




 本文解读了一篇关于one-stage目标检测的论文,作者提出AP损失函数,解决了锚点不平衡问题,通过排序损失和误差驱动学习优化非凸AP。论文创新地将AP直接作为训练目标,有效改善了模型性能。
本文解读了一篇关于one-stage目标检测的论文,作者提出AP损失函数,解决了锚点不平衡问题,通过排序损失和误差驱动学习优化非凸AP。论文创新地将AP直接作为训练目标,有效改善了模型性能。
论文解读之:
Towards Accurate One-Stage Object Detection with AP-Loss
这篇论文是关于one-stage目标检测的一篇论文,作者通过提出一种AP损失,直接对评价指标构成的损失函数进行训练。

写在前面
在目标检测领域,有着两种主要的思路:One-stage与Two-stage。其中,one-stage的目标检测是同时进行目标的定位与识别,而two-stage是分为两步,首先生成一系列候选框,然后对其进行识别分类。one-stage方法包括YOLO、SSD等常见网络,而two-stage方法包括Faster RCNN等常见网络。
两种目标检测的思路各有利弊,one-stage的方法效率高,但是准确率不如two-stage。这篇文章的作者研究了one-stage的问题。在one-stage目标检测中,一个重要的问题就是锚点数量过大,导致了前背景极度不平衡。
在目标检测中,常用的评价指标包括mean AP、IoU等。其中AP是不可微的,且是非凸的,所以如果使用传统的梯度下降方法无法进行优化。所以之前的方法都是构造其他损失函数,而我们能不能把AP构造成能学习的损失函数呢?如果可以的话,从评价指标的角度看这样的学习更直接。
另外,还有一个很尴尬的情况,就是由于正负样本不均衡的原因,导致检测的结果很垃圾但是分类准确率依然很高,如下图所示:
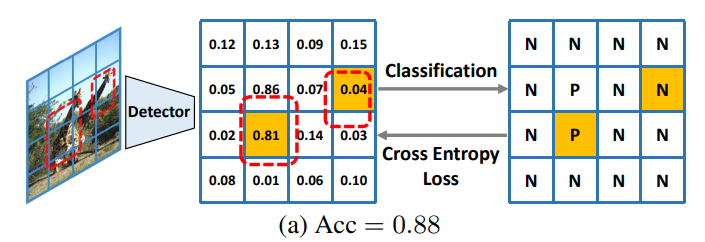
本文的作者提出了一种使用AP loss的学习方法,根据论文中的说法,本篇论文的贡献如下:
贡献
- 提出了一种新的one-stage目标检测框架,该框架采用排序损失来处理不平衡问题。
- 提出了一种误差驱动学习算法,通过理论和实验验证,该算法能够有效地优化不可微且非凸的基于AP的损失函数。
- 在不改变模型结构的情况下,对于不同类型的分类损失,文章提出的方法性能能达到先进水平。
作者主要提出了AP损失,并创造了学习这种不可微损失的学习方法。其中AP损失是通过将分类问题替换为排序问题设计出来的。所以理解本文主要分为两个部分:损失函数设计与训练方法。
AP损失函数
首先,在传统检测器特征提取后,每个anchor box将产生K+1维的得分,分别对应K个类别和背景。为了便于后面排序,作者将每个anchor box复制K个,每个anchor box在特征提取阶段仅得到一个得分,用于代表对应的某一个类的得分。
设 B B B为anchor box集合, b i b_i bi为第 i i i个anchor box。在检测器提取特征后,每一个anchor box得到一个得分 s i s_i si和一个二进制标签 t i t_i ti,这个标签指示这个anchor box是前景还是背景,前景取1,背景取0。
然后计算差分,将 s i s_i si转为 x i j x_{ij} xij,其中 θ \theta θ为特征提取过程中CNN的参数。
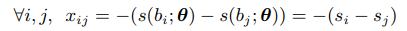
这个 x i j x_{ij} xij就指示了 s i s_i si的排序,如果 x i j > 0 x_{ij}>0 xij>0说明 s i s_i si排在 s j s_j sj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









