







LLM—文献摘要生成(文献综述任务),人工流程指导的文献总结生成,论文理解与阅读:ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary
ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary
ChatCite: 为比较文学摘要提供人工工作流程指导的 LLM 代理
paper: https://arxiv.org/abs/2403.02574
github:
本文介绍的是综述论文生成任务中的第二个子任务,即文献摘要生成,可以理解为文献总结,他通过设计两个生成器的方法,提升摘要生成的准确性和稳定性。
- 关键元素生成器:从每篇论文和给出的工作描述中生成给定问题的关键元素信息。(为了充分保留文献摘要的关键要素)
- 比较总结生成器: 根据给出的工作描述中的关键元素,每篇参考文献中的关键元素和比较总结的增量生成结果,由比较总结生成器生成摘要,每篇文献生成多个摘要(克服 LLM 生成的文献综述缺乏比较分析和组织结构的难题)
- 反思评估器:对生成的摘要进行投票,统计得分,并根据得分排序,选择topk个候选结果作为下一轮的增量生成。 (为了提高文本生成的稳定性)
文章目录~
1.背景动机
撰写文献综述需要搜索相关文献并进行详细的比较总结,包括两个步骤:收集文献,然后根据收集到的资料生成文献摘要。
现有文献摘要生成方法存在的问题:
现有的自动生成文献摘要的方法存在以下问题:
- 机器生成的文献摘要会遇到信息遗漏、语言不够流畅、对比分析不足。
- 通过提取和抽象方法生成的摘要可能会遗漏关键信息,导致生成的摘要缺乏关键点或发现。
- 自动化系统可能缺乏深入对比分析的能力,可能导致生成的文献摘要缺乏对该领域相关研究的全面了解。
介绍LLM可以用来生成摘要,并分析之前研究的缺陷:
现开始探索利用 LLM 生成自动文献摘要,提出了一种思维链(CoT)提示方法,以增强大型语言模型执行复杂推理的能力。但是之前基于LLM的研究存在问题:
- 研究重点问题:关于文献综述的研究更多地关注如何更准确地检索相关论文,而忽视了对文献摘要的研究**。**他们仅使用简单的 CoT 指导来生成文献摘要,导致缺乏比较和组织分析
- LLM问题:LLM尽管可以生成流畅的语言,但由于其不可预知性和随机性,很难持续生成具有可比性的文献摘要。这些模型的长度限制要求采用两步摘要法,增加了摘要生成过程中信息遗漏的风险。
介绍本文工作—独立文献总结任务,提出新的生成摘要评估方法:
在这项工作中,专注于独立文献总结任务,旨在通过一定的文献集和对提出的工作的描述生成全面的比较文献总结,提出ChatCite一种基于 LLM 的、由人类工作流引导的代理。
2.Model
1.介绍文献综述任务,指出本文解决的子任务:
文献综述任务可分解为两个子任务:相关论文检索和文献摘要生成。这项工作的重点是文献摘要生成这一独立任务。根据提出的工作描述 D D D 和一定的参考文献集 R = { r 1 , r 2 , . . . , r n } R=\{r_{1},r_{2},...,r_{n}\} R={r1,r2,...,rn} 生成文献摘要,即给定 D D D 和 R R R,代理生成文献摘要 Y = f ( D,R ) Y=f(\textit{D,R}) Y=f(D,R)。
1.1.介绍现有摘要生成(使用简单的CoT)的缺陷:
现有工作中利用简单的思维链(CoT)指导,面临以下问题:
缺失的关键要素: 由于 LLM 的窗口限制,采用两步法,即总结和生成文献综述。然而,这可能会导致关键要素在总结过程中丢失。即使可以直接生成整个文献综述,使用整个文本也可能导致对关键要素理解的错误和要素的丢失。
缺乏比较分析: 比较分析在文献总结中至关重要,需要分析现有研究方法的局限性和优势,重点关注方法、实验设计、数据集使用等方面的异同。直接使用 CoT 生成的结果往往缺乏比较分析。
缺乏组织结构:仅由CoT生成的文献摘要往往对每篇论文都是离散的,缺乏对类似作品的分类和文献综述的组织结构。
1.2.介绍本文提出的人类工作流程为指导的LLM代理过程:
本文提出的用于比较文献总结的 LLM 代理,由两个模块组成:关键要素提取器和反射式增量生成器。
整个生成过程如下:
- 给出的工作描述和参考文献集中的参考文献最初分别使用关键要素提取器进行处理。
- 使用参考文献集迭代生成文献摘要。在每次迭代中,使用比较摘要器生成比较分析摘要。然后,使用反思评价器对生成的候选结果进行投票,根据投票得分进行排序,并保留排名前 n c n_{c} nc 的结果。不断迭代,直到处理完所有参考文献。最终的输出结果是根据所生成的相关工作摘要中最高的投票得分选出的。
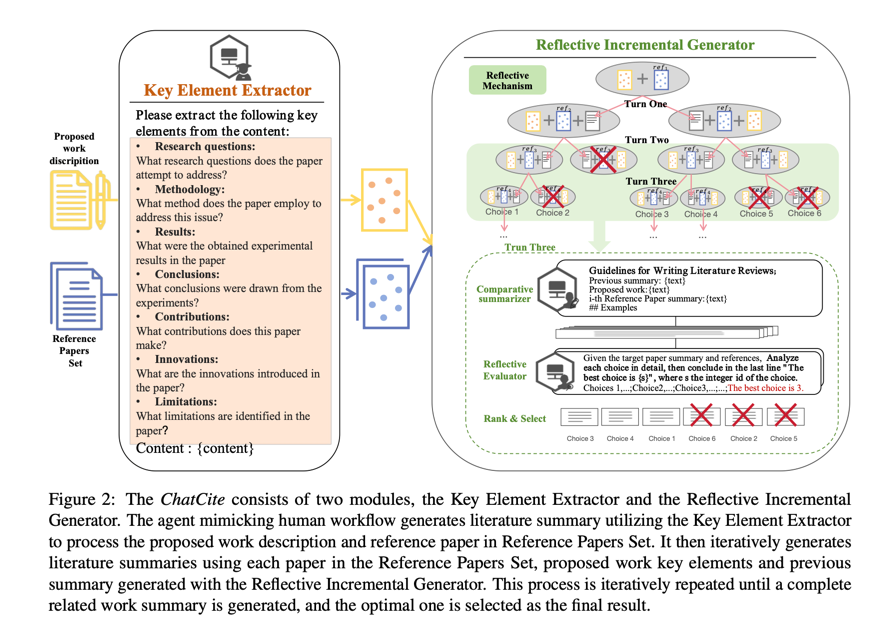
图 2:ChatCite 由两个模块组成:关键要素提取器和反射增量生成器。代理模仿人类工作流程,利用关键要素提取器处理给出的工作描述和参考文献,生成文献摘要。然后,它利用每篇论文、给出的工作关键要素和之前用 "反思增量生成器 "生成的摘要,反复生成文献摘要。这一过程反复进行,直到生成完整的相关工作摘要,并选择最优摘要作为最终结果。
2.1.Key Element Extractor
2.关键元素提取器:
为了充分保留文献摘要的关键要素,本文提出了七个简单的指导性问题。将这些问题和需要提取的内容串联起来作为提示,指导 LLM 提取关键要素,这些问题为 Q e = [ q 1 , q 2 , . . . , q 7 ] Q_{e}=\left[q_{1},q_{2},...,q_{7}\right] Qe=[q1,q2,...,q7]。这些问题 Q e Q_{e} Qe和论文内容 C C C串联起来形成了关键要素提取提示 P e = [ Q e , C ] P_{e}=\left[Q_{e},C\right] Pe=[Qe,C]。使用 LLM 作为提取解码器提取关键元素。
2.2.Reflective incremental Generator
3.反思增量生成器:
为了克服 LLM 生成的文献综述缺乏比较分析和组织结构的难题,设计了反思增量生成器。
生成器使用比较总结器继续撰写比较总结,将前一轮的结果与提出的工作和参考文献的关键要素结合起来。然后,它利用反思评估器过滤生成的结果。这一过程会交替应用于参考文献集中的每篇参考文献,直到处理完所有参考文献。最终,最佳结果将被保留,作为模型生成的输出结果。
3.1.Comparative Summarizer,比较总结器:
对于第 i 轮,基于提出的工作关键要素pro、第 i 篇参考文献的关键要素 r e f i ref_{i} refi和比较总结指导,按顺序生成摘要 s∈ Si-1,每次生成 ns 样本。Si = {G(Dg, pro, refi, s, ns), ∀s∈ Si-1}。为了增强生成摘要的可比性和条理性,提供了比较摘要指南: “考虑参考文献与目标论文之间的关系,以及之前完成的相关工作中的现有参考文献,同时保留之前完成的相关工作中提及的所有参考文献的内容”。
3.2.Reflective Mechanism,反思评估器:
由于文本生成任务中存在很大的不确定性,采用反射生成来提高生成段落的质量和稳定性。
- 使用 LLM 作为反思评估器,每轮对生成的结果进行nv次投票,然后对投票结果进行统计分析,得到投票得分 Ei = E(De,Si′)。
- 然后,对得分进行排序,并保留排名前列的 n c n_{c} nc 候选者 S i = { S t , t ∈ S o r t ( E i ) ( 1 , n c ) } S_{i}=\{S_{t},t\in Sort(E_{i})(1,n_{c})\} Si={St,t∈Sort(Ei)(1,nc)} 。这些选定的候选结果将用于下一轮增量生成。

2.3. 使用的模型和提示
Model,模型:
对于 LLMs 基线,采用了 16K 上下文窗口的 GPT-3.5 模型和 128K 上下文窗口的 GPT-4.0 模型。
prompt,提示设计:
在zero-shot的设置中,对于 GPT- 3.5 模型,由于上下文窗口的限制,采用了两步生成法:摘要+生成
- 提示 [ps] =“Summarize the current article, preserving as much as possible information. Con- tent:{content}” 进行总结。
- 在生成相关工作部分时,提示 [pg] =“Generate the related work section based on the given target paper summary and its references sum- mary. Read the Target Paper Content: {Target}. References content: {References}”。
对于 GPT-4.0,[pg] 可直接用于摘要。
在few-shot的设置中,添加说明 “Follow the writing style of the example but without including any content from the example. {Examples}”。
3.原文阅读
Abstract
文献综述是研究过程中不可或缺的一步。它有助于理解研究问题,了解研究现状,同时对以前的工作进行比较分析。然而,文献总结既具有挑战性又耗费时间。以往基于 LLM 的文献综述研究主要集中在整个过程,包括文献检索、筛选和总结。然而,对于总结步骤,简单的 CoT 方法往往缺乏提供广泛比较总结的能力。在这项工作中,我们首先关注独立的文献总结步骤,并引入了ChatCite-一个具有人类工作流程指导功能的 LLM 代理,用于比较文献总结。该代理通过模仿人类工作流程,首先从相关文献中提取关键要素,然后利用反思增量机制生成摘要。为了更好地评估所生成摘要的质量,我们参考人类的评估标准,设计了基于 LLM 的自动评估指标 G-Score。在实验中,ChatCite 代理在多个维度上都优于其他模型。由_ChatCite_生成的文献摘要还可以直接用于起草文献综述。
1 Introduction
介绍文献综述的问题:
随着学术研究的飞速发展,学者们必须深入研究现有文献,以了解过去的研究,认识未来的研究趋势,并找到各自领域的创新方法。撰写文献综述需要搜索相关文献并进行详细的比较总结。这通常包括两个主要步骤:收集文献,然后根据收集到的资料生成文献摘要。然而,要组织一篇高质量的文献综述,学者们必须对大量相关著作进行深入分析、组织、比较和整合,这通常是一项具有挑战性且耗时的任务。
现有文献摘要生成方法存在的问题:
因此,Hoang 和 Kan(2010 年)提出了自动生成文献摘要的方法。然而,
- 机器生成的文献摘要往往会遇到信息遗漏、语言不够流畅、对比分析不足等难题。
- 在传统模式中,由于模型的局限性,通过提取和抽象方法生成的摘要可能会遗漏关键信息,导致生成的摘要缺乏关键点或发现。
- 有些自动化系统可能缺乏深入对比分析的能力,可能导致生成的文献摘要缺乏对该领域相关研究的全面了解。
介绍LLM可以用来生成摘要,并分析之前研究的缺陷:
近年来,随着大型语言模型(LLMs)的快速发展,其在自然语言生成任务中的强大能力已经在各种任务中得到了证明,这为处理较长文本和生成综合摘要提供了可能性。研究人员已经开始探索如何利用 LLM 生成自动文献摘要。Wei 等人(2023 年)提出了一种思维链(CoT)提示方法,以增强大型语言模型执行复杂推理的能力。CoT 允许 LLM 设计自己的计划,从而生成更符合人类偏好的文本。
之前的研究问题:最近,Huang 和 Tan(2023 年)以及 Agarwal 等人(2024 年)关于文献综述的研究更多地关注如何更准确地检索相关论文,而忽视了对文献摘要的研究。他们仅使用简单的 CoT 指导来生成文献摘要,导致缺乏比较和组织分析。
大模型应用问题:大型语言模型尽管可以生成流畅的语言,但由于其不可预知性和随机性,很难持续生成具有可比性的文献摘要。这些模型的长度限制要求采用两步摘要法,增加了摘要生成过程中信息遗漏的风险。
介绍本文工作—独立文献总结任务,提出新的生成摘要评估方法:

在这项工作中,我们专注于独立文献总结任务,旨在通过一定的文献集和对提出的工作的描述生成全面的比较文献总结,如图 1 所示。为了应对上述挑战,我们的工作提出了_ChatCite_-一种基于 LLM 的、由人类工作流引导的代理。与简单的 CoT 提示方法不同,该代理是在人类工作流程指导下设计的,而不是以黑箱方式制定生成流程,从而确保更稳定地生成更高质量的通用摘要。
此外,生成任务的质量评估一直是个难题。之前的文献摘要研究主要依赖于文本摘要指标,如 ROUGE。然而,传统的文本摘要评价指标(如 ROUGE)不足以评估文献摘要的质量。要确保生成的文献摘要真正符合要求,需要涵盖多个维度的更全面的评价标准。因此,我们结合人类对文献综述的研究 Justitia 和 Wang(2022 年)从多个维度制定了文献综述的评价标准,并提出了基于 LLM 的自动评价指标 G-Score。实验结果表明其与人类评价结果一致。
在本文中,我们将对我们框架的主要贡献总结如下:
- 我们专注于文献综述中的独立文献总结步骤,并引入了_ChatCite_-一个具有人类工作流程指导的用于比较文献总结的 LLM 代理。
- 在文献总结研究的基础上,我们提出了文献总结的多维质量评估标准。此外,我们还提出了基于 LLM 的自动评估指标 G-Score,其结果与人类偏好一致。
- 实验结果表明,_ChatCite_在所有质量维度上都优于其他基于LLM的文献摘要方法。由 ChatCite 生成的文献摘要可直接用于起草文献综述。
- 我们证明,在人类工作流程的指导下,大型语言模块有能力有效地对多篇文献进行全面的比较总结。因此,我们推断大语言模型(LLM)有潜力处理更复杂的推理总结任务。
2 Related Work
近年来,关于生成文献摘要的研究非常丰富,Hoang 和 Kan(2010 年)提出了基于提取方法的主题相关作品摘要自动生成相关作品摘要的初步建议。为了生成引文句子,Xing 等人(2020)采用了具有交叉注意机制的多源指针生成网络,AbuRa’ed 等人(2020)利用神经序列学习过程的 ARWG 系统,Ge 等人(2021)提出了基于背景知识和内容的 BACO 框架。此外,Chen 等人(2021 年)采用关系感知相关作品生成器(RRG)生成引文段落,而 Chen 等人(2022 年)则采用对比学习生成目标感知相关作品段落。然而,传统的生成方法由于其模型的大小以及缺乏连贯和程序化的语言连续性,无法生成全面连贯的文献综述。
大型语言模型(LLMs),如GPT(Radford等人(2019),Brown等人(2020)),已经在自然语言生成任务中展示了其强大的能力。Huang和Tan(2023)关于在撰写科学评论文章时使用Chat-GPT等人工智能工具的研究揭示了人工智能在学术写作中的潜在好处和缺点。基于这些见解,Agarwal 等人(2024 年)介绍了 LitLLM 工具包,该工具包通过采用检索增强生成(RAG)原则、专门提示和指导性技术,克服了生成幻觉内容和忽略最新研究等难题。然而,这些研究仅在文献综述的搜索和筛选过程中应用了简单的思维链(CoT),导致可读性较差。相比之下,_ChatCite_侧重于文本摘要这一独立任务,旨在生成更高质量的摘要。
此外,本文还引入了多维 G-Score 评价指标,该指标的灵感来自于之前通过思维链方法使用大型语言模型(LLM)来评价自然语言生成(NLG)系统质量的尝试(Liu 等人(2023 年)、Goyal 等人(2023 年)),与传统的 ROUGE 指标(Lin(2004b))相比,该指标更符合人类评价。
3 ChatCite
介绍文献综述任务,并指出本文所关注的子任务:
文献综述任务可分解为两个子任务:相关论文检索和文献摘要生成。这项工作的重点是文献摘要生成这一独立任务。我们的任务是根据提出的作品描述 D D D 和一定的参考文献集 R = { r 1 , r 2 , . . . , r n } R=\{r_{1},r_{2},...,r_{n}\} R={r1,r2,...,rn} 生成文献摘要。给定 D D D 和 R R R,我们的代理生成文献摘要 Y = f ( D,R ) Y=f(\textit{D,R}) Y=f(D,R)。
介绍现有摘要生成(使用简单的CoT)的缺陷
与新闻摘要等其他类型的摘要不同,现有工作中利用简单的思维链(CoT)指导,由大型语言模型直接生成的文献摘要主要面临以下问题:
缺失的关键要素: 由于 LLM 的窗口限制,直接生成完整的文献综述具有挑战性。通常情况下,我们采用两步法,即总结和生成文献综述。然而,这一过程可能会导致关键要素在总结过程中丢失。即使可以直接生成整个文献综述,使用整个文本也可能导致对关键要素理解的错误和这些要素的丢失。
缺乏比较分析: 比较分析在文献总结中至关重要,需要分析现有研究方法的局限性和优势,重点关注方法、实验设计、数据集使用等方面的异同。直接使用 CoT 生成的结果往往缺乏比较分析。
**缺乏组织结构:仅由CoT生成的文献摘要往往对每篇论文都是离散的,缺乏对类似作品的分类和文献综述的组织结构。
介绍本文提出的人类工作流程为指导的LLM代理过程:
为了应对这些挑战,我们提出了一种用于比较文献总结的 LLM 代理,它由两个模块组成:关键要素提取器和反射式增量生成器(如图 2 所示)。在这一过程中,我们利用大型语言模型作为生成和评估组件,省去了额外的模型训练,并在一定程度上提高了生成文本的质量。
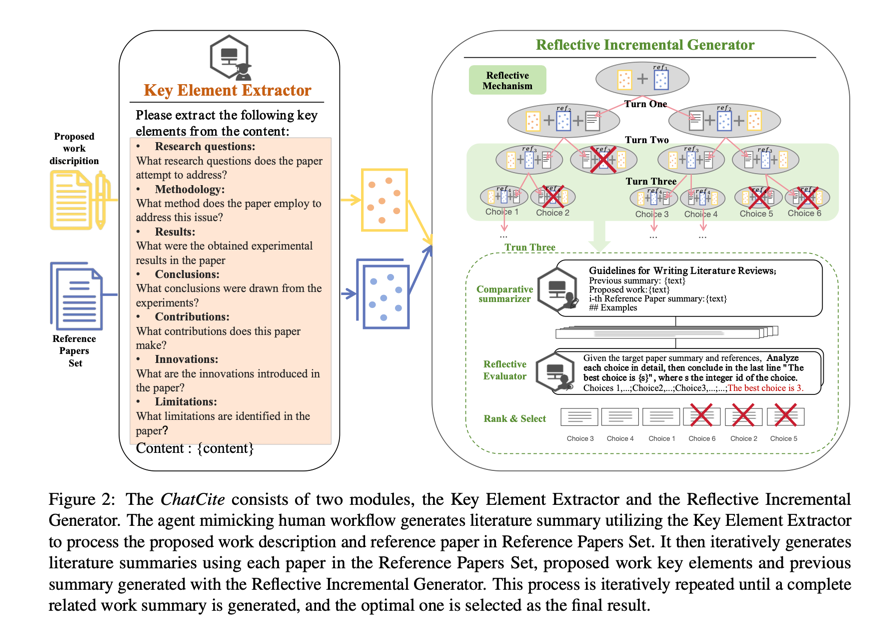
以人类工作流程为指导的生成过程如下:
- 给出的工作描述和参考文献集中的参考文献最初分别使用关键要素提取器进行处理。
- 使用参考文献集迭代生成文献摘要。在每次迭代中,使用比较摘要器生成比较分析摘要。然后,使用反思评价器对生成的候选结果进行投票,根据投票得分进行排序,并保留排名前 n c n_{c} nc 的结果。不断迭代,直到处理完所有参考文献。
最终的输出结果是根据所生成的相关工作摘要中最高的投票得分选出的。
在本节中,我们首先详细阐述关键元素提取器**(SS3.1)和迭代生成器模块(SS3.2)**的具体内容。
3.1.Key Element Extractor
关键元素提取器:
为了充分保留文献摘要的关键要素,我们根据 Justitia 和 Wang(2022 年)对文献综述的分析,提出了七个简单的指导性问题。我们将这些问题和需要提取的内容串联起来作为提示,指导 LLM 提取关键要素。对于每个要素,我们都设置了一个简单的问题(如图2所示)来指导模型进行提取,这些问题为 Q e = [ q 1 , q 2 , . . . , q 7 ] Q_{e}=\left[q_{1},q_{2},...,q_{7}\right] Qe=[q1,q2,...,q7]。这些问题 Q e Q_{e} Qe和论文内容 C C C串联起来形成了关键要素提取提示 P e = [ Q e , C ] P_{e}=\left[Q_{e},C\right] Pe=[Qe,C]。使用 LLM 作为提取解码器提取关键元素并将其存储在内存中。
3.2.Reflective incremental Generator
反思增量生成器:
为了克服 LLM 生成的文献综述缺乏比较分析和组织结构的难题,我们设计了反思增量生成器。生成器使用比较总结器继续撰写比较总结,将前一轮的结果与提出的工作和参考文献的关键要素结合起来。然后,它利用反思评估器过滤生成的结果。这一过程会交替应用于参考文献集中的每篇参考文献,直到处理完所有参考文献。最终,最佳结果将被保留,作为模型生成的输出结果。
3.2.1 Comparative Summarizer
介绍比较总结器:
对于第 i 轮,基于提出的工作关键要素 pro、第 i 篇参考文献的关键要素 r e f i ref_{i} refi和比较总结指导,按顺序生成摘要,每次摘要 s∈ Si-1,每次生成 ns 样本。Si = {G(Dg, pro, refi, s, ns), ∀s∈ Si-1}。在此,为了增强生成摘要的可比性和条理性,我们提供了比较摘要指南: “考虑参考文献与目标论文之间的关系,以及之前完成的相关工作中的现有参考文献,同时保留之前完成的相关工作中提及的所有参考文献的内容”。
3.2.2 Reflective Mechanism
介绍反思评估器:
由于文本生成任务中存在很大的不确定性,我们采用反射生成来提高生成段落的质量和稳定性。在这里,我们使用 LLM 作为反射评估器,每轮对生成的结果进行 nv 次投票,然后对投票结果进行统计分析,得到投票得分 Ei = E(De,Si′)。
然后,我们对得分进行排序,并保留排名前列的 n c n_{c} nc 候选者 S i = { S t , t ∈ S o r t ( E i ) ( 1 , n c ) } S_{i}=\{S_{t},t\in Sort(E_{i})(1,n_{c})\} Si={St,t∈Sort(Ei)(1,nc)} 。这些选定的候选结果将用于下一轮增量生成。这种方法有助于识别最有希望的结果,确保生成文本的质量,并提高生成的稳定性。
3.2.3 Reflective Incremental Generator Algorithm
整个反思增量生成器算法的流程:
在实现反思增量生成的过程中,我们从树的广度优先搜索算法(算法 1)中汲取了灵感。

注: G ( ) G() G() 对应 SS3.2.1 中描述的比较总结器函数, E ( ) E() E() 对应 SS3.2.2 中描述的反思评价函数。在每一步中,都会保留一个包含 n c n_{c} nc 最有希望生成结果的集合,其中树的深度等于相关文献集合中的文档数, S t ′ S^{\prime}_{t} St′ 包含 n c n_{c} nc * n s n_{s} ns 结果,而 S i − 1 S_{i-1} Si−1 和 S i S_{i} Si 则各包含 n c n_{c} nc 结果。
4 G-Score: LLM-based automatic Evaluation Metrics
对生成任务进行评估一直是一项挑战。以往的文献摘要研究主要依赖于文本摘要指标,如 ROUGE。然而,ROUGE 等传统的文本摘要评价指标在衡量文献摘要质量方面存在不足。关键是要在各个维度上采用更全面的评价标准,以保证生成的文献摘要符合必要的标准。在此,受 G-Eval Liu 等人(2023 年)的启发,我们尝试使用 LLM 进行评估。我们在 Justitia 和 Wang(2022 年)对文献摘要的研究基础上,建立了用于自动评估的六维指标。
Evaluation Steps:
我们使用大型语言模型(LLM)对通用质量的六个维度进行评分,并从一系列模型生成的摘要中投票选出最佳摘要。特别是,为了确保评价的公平性和一致性,我们在一次对话中同时对多个模型生成的结果进行评分和投票。
评价标准:一致性 (1-5):生成的摘要与黄金摘要之间的内容一致性。生成的摘要不得包含与黄金摘要冲突的内容。
连贯性(1-5):生成的摘要中语言连贯的质量,不应只是一堆相关信息。
比较性(1-5):评估所生成的摘要在多大程度上对参考文献和建议的工作进行了比较分析。是否对类似的相关作品进行了综合总结。
完整性 (1-5):评估摘要是否涵盖基本要素:研究背景、参考文献摘要、过去的研究评估、贡献和创新。
流畅性(1-5):从语法、拼写、标点符号、用词和句子结构等方面评估摘要的质量。
引用准确性(1-5):_在提及参考文献时,评估摘要是否以"[参考文献 i]"的格式正确引用参考文献。
5 Experiment
我们通过验证以下问题来验证我们提出的 ChatCite 代理的能力:
- _ChatCite_生成的文献摘要是否优于使用CoT的LLM和其他基于LLM的文献综述方法直接生成的文献摘要?
- _ChatCite_中的所有模块是否都有助于提高其效率?
- _ChatCite_框架中的模块对生成摘要的质量有什么具体影响?
在本节中,我们针对这些问题进行了一系列实验。首先,我们介绍了实验设置(SS5.1)。我们比较了现有的大语言模型(LLM)在零次和少次访问设置下直接生成相关作品的性能,以及性能最好的基于 LLM 的文献综述方法(SS5.2)。此外,我们还对代理中的每个模块进行了消融分析,以验证它们各自的能力(SS5.3)。最后,我们进行了一项人工研究,对生成的相关工作摘要进行了详细的质量评估(SS5.4)。
5.1.Experimental Setup
数据集: 我们在为相关工作摘要任务设计的论文数据集 NudtRwG-Citation 数据集(Wang 等人,2020 年)上进行了实验验证。该测试集包括 50 篇计算机科学领域的学术研究论文,每篇论文都包含以下内容:
- 要求生成相关工作的目标论文,不包含相关工作部分。
- 一个基本真实的相关工作部分。
- 目标论文的参考文献(注有作者和年份)。
每篇论文都在计算语言学和自然语言处理会议上受到好评,平均引用次数达到 63.59,这表明这些目标论文得到了学术界的广泛认可。
模型:对于 LLMs 基线,我们采用了 16K 上下文窗口的 GPT-3.5 模型和 128K 上下文窗口的 GPT-4.0 模型。我们评估了它们在zero-shot和few-shot设置下的性能。对于以前表现最好的基于 LLM 的文献综述方法,我们使用最近提出的方法 LitLLM作为基准。我们重现了他们根据论文中提到的 CoT 提示生成文献摘要的能力。为了展示其最佳性能,我们使用 GPT-4.0 作为 LitLLM 基线的解码器。对于我们的模型,由于 GPT-4.0 的成本较高,我们在实验中使用了 GPT-3.5(版本 gpt-3.5-turbo-1106)作为解码器。在评估中,我们使用 GPT-4.0 (gpt-4-turbo-preview)作为解码器。
实施: 在零镜头设置下,对于 GPT- 3.5 模型,由于上下文窗口的限制,采用了两步生成法: 1) 摘要后生成,提示 [ps] =“Summarize the current article, preserving as much as possible information. Con- tent:{content}” 进行总结。在生成相关工作部分时,我们使用提示 [pg] =“Generate the related work section based on the given target paper summary and its references sum- mary. Read the Target Paper Content: {Target}. References content: {References}”。对于 GPT-4.0 和带有 GPT-4.0 的 LitLLM,[pg] 可直接用于摘要。
在寥寥数语的设置中,我们添加了这样的说明 “Follow the writing style of the example but without including any content from the example. {Examples}”。
评价指标: 我们利用自动指标和人工评价来评估通用结果。我们采用了传统的自动总结评估指标-词汇重叠度量ROUGE-1/2/L (F1)、我们提出的基于 LLM 的评估指标 G-Eval,以及相同评估标准下的人工评估。
5.2.Main Results
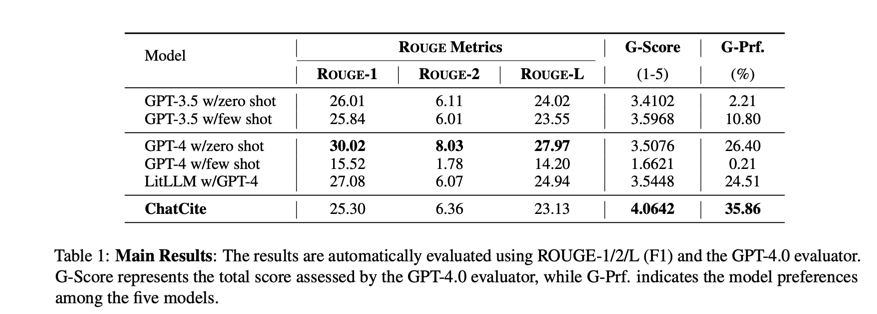
我们比较了不同基线模型在论文测试集上的表现(见表 1)。在传统的总结性评价指标(如 ROUGE)中,GPT-4.0 在零镜头设置下取得了最好的成绩。虽然 ChatCite 的 ROUGE 分数可能略低于 GPT-4.0 的 zero-shot,但它在由 LLM 生成的质量指标和 LLM 偏好方面的表现远远优于直接从其他 LLM 基线获得的结果。
出乎意料的是,GPT-4.0 在少数几个镜头的设置中表现不佳。我们发现,在少数几个镜头中,GPT-4.0 受到实例的影响,导致案例研究后的总结不相关且错误。值得注意的是,使用 GPT-4.0 的 LitLLM 与 GPT-4.0 在零镜头中产生的结果相似,但明显低于 ChatCite。
因此,我们得出结论:“在基于 LLM 的文献总结方法中,ChatCite 的表现最佳,而且遵循人工工作流程指导的方法优于思维链(CoT)方法所获得的结果”。
5.3.Ablation Analysis
我们提出的框架可分解为两个部分:关键要素提取器和反射式增量生成器。反射式增量生成器包括两个关键点:比较增量生成和反射机制。因此,我们将分别分析这三个部分。
Key Element Extractor:
为了验证关键要素提取器的有效性,我们选择了不带关键要素提取器的 ChatCite 作为对比。不带关键要素提取器的 ChatCite 使用基线摘要提示 [ p s ] [p_{s}] [ps] 直接摘要文章,然后使用反思增量生成器生成文献摘要。
在表 2 中,我们比较了不带关键要素提取器的 ChatCite 和 ChatCite 的结果,可以发现 ChatCite 在 ROUGE 指标和基于 LLM 的评价器生成的指标的所有维度上都表现得更好。因此,这表明主题提取模块在文献摘要中发挥了有效的作用。
Comparative Incremental Mechanism:
为了验证比较增量机制的有效性,我们选择了不带比较增量机制的 ChatCite 作为对比,以少量的基线提示 [ p s ] [p_{s}] [ps]和少量的示例作为提示,在标准摘要后直接从文本中生成文献摘要。考虑到增量机制的控制变量,我们还在方法中加入了CoT写作指导,以确保实验结果不受写作指导的影响。
在表 2 中,当比较 ChatCite 有无增量比较机制时,结果表明与没有增量比较机制的 ChatCite 相比,ChatCite 获得了更高的 ROUGE 指标和基于 LLM 的评价指标。这表明比较递增机制大大提高了 ChatCite 框架中文献摘要的有效性。

Reflective Mechanism:
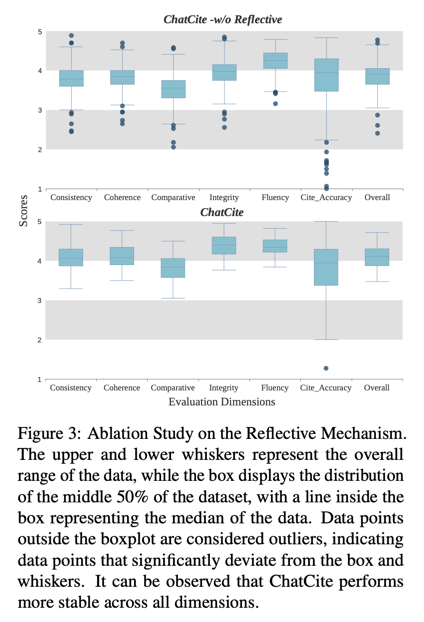
最后,我们分析了反思机制的影响。我们根据 ChatCite 的多个结果评估了各维度的 G 值,其中既包括有反思机制的结果,也包括没有反思机制的结果。图 3 中的方框图结果显示,有反思机制和没有反思机制的 ChatCite 的结果有相似之处。不过,ChatCite 的总体结果略高,异常值分布极少,表明结果的生成更加稳定。这说明反思机制有效提高了 ChatCite 生成文本的质量和稳定性。
总之,通过对三个组件的消减实验,我们证明了_“ChatCite_框架的每个部分都有助于提高文献摘要中生成结果的质量和稳定性”。
5.4.Human Study
为了对 ChatCite 生成的摘要质量进行精细分析,并了解单个模块对摘要的具体影响,我们进行了一项人工研究。我们邀请了计算机科学领域的几位具有学术写作经验的研究人员,使用同一套标准对 10 个选定的样本进行评估,并选出较好的摘要。
图 4 显示,G-score 指标的结果与人类偏好一致。具体来说,包含关键要素提取器的方法表现出更高的内容一致性。比较增量生成机制生成的摘要表现出更好的文献综述特征,在组织结构、比较分析和引用准确性方面表现出色。LLM 生成的结果的流畅度一直很高,不同模型之间的差异相对较小。在人工评价方面,不使用增量比较机制生成的摘要对每篇论文的描述过于分散,缺乏连贯性。意想不到的是,大型模型的评估并没有捕捉到这一特点。
此外,图 5 显示了人类对 ChatCite 模型的偏好。
6 Conclusion
LLM 是生成文献摘要的强大工具,但它也面临着信息遗漏、缺乏比较摘要和组织缺陷等挑战。在 ChatCite 中,关键要素提取器有助于提高内容的一致性,而增量比较生成器则能有效增强生成摘要的组织结构、比较分析和引文准确性。此外,ChatCite 生成的文献综述可直接用于起草文献综述。我们的研究还表明,遵循人类工作流程指导的方法优于思维链(CoT)方法所获得的结果。未来,我们希望我们的工作能进一步激发对复杂推理写作的研究,充分发挥 LLM 在开放式写作任务中的潜力。


















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









