







Towards Accurate One-Stage Object Detection with AP-Loss
- 作者认为在one-stage的detection中,detection和classification任务之间的gap影响了模型的performance,于是把classification task改为ranking task,把classification loss 改为ranking loss,并采用APloss作为target loss
- 由于APloss是non-convex和non-differentiable,需要采取特殊的方法:
- 用SVM来学习APloss
- 修改loss为APloss的某个upper bound
- approximate gradient methods
- 论文提出的方法:改classification 为 ranking task,并使用一种error-driven的算法来optimize AP-loss,这里的error-driven的算法基于1957年提出的Perceptron Learning Algorithm,即采用sign函数作为activation function
我只是个莫得感情的论文搬运机器大意上是说原来的模型每个bbox输出k+1维向量而文章提出的模型只输出一个标量但是会重复k遍,而label也改为标量形式:
In our framework, instead of one box with K + 1 dimensional score predictions, we replicate each box bi for K times to obtain bik where k = 1, · · · , K, and the k-th box is responsible for the k-th class. Each box bik will be assigned a label tik ∈ {−1, 0, 1} through the same IoU strategy (label −1 for not counted into the ranking loss). Therefore, in the training and testing phase, the detector will predict only one scalar score sik for each box bik.

- 下面讲一下ap-loss的算法:
- 既然anchor box的输出是一个标量(先不管重复输出),可以设为
b
i
b_i
bi,算得一个
x
i
j
x_{ij}
xij为两个anchor box之间差的度量,这里
s
(
b
i
;
θ
)
s(b_i;\theta)
s(bi;θ)指模型参数为
θ
\theta
θ的时候第i个anchor box的输出score:
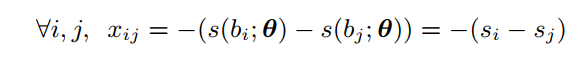
- 同时需对label做类似的转换,表示
t
i
=
1
,
t
j
=
0
t_i=1,t_j=0
ti=1,tj=0时
y
i
j
=
1
y_{ij}=1
yij=1否则为0,这里t就是label
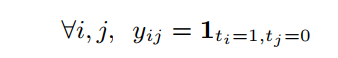
- primary-loss为:
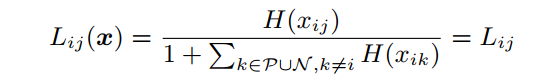 其中
H
(
x
i
j
)
H(x_{ij})
H(xij)即前文所提的符号函数:
其中
H
(
x
i
j
)
H(x_{ij})
H(xij)即前文所提的符号函数: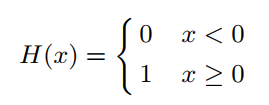
- AP-loss为:
 其中
r
a
n
k
+
(
i
)
rank^+(i)
rank+(i)为
s
i
s_i
si在所有正样本中的排序值而
r
a
n
k
(
i
)
rank(i)
rank(i)为
s
i
s_i
si在所有有效样本中的排序值,
P
=
{
i
∣
t
i
=
1
}
,
N
=
{
i
∣
t
i
=
0
}
P = \left\{ i|t_i = 1\right\}, N = \left\{i|t_i = 0\right\}
P={i∣ti=1},N={i∣ti=0},L and y are vector form for all
L
i
j
L_{ij}
Lij and
y
i
j
y_{ij}
yij respectively, <, >means dot-product of two input vectors.注意 x,y,L都是d维向量,d为有效输出的anchor数。
其中
r
a
n
k
+
(
i
)
rank^+(i)
rank+(i)为
s
i
s_i
si在所有正样本中的排序值而
r
a
n
k
(
i
)
rank(i)
rank(i)为
s
i
s_i
si在所有有效样本中的排序值,
P
=
{
i
∣
t
i
=
1
}
,
N
=
{
i
∣
t
i
=
0
}
P = \left\{ i|t_i = 1\right\}, N = \left\{i|t_i = 0\right\}
P={i∣ti=1},N={i∣ti=0},L and y are vector form for all
L
i
j
L_{ij}
Lij and
y
i
j
y_{ij}
yij respectively, <, >means dot-product of two input vectors.注意 x,y,L都是d维向量,d为有效输出的anchor数。 - 所以optimize的目标为为
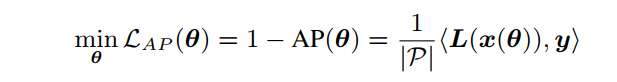 但这里的L是不可导的,需要采用特殊的方法
但这里的L是不可导的,需要采用特殊的方法 - Perceptron Learning Algorithm是这样的:
Suppose x i j x_{ij} xij is the input and L i j L_{ij} Lij is the current output, the update for x i j x_{ij} xij is thus ∆ x i j = L i j ∗ − L i j ∆x_{ij} = L^*_{ij} − L_{ij} ∆xij=Lij∗−Lij where L i j ∗ L^*_{ij} Lij∗ is the desired output.
- 而论文的error-driven算法是这样的:
∆ x i j = − L i j ⋅ y i j ∆x_{ij} = −L_{ij} · y_{ij} ∆xij=−Lij⋅yij
从loss的形式可以看出,当L·y为0时有最小的loss,而有两种情况,一种y为0,则L不论多少都没关系此时不更新,一种y为1则L期望为0,所以采取这样的更新形式
8.方向传播对于
s
i
s_i
si的gradient的形式是这样的: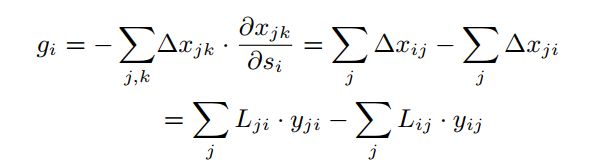 实践中即设一个
x
i
j
x_{ij}
xij 的梯度为
−
∆
x
i
j
−∆x_{ij}
−∆xij,至于为什么是这种形式,论文中给出了推导,也不复杂,这里就不赘诉。
实践中即设一个
x
i
j
x_{ij}
xij 的梯度为
−
∆
x
i
j
−∆x_{ij}
−∆xij,至于为什么是这种形式,论文中给出了推导,也不复杂,这里就不赘诉。
训练细节:
- minibatch可以应用到AP-loss的ranking中
- 前期训练由于
s
i
s_i
si差距很小会导致较大的loss,训练不稳定,可以H(·)函数为
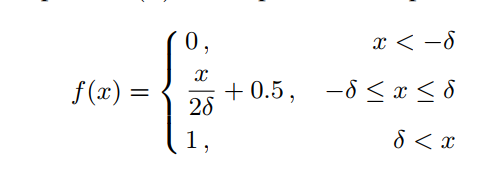
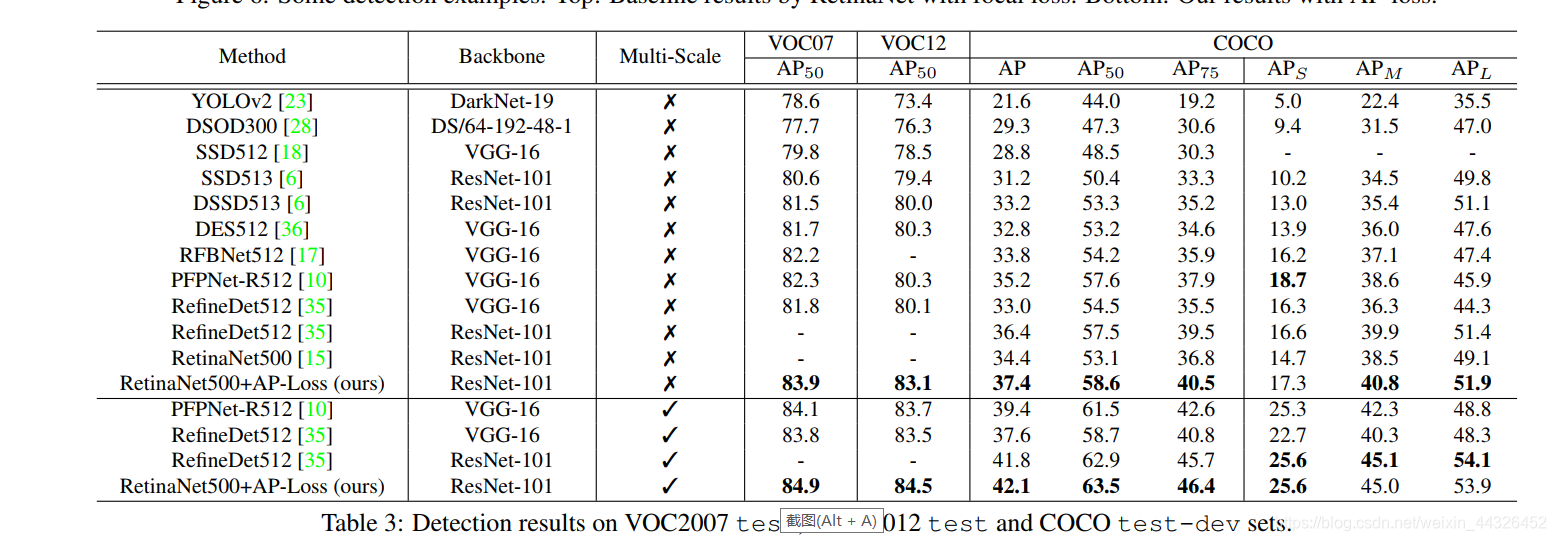
experiment
















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









