







CoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
CoastTerm:用于从海岸科学文献中提取多学科术语的语料库
github: https://github.com/jdelaunay/coastal_area_term_extraction
提出了一个用于沿海情况的专业术语抽取数据集,并使用xmlR和roberta-base/large进行了实验验证,测试xlmr还是能力较强的
文章目录~
1.背景动机
说明术语自动提取的难度:
最近,从基于规则的方法到神经方法,几种 ATE 方法正以不同的方式得到推动。然而,与其他类似的自然语言处理(NLP)下游任务相比,ATE 的性能仍有很大差距,部分原因在于以下几点。
首先,术语本身具有语义定义,指的是特定领域的概念。除了试图定义术语的含义(如 "在某一主题领域使用的、以使用特定语言表达手段为特征的语言"外,在现实生活中,术语的定义并不一致,其定义也因领域和用例而异,因此很难开发通用的术语提取方法。
其次,即使最近做出了一些有价值的努力,但仍缺乏有据可查且透明的特定领域语料库。
2.Model
我们从 Scopus中收集了 6.4 万篇论文,时间跨度从 1980 年到 2023 年,这些论文的摘要 或标题中包含 "沿海地区 "或 “滨海”。
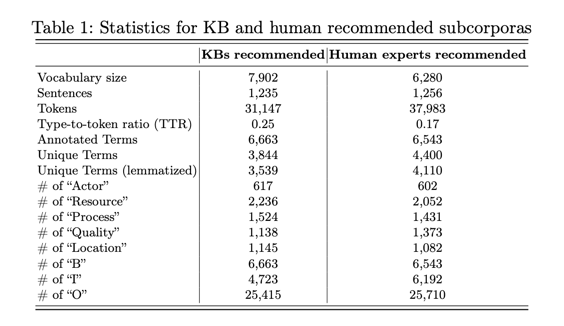
知识库推荐语料库包含 1,235 个注释句子,涉及 61 个不同的关键词,包括 6,663 个注释术语。人工推荐语料库包含 1,256 个注释句子,涉及 92 个不同的关键词,包括 6,543 个注释术语。
数据标注:
对 ATC 采用了相同的标注方案,并在 IOB 标签后添加了术语的类别。
模型选择:
试用了两个语言模型系列,包括基本版本和大型版本:
- 单语预训练模型:我们选择了 RoBERTa
- 多语种预训练模型:我们选择了 XLMR
实验结果:
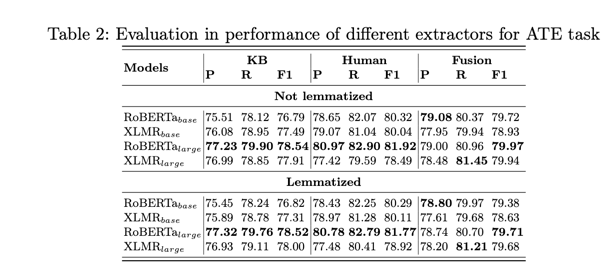
结果表明,在词化和未词化文本方面,XLMRbase 的性能都优于 RoBERTabase。不过,RoBERTalarge 的性能优于 XLMRlarge。相反,在人类推荐的数据集上,单语言模型比多语言模型表现得更好。此外,还发现 XLMRlarge 在这种情况下的表现最差。
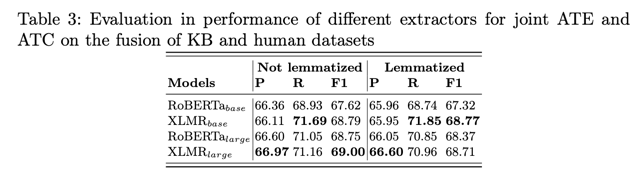
分类器在 ATC 任务中使用知识库推荐数据集和人类推荐数据集的综合表现。多语言分类器的性能优于单语言分类器。此外,在对预测进行词素化处理后,XLMRbase 比 XLMRlarge 表现出更好的性能。
3.原文阅读
Abstract
气候变化对沿海地区(尤其是活跃但脆弱的地区)的影响日益加剧,这就要求各利益相关方和各学科通力合作,共同制定有效的环境保护政策。我们为自动术语提取(ATE)和自动分类(ATC)任务引入了一个新的专业语料库,该语料库由 410 篇有关沿海地区的科学摘要中的 2491 个句子组成。受 ARDI 框架的启发,我们利用单语和多语种transformer模型,自动提取领域术语及其在沿海系统运作中的独特作用,该框架侧重于识别 “因素”(Ac- tors)、“资源”(Resources)、“动力”(Dynamics)和 “相互作用”(Interactions)。评估结果表明,自动术语提取的 F1 得分约为 80%,术语及其标签的 F1 得分约为 70%。这些研究结果很有希望,标志着向开发沿海地区专用知识库迈出了第一步。
1 Introduction
介绍沿海气候问题,并引出术语自动提取(ATE)和分类(ATC:
沿海地区面临着全球变化和人类干预的双重影响,是一个复杂的系统,其中各种动力(物理、化学、生物、社会及其他)不断相互作用。要了解这一系统,就必须将其作为人类固有的环境来研究。在这种情况下,只有考虑到人类的行为,如沿海开发、影响陆地和海洋的活动、资源管理和城市化,才能理解许多因素和机制。
由此产生的跨学科性为术语及其使用的自动分析提供了一个非常有趣的用例。沿岸文献中出现了许多来自环境科学、地理学、生态学和社会学等不同领域的细微术语, 反映了其跨学科性质。术语的自动分析为识别和归类这些特定领域的概念提供了一种系统方法,这些概念对 于理解沿岸环境的动态结构至关重要。通过适应不断发展的术语地貌,这一过程有助于识别沿岸系统中的关键实体,并将不同的学科观点整合到一个连贯的框架中。
ARDI 框架能够识别影响区域的行为体、他们利用的资源、运行中的动力以及这些行为体和资源之间的相互关系。采用 ARDI 框架,利益相关者可以共同构建系统的概念框架,从而促进环境保护政策的制定,并增强科学家对这些区域的理解。然而,在这种错综复杂的系统中确定关键实体是一项相当大的挑战。由于涉及这一主题的科学学科众多,包括但不限于生物学、海洋学、化学和工程学,每年都会产生大量的学术文献,从而加剧了这一困难。在这种情况下,术语自动提取(ATE)和分类(ATC)在挖掘科学文献中蕴含的知识方面发挥着至关重要的作用。
说明术语自动提取的难度:
最近,我们注意到,从基于规则的方法到神经方法,几种 ATE 方法正以不同的方式得到推动。然而,与其他类似的自然语言处理(NLP)下游任务相比,ATE 的性能仍有很大差距,部分原因在于以下几点。首先,术语本身具有语义定义,指的是特定领域的概念。除了试图定义术语的含义(如 "在某一主题领域使用的、以使用特定语言表达手段为特征的语言"外,在现实生活中,术语的定义并不一致,其定义也因领域和用例而异,因此很难开发通用的术语提取方法。其次,即使最近做出了一些有价值的努力,但仍缺乏有据可查且透明的特定领域语料库。
我们的主要贡献有三方面,概括如下:
- 我们为 ATE 和 ATC 提出了两个金标注多学科数据集,重点是沿海地区。
- 受 ARDI 框架的启发,我们提出了一套标签,旨在促进独立于研究领域的系统表征。
- 我们在数据集上比较了一系列 ATE 最新模型,并确定了我们的数据固有的具体挑战。
确定我们的数据所固有的特定挑战。
2 Related Work
2.1.Term extraction datasets
针对术语抽取系统[33],特别是针对科学领域,已经开发了几种人工标注的单语和多语种特定领域再资源。ACL 术语提取和分类参考数据集(ACL RD-TEC)[29] 是评估计算语言学相关科学文献中术语提取和分类的基准。它包括 ACL 文选参考语料库(1978-2006 年)中 300 篇人工标注的文章摘要,分为不同的类别。Au- genstein 等人(2017)为 SemEval 2017 任务 10 引入了一个语料库,其中包含 500 篇来自计算机科学、材料科学和物理学领域的双重注释文档[7]。该语料库解决了关键词在词层面的识别和分类问题,将关键词分为过程、任务和材料三类。
关于环境研究,SPECIES-800[27]是一个由 800 篇人工标注摘要组成的语料库,用于识别分类群的提及。该语料库通过从各种期刊中随机抽取 100 篇 MEDLINE 摘要来构建,其中包含 718 个独特物种的 3,708 次提及,并以 1,503 个独特名称作为参考。Biodi- vNERE [1] 为生物多样性研究中的命名实体识别(NER)和关系抽取(RE)提供了两个黄金标准语料库,这些语料库由生物多样性元数据和摘要创建,并经专家人工验证。该语料库包含来自 150 篇文档的 2,398 个语句,其中 NER 语料库可识别生物、环境、质量、位置、现象和物质等实体。COPIOUS [26] 是来自生物多样性遗产图书馆的黄金标准语料库。该语料库由 668 篇文档中的 26K 多个句子组成,将 28K 个实体分为五类:分类群名称、地理位置、栖息地、时间表达和人名。
然而,据我们所知,在沿海地区或相关领域(如海洋)的跨学科研究中,还没有用于术语抽取的注释语料库。因此,CoastTerm 是这方面的一项开创性工作,它为研究沿海地区的详尽的跨领域和多学科知识图谱构建系统铺平了道路。
2.2.Term extraction methods
经典的术语提取方法主要依赖于语言学或统计学方面[13],或将两者结合起来[17],并应用基于规则或机器学习的方法来提取候选术语。最近,表征学习和神经网络的引入使得各种文本嵌入技术被应用于术语提取,包括局部-全局[2]、非上下文嵌入(如 GloVe6、Word2Vec、skip-gram [2,3,21,41])、上下文词嵌入(如 Flair7、BERT [21,5,32])以及它们的组合(如堆叠 Flair + BERT [5,32])。
神经架构也被用作端到端术语提取系统,目前大多数系统侧重于基于标记的模型 [15,22]。在基于标记的机制中,任务被表述为:(1) 序列分类,即使用基于 BERT 的模型的不同变体(如 BERT、RoBERTa 和 XLMR),为给定句子中固定长度的每个可能的 n-gram 指定术语的二进制标签;或 (2) 标记分类,即使用不同的语言模型,按照 IOB 注释格式为给定句子中的每个词指定标签。
随着transformer的出现,一些预先训练好的语言模型被用作标记分类器。最重要的是,XLMR 现在被认为是多种语言的标杆。跨领域和跨语言学习也被应用到这些基准中,以在缺乏可用注释数据的情况下提高提取性能。
此外,还有一些关于 ATE 的实验,采用基于跨度的方法[40]或应用考虑 Seq2Seq 模型的生成模型(如 mBART[22])来更有效地提取候选词。不过,虽然基于跨度的方法显示出了其潜力,但生成模型的性能仍受到质疑。
就我们的研究领域而言,Zhao 等人(2022 年)探索了从海事决策操作句子中提取知识的方法[42];Andersen 等人(2022 年)建议开发一个语料库,以培养与挪威海事话语相关的专业术语[4];Mouratidis 等人(2022 年)在希腊语海事主题的法律文件中进行术语提取[25]。与我们的工作类似,在岩溶研究领域,TermFrame8 是通过从英语和斯洛文尼亚语岩溶语料库中提取术语和三连词构建的 KG [28, 39]。EcoLexicon [11, 12] 是一个专门的环境知识库,包含六种语言(英语、法语、德语、现代希腊语、俄语和西班牙语)。此外,对于 NER 任务,TaxoNERD [23] 的目标是识别生态文档中的分类群提及,而 AGRONER [38] 则采用了针对农业领域的无监督 NER 技术,将扩展的 BERT 模型与潜在 Dirichlet 分配(LDA)主题建模相结合。
3 CoastTerm corpus for term extraction
3.1.Annotation process
我们从 Scopus9 中收集了 6.4 万篇论文,时间跨度从 1980 年到 2023 年,这些论文的摘要 或标题中包含 "沿海地区 "或 “滨海”。我们最初随机选取了 600 篇摘要进行人工注释,其中普通文章占 60%,调查报告占 40%。注释工作首先邀请了两名地球科学专业的本科硕士生参与,并为他们的贡献提供报酬。我们向这些学生提供了注释示例和指南,以便他们进行文档级联合实体和关系提取任务,其中包括嵌套 ATE 和 ATC、核心参照解析和文档级关系提取。注释指南是由一名计算机科学和沿岸再搜索博士生和一名领域专家在本体论专家的协助下编写的。我们只对提供海岸带功能信息的句子进行了注释,避免了对文章中使用的方法进行描述的句子。
我们对 ARDI 框架进行了调整,以提取与科学摘要中描述的系统功能有关的信息。因此,我们为 ATC 指定了以下标签: “行为者”(消耗资源和/或启动流程的利益相关者)和 “资源”(利益相关者使用的货物、产品、设施和元素,包括植物和动物)。根据基本形式本体论(BFO),我们用环境本体论(ENVO)定义的 "过程 "取代了 ARDI 中的 "动态 "标签,"过程 "指的是影响系统并引起变化的环境、社会或经济过程。为了提高提取信息的精确度,我们引入了表型与性状本体论(PATO)中的 "质量 "标签,指高度、浓度或特异性,并添加了 "位置 "标签。
除了两名地球科学专业的学生外,注释过程中还有同一位领域专家和博士生,他们同时对论文进行注释。所有注释者都熟悉注释工具 IN- CEpTION [18]。在两个月的时间里,该活动的目标是实现双注释者覆盖全部注释摘要的 60%。最终,有 215 篇摘要得到了注释,平均克里彭多夫α[20] 为 43%,这表明注释的一致性尚可,但不足以直接使用数据集,未达到直接使用数据集所需的最低阈值(66%),这凸显了术语人工注释的难度。随后,博士生根据指南对注释进行了整理。
我们使用了三个与领域相关的知识库(KBs)(即 AGROVOC10、GEMET(GEneral Multilingual Environmental Thesaurus)11、AFO(Agriculture and Forestry Ontology)12 和 TAXREF-LD13),对 195 篇摘要的二级子集中的相关术语进行了预先标注。这一过程大大有助于完善术语边界。然后,博士生注释员按照既定指南,利用从初始注释过程中获得的见解进行注释。随后,最初完全由人工标注的子集与知识库推荐的子集进行了同质化,生成了两个用于沿海地区研究的数据集。在本研究中,这两个数据集都经过了人工调整,删除了表示核心参照的关系和代词,以便进行术语提取。
3.2.Dataset description
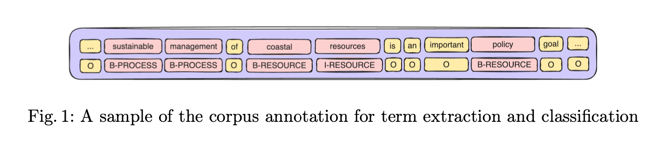
知识库推荐语料库包含 1,235 个注释句子,涉及 61 个不同的关键词,包括 6,663 个注释术语。人工推荐语料库包含 1,256 个注释句子,涉及 92 个不同的关键词,包括 6,543 个注释术语。从表 1 中可以看出,两个数据集的标签分布是一致的。此外,"演员 "标签的使用率较低,而 "资源 "标签的使用率最高。这两个数据集总共包含 101 个独特的关键词,其中 “水产科学”、“海洋学”、“生态学、进化论、行为学和系统学”、“生态学”、“污染”、“地球和行星科学”、“环境科学”、“管理、监测、政策和法律”、"水科学和技术 "以及 "地理学、规划和发展 "最为突出。前 100 个常用词的比较显示,两个语料库之间有 52% 的明显重叠。总的来说,两个数据集共有 751 个共同术语(如果进行词素化处理,则共有 730 个)。我们将每篇文章中 70% 的注释句子分配到训练集,10% 分配到验证集,20% 分配到测试集。图 1 是一个注释示例。
4.Experiments
为了评估 CoastTerm 所面临的挑战,我们使用最先进的 ATE 进行了大量实验,并将评估扩展到 ATC。我们的深入分析有助于讨论与沿海地区有关的跨学科 ATE 和 ATC 研究的潜在未来发展轨迹。
4.1.Models
我们认为 ATE 是一项序列标注任务,模型会使用 IOB 标注机制为文本序列中的每个标记返回一个标签。我们对 ATC 采用了相同的标注方案,并在 IOB 标签后添加了术语的类别。
我们试用了两个语言模型系列,包括基本版本和大型版本:
- 单语预训练模型:我们选择了 RoBERTa [24],这是一个基于转换器的模型,以自我监督的方式在大量英语数据语料库上进行预训练。
- 多语种预训练模型:我们选择了 XLMR [9],这是一个基于转换器的模型,在 2.5TB 的 CommonCrawl 过滤数据(包含 100 种语言)上进行了预训练。这个多语言版本的 RoBERTa 在 ATE 中对资源丰富的语言(如英语)实现了基准性能[30, 34]。
4.2.Evaluation Metrics
为了评估 ATE 系统在人类推荐和知识库推荐数据集上的性能,我们将从整个测试集中提取的候选独特术语列表与测试集的黄金标准并列。我们使用已词化和未词化的术语进行了测试。评估采用严格的匹配标准,指标包括精确度(P)、召回率(R)和微观 F1 分数(F1)。对于 ATC 任务,评估过程保持不变,但每个术语都附有相应的标签。
4.3.Results
表 2 列出了单语和多语种分类器在人类推荐和知识库推荐的数据集上完成 ATE 任务的性能。关于知识库推荐的数据集,结果表明,在词化和未词化文本方面,XLMRbase 的性能都优于 RoBERTabase。不过,RoBERTalarge 的性能优于 XLMRlarge。相反,在人类推荐的数据集上,单语言模型比多语言模型表现得更好。此外,我们还发现 XLMRlarge 在这种情况下的表现最差。我们还对 KB 数据集和人类推荐数据集进行了组合实验。这种配置在表 2 中被称为 “融合”,其中人类推荐数据集的 20% 和 40% 分别分配给验证集和测试集。知识库推荐数据集与剩余 40% 的人类推荐数据集组成训练集。报告显示,单语模型的性能优于多语模型。
表 3 显示了分类器在 ATC 任务中使用知识库推荐数据集和人类推荐数据集的综合表现。值得注意的是,多语言分类器的性能优于单语言分类器。此外,在对预测进行词素化处理后,XLMRbase 比 XLMRlarge 表现出更好的性能。
4.3.Error analysis
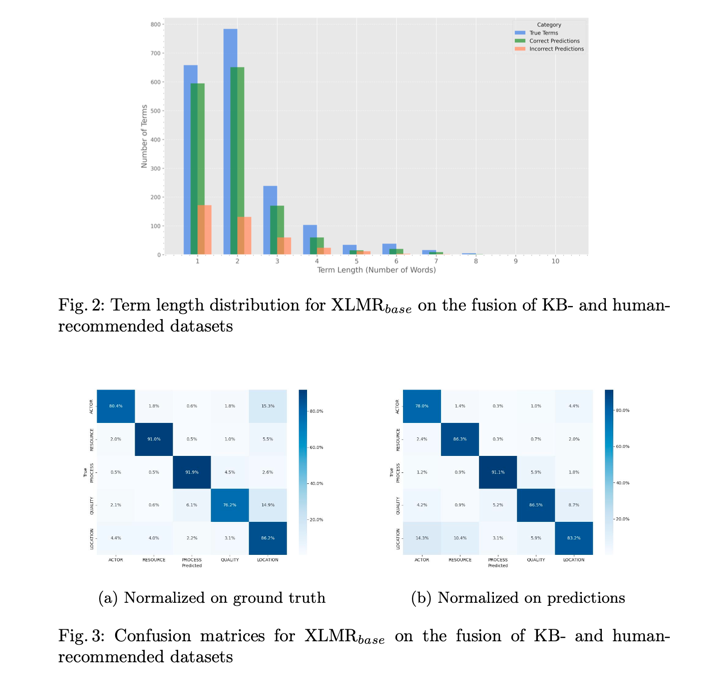
为了评估术语长度对模型性能的影响,我们检查了相对于术语长度的正确和错误预测比例。图 2 显示,在 XLMRbase 中,随着术语长度的增加,模型在准确预测方面遇到了更大的困难,因此可能会预测更短的术语。不过,绝大多数术语都由一个或两个单词组成,这减轻了对性能的负面影响。所有模型都存在这种情况。
我们还在图 3 中报告了 ATC 的混淆矩阵。结果是一致的,因为模棱两可的情况可能来自这样一个事实,即一个实体可能在某一点上是 “行为体”,而在另一点上是 “位置”(例如国家);或者根据上下文,可能是 "位置 "和 "资源 "或 “质量”。
5 Conclusion and Future Works
我们介绍了 CoastTerm,这是一个包含 2491 个黄金标注句子的语料库,用于与沿海地区相关的跨学科术语自动提取和分类。通过调整 ARDI 框架,我们提供了适用于不同领域的综合标签。在 ATE 和 ATC 任务中对最先进的单语和多语模型进行基准测试,结果令人鼓舞,为沿海地区领域的跨学科知识库建设铺平了道路。


















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









