









图像分割
(一)点、线和边缘检测
1.1 孤立点的检测
- 一阶导数通常在图像中产生较粗的边缘
- 二阶导数对精细细节,如细线、孤立点和噪声有较强的响应
- 二阶导数在灰度斜坡和灰度台阶过渡处会产生双边缘响应
- 二阶导数的符号可用于确定边缘的过渡是从亮到暗还是从暗到亮
 孤立点的检测:
孤立点的检测:
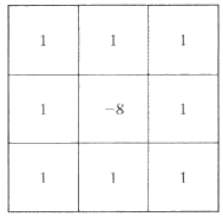
拉普拉斯模版,响应绝对值超过指定阈值即为孤立点。
注:对于一个导数模版,系数之和为零表明在恒定灰度区模版响应将是零。
拉普拉斯算子
特点:
■中心为正,邻近为负;模板和为0
■对噪声敏感、产生双象素宽边缘,没有方向信息
用途:
■少用于边缘检测
■常用于在边缘已知情况下,确定像素在明区或暗区。
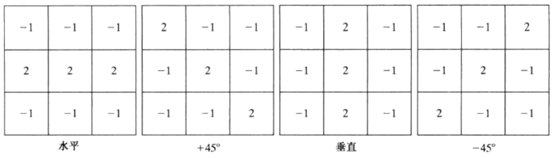
1.2 线检测
1.线检测同样可以使用拉普拉斯模板,但拉普拉斯检测子是各向同性的,因此其响应与方向无关,也可以使用与方向有关的改进算子:
 2.Hough变换检测直线(重点)
2.Hough变换检测直线(重点)
Hough变换时一种利用图像的全局特征将特定形状边缘链接起来。它通过点线的对偶性,将源图像上的点影射到用于累加的参数空间,把原始图像中给定曲线的检测问题转化为寻找参数空间中的峰值问题。由于利用全局特征,所以受噪声和边界间断的影响较小,比较鲁棒。
Hough变换思想为:
在原始图像坐标系下的一个点对应了参数坐标系中的一条直线,同样参数坐标系的一条直线对应了原始坐标系下的一个点,然后,原始坐标系下呈现直线的所有点,它们的斜率和截距是相同的,所以它们在参数坐标系下对应于同一个点。这样在将原始坐标系下的各个点投影到参数坐标系下之后,看参数坐标系下有没有聚集点,这样的聚集点就对应了原始坐标系下的直线。
一条直线在直角坐标系下可以用y=kx+b表示, 霍夫变换的主要思想是将该方程的参数和变量交换,即用x,y作为已知量k,b作为变量坐标,所以直角坐标系下的直线y=kx+b在参数空间表示为点(k,b),而一个点(x1,y1)在直角坐标系下表示为一条直线y1=x1·k+b,其中(k,b)是该直线上的任意点。为了计算方便,我们将参数空间的坐标表示为极坐标下的γ和θ。因为同一条直线上的点对应的(γ,θ)是相同的,因此可以先将图片进行边缘检测,然后对图像上每一个非零像素点,在参数坐标下变换为一条直线,那么在直角坐标下属于同一条直线的点便在参数空间形成多条直线并内交于一点。因此可用该原理进行直线检测。
因此采用hough变换主要有以下几个步骤:
- Detect the edge
检测得到图像的边缘 - Create accumulator
采用二维向量描述图像上每一条直线区域,将图像上的直线区域计数器映射到参数空间中的存储单元,ρ为直线区域到原点的距离(直线到原点的垂直距离),所以对于对角线长度为n的图像,ρ的取值范围为(0, n),θ值得取值范围为(0, 360),定义为二维数组HoughBuf[n][360]为存储单元。
对所有像素点(x,y)在所有θ角的时候,求出ρ.从而累加ρ值出现的次数。高于某个阈值的ρ就是一个直线。
这个过程就类似于如下一个二维的表格,横坐标就是θ角,ρ就是到直线的最短距离。横坐标θ不断变换,根据直线方程公司,ρ = xcosθ + ysinθ 对于所有的不为0的像素点,计算出ρ,找到ρ在坐标(θ,ρ)的位置累加1. - Detect the peaks, maximal in the accumulator
通过统计特性,假如图像平面上有两条直线,那么最终会出现2个峰值,累加得到最高的数组的值为所求直线参数。
实验代码:
标准霍夫线变换:
def line_detection_demo(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
lines = cv2.HoughLines(edges, 1, np.pi/180, 200) # 函数将通过步长为1的半径和步长为π/180的角来搜索所有可能的直线
for line in lines:
rho, theta = line[0] # line[0]存储的是点到直线的极径和极角,其中极角是弧度表示的
a = np.cos(theta) # theta是弧度
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000 * (-b)) # 直线起点横坐标
y1 = int(y0 + 1000 * (a)) # 直线起点纵坐标
x2 = int(x0 - 1000 * (-b)) # 直线终点横坐标
y2 = int(y0 - 1000 * (a)) # 直线终点纵坐标
cv2.line(image, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.imshow("image_lines", image)
统计概率霍夫线变换:
def line_detect_possible_demo(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGRA2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
# 函数将通过步长为1的半径和步长为π/180的角来搜索所有可能的直线
lines = cv2.HoughLinesP(edges, 1, np.pi / 180, 100, minLineLength=50, maxLineGap=10)
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(image, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.imshow("line_detect_possible_demo", image)
处理效果:




结果分析: 对于线条清晰的直线检测效果明显,可以有效标注出位置,一些和背景区域颜色相近或者边界区域不明显的线条则有一些误判,也有一些时心里视觉造成觉得直线的检测有偏颇。
1.3 边缘检测
(1)边缘模型
1.台阶模型
2.斜坡模型
3.屋顶边缘模型
 一阶导数的幅度可用于检测图像中的某个点处是否存在一个边缘。二阶导数的符号可用于确定一个边缘像素是位于该边缘的暗侧还是亮侧。二阶导数的附加性质:对图像中的每条边缘,二阶导数生成两个值;二阶导数的零交叉点可用于定位粗边缘的中心。
一阶导数的幅度可用于检测图像中的某个点处是否存在一个边缘。二阶导数的符号可用于确定一个边缘像素是位于该边缘的暗侧还是亮侧。二阶导数的附加性质:对图像中的每条边缘,二阶导数生成两个值;二阶导数的零交叉点可用于定位粗边缘的中心。
边缘检测是基于灰度突变来分割图像的最常用的方法。实际中,数字图像都存在被模糊且带有噪声的边缘,模糊的程度主要取决于聚焦机理(如光学成像中的镜头)中的限制,且噪声水平主要取决于成像系统的电子元件。
零灰度轴和二阶导数极值间的连线的交点称为该二阶导数的零交叉点,可用于定位粗边缘的中心。微弱的可见噪声对检测边缘所用的两个关键导数有严重的影响,所以图像的平滑处理是检测之前必须仔细考虑的问题。
(2)基本边缘检测
图像梯度及其性质:
图像坐标系统的原点位于左上角,正x轴向下延伸,正y轴向右延伸。
任意点处一个边缘的方向与该点处梯度向量的方向正交。
梯度算子:
用于计算梯度偏导数的滤波器模版,通常称为梯度算子、差分算子、边缘算子或边缘检测子。常见的有:
罗伯特交叉梯度算子(Roberts)、Prewitt算子、Sobel算子、Laplace算子、Scharr滤波器。Sobel模版能较好地抑制(平滑)噪声。
改进的边缘检测技术
(1) Marr-Hildreth边缘检测器(LOG滤波器) 算法步骤:
1.使用高斯滤波器平滑图像,并计算其拉普拉斯算子
2.寻找步骤2所得图像的零交叉
(2)坎尼边缘检测器(Canny)算法步骤:
- 用高斯滤波器对图像进行去噪。
- 计算梯度。
- 在边缘上使用非最大抑制(NMS)。
- 在检测到的边缘上使用双阈值去除假阳性。
- 分析所有的边缘及其之间的连接。
实验:
各个边缘算子定义:
# Roberts边缘算子
kernel_Roberts_x = np.array([
[1, 0],
[0, -1]
])
kernel_Roberts_y = np.array([
[0, -1],
[1, 0]
])
# Sobel边缘算子
kernel_Sobel_x = np.array([
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
kernel_Sobel_y = np.array([
[1, 2, 1],
[0, 0, 0],
[-1, -2, -1]])
# Prewitt边缘算子
kernel_Prewitt_x = np.array([
[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]])
kernel_Prewitt_y = np.array([
[1, 1, 1],
[0, 0, 0],
[-1, -1, -1]])
# 拉普拉斯卷积核
kernel_Laplacian_1 = np.array([
[0, 1, 0],
[1, -4, 1],
[0, 1, 0]])
kernel_Laplacian_2 = np.array([
[1, 1, 1],
[1, -8, 1],
[1, 1, 1]])
# 下面两个卷积核不具有旋转不变性
kernel_Laplacian_3 = np.array([
[2, -1, 2],
[-1, -4, -1],
[2, 1, 2]])
kernel_Laplacian_4 = np.array([
[-1, 2, -1],
[2, -4, 2],
[-1, 2, -1]])
# 5*5 LOG卷积模板
kernel_LoG = np.array([
[0, 0, -1, 0, 0],
[0, -1, -2, -1, 0],
[-1, -2, 16, -2, -1],
[0, -1, -2, -1, 0],
[0, 0, -1, 0, 0]])
# Canny边缘检测 k为高斯核大小,t1,t2为阈值大小
def Canny(image, k, t1, t2):
img = cv2.GaussianBlur(image, (k, k), 0)
canny = cv2.Canny(img, t1, t2)
return canny
处理效果:



结果分析: 可以明显看出LOG算子和Canny算子的处理效果优越于其它算子,对于边缘连接的细微处更敏感,识别效果更佳,同时LOG效果比Canny效率要高一些。
(二)阈值处理
基本概念: 一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,常用的方法就是设定一个阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。这是研究灰度变换的最特殊的方法,称为图像的二值化(Binarization)。
阈值分割法的特点是:适用于目标与背景灰度有较强对比的情况,重要的是背景或物体的灰度比较单一,而且总可以得到封闭且连通区域的边界。
2.1 简单阈值(单一全局阈值)
选取一个全局阈值,然后就把整幅图像分成非黑即白的二值图像。
函数为cv2.threshold( )
这个函数有四个参数,第一个是原图像矩阵,第二个是进行分类的阈值,第三个是高于(低于)阈值时赋予的新值,第四个是一个方法选择参数,常用的有:
-
cv2.THRESH_BINARY(黑白二值)
-
cv2.THRESH_BINARY_INV(黑白二值翻转)
-
cv2.THRESH_TRUNC(得到额图像为多像素值)
-
cv2.THRESH_TOZERO(当像素高于阈值时像素设置为自己提供的像素值,低于阈值时不作处理)
-
cv2.THRESH_TOZERO_INV(当像素低于阈值时设置为自己提供的像素值,高于阈值时不作处理)
这个函数返回两个值,第一个值为阈值,第二个就是阈值处理后的图像矩阵。
实验代码:
简单阈值
img = cv2.imread('D:/Data/school.jpg', 0)
ret, thresh1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) # binary (黑白二值)
ret, thresh2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV) # (黑白二值反转)
ret, thresh3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC) # 得到的图像为多像素值
ret, thresh4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO) # 高于阈值时像素设置为255,低于阈值时不作处理
ret, thresh5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV) # 低于阈值时设置为255,高于阈值时不作处理
print(ret)
处理效果:



结果分析: 对图像灰度值明显变化的边缘区域有很好的效果,而灰度值变化比较平缓,视觉上与背景区别较弱的边缘区域,本算法处理敏感度有所下降。
2.2 自适应阈值
2.1中的简单阈值是一种全局性的阈值,只需要设定一个阈值,整个图像都和这个阈值比较。而自适应阈值可以看成一种局部性的阈值,通过设定一个区域大小,比较这个点与区域大小里面像素点 的平均值(或者其他特征)的大小关系确定这个像素点的情况。这种方法理论上得到的效果更好,相当于在动态自适应的调整属于自己像素点的阈值,而不是整幅图都用一个阈值。
实验代码:
img = cv2.imread('D:/Data/school.jpg', 0)
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
th2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 2)
th3 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
th4 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
- 第一个参数为原始图像矩阵,第二个参数为像素值上限,第三个是自适应方法(adaptive method):
cv2.ADAPTIVE_THRESH_MEAN_C:领域内均值
cv2.ADAPTIVE_THRESH_GAUSSIAN_C:领域内像素点加权和,权重为一个高斯窗口 - 第四个值的赋值方法:只有cv2.THRESH_BINARY
和cv2.THRESH_BINARY_INV - 第五个Block size:设定领域大小(一个正方形的领域)
- 第六个参数C,阈值等于均值或者加权值减去这个常数(为0相当于阈值,就是求得领域内均值或者加权值)
处理效果:





结果分析: 对于参数的窗口越来越小时,发现得到的图像越来越细了,可以设想,如果把窗口设置的足够大的话(不能超过图像大小),那么得到的结果可能就和第二幅图像的相同了。
2.3 Otsu’s二值化
cv2.threshold( )函数有两个返回值,一个是阈值,第二个是处理后的图像矩阵。在前面对于阈值的设定上,我们选择的阈值都是127,在实际情况中,有的图像阈值不是127得到的图像效果更好。那么这里就需要算法自己去寻找一个阈值,而Otsu’s就可以自己找到一个认为最好的阈值。并且Otsu’s非常适合于图像灰度直方图(只有灰度图像才有)具有双峰的情况。他会在双峰之间找到一个值作为阈值,对于非双峰图像,可能并不是很好用。那么经过Otsu’s得到的那个阈值就是函数cv2.threshold的第一个参数了。因为Otsu’s方法会产生一个阈值,那么函数cv2.threshold( )的第二个参数(设定阈值)就是0了,并且在cv2.threshold的方法参数中还得加上语句cv2.THRESH_OTSU.
实验代码:
ret1, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) # 简单滤波
ret2, th2 = cv2.threshold(img, 0, 255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) # Otsu 滤波
处理效果:






结果分析: 对比之下发现对于单灰度峰值的处理效果不是很好,对多峰值的图像处理情况要好一些,对一副双峰图像自动根据其直方图计算出一个阈值,处理后效果有改善。
(三)基于区域的分割
3.1 区域生长
区域生长是一种串行区域分割的图像分割方法。区域生长是指从某个像素出发,按照一定的准则,逐步加入邻近像素,当满足一定的条件时,区域生长终止。区域生长的好坏决定于1.初始点(种子点)的选取。2.生长准则。3.终止条件。区域生长是从某个或者某些像素点出发,最后得到整个区域,进而实现目标的提取。
区域生长的原理
区域生长的基本思想是将具有相似性质的像素集合起来构成区域。具体先对每个需要分割的区域找一个种子像素作为生长起点,然后将种子像素和周围邻域中与种子像素有相同或相似性质的像素(根据某种事先确定的生长或相似准则来判定)合并到种子像素所在的区域中。将这些新像素当作新的种子继续上面的过程,直到没有满足条件的像素可被包括进来。这样一个区域就生长成了。
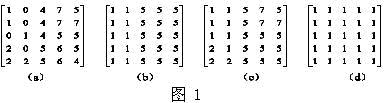
图1给出已知种子点进行区域生长的一个示例。图1(a)给出需要分割的图像,设已知两个种子像素(标为深浅不同的灰色方块),现要进行区域生长。设这里采用的判定准则是:如果考虑的像素与种子像素灰度值差的绝对值小于某个门限T,则将该像素包括进种子像素所在的区域。图1(b)给出了T=3时的区域生长结果,整幅图被较好地分成2个区域;图1(c)给出了T=1时的区域生长结果,有些像素无法判定;图1(c)给出了T=6时的区域生长的结果,整幅图都被分在一个区域中了。由此可见门限的选择是很重要的。
区域生长实现的步骤如下:
-
对图像顺序扫描!找到第1个还没有归属的像素, 设该像素为(x0, y0);
-
以(x0, y0)为中心, 考虑(x0, y0)的4邻域像素(x, y)如果(x0, y0)满足生长准则, 将(x, y)与(x0, y0)合并(在同一区域内), 同时将(x, y)压入堆栈;
-
从堆栈中取出一个像素, 把它当作(x0, y0)返回到步骤2;
-
当堆栈为空时!返回到步骤1;
-
重复步骤1 - 4直到图像中的每个点都有归属时。生长结束。
代码实现:
def grab_cut(sourceDir):
# 读取图片
img = cv2.imread(sourceDir)
# 图片宽度
img_x = img.shape[1]
# 图片高度
img_y = img.shape[0]
# 分割的矩形区域
rect = (96,1, 359, 358)
# 背景模式,必须为1行,13x5列
bgModel = np.zeros((1, 65), np.float64)
# 前景模式,必须为1行,13x5列
fgModel = np.zeros((1, 65), np.float64)
# 图像掩模,取值有0,1,2,3
mask = np.zeros(img.shape[:2], np.uint8)
# grabCut处理,GC_INIT_WITH_RECT模式
cv2.grabCut(img, mask, rect, bgModel, fgModel, 4, cv2.GC_INIT_WITH_RECT)
# grabCut处理,GC_INIT_WITH_MASK模式
# cv2.grabCut(img, mask, rect, bgModel, fgModel, 4, cv2.GC_INIT_WITH_MASK)
# 将背景0,2设成0,其余设成1
mask2 = np.where((mask==2) | (mask==0), 0, 1).astype('uint8')
# 重新计算图像着色,对应元素相乘
img = img*mask2[:, :, np.newaxis]
cv2.imshow("Result", img)
cv2.waitKey(0)
处理效果:


结果分析: 对整体区域特征比较明显的块状区域的效果很好,一些和背景区域颜色相近或者边界区域不明显的区域则有一些误判和舍弃,细节处有待改进。
3.2 区域分裂合并
区域分裂合并算法的基本思想 是先确定一个分裂合并的准则,即区域特征一致性的测度,当图像中某个区域的特征不一致时就将该区域分裂成4 个相等的子区域,当相邻的子区域满足一致性特征时则将它们合成一个大区域,直至所有区域不再满足分裂合并的条件为止。当分裂到不能再分的情况时,分裂结束,然后它将查找相邻区域有没有相似的特征,如果有就将相似区域进行合并,最后达到分割的作用。
在一定程度上区域生长和区域分裂合并算法有异曲同工之妙,互相促进相辅相成的,区域分裂到极致就是分割成单一像素点,然后按照一定的测量准则进行合并,在一定程度上可以认为是单一像素点的区域生长方法。
区域生长比区域分裂合并的方法节省了分裂的过程,而区域分裂合并的方法可以在较大的一个相似区域基础上再进行相似合并,而区域生长只能从单一像素点出发进行生长(合并)。
反复进行拆分和聚合以满足限制条件的算法。
令R表示整幅图像区域并选择一个法则P。对R进行分割的一种方法是反复将分割得到的结果图像再次分为四个区域,直到对任何区域Ri,有P(Ri)=TRUE。这里是从整幅图像开始。如果P®=FALSE,就将图像分割为4个区域。对任何区域如果P的值是FALSE.就将这4个区域的每个区域再次分别分为4个区域,如此不断继续下去。这种特殊的分割技术用所谓的四叉树形式表示最为方便(就是说,每个非叶子节点正好有4个子树),这正如图10.42中说明的树那样。注意,树的根对应于整幅图像,每个节点对应于划分的子部分。此时,只有R4进行了进一步的再细分。
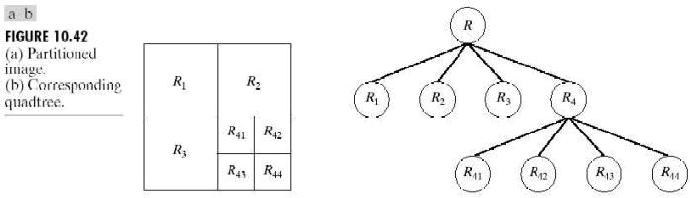
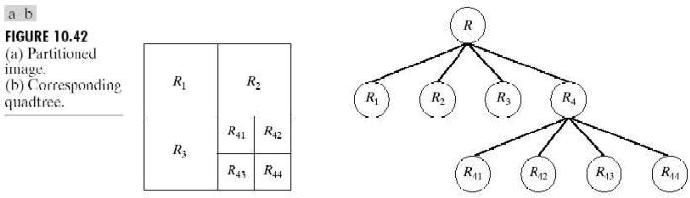 如果只使用拆分,最后的分区可能会包含具有相同性质的相邻区域。这种缺陷可以通过进行拆分的同时也允许进行区域聚合来得到矫正。就是说,只有在P(Rj∪Rk)=TRUE时,两个相邻的区域Rj和Rk才能聚合。
如果只使用拆分,最后的分区可能会包含具有相同性质的相邻区域。这种缺陷可以通过进行拆分的同时也允许进行区域聚合来得到矫正。就是说,只有在P(Rj∪Rk)=TRUE时,两个相邻的区域Rj和Rk才能聚合。
前面的讨论可以总结为如下过程。反复操作的每一步:
1.对于任何区域Ri,如果P(Ri)=FALSE,就将每个区域都拆分为4个相连的象限区域。
2.将P(Rj∪Rk)=TRUE的任意两个相邻区域Rj和Rk进行聚合。
3.当再无法进行聚合或拆分时操作停止。
可以对前面讲述的基本思想进行几种变化。例如,一种可能的变化是开始时将图像拆分为一组图象块。然后对每个块进一步进行上述拆分,但聚合操作开始时受只能将4个块并为一组的限制。这4个块是四叉树表示法中节点的后代且都满足谓词P。当不能再进行此类聚合时,这个过程终止于满足步骤2的最后的区域聚合。在这种情况下,聚合的区域可能会大小不同。这种方法的主要优点是对于拆分和聚合都使用同样的四叉树,直到聚合的最后一步。
(四)形态学分水岭分割
4.1 基本概念介绍
分水岭概念 以对图像进行三维可视化处理为基础的:其中两个是坐标,另一个是灰度级。对于这样:一种“地形学”的解释,我们考虑三类点:(a)属于局部性最小值的点;
(b)当一滴水放在某点的位置上的时候,水一定会下落到一个单一的最小值点;
©当水处在某个点的位置上时,,水会等概率地流向不止一个这样的最小值点。
对一个特定的区域最小值,满足条件(b)的点的集合称为这个最小值的“汇水盆地”或“分水岭”。满足条件©的点的集合组成地形表面的峰线,术语称做“分割线”或“分水线”。
基于这些概念的分割算法的主要目标是找出分水线。基本思想很简单:假设在每个区域最小值的位置上打一个洞并且让水以均匀的上升速率从洞中涌出,从低到高淹没整个地形。当处在不同的汇聚盆地中的水将要聚合在一起时,修建的大坝将阻止聚合。水将只能到达大坝的顶部处于水线之上的程度。这些大坝的边界对应于分水岭的分割线。所以,它们是由分水岭算法提取出来的(连续的)边界线。
 假设在每个区域最小值中打一个洞(如图(b)中的深色区域),并且让水以均匀的上升速率从洞中涌出,从低到高淹没整个地形。图©说明被水淹没的第一个阶段,这里水用浅灰色表示,覆盖了对应于图中深色背景的区域。在图(d)和(e)中,我们看到水分别在第一和第二汇水盆地中上升。由于水持续上升,最终水将从一个汇水盆地中溢出到另一个之中。图(f)中显示了溢出的第一个征兆。这里,水确实从左边的盆地溢出到右边的盆地,并且两者之间有一个短“坝”(由单像素构成)阻止这一水位的水聚合在一起(在接下来的章节中将讨论坝的构筑)。由于水位不断上升,实际的效果要超出我们所说的。如图(g)所显示的那样。这幅图中在两个汇水盆地之间显示了一条更长的坝,另一条水坝在右上角。这条水坝阻止了盆地中的水和对应于背景的水的聚合。这个过程不断延续直到到达水位的最大值(对应于图像中灰度级的最大值)。水坝最后剩下的部分对应于分水线,这条线就是要得到的分割结果。
假设在每个区域最小值中打一个洞(如图(b)中的深色区域),并且让水以均匀的上升速率从洞中涌出,从低到高淹没整个地形。图©说明被水淹没的第一个阶段,这里水用浅灰色表示,覆盖了对应于图中深色背景的区域。在图(d)和(e)中,我们看到水分别在第一和第二汇水盆地中上升。由于水持续上升,最终水将从一个汇水盆地中溢出到另一个之中。图(f)中显示了溢出的第一个征兆。这里,水确实从左边的盆地溢出到右边的盆地,并且两者之间有一个短“坝”(由单像素构成)阻止这一水位的水聚合在一起(在接下来的章节中将讨论坝的构筑)。由于水位不断上升,实际的效果要超出我们所说的。如图(g)所显示的那样。这幅图中在两个汇水盆地之间显示了一条更长的坝,另一条水坝在右上角。这条水坝阻止了盆地中的水和对应于背景的水的聚合。这个过程不断延续直到到达水位的最大值(对应于图像中灰度级的最大值)。水坝最后剩下的部分对应于分水线,这条线就是要得到的分割结果。
对于这个例子,在图(h)中显示为叠加到原图上的一个像素宽的深色路径。注意一条重要的性质就是分水线组成一条连通的路径,由此给出了区域之间的连续的边界。
分水岭分割法的主要应用是从背景中提取近乎一致(类似水滴的)的对象。那些在灰度级上变化较小的区域的梯度值也较小。因此,实际上,我们经常可以见到分水岭分割方法与图像的梯度有更大的关系,而不是图像本身。 有了这样的表示方法,汇水盆地的局部最小值就可以与对应于所关注的对象的小的梯度值联系起来了。
4.2 水坝构造
在进行讨论之前,让我们考虑一下如何构造分水岭分割方法所需的水坝或分水线。水坝的构造是以二值图像为基础的。构造水坝分离二元点集的最简单的方法是使用形态膨胀。
下图说明了如何使用形态膨胀构造水坝的基本点。图(a)显示了两个汇水盆地的部分区域在淹没步骤的第n-1步时的图像。图(b)显示了淹没的下一步(第n步)的结果。水已经从一个盆地溢出到另一个盆地,所以,必须建造水坝阻止这种情况的发生。为了与紧接着要介绍的符号相一致,令M1和M2表示在两个区域极小值中包含的点的坐标集合。然后,将处于汇水盆地中的点的坐标集合与这两个在溢出的第n-1个阶段的最小值联系起来,并用 Cn-1(M1) 和 Cn-1(M2) 表示。这就是图(a)中的两个黑色区域。
 令这两个集合的联合用 C[n—1] 表示。图(a)中有两个连通分量,而图(b)中只有一个连通分量。这个连通分量包含着前面的两个分量,用虚线表示。两个连通分量变成一个连通分量的事实说明两个汇水盆地中的水在淹没的第n步聚合了。用q表示此时的连通分量。注意,第n-1步中的两个连通分量可以通过使用“与”操作 (q∩C[n-1]) 从q中提取出来。我们也注意到,属于独立的汇水盆地的所有点构成了一个单一的连通分量。
令这两个集合的联合用 C[n—1] 表示。图(a)中有两个连通分量,而图(b)中只有一个连通分量。这个连通分量包含着前面的两个分量,用虚线表示。两个连通分量变成一个连通分量的事实说明两个汇水盆地中的水在淹没的第n步聚合了。用q表示此时的连通分量。注意,第n-1步中的两个连通分量可以通过使用“与”操作 (q∩C[n-1]) 从q中提取出来。我们也注意到,属于独立的汇水盆地的所有点构成了一个单一的连通分量。
假设图(a)中的每个连通分量通过使用图(e)中显示的结构元膨胀,在两个条件下:
(1)膨胀受到q的约束(这意味着在膨胀的过程中结构化元素的中心只能定位于q中)并且(2)在引起集合聚合的那些点上不能执行膨胀(成为单一的连通分量)。图(d)显示首轮膨胀(浅灰色表示)使用了每个初始连通分量的边界。注意,在膨胀过程中每个点都满足条件(1)。条件(2)在膨胀处理中没有应用于任何的点;因此,每个区域的边界都进行了均匀的扩展。
在第二轮膨胀中(中等灰度表示),几个不满足条件(1)的点符合条件(2)时,得到图中显示的断开周界。很明显,只有满足上述两个条件的属于q中的点描绘了图(d)中交叉阴影线表示的一个像素宽度的连通路径。这条路径组成在淹没的第n个阶段我们希望得到的水坝。在这个淹没水平上,水坝的构造是由置所有刚好在这条路径上的点的值为比图像中灰度级的最大值还大的值完成的。所有水坝的高度通常设定为1加上图像中灰度级最大允许值。这样设定可以阻止在水位不断升高的情况下水越过部分水坝。应该特别注意到的是通过这一过程建立的水坝是连通分量,就是希望得到的分割边界。就是说,这种方法消除了分割线产生间断的问题。
4.3 分水岭分割算法
令M1,M2,…,MR为表示图像g(x,y)的局部最小值点的坐标的集合。如同在10.5.1节结尾说明的那样,这是一幅典型的梯度图像。令G(Mi)为一个点的坐标的集合,这些点位于与局部最小值Mi (回想无论哪一个汇水盆地内的点都组成一个连通分量)相联系的汇水盆地内。符号min和max代表g(x,y)的最小值和最大值。最后,令T[n]表示坐标(s,t)的集合,其中g(s,t)<n,即
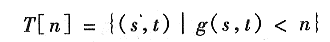
在几何上,T[n]是g(x,y)中的点的坐标集合,集合中的点均位于平面g(x,y)=n的下方。
随着水位以整数量从n=min+1到n=max+1不断增加,图像中的地形会被水漫过。在水位漫过地形的过程中的每一阶段,算法都需要知道处在水位之下的点的数目。从概念上来说,假设T[n]中的坐标处在g(x,y)=n平面之下,并被“标记”为黑色,所有其他的坐标被标记为白色。然后,当我们在水位以任意增量n增加的时候,从上向下观察xy平面,会看到一幅二值图像。在图像中黑色点对应于函数中低于平面g(x,y)=n的点。这种解释对于理解下面的讨论很有帮助。
令Cn(Mi)表示汇水盆地中点的坐标的集合。这个盆地与在第n阶段被淹没的最小值有关。参考前一段的讨论,Cn(Mi)也可以被看做由下式给出的二值图像:
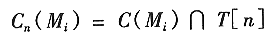
换句话说,如果(x,y)∈Cn(Mi)且(x,y)∈T[n],则在位置(x,y)有Cn(Mi)=1。否则Cn(Mi)=0.对于这个结果几何上的解释是很简单的。我们只需在水溢出的第n个阶段使用“与(AND)”算子将T[n]中的二直图像分离出来即可。T[n]是与局部最小值Mi相联系的集合。
接下来,我们令C[n]表示在第n个阶段汇水盆地被水淹没的部分的合集:
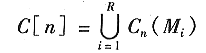
然后令C[max+1]为所有汇水盆地的合集:
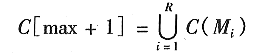
可以看出处于Cn( Mi)和T[n]中的元素在算法执行期间是不会被替换的,而且这两个集合中的元素的数目与n保持同步增长。因此,C[n-1]是集合C[n]的子集。根据式(10.5.2)和式(10.5.3),C[n]是T[n]的子集,所以,C[n-1]是T[n]的子集。从这个结论我们得 出重要的结果:C[n-1]中的每个连通分量都恰好是T[n]的一个连通分量。
找寻分水线的算法开始时设定C[min+1]=T[min+1]。然后算法进入递归调用,假设在第n步时,已经构造了C[n-1]。根据C[n-1]求得C[n]的过程如下:令Q代表T[n]中连通分量的集合。然后,对于每个连通分量q∈Q[n],有下列3种可能性:
(1) q∩C[n-1]为空。
(2) q∩C[n-1]包含C[n-1]中的一个连通分量。
(3) q∩C[n-1]包含C[n-1]多于一个的连通分量。
根据C[n-1]构造C[n]取决于这3个条件。当遇到一个新的最小值时符合条件(1),则将q并人C[n-1]构成C[n]。当q位于某些局部最小值构成的汇水盆地中时,符合条件(2),此时将q合并入C[n-1]构成C[n]。当遇到全部或部分分离两个或更多汇水盆地的山脊线的时候,符合条件(3)。进一步的注水会导致不同盆地的水聚合在一起,从而使水位趋于一致。因此,必须在q内建立一座水坝(如果涉及多个盆地就要建立多座水坝)以阻止盆地内的水溢出。正如前一节中的解释,当用3×3个1的结构元素膨胀 q∩C[n-1] 并且需要将这种膨胀限制在q内时,一条一个像素宽度的水坝是能够构造出来的。
通过使用与g(x,y)中存在的灰度级值相对应的n值,可以改善算法效率;根据g(x,y)的直方图,可以确定这些值及其最小值和最大值。
4.4 实验
基于标记的分水岭分割功能:
img = np.zeros((400, 400), np.uint8)
cv2.circle(img, (150, 150), 100, 255, -1)
cv2.circle(img, (250, 250), 100, 255, -1)
dist = cv2.distanceTransform(img, cv2.cv.CV_DIST_L2, cv2.cv.CV_DIST_MASK_PRECISE)
dist3 = np.zeros((dist.shape[0], dist.shape[1], 3), dtype = np.uint8)
dist3[:, :, 0] = dist
dist3[:, :, 1] = dist
dist3[:, :, 2] = dist
markers = np.zeros(img.shape, np.int32)
markers[150,150] = 1 # seed for circle one
markers[250, 250] = 2 # seed for circle two
markers[50,50] = 3 # seeds for background
cv2.watershed(dist3, markers)
形态学分水岭:
def watershed(imgpath):
img = cv2.imread(imgpath)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret0, thresh0 = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh0,cv2.MORPH_OPEN,kernel, iterations = 2)
确定背景区域:
sure_bg = cv2.dilate(opening,kernel,iterations=3)
确定前景区域:
dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5)
ret1, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
查找未知区域:
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)
标记标签:
ret2, markers1 = cv2.connectedComponents(sure_fg)
markers = markers1+1
markers[unknown==255] = 0
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [0,255,0]
return thresh0,sure_bg,sure_fg,img
处理效果:
例1
二值化:
 背景区域:
背景区域:
 前景区域:
前景区域:
 处理结果:
处理结果:
 例2
例2




结果分析: 对背景区域的分割很好,有效标记区分出蓝天和建筑物,对前景的分割有些问题,没有将所有区分不明显和有粘连的区域标记出,标记区域处理的效果还可以。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









