






代码:
%% 初始化数据
clc
clear
close all
%% 导入数据
data = xlsread('数据集.xlsx','Sheet1','A1:F100');%导入数据库
%% 划分训练集和测试集
TE= randperm(100);%将数据打乱,重新排序;
PN = data(TE(1: 80), 1: 5)';%划分训练集输入
TN = data(TE(1: 80), 6)';%划分训练集输出
PM = data(TE(81: end), 1: 5)';%划分测试集输入
TM = data(TE(81: end), 6)';%划分测试集输出
%% 数据归一化
[pn, ps_input] = mapminmax(PN, 0, 1);%归一化到(0,1)
pn=pn';
pm = mapminmax('apply', PM, ps_input);%引用结构体,保持归一化方法一致;
pm=pm';
[tn, ps_output] = mapminmax(TN, 0, 1);
tn=tn';
%% 模型参数设置及训练模型
trees = 100; % 决策树数目
leaf = 5; % 最小叶子数
OOBPrediction = 'on'; % 打开误差图
OOBPredictorImportance = 'on'; % 计算特征重要性
Method = 'regression'; % 选择回归或分类
net = TreeBagger(trees, pn, tn, 'OOBPredictorImportance', OOBPredictorImportance,...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
importance = net.OOBPermutedPredictorDeltaError; % 重要性
%% 仿真测试
pyuce = predict(net, pm );
%% 数据反归一化
Pyuce = mapminmax('reverse', pyuce, ps_output);
Pyuce =Pyuce';
%% 绘图
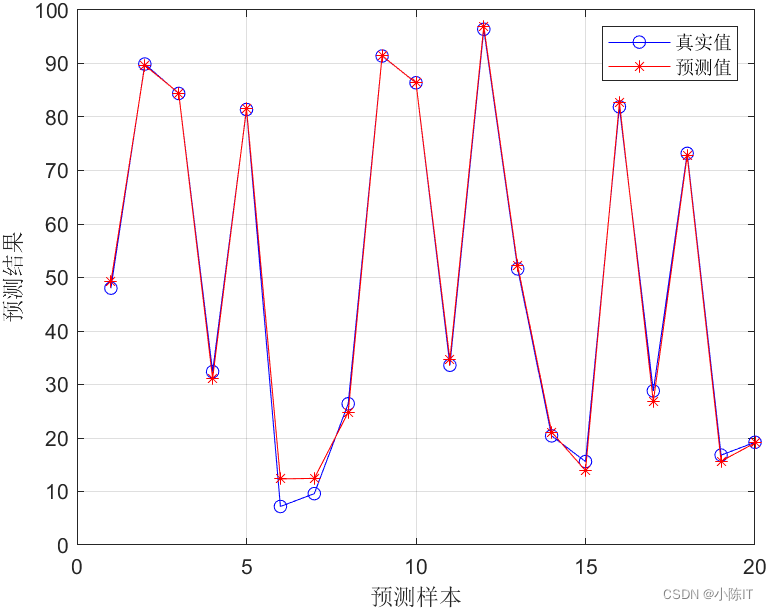
figure %画图真实值与预测值对比图
plot(TM,'bo-')
hold on
plot(Pyuce,'r*-')
hold on
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
grid on
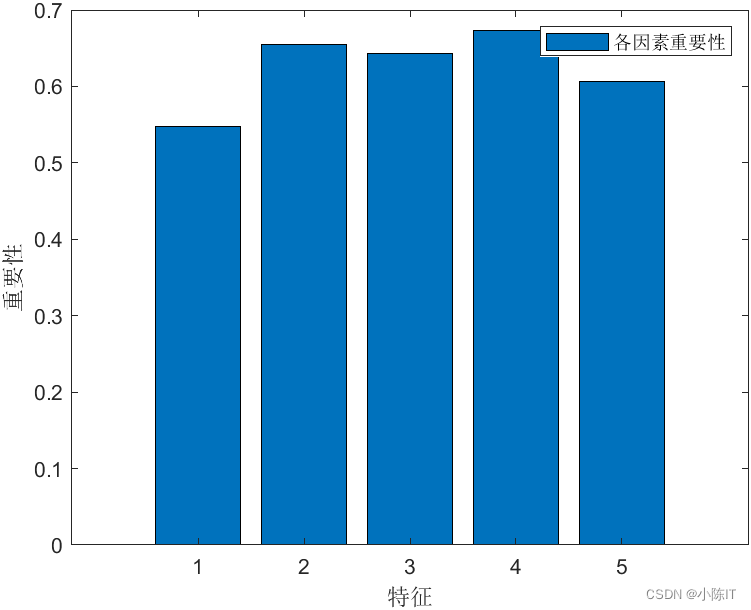
figure % 绘制特征重要性图
bar(importance)
legend('各因素重要性')
xlabel('特征')
ylabel('重要性')
%% 相关指标计算
error=Pyuce-TM;
[~,len]=size(TM);
R2=1-sum((TM-Pyuce).^2)/sum((mean(TM)-TM).^2);%相关性系数
MSE=error*error'/len;%均方误差
RMSE=MSE^(1/2);%均方根误差
disp(['测试集数据的MSE为:', num2str(MSE)])
disp(['测试集数据的MBE为:', num2str(RMSE)])
disp(['测试集数据的R2为:', num2str(R2)])
数据部分截图
结果:
如有需要数据和代码压缩包请在评论区发邮箱留言,一般一天之内会发送,记得关注和点赞哦!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









