







卷积神经网络(CNN)主要由卷积层(Convolutional Layer)、池化层(Pooling Layer)、激活层(Activation Layer)和全连接层(Fully-connected Layer)组成。
-
卷积层(Convolutional Layer):卷积层是CNN的核心组成部分,其通过运用卷积核对输入进行卷积操作,提取特征和特征组合,形成新的特征。卷积层的参数主要是卷积核的大小、步长、填充方式。
-
池化层(Pooling Layer):池化层用于对卷积层提取的特征进行压缩和精简,以减小特征空间的大小,并减少参数数量,降低过拟合和计算负担。一般池化具有两种方式,最大值池化(max-pooling)和均值池化(average-pooling)。
-
激活层(Activation Layer):激活层主要对卷积和池化层的输出进行非线性变换,引入非线性因素,激活神经元,对网络的表达能力进行提升。其主要有几种常用激活函数,包括Sigmoid、ReLU、Tanh等。
-
全连接层(Fully-connected Layer):全连接层是将卷积层、池化层、激活层得到的特征图进行分类、识别和判别处理的最后一层。其主要工作是将特征图展开成向量,与权重矩阵进行全连接计算,并进行softmax归一化处理,来实现最终的分类目的。
CNN通过卷积、池化、非线性激活和全连接层以及其他一些辅助技术构成,可实现高效、准确、鲁棒的图像处理、分类和识别任务。
本文以手写数字识别为实例梳理一下卷积神经网络训练的流程。
1. 数据输入
import torch
import torchvision
from torchvision.transforms import ToTensor
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
train_ds = torchvision.datasets.MNIST('data/', train=True, transform=ToTensor(), download=True)
test_ds = torchvision.datasets.MNIST('data/', train=False, transform=ToTensor(), download=True)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=46)
imgs, labels = next(iter(train_dl)) # 创建生成器,并用next方法返回一个批次数据
print(imgs.shape) # 输出torch.Size([64, 1, 28, 28])
print(labels.shape) # 输出torch.Size([64])
从以上代码中可以看到,train_dl返回的图片数据是四维的,4个维度分别代表批次、通道数、高度和宽度(batch, channel,height, width),这正是PyTorch下卷积模型所需要的图片输入格式。
2. 创建卷积模型并训练
下面创建卷积模型来识别MNIST手写数据集。我们所创建的卷积模型先使用两个卷积层和两个池化层,然后将最后一个池化的输出展平为二维数据形式连接到全连接层,最后是输出层,中间的每一层都使用ReLU函数激活,输出层的输出张量长度为10,与类别数一致。代码如下:
class Model(nn.Module):
def _init__(self):
super().__init_()
self.convl = nn.Conv2d(1, 6, 5)# 初始化第一个卷积层
self.conv2 = nn.Conv2d(6, 16, 5)# 初始化第二个卷积层
self.liner_1 = nn.Linear(16 * 4 * 4, 256)# 初始化全连接层
self.liner_2 = nn.Linear(256, 10)# 初始化输出层
def forward(self, input):
# 调用第一个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv1(input)), 2)
# 调用第二个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv2(x)), 2)
# view ()方法将数据展平为二维形式
# torch.Size([64,16,4,4] )→torch.Size([64,16*4*4])
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.liner_1(x)) # 全连接层
x = self.liner_2(x) # 输出层
return x
下面逐行来看代码,在这个卷积模型的初始化方法中,首先初始化了2个卷积层和2个线性层。
self.convl = nn.Conv2d(1, 6, 5)# 初始化第一个卷积层
self.conv2 = nn.Conv2d(6, 16, 5)# 初始化第二个卷积层
self.liner_1 = nn.Linear(16 * 4 * 4, 256)# 初始化全连接层
self.liner_2 = nn.Linear(256, 10)# 初始化输出层
图片首先通过第一个卷积层,它的第一个参数in_channels代表输入的通道数,这里图片的通道数为1,因此in_channels是1;第二个参数out_channels代表输出的通道数,也就是卷积核的个数,每一个卷积核都会与前面一层进行卷积并输出一个特征层,因此这个卷积核的个数也就代表卷积层输出的特征层的厚度。这个数是一个超参数,我们自己来定义,这里设置为6;第三个参数为kernel_size,也就是卷积核的大小,一般设置为小的奇数值,如1、3、5、7等,我们设置为5。
第二个卷积层的输入通道数in_channels就是上一层的输出通道数,上一层卷积的out_channels为6,因此这里第一个参数为6;相比第一个卷积层6个卷积核,第二层卷积out_channels设置为16,这种递增的卷积核设置被证明可有效地提升卷积模型的拟合能力,这也符合第7章所说的通过卷积使得图像越来越小、越来越厚的目标。
第三行代码初始化了全连接层self.liner_1,全连接层只能接收二维数据(第一维是batch维),它的输入是将前面卷积层的输出展平后的二维数据,也就是说,除去batch维,其他3个维度(channel, height, width)展平,因此这一层的输入为上一层这3个维度的积(channel×height×width),在这里in_features是16×4×4,输出out_features设置为256。
第四行代码是输出层,输出层in_features是上一层输出out_features,也就是256,输出的out_features与类别数一致,这里共有10类,因此设置为10。
下面来看在forward前向传播中如何使用这些层:
# 调用第一个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv1(input)), 2)
# 调用第二个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv2(x)), 2)
# view ()方法将数据展平为二维形式
# torch.Size([64,16,4,4] )→torch.Size([64,16*4*4])
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.liner_1(x)) # 全连接层
x = self.liner_2(x) # 输出层
forward()方法中定义了模型的输入如何经过这些层进行前向传播。第一行代码中输入经第一个卷积层卷积、使用ReLU函数激活,然后通过最大池化。注意最大池化有一个参数kernel_size,代码中设置为2,这里等价于(2,2),也就是说,池化核的高和宽都为2,因此数据经过这个池化层时,高和宽都会变为原来的一半,此时数据集的形状为torch.Size([64, 6, 12,12]);第二行代码调用第二个卷积层和池化层,输出的数据集形状为torch.Size([64, 16, 4, 4]);第三行代码使用view()方法改变数据的形状,将图片的3个维度(channel, height, width)展平为一维(channel×height×width),然后就是全连接层,全连接仅需要激活即可,最后是输出层。
我们重点来看编码过程中如何确定输出的张量形状(shape属性),在上面定义模型中,view()方法将三维特征输出展平为channel×height×width,这就需要我们明确地知道经过两个卷积层和池化后数据集的形状。因为卷积核大小、填充方式和池化等均可影响最后输出的形状,可以通过论文A guide to convolution arithmetic for deep learning介绍的公式,利用输入大小、kernel_size、stride、padding等设置计算卷积后输出特征的形状大小。
为了简单,也可以在forward()方法中打印出某一层的shape属性,这样当在输入图像上调用模型时就可以打印出这一层输出的张量形状,代码如下:
# 此临时定义模型仅用于观察层输出的数据集形状,这部分代码不属于完整代码
class _Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
def forward(self, input):
x = torch.max_pool2d(torch.relu(self.conv1(input)), 2)
x = torch.max_pool2d(torch.relu(self.conv2(x)), 2)
print(x.size()) # 输出卷积部分的最后输出数据集形状
temp_model = _Model()# 初始化模型
# 在一个批次数据上调用此模型
temp_model(imgs)# 输出数据集形状为torch.Size([64,16,4, 4])
经过调用此模型,可以看到卷积部分最后的输出形状为torch.Size([64, 16, 4, 4]),这样就可以确定展平后第二维的数值为16×4×4,这是一个确认输出形状的小技巧,在编写模型代码时可以使用此方法确认某一层输出形状大小。确认之后再继续定义下面的层。
至此,我们的模型编写好了,可以初始化了。在初始化之前,让我们来看看如何将模型上传到显存使用显卡训练。使用显卡训练仅需要将模型和每一个批次的数据使用.to(device)方法上传到显存,这里的device是计算机当前可用的训练设备,使用如下代码可获取当前设备:
# 判断当前可用的device,如果显卡可用,就设置为cuda,否者设置为cpu
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
执行上面的代码,如果GPU可以用,将显示Using cuda device信息,否则将会显示Using cpu device信息。下面代码中我们仅需要将模型和每一个批次的数据使用.to(device)方法即可。
# 初始化模型,并使用.to()方法将其上传到device
# 如果GPU可以用,会上传到显存,如果device是 CPU,仍保留在内存
model = Model().to(device)# 初始化模型并设置设备
print(model)# 输出查看此模型实例
'''
Model(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(liner_1): Linear(in_features=256, out_features=256, bias=True)
(liner_2): Linear(in_features=256, out_features=10, bias=True)
)
'''
然后定义损失函数和优化器并进行训练,全部整合代码:
# -*- coding: UTF-8 -*-
import torch
import torchvision
from torchvision.transforms import ToTensor
from torch import nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
train_ds = torchvision.datasets.MNIST('data/', train=True, transform=ToTensor(), download=True)
test_ds = torchvision.datasets.MNIST('data/', train=False, transform=ToTensor(), download=True)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=46)
imgs, labels = next(iter(train_dl)) # 创建生成器,并用next方法返回一个批次数据
print(imgs.shape) # 输出torch.Size([64, 1, 28, 28])
print(labels.shape) # 输出torch.Size([64])
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 初始化第一个卷积层
self.conv2 = nn.Conv2d(6, 16, 5) # 初始化第二个卷积层
self.liner_1 = nn.Linear(16 * 4 * 4, 256) # 初始化全连接层
self.liner_2 = nn.Linear(256, 10) # 初始化输出层
def forward(self, input):
# 调用第一个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv1(input)), 2)
# 调用第二个卷积层和池化层
x = torch.max_pool2d(torch.relu(self.conv2(x)), 2)
# view ()方法将数据展平为二维形式
# torch.Size([64,16,4,4] )→torch.Size([64,16*4*4])
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.liner_1(x)) # 全连接层
x = self.liner_2(x) # 输出层
return x
# 此临时定义模型仅用于观察层输出的数据集形状,这部分代码不属于完整代码
class _Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
def forward(self, input):
x = torch.max_pool2d(torch.relu(self.conv1(input)), 2)
x = torch.max_pool2d(torch.relu(self.conv2(x)), 2)
print(x.size()) # 输出卷积部分的最后输出数据集形状
# temp_model = _Model() # 初始化模型
# temp_model = Model() # 初始化模型
# # 在一个批次数据上调用此模型
# temp_model(imgs) # 输出数据集形状为torch.Size ( [64,16,4, 4])
# 判断当前可用的device,如果显卡可用,就设置为cuda,否者设置为cpu
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 初始化模型,并使用.to()方法将其上传到device
# 如果GPU可以用,会上传到显存,如果device是 CPU,仍保留在内存
model = Model().to(device)# 初始化模型并设置设备
# model = temp_model.to(device)# 初始化模型并设置设备
print(model)# 输出查看此模型实例
'''
Model(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(liner_1): Linear(in_features=256, out_features=256, bias=True)
(liner_2): Linear(in_features=256, out_features=10, bias=True)
)
'''
loss_fn = nn.CrossEntropyLoss() # 初始化交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # 初始化优化器
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) #获取当前数据集样本总数量
num_batches = len(dataloader) #获取当前dataloader总批次数
# train_loss用于累计所有批次的损失之和,correct用于累计预测正确的样本总数
train_loss, correct = 0, 0
for x, y in dataloader:
#对dataloader进行迭代
x, y = x.to(device), y.to(device) #每一批次的数据设置为使用当前device
#进行预测,并计算一个批次的损失
pred = model(x)
loss = loss_fn(pred, y) #返回的是平均损失
#使用反向传播算法,根据损失优化模型参数
optimizer.zero_grad() #将模型参数的梯度先全部归零
loss.backward() #损失反向传播,计算模型参数梯度
optimizer.step() #根据梯度优化参数
with torch.no_grad():
#correct用于累计预测正确的样本总数
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# train_loss用于累计所有批次的损失之和
train_loss += loss.item()
# train_loss是所有批次的损失之和,所以计算全部样本的平均损失时需要除以总批次数
train_loss /= num_batches
#correct是预测正确的样本总数,若计算整个epoch总体正确率,需除以样本总数量
correct /= size
return train_loss, correct
def test(dataloader, model):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device),y.to(device)
pred = model(x)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
return test_loss, correct
train_ds = torchvision.datasets.MNIST('data/', train=True, transform=ToTensor(), download=True)
test_ds = torchvision.datasets.MNIST('data/', train=False, transform=ToTensor(), download=True)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=46)
epochs = 10 #一个epoch代表对全部数据训练一遍
train_loss = [] #每个epoch训练中训练数据集的平均损失被添加到此列表
train_acc = [] #每个epoch训练中训练数据集的平均正确率被添加到此列表
test_loss = [] #每个epoch训练中测试数据集的平均损失被添加到此列表
test_acc = [] # 每个epoch 训练中测试数据集的平均正确率被添加到此列表
for epoch in range(epochs):
#调用train()函数训练
epoch_loss, epoch_acc = train(train_dl, model, loss_fn, optimizer)
#调用test()函数测试
epoch_test_loss, epoch_test_acc = test(test_dl, model)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
#定义一个打印模板
template = ("epoch: {:2d}, train_loss: {:.5f}, train_acc: {:.1f}% ,test_loss: {:.5f}, test_acc: {:.1f}%")
#输出当前epoch 的训练集损失、训练集正确率、测试集损失、测试集正确率
print(template.format(epoch, epoch_loss, epoch_acc * 100, epoch_test_loss, epoch_test_acc * 100))
print("Done!")
先测试经过10个epoch训练,可以看到以下输出:
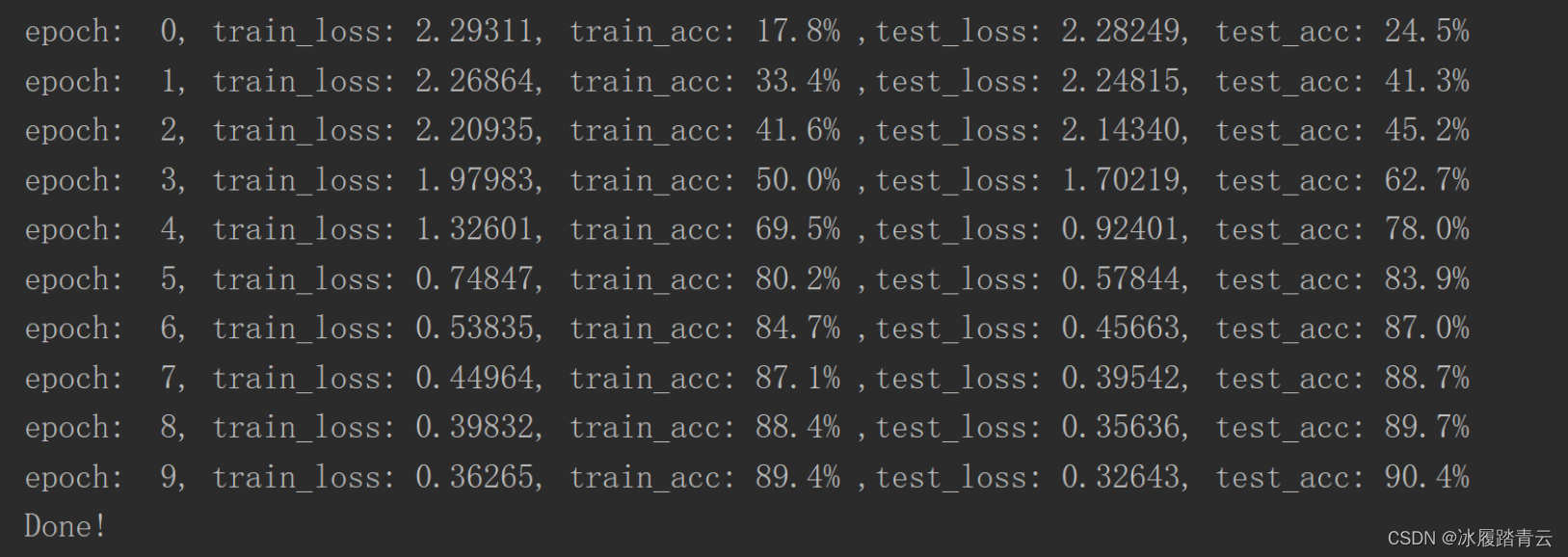
test_acc曲线仍然在保持着上升的趋势,说明我们还可以加epoch训练,再测试50个epoch:
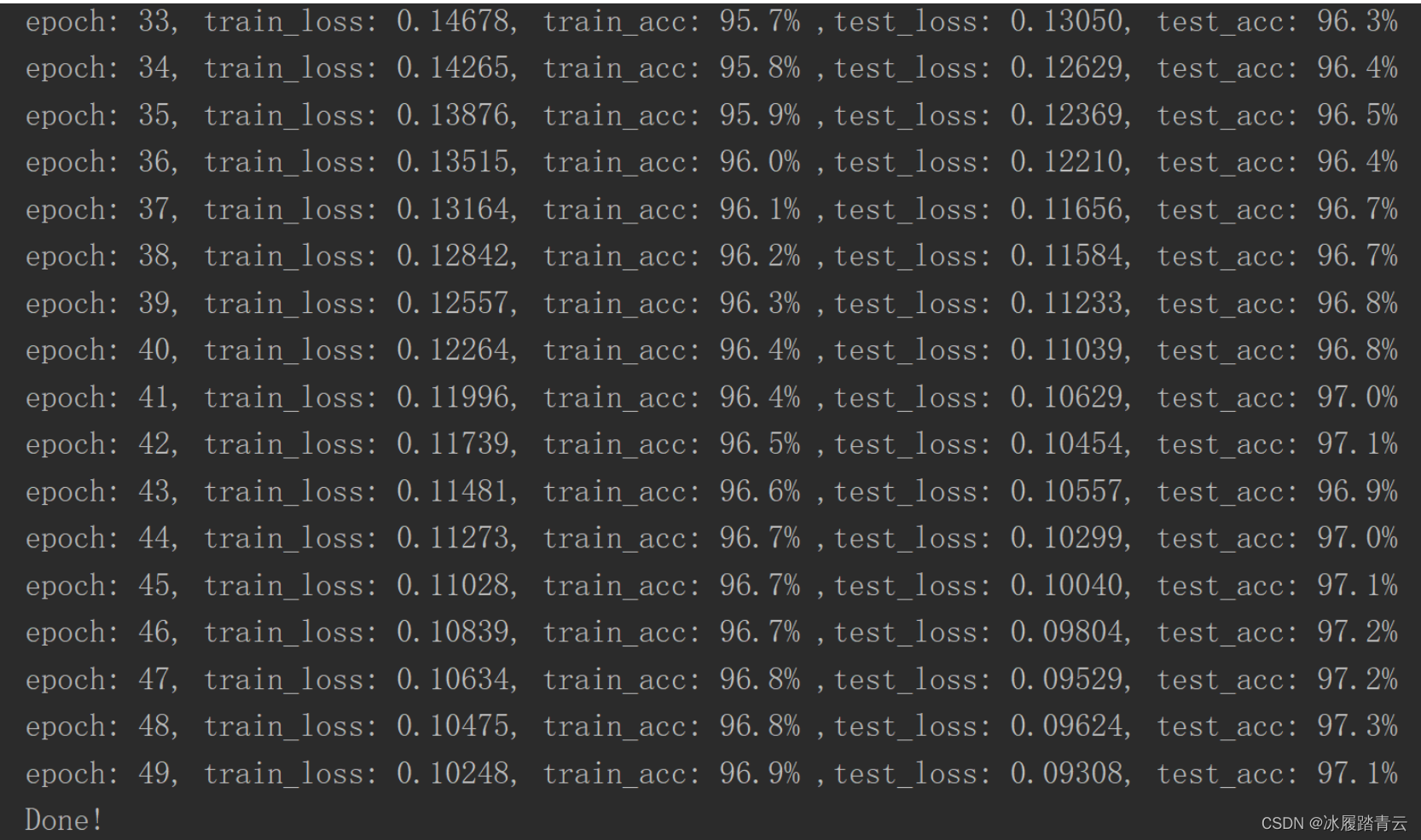
可以看到经过50个epoch的训练,正确率已经达到了97%左右,
下图是前面手写数字模型训练输出结果:
具体细节可看之前的文章: 多层感知器模型与模型训练
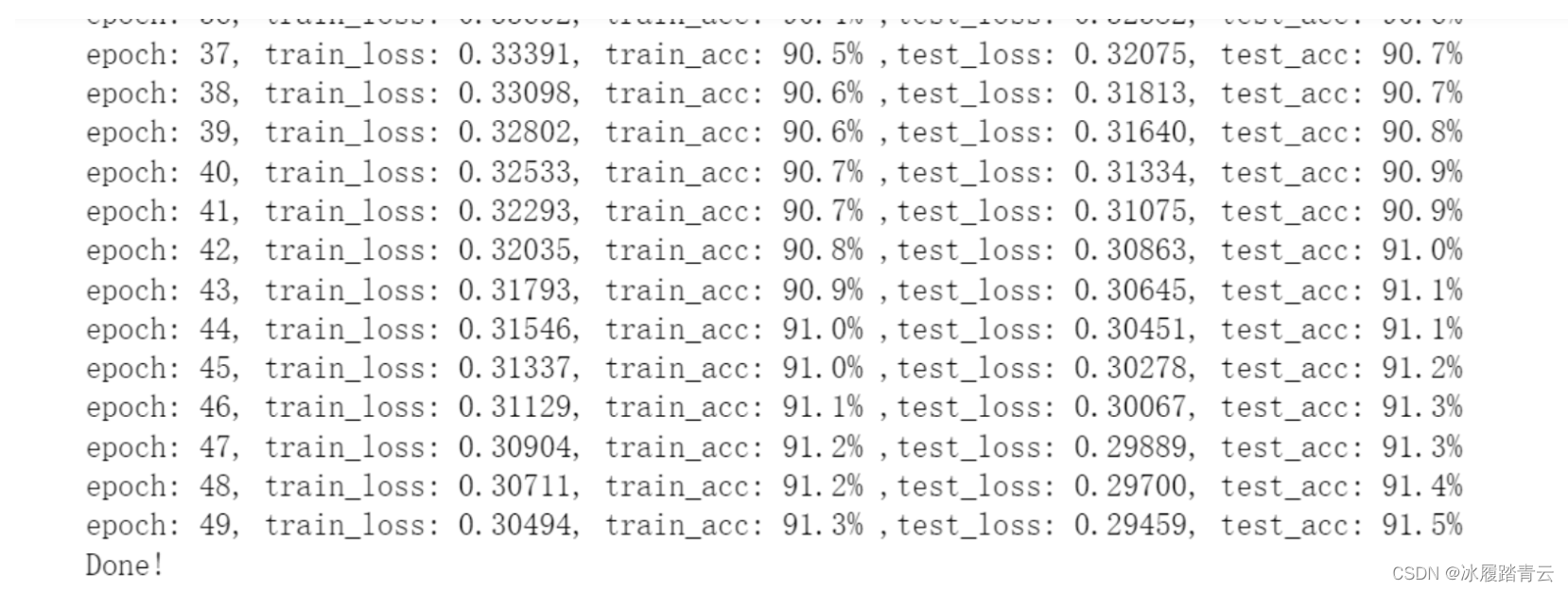
将训练结果与前面手写数字模型的训练输出对比,很显然,使用卷积模型的正确率上升了很多。
3. 超参数选择
在定义模型过程中,有很多超参数是需要我们自己去设置的,所谓超参数,就是搭建神经网络中需要我们自己去选择(不是通过梯度下降法去优化)的那些参数。例如,每一层卷积核的个数、全连接层单元数、学习速率、优化器参数等。那么这些超参数如何做出选择呢?
首先介绍网络容量的概念,网络容量可以认为是与网络中的可训练参数成正比的,网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。网络容量越大,网络的拟合能力越强,但是训练速度越慢,训练难度越大,越容易产生过拟合。如果想获得更高的正确率,就需要提高网络拟合能力,那么如何提高网络的拟合能力?
一种显然的想法是增大网络容量,如增加层、增加每层隐藏神经元个数,这两种方法哪种更好呢?
通过实验对比可以明确,单纯地增加每层的神经元个数对网络性能的提高并不是特别明显;增加层,也就是增大网络深度,会大大提高网络的拟合能力,这也是为什么现在深度学习网络越来越深的原因。
当我们选择增加模型深度,也就是增加层来提高拟合能力的时候,还要注意,单层的神经元个数不能太小,太小会造成信息瓶颈,信息不能有效地通过这一层,造成模型欠拟合。
所谓过拟合,是指模型在训练样本上表现得过于优越,但是在验证数据集以及测试数据集上表现不佳。过拟合的本质是模型对训练样本的过度学习,反而失去了泛化能力。当发生过拟合时,一般说明模型的拟合能力是没有问题的,但是泛化能力需要提高。关于过拟合的处理,可以使用Dropout抑制过拟合,也可以适当地减小模型的拟合能力,如减小模型容量(减少层或减少每一层的单元数),这样能够起到正则化的效果;当然,最好的办法是增加训练样本,模型能学习到更多的样本,泛化能力自然会提高。
所谓欠拟合是指模型的拟合能力不够,在训练集就表现很差,在验证数据集上当然也不会好,这时我们需要做的就是增大模型的拟合能力,如增大网络深度、适当增加每层神经元个数等。
总结开发深度学习模型的参数选择的原则,我们可以首先开发一个过拟合的模型。
-
添加更多的层。
-
让每一层变得更大。
-
训练更多的轮次。然后,抑制过拟合,再次,调节超参数。
-
学习速率。
-
网络深度。
-
隐藏层单元数。
-
训练轮次。
-
调节其他参数。
超参数的选择是一个不断测试的结果。在实际开发时,要注意观察训练过程中模型在训练数据集和验证数据集上的损失变化曲线和正确率变化曲线,这些曲线可以直观地反映模型当前所处的状态。如果是欠拟合,就增大模型拟合能力;如果是过拟合,就需要抑制过拟合。在开发过程中,还要使用不同的超参数进行对比实验,从而选择能得到最高验证集正确率的超参数。

















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











