







- An image is 11worth 16x16 words: Transformers for image recognition at scale.
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby.
- In International Conference on Learning Representations, 2021. 1, 2, 3, 4, 5, 6, 9
ViT原理:
1. 传入transformer之前的预处理:
![![[Pasted image 20230825150251.png|800]]](https://img-blog.csdnimg.cn/5d1fdcc9abca474ea3a8f920b3373855.png)
![![[Pasted image 20230825172749.png|800]]](https://img-blog.csdnimg.cn/29948b5d354441488cfd34f38bc6a96e.png)
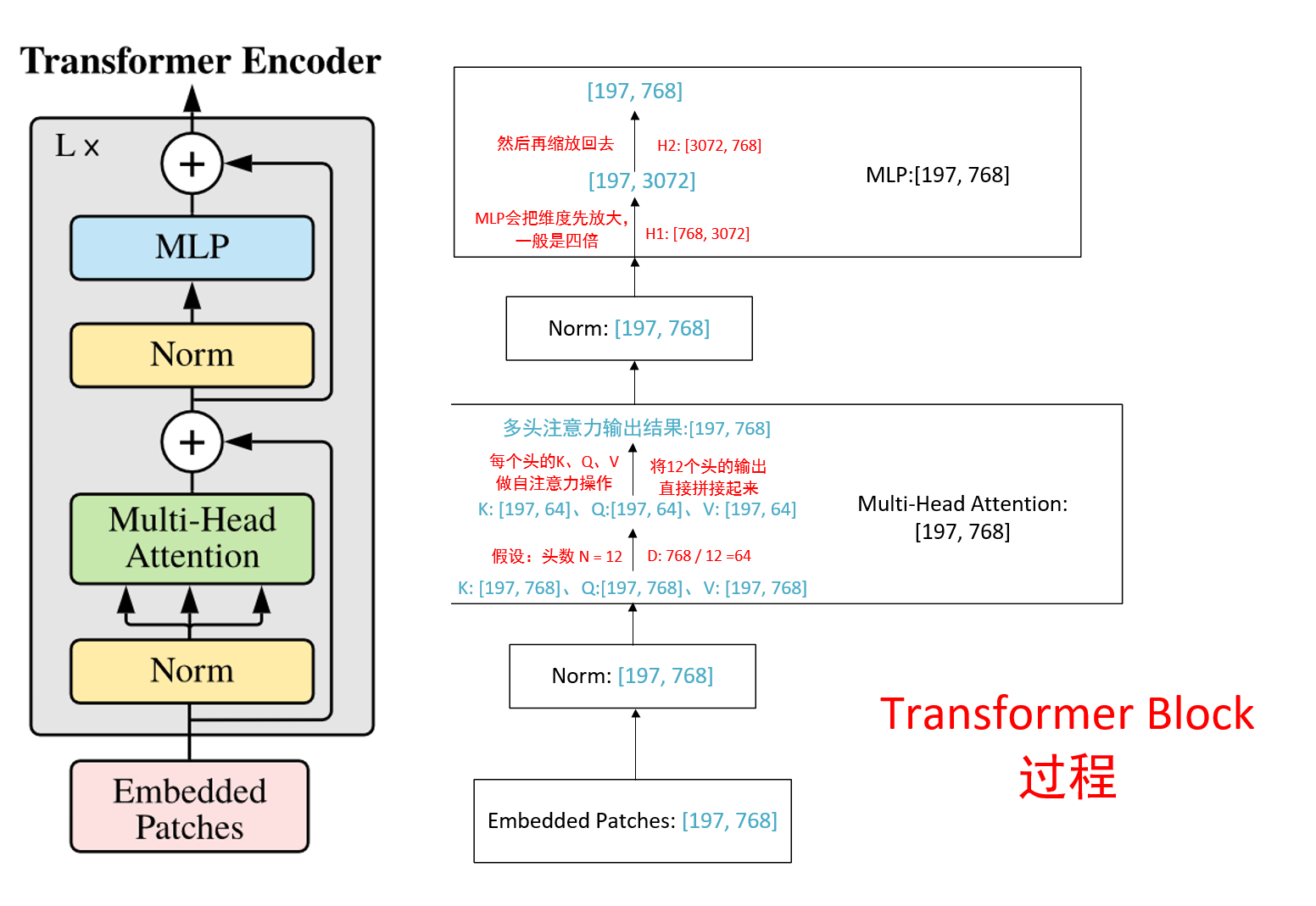
2. Transformer bolck的过程:















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









