformer及其变体成功的真正原因?本文的答案是通用架构,即MetaFormer。本文利用池作为基本的token mixer来探索MetaFormer的效果。
3 方法
3.1 MetaFormer
MetaFormer是一种通用架构,其中不指定token mixer,而模型其他部分与transformer保持相同。输入首先通过输入embedding进行处理。
将通过重复的MetaFormer块运算,每个块包括两个具有残差结构的子块。
第一子块主要包含一个token mixer,用于在token之间传递信息,该子块可以表示为
其中Norm(·)表示归一化,如BN或LN;TokenMixer(·)是指一个主要用于混合token信息的模块。在最近的ViT模型中,它是通过各种注意力机制实现的,或者在类MLP的模型中通过空间MLP实现。token mixer的主要功能是传递token信息,一些token mixer也可以混合信道,如注意力。
第二子块主要由具有非线性激活的双层MLP组成,
MetaFormer的实例化。MetaFormer描述了一种通用架构,通过指定token mixer的具体设计,可以获得不同的模型。如图1(a)所示,如果将token mixer指定为注意力或spatial MLP,则MetaFormer将分别成为一个transformer或类似MLP的模型。
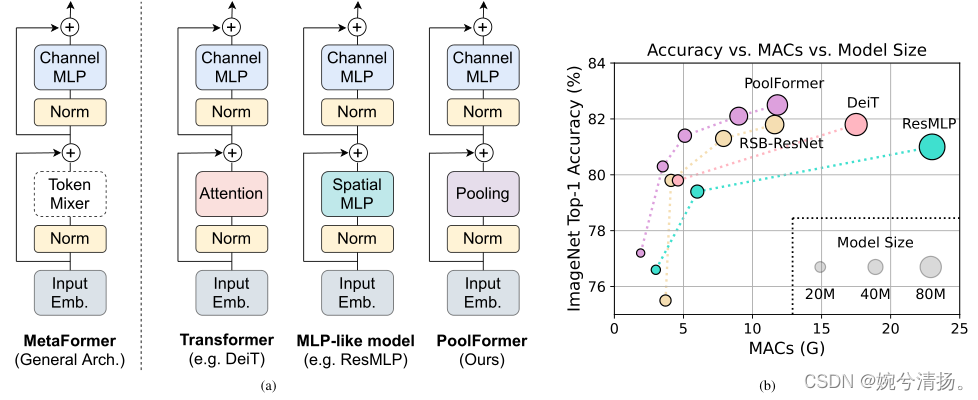
3.2 PoolFormer
本文认为MetaFormer通用架构对最近的transformer和类似MLP的模型的成功贡献很大。为了证明这一点,本节使用一个简单的pooling操作作为token mixer。该算子没有可学习的参数,它只是使每个token平均聚合其附近的token特征。
由于这项工作是针对视觉任务的,我们假设输入是通道优先的数据格式,即。
pooling操作可以表示为
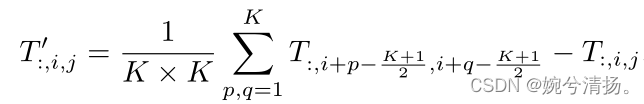
其中K表示pool的尺寸,公式中减T操作是因为模型架构中含有残差结构,因此要减去残差结构带来的+T操作。
伪代码如下:

自注意力机制和spatial MLP的计算复杂度与要混合的token数量成平方关系。且spatial MLP在处理较长序列时具有更多的参数。因此,自注意力机制和spatial MLP通常只能处理数百个token。而本文提出的pooling操作复杂度与序列长度呈线性。
PoolFormer的整体架构如图,从图中可以看出,整个模型有四个部分,假设整个模型共有L个PoolFormer Blocks,第一、二、四部分设置L/6个PoolFormer Blocks,第三部分设置L/2个PoolFormer Blocks。四个部分具有不同的token尺寸。
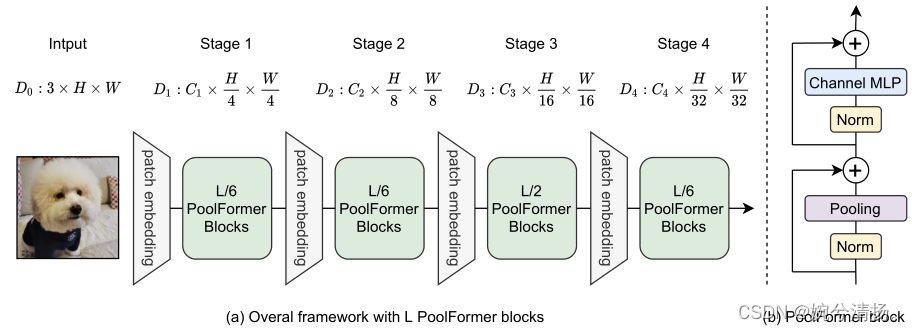
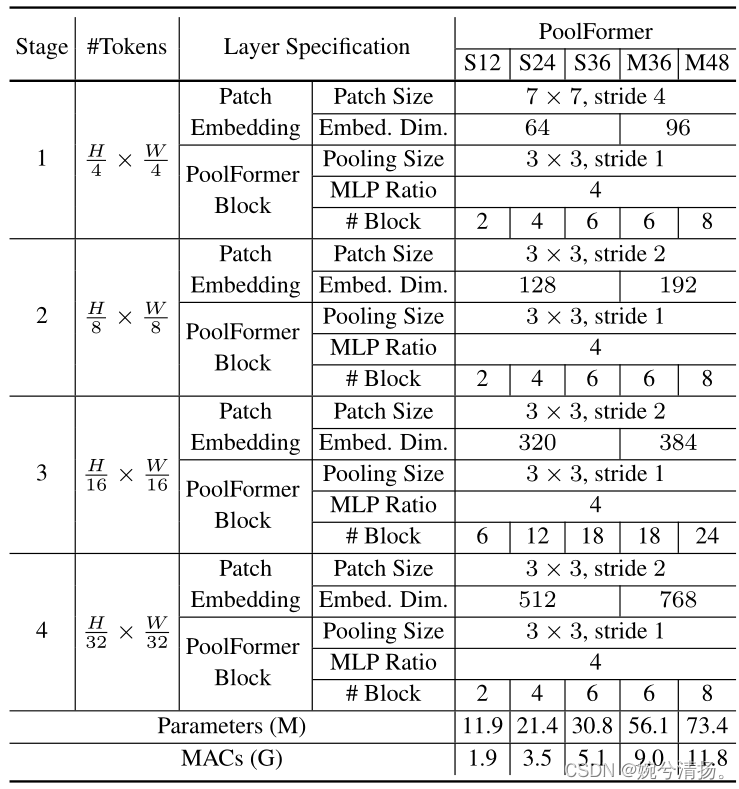
作者设置了五种不同大小的PoolFormer(S12,S24,S36,M36,M48)。五种模型的各阶段尺寸如下表所示。MACs(Multiply–Accumulate Operations):乘加累积操作数,常常被人们与FLOPs概念混淆。实际上1MACs包含一个乘法操作与一个加法操作,大约包含2FLOPs。通常MACs与FLOPs存在一个2倍的关系。
4 实验
4.1 图像分类
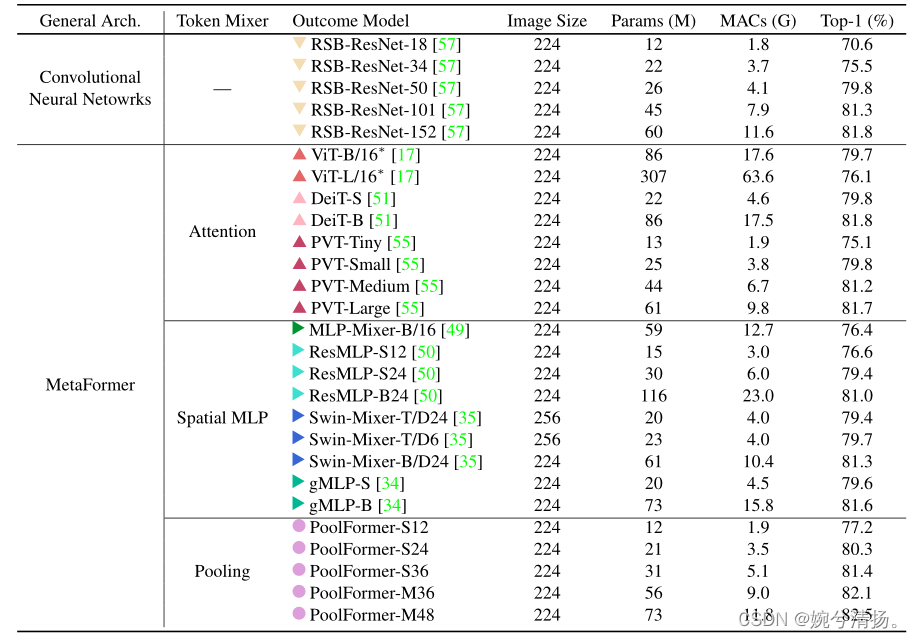
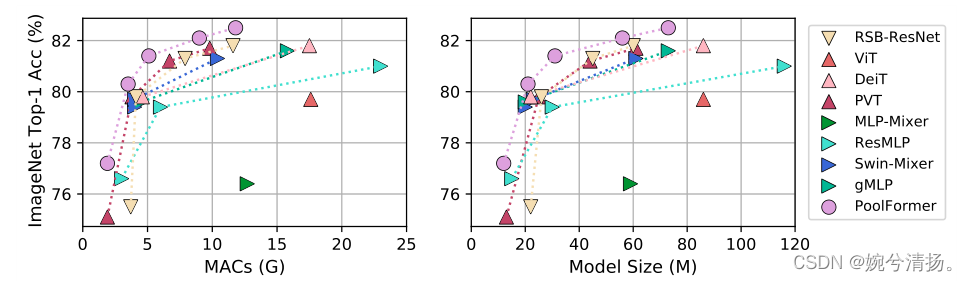
pooling 操作使每个 token 都能从其邻近的 token 中平均的抽取特征,可以看做是最基本的 token mixing 方式,但 PoolFormer 仍然取得了很好的效果。
 4.2 目标检测与实例分割
4.2 目标检测与实例分割
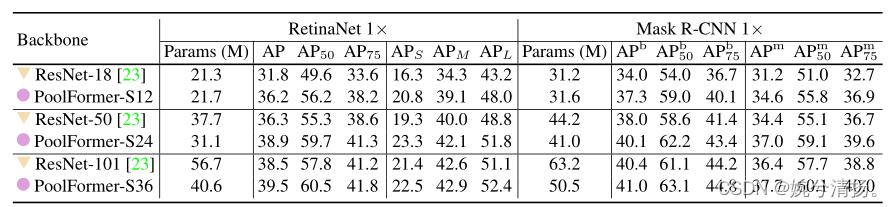
PoolFormer被用作两种标准检测器的主干,即RetinaNet[32]和Mask R-CNN[22]。配备了用于物体检测的RetinaNet,基于PoolFormer的模型始终优于可比的ResNet模型。例如,PoolFormer-S12实现了36.2个AP,大大超过了ResNet-18(31.8个AP)。对于基于Mask R-CNN的模型,在目标检测和实例分割方面也观察到了类似的结果。例如,PoolFormer-S12在很大程度上超过了ResNet-18(边界框AP 37.3 vs 34.0,掩码AP 34.6 vs 31.2)。总之在COCO数据集上的目标检测和实例分割方,PoolFormer实现了有竞争力的性能。
4.3 语义分割
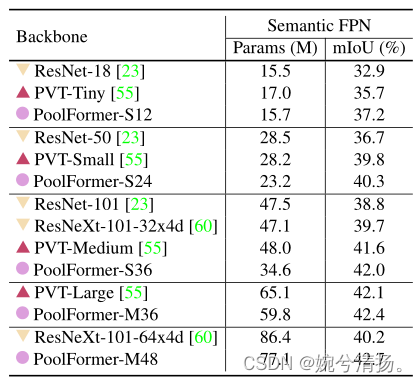
基于PoolFormer的模型始终优于基于CNN的ResNet和ResNeXt以及基于transformer的PVT的backbone模型。
4.4 消融实验
消融实验在ImageNet-1K上进行。将从以下方面进行消融实验。
token mixers。作者首先使用恒等映射来代替 pooling,发现仍能达到 74.3% 的top-1 acc,证明了作者认为的 Transformer 的结构的重要性。
再将池化替换为每个块的全局随机矩阵WR∈RN×N。矩阵用区间[0,1)上均匀分布的随机值初始化,然后利用Softmax对每一行进行归一化。该模型仍然可以获得75.8%的准确率,比恒等映射高1.5%的性能。这表明,即使在随机token混合的情况下,MetaFormer仍然具有很好的性能。
最后对不同 pooling size 做了实验,当使用 3,5,7 的时候,效果都差不多。使用 9 的时候,性能下降了 0.5%,所以,作者使用了 3。
归一化。将层归一化LN改为修改的层归一化(MLN),MLN计算沿token和信道维度的平均值和方差,而在普通层归一化中仅计算信道维度的平均值和方差。通过实验结果发现PoolFormer使用MLN效果更好,比层归一化或批归一化高0.7%-0.8%。因此,MLN被设置为PoolFormer的默认归一化方式。当去除归一化时,模型不能很好地训练收敛,其性能急剧下降到只有46.1%。
激活函数。将GELU更改为ReLU或SiLU。当采用ReLU进行激活时,观察到0.8%的明显性能下降。对于SiLU,其性能与GELU几乎相同。因此,文中仍然采用GELU作为默认激活函数。
其他部分。缺少残差和channel MLP,该模型不能收敛,仅达到0.1%/5.7%的精度,证明了这些部分的必要性。
混合。前几阶段使用具有池化的MetaFormer以处理长序列,并在后面阶段使用基于注意力或spatial MLP的mixer。这种设计仅使用16.5M个参数和2.6G MAC就实现了81.0%的准确率。作为比较,ResMLP-B24需要7.0×参数(116M)和8.8×MAC(23.0G)才能达到相同的精度。这些结果表明,将池化与MetaFormer的其他token mixer相结合可能是进一步提高性能的方向。

5 结论和未来工作
本文主要证明了transformer结构起作用的是整体架构而非注意力机制,抽象出了MetaFormer的整体架构,设计了一种PoolFormer的简单结构,在许多视觉任务上取得了具有竞争性的成绩,同时也证明了前文的假设。
未来将在更多不同的学习环境下进一步评估PoolFormer,如自我监督学习和迁移学习。希望本文工作能够激励未来更多的研究,致力于改进基础架构MetaFormer,而不是过于关注token mixer模块。















 6166
6166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









