







SYSTEM FOR SYSTEMATIC LITERATURE REVIEW USING MULTIPLE AI AGENTS: CONCEPT AND AN EMPIRICAL EVALUATION
使用多个人工智能代理进行系统性文献审查的系统: 概念与实证评估
paper:
github: https://github.com/GPT-Laboratory/SLR-automation
文章目录~
1.背景动机
现如今SLR的问题:
系统文献综述(SLR)对特定主题的现有文献进行全面、公正的概述。它采用结构化的方法来识别、评估和综合所有相关研究,以解决明确界定的研究问题。然而
-
开展 SLR 本身就是一项耗时耗力的工作。它需要精心策划、广泛搜索和严格筛选大量文献。
-
这项任务的复杂性和规模,尤其是在拥有大量且快速扩展的研究成果的领域,可能会令人生畏并耗费大量资源。
-
挑战不仅在于收集相关文献,还在于准确综合和解释收集到的数据。
提出的解决方案框架:
提出的模型利用了 LLM 的功能,使整个 SLR 流程自动化。目标开发了一个多人工智能代理模型,可自动完成从最初的文献搜索到最终分析的 SLR 的每个步骤:
- 该模型从简单的用户输入开始-研究人员在指定的文本框中输入主题。
- 然后,LLM 对输入进行处理,生成精确的搜索字符串,以检索最相关的学术论文。
- 该模型的下一阶段涉及智能过滤机制。它采用包容性和排他性理论,筛选标题和摘要,只保留与指定研究领域直接相关的研究。
- 最后阶段是对所选论文的摘要进行自主总结,确保只保留与研究问题相关的内容。该模型会对所选论文进行深入分析,并将分析结果与研究问题直接联系起来。
这种全面的方法确保了最终结果不仅反映了现有的大量文献,而且是根据研究人员的特定需求量身定制的重点突出的相关资源。
2.Model
介绍提出的模型的创新,以及模型主要包括的内容:
其创新之处在于,它能够通过一系列自动化、相互关联的步骤,将给定的研究课题转化为全面的审查。每个步骤都由模型中的一个专门代理进行管理,通过协同工作确保文献综述过程的无缝和高效。
1.搜索字符串代理:
我们模型中的第一个代理专门负责生成研究问题和目的以及搜索字符串。该代理采用先进的语言理解算法来解释主题的关键要素。基于 LLM 的算法专为深度语义理解而设计,它分析主题以提取关键概念、主题和术语。然后,它利用对各种文本数据的广泛训练来构建一个精确而全面的搜索字符串。
2.文献搜索代理:
在生成搜索字符串、研究问题和每个问题的目的之后,下一个代理将接手文献检索任务。该代理负责使用搜索字符串查询学术数据库,并检索可能与研究课题相关的初始论文集。它采用复杂的过滤算法来管理海量的可用数据,根据标题选择与搜索字符串的预定义参数最接近的论文。
3.数据抽取代理:
我们模型中的第三个代理负责根据研究目标,使用包含和排除标准来完善文献。首先,它采用我们的 LLM 算法分析检索到的论文标题,辨别它们与研究主题的相关性。这一步涉及文本分析,LLM 算法可识别与研究目标一致的关键术语和概念。
在标题分析之后,代理继续分析所选论文的摘要。LLM 算法会进行更深入的文本分析,评估摘要中的背景、方法和结论,以评估其相关性。最后也是最全面的一步是分析每篇论文的全部内容。这种全面的检查涵盖整篇论文,使代理能够评估每篇论文的内容和结论与特定研究问题的关联性。该代理会提取关键信息,回答筛选出的论文中的每个问题,并以表格形式显示其数据。
4.数据整合代理:
多代理模型中的最后一个代理负责分析与研究问题和目标相关的综合数据。它评估趋势,找出文献中的不足,并根据汇总的信息得出结论。该代理还负责编写报告,总结文献综述的结果,简明扼要地概述特定主题的研究情况。
3.原文阅读
Abstract
系统文献综述(SLR)已成为循证研究的基础,使研究人员能够根据特定的研究问题对现有研究进行识别、分类和合并。进行系统文献综述在很大程度上需要人工操作。过去几年中,研究人员在 SLR 流程的某些阶段实现自动化方面取得了重大进展,旨在减少开展高质量 SLR 所需的精力和时间。然而,目前仍缺乏基于人工智能代理的模型来自动完成整个 SLR 流程。为此,我们引入了一种新颖的多人工智能代理模型,旨在实现 SLR 过程的完全自动化。通过利用大型语言模型(LLM)的功能,我们提出的模型简化了审查流程,提高了效率和准确性。
框架的具体流程:
该模型通过一个用户友好型界面进行操作,研究人员在该界面上输入他们的主题,作为回应,该模型将生成一个搜索字符串,用于检索相关的学术论文。随后,会应用一个包容和排他性过滤过程,重点关注与特定研究领域相关的标题。
然后,模型会自主汇总这些论文的摘要,只保留与研究领域直接相关的论文。
在最后阶段,模型会根据预先确定的研究问题对所选论文进行全面分析。
本文详细介绍了该模型的开发过程及其操作框架,并展示了该模型如何在确保高度全面性和精确性的同时,大幅减少传统 SLR 所需的时间和精力。我们还对所提出的模型进行了评估,与十位有能力的软件工程研究人员分享了该模型,并对其进行了测试和分析。研究人员对提出的模型表示非常满意,并提供了进一步改进的反馈意见。今后,我们计划让 50 名从业人员和研究人员参与评估我们的模型。此外,我们还计划在芬兰罗瓦尼尼举行的 SANER 2024 会议上向听众展示我们的模型,以便进行进一步的测试、分析和反馈收集。该项目的代码可在 GitHub 存储库中找到:https://github.com/GPT-Laboratory/SLR-automation。
1 Introduction
介绍系统文献综述SLR的背景与问题:
系统文献综述(SLR)是学术研究的基本组成部分,它对特定主题的现有文献进行全面、公正的概述,Keele 等人。它采用结构化的方法来识别、评估和综合所有相关研究,以解决明确界定的研究问题 。这一过程对于建立新研究的背景和基础、确定当前知识的差距以及为未来研究方向提供信息至关重要。然而,开展 SLR 本身就是一项耗时耗力的工作。它需要精心策划、广泛搜索和严格筛选大量文献。这项任务的复杂性和规模,尤其是在拥有大量且快速扩展的研究成果的领域,可能会令人生畏并耗费大量资源。挑战不仅在于收集相关文献,还在于准确综合和解释收集到的数据。
介绍如今的大模型对于SLR的优势:
人工智能(AI)中出现的大型语言模型(LLMs)为自动化和简化 SLR 流程提供了新的机遇。经过大量文本数据集训练的 LLM 擅长理解和生成类似人类的语言。它们可以快速处理和分析大量文本,提供人类需要更长时间才能编译的见解和摘要。它们能够理解上下文和语言中的细微差别,因此特别适用于识别相关文献、提取关键信息和总结研究成果等任务。通过将 SLR 流程中较为繁琐和重复的环节自动化,LLM 可以大大减少所需的时间和精力,使研究人员能够专注于其研究中更为细微的环节。
介绍本文提出的框架:
在这种情况下,我们提出的模型利用了 LLM 的功能,使整个 SLR 流程自动化。我们开发了一个多人工智能代理模型,可自动完成从最初的文献搜索到最终分析的 SLR 的每个步骤。该模型从简单的用户输入开始–研究人员在指定的文本框中输入主题。然后,LLM 对输入进行处理,生成精确的搜索字符串,以检索最相关的学术论文。该模型的下一阶段涉及智能过滤机制。它采用包容性和排他性理论,筛选标题和摘要,只保留与指定研究领域直接相关的研究。
**我们模型的最后阶段是对所选论文的摘要进行自主总结,确保只保留与研究问题相关的内容。**它在数据分析中引入了人工难以达到的精确度和一致性。最后,该模型会对所选论文进行深入分析,并将分析结果与研究问题直接联系起来。这种全面的方法确保了最终结果不仅反映了现有的大量文献,而且是根据研究人员的特定需求量身定制的重点突出的相关资源。因此,我们的模型证明了将先进的人工智能技术整合到学术研究方法中的潜力。
我们还与十位精通软件工程的研究人员分享了我们提出的模型,对其效率和准确性进行了全面的测试和分析。收到的反馈非常积极,凸显了模型的有效性,并为进一步改进铺平了道路。展望未来,我们的目标是扩大评估范围,让另外 50 名从业人员和研究人员参与进来。此外,我们还打算在即将于芬兰罗瓦涅米举行的 SANER 2024 会议上展示我们的模型,以扩大其测试和分析范围,同时从更广泛的受众那里收集宝贵的反馈意见。这一步骤对于完善我们的模型并确保其在不同现实世界场景中的适用性和稳健性至关重要。
我们的贡献可概括如下:
- 我们提出了一种新颖的多人工智能代理模型,利用 LLM 自动执行 SLR 流程,显著提高了效率和准确性。
- 十位经验丰富的软件工程研究人员和从业人员对我们的模型进行了评估,确认了其有效性,并为进一步完善收集了见解。
- 我们计划将评估范围扩大到另外 30 名从业人员和研究人员,并在芬兰罗瓦涅米举行的 SANER 2024 会议上展示该模型,以获得更广泛的测试和反馈。
2 Related Work
Bartholomew(2002 年)进行了首次可持续土地利用研究,开展了系统的临床试验,以确定坏血病的有效治疗方法。Bartholomew (2002 年)在他的试验中严格评估了各种可能的疗法,特别强调了橘子和柠檬作为最成功疗法的有效性。在社会经济研究领域,Kitchenham(2004 年)引入了 SLR 方法。这一框架有助于将已在医疗保健和社会科学等领域盛行的系统性审查原则调整为适应社会经济研究的特定挑战和需求。在这一发展之后,SLR 已成为支持 SE 循证材料的广泛应用实践。SLR 在促进循证研究方面的成功促使其他研究人员在其工作中采用这种方法,Kitchenham 等人(2009 年)。然而,开展 SLR 通常是一项具有挑战性的工作,包括收集、评估和记录证据等各种活动。SLR 中的这些任务通常都是人工完成的,没有自动化或决策支持工具的辅助,使得整个过程不仅耗时耗力,而且容易出错 van Dinter 等人(2021 年)。许多研究人员在实现 SLR 过程自动化方面取得了进展 van Dinter 等人(2021 年)。
目前的研究工作主要集中在改进 SLR 流程,在确保高召回率的同时优化精度,解决现有方法中经常出现的精度缺陷 O’Mara-Eves 等人(2015)。此外,人们还在大力推动减少人为错误,尤其是因为审查过程中的许多步骤都是高度重复的 Marshall 等人(2016)。在这方面,K.R. Felizardo 和 J.C. Maldonado 的研究成果值得关注。他们探索了从传统、重复和易出错的 SLR 方法向可视化文本挖掘应用的转变。正如他们的文章 Felizardo 等人(2012 年)、Felizardo 等人(2014 年)、Felizardo 等人(2011 年)和 Malheiros 等人(2007 年)所概述的那样,这种方法利用无监督学习来帮助用户识别相关文章,不过它确实要求用户具备机器学习和统计学背景。
Olorisade 等人(2016 年)提出了一种创新的 ML 模型,旨在实现 SLR 中主要研究选择过程的自动化,从而有可能简化这一关键步骤,并大大减少筛选大量学术文献所需的人工工作。Shakeel 等人(2018 年)就 SLR 流程自动化时可能出现的潜在威胁提出了宝贵的见解。Feng等人(2017)强调了目前在SLR中采用的各种文本挖掘技术,我们的工具正是建立在这一基础之上。值得注意的是,Payrter 等人(2016 年)提交了一份综合报告,描述了文本挖掘(TM)技术在 SLR 流程自动化各个阶段的应用,包括选择、提取和更新。这与我们工具的目标非常吻合。Clark 等人(2020 年)证明了使用多种工具在明显缩短的时间内完成 SLR 的可行性,这为我们的工具旨在实现的效率开创了先河。
Michelson 和 Reuter(2019 年)提供了 SLR 的经济分析和时间估算,强调了自动化解决方案的必要性,而我们的工具正是直接响应了这一呼吁。同样,Beller 等人(2018 年)不仅列出了有助于实现 SLR 自动化的工具,还制定了八项准则,为我们工具的开发提供了参考。
Jonnalagadda等人(2015)详细介绍了从已发表报告中提取数据的方法,这对我们工具数据处理能力的形成起到了重要作用。此外,Marshall 和 Wallace(2019 年)以及 O’Connor 等人(2019 年)分别列出了系统性综述的有用工具,并阐明了采用此类工具的障碍,从而全面了解了该领域的现状和用户的犹豫不决。其他贡献还包括 O’Mara-Eves 等人(2015 年)和 O’Mara-Eves 等人(2015 年),他们分别对文本挖掘在 SLR 自动化中的作用进行了 SLR,并描述了 SLR 流程中不同步骤的自动化潜力。这些工作对于确定我们的工具在哪些领域能发挥最大作用至关重要。此外,Jaspers 等人(2018 年)和 Thomas 等人(2011 年)探讨了机器学习技术和 TM 技术在 SLR 流程自动化中的应用,这些都对我们的工具设计产生了关键影响。最后,Van Altena 等人(2019 年)的调查强调,研究人员对 SLR 工具的使用有限,因此需要更多像我们的工具这样的用户友好型高效解决方案。
尽管在 SLR 流程自动化方面取得了这些进展,但在使用 LLMs 实现 SLR 完全自动化方面仍存在明显差距。针对这一差距,我们开发了一种新方法:基于 LLM 的多代理模型。这一创新模型旨在利用 LLM 的先进功能实现 SLR 过程的完全自动化,从而有效地管理和综合大量数据,这是在自动化文献综述领域迈出的重要一步。
3 Research Method
本研究旨在探讨如何利用基于 LLM 的多代理模型实现 SLR 整个流程的自动化。我们还概述了测试和分析模型能力的方法。下面,我们将讨论基于 LLM 的多代理模型如何协作并执行此类任务。我们提出了以下研究问题(RQs):
问题 1:基于 LLM 的多代理系统如何转变传统方法,使 SE 中的系统文献综述过程自动化?
动机:之所以提出这个研究问题,是因为在快速发展的社会经济领域,需要提高文献综述过程的效率和效果。传统的文献综述方法往往耗时耗力,有可能导致研究进展和新知识传播的延误。LLM 的整合带来了范式的转变,有可能实现这些流程的自动化和简化。通过探索基于 LLM 的多代理系统带来的转变,本研究旨在减少全面文献综述所需的时间和精力,并提高这些综述的准确性和范围。在 SE 领域,紧跟当前趋势、方法和发现对于技术进步和创新至关重要。
问题 2. 如何评估提出的基于 LLM 的多代理模型的效率和准确性?
动机:这一研究问题背后的动机是基于验证和量化提出的模型性能的迫切需要,特别是在进行 SLR 时。随着基于 LLM 的多代理系统等复杂模型的引入,建立严格的评估标准以评估其在现实世界中的适用性和可靠性变得势在必行。本问题探讨了提出的模型在选择和解释相关文献时系统衡量其效率和准确性的必要性。评估所提出的模型对于确保将此类模型纳入学术工作流程能够提高而不是降低研究成果的质量至关重要。
3.1.LLM-Based Assisted Systematic Literature Review
介绍提出的模型的创新,以及模型主要包括的内容:
本节重点介绍开发基于 LLM 的多代理模型的研究方法。该模型专为实现 SLR 整个流程的自动化而设计。其创新之处在于,它能够通过一系列自动化、相互关联的步骤,将给定的研究课题转化为全面的审查。每个步骤都由模型中的一个专门代理进行管理,通过协同工作确保文献综述过程的无缝和高效。在图 1 中,我们展示了代理如何相互协作生成回复。下面,我们还将详细介绍这个多代理系统中每个代理的功能。
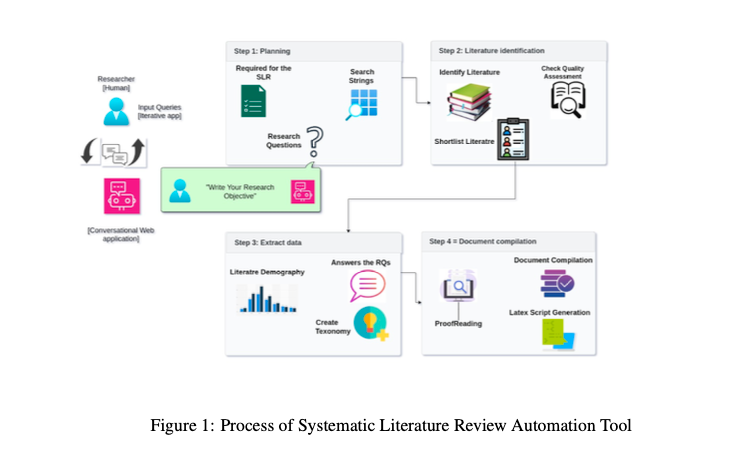
3.1.1 Planner agent
搜索字符串代理:
我们模型中的第一个代理专门负责生成研究问题和目的以及搜索字符串。该代理采用先进的语言理解算法来解释主题的关键要素。基于 LLM 的算法专为深度语义理解而设计,它分析主题以提取关键概念、主题和术语。然后,它利用对各种文本数据的广泛训练来构建一个精确而全面的搜索字符串。该字符串由相关关键词、同义词和技术术语组合而成,能抓住研究问题的本质。此外,该算法还善于理解上下文和不同的语义结构,使其能够完善搜索字符串,以匹配特定的研究领域。生成的搜索字符串对于从各种学术数据库中准确检索相关文献至关重要。通过确保初始搜索既全面又有针对性,代理可显著提高文献收集过程的效率和质量。这为 SLR 的后续阶段奠定了坚实的基础,在这些阶段中,所收集文献的深度和广度起着至关重要的作用。
3.1.2 Literature identification agent
文献搜索代理:
在生成搜索字符串、研究问题和每个问题的目的之后,下一个代理将接手文献检索任务。该代理负责使用搜索字符串查询学术数据库,并检索可能与研究课题相关的初始论文集。它采用复杂的过滤算法来管理海量的可用数据,根据标题选择与搜索字符串的预定义参数最接近的论文。这一步骤对于将文献库缩小到可管理的规模以便进行深入审查至关重要。
3.1.3 Data extraction agent
数据抽取代理:
我们模型中的第三个代理负责根据研究目标,使用包含和排除标准来完善文献。首先,它采用我们的 LLM 算法分析检索到的论文标题,辨别它们与研究主题的相关性。这一步涉及文本分析,LLM 算法可识别与研究目标一致的关键术语和概念。通过应用这些预定义的规则,代理可以有效地过滤掉不相关的材料,确保文献综述重点突出并与研究问题相关。
在标题分析之后,代理继续分析所选论文的摘要。LLM 算法会进行更深入的文本分析,评估摘要中的背景、方法和结论,以评估其相关性。最后也是最全面的一步是分析每篇论文的全部内容。这种全面的检查涵盖整篇论文,使代理能够评估每篇论文的内容和结论与特定研究问题的关联性。该代理会提取关键信息,回答筛选出的论文中的每个问题,并以表格形式显示其数据。这种综合对于了解所选文献中研究结果的更广泛背景和意义至关重要。
3.1.4 Data compilation agent
数据整合代理:
多代理模型中的最后一个代理负责分析与研究问题和目标相关的综合数据。它评估趋势,找出文献中的不足,并根据汇总的信息得出结论。该代理还负责编写报告,总结文献综述的结果,简明扼要地概述特定主题的研究情况。
基于 LLM 的多代理模型中的每个代理都在系统文献综述过程自动化中发挥着重要作用。从生成搜索字符串到报告结果,各代理以协调的方式开展工作,以确保进行全面、高效和准确的审查。这种方法代表了系统性文献综述方式的重大进步,为学术研究提供了一种更精简、更有效的方法。
3.2.Performance Validation
在这个项目中,我们聘请了 10 位研究人员来评估我们提出的模型的效率和性能。这些专业人士来自不同的行业和研究团体,以确保他们的观点具有多样性。我们的评估方法立足于以实践为导向的框架,侧重于由经验丰富的业内专业人士对模型的实用性和有效性进行严格审查。这种方法保证了评估的详细性和洞察力,并将相应领域专家的实际应用和需求考虑在内。
3.2.1 Professional-based evaluation
在研究的验证阶段,我们与来自学术界和产业界等不同领域的十位专家合作,对我们基于 LLM 的模型的有效性进行评估。这一选择是战略性的,目的是在不同的专业背景下捕捉有关模型性能的广泛视角和见解。为便于进行全面评估,每位专家都可以使用该模型,并附有关于其预期用途和功能的全面说明。这种方法确保他们有足够的能力在各自的领域内对模型进行深入评估。
参与者的选择: 起初,我们从不同的研究小组中寻找合适的研究人员,并通过社交网络扩大了与个人的联系。我们通过研究人员的 ResearchGate 和 Google Scholar 资料联系他们。在这些平台上,我们招募了五名参与者,其余五名则是通过社交网站和专业联系人确定的。因此,我们召集了十名参与者(表 1 中称为 P1 至 P10),对我们提出的模型进行评估。表 1 显示,这些参与者来自不同领域,如软件工程和机器学习/深度学习开发。
数据收集: 该方法采用了一种系统的方法来收集反馈数据。参与者的任务是将模型整合到他们的研究中,并提供一个与其专业知识相关的主题。然后,他们将我们的模型生成的结果与人工获得的结果进行比较。为了收集他们的反馈,我们实施了一个全面的反馈机制,使他们能够系统地记录他们的经验、观察和批评。该机制旨在获得有关模型效率、用户友好性和数据分析准确性的详细反馈。反馈的格式经过精心设计,以提取深入的定性见解,从而促进对模型性能可量化要素的评估。
数据分析: 在我们验证过程的最后阶段,分析参与者的反馈对于不断改进模型至关重要。参与者可以选择任何数据源进行输入。我们收集并仔细研究了他们的反馈意见,以了解模型在各种情况下的表现。为了评估模型的性能,我们使用了一个广泛的李克特量表,范围从 "不满意 "到 “优秀”,中间选项包括 “一般”、“满意”、"好 "和 “非常好”。该量表提供了一个细致入微的评估范围,可对模型的有效性进行精确而全面的分级。我们的迭代方法以增强模型的功能、用户体验和整体功效为重点,旨在满足定性数据分析专业人员的不同需求和期望。
4 Results
本节介绍了实施基于人工智能代理的模型所取得的成果,该模型旨在将 SE 中的 SLR 流程自动化。研究结果根据两个主要研究问题(RQs)进行了详细说明,这两个问题为模型的创建和评估提供了指导。



4.1.LLM Based Multi-Agent Model (RQ1)
我们的研究引入了基于 LLM 的多代理模型,重新定义了 SE 中 SLR 的传统方法。为实现 SLR 流程自动化而开发的多代理模型通过结构化和顺序化的工作流程证明了其有效性。如图 2 所示,该流程从输入研究课题开始。
收到研究课题后,模型会系统地生成一组相关的研究问题。如图 2 所示,它提出的问题包括:"大型语言模型是如何在软件开发过程的各个方面得到利用的?"以及 "在软件开发中采用和实施大型语言模型存在哪些挑战和限制?这些问题在指导文献搜索和分析过程中起着至关重要的作用。在提出研究问题之后,模型会生成一个搜索字符串。在本例中,我们创建了 "大型语言模型或软件开发 "这一搜索字符串,并指定了年份,以缩小搜索范围,从而提高搜索结果的相关性和精确性。
随后的阶段是检索与生成的搜索字符串相匹配的论文。如图 3 中的论文列表所示,该模型的这一功能专门用于从各种数据库中检索研究论文。在本次演示中,我们只关注 2023 年发表的论文,将模型设置为只检索该年的 10 篇论文,这些论文都与该领域相关。该工具能有效汇编相关信息,如标题、作者、发表 URL、期刊名称、DOI、论文类型、所属国家和所属机构。此外,该模型还具备根据标题应用包容性和排他性标准的功能,从而进一步完善搜索结果,确保只有最相关的文献才会被考虑进行审阅。如图 4 所示,只有三篇论文被选中进行深入分析。
最后,该模型根据制定的 RQs 提取数据。这一高级功能在演示中得到了体现,演示中为之前生成的 RQs 提供了详细的答案。例如,第一个 RQ 的答案讨论了大型语言模型在软件开发生命周期中的各种应用,并强调了其使用的具体实例,如论文 "InferLink End-to-End Program Repair with Large Language Models "中的推论。
总之,自动 SLR 工具展示了其简化费力的文献综述过程的能力,从确定研究范围到提取和综合与研究问题相关的数据。该演示肯定了该模型在大幅减少进行系统文献综述所需的时间和精力方面的潜力。
4.2.Evaluation Result (RQ2)
对我们的工具进行实证评估时,有十位来自社会企业界不同背景的研究人员和从业人员参与。他们的参与为模型的实用性和用户体验提供了全面的视角。他们的反馈非常积极,80% 的参与者认可该工具的功能,并肯定了它对简化 SLR 流程的贡献。
尽管大家对该模型的功效达成了普遍共识,但仍有 20% 的与会者提出了改进建议。具体建议强调需要对复杂的研究查询进行更细致的解释,并生成更精细的搜索字符串。这些建设性的反馈意见非常宝贵,因为它引导我们将重点放在增强模型的解释算法和处理模糊或多方面研究问题的能力上。
为了不断改进该模型,计划对其进行进一步的展示和评估。在芬兰罗瓦涅米举行的 SANER 2024 会议为 SE 研究界提供了一个广泛征求反馈意见的机会,这将有助于模型的迭代发展。此外,还计划开展一项大规模的测试活动,将模型分发给 50 名研究人员和从业人员进行广泛评估。
在即将开始的这一阶段,预计将对模型在社会经济各个领域的可推广性和性能产生更深入的了解。它还将有助于确定模型需要适应的可持续土地退化过程中的任何细微差别。全面的反馈意见将是完善模型不可或缺的一部分,以确保最终版本不仅有效、高效,而且用途广泛、便于使用。最终目标是提供一个强大的、普遍适用的工具,使 SLR 标准化和自动化,促进 SE 研究方法的进步。
5 Discussions
我们的多人工智能代理 SLR 模型的实施结果既令人鼓舞又富有洞察力。该模型成功地实现了 SLR 流程关键部分的自动化,包括搜索字符串的生成、相关文献的选择和过滤以及关键发现的总结。这种自动化大大减少了进行 SLR 通常所需的时间和精力,同时保持并在某些方面提高了审查的准确性和全面性。该模型能够快速处理和分析大量文本,并能准确识别相关研究,这证明了将 LLM 整合到学术研究中的巨大潜力。
这些结果影响深远。首先,该模型为各个领域的研究人员提供了一个宝贵的工具,减少了进行全面文献综述的障碍。这种效率可以加快研究和发现的步伐,使学者们能够专注于更复杂、更具创造性的工作。此外,该模型对 SLR 流程的标准化有可能带来更加一致和可复制的研究成果,而这正是科学研究的基石。减少人工操作也为以下方面提供了机会资源有限的研究人员或面临时间压力等限制的研究人员,扩大了能够进行全面文献综述的人员范围。
展望未来,我们的模型将产生重大影响。一个重要的里程碑将是我们参加 3 月 12 日的 Sanner 大会,届时我们将向不同的受众展示我们开发的工具。这次活动不仅是展示我们模型能力的平台,也是收集广大用户反馈意见的重要机会。这些反馈意见对于进一步完善和改进模型非常宝贵。了解模型在实际场景中的表现并收集不同的观点,将使我们能够使模型更加符合研究界的需求。之后,我们计划根据这些反馈意见实施更新和改进,确保我们的工具始终处于可持续土地退化自动化创新的前沿。根据用户意见对我们的模型进行持续开发和调整,将确保其在不断发展的学术研究领域中的相关性和实用性。
此外,我们的工作预计将对研究人员和更广泛的学术界产生巨大的长期影响。我们的模式代表了 SLR 开展方式的范式转变,提供了一种不仅高效而且能适应研究人员不断变化的需求的工具。未来的一个重要影响就是研究的民主化。通过简化 SLR 流程,我们的工具让更多研究人员,包括那些来自资源较少机构的研究人员或该领域的新手,都能获得高质量的文献综述。这种便利性可以使学术研究中的声音和观点更加多样化,从而丰富整个领域。
此外,该模型在处理大量数据方面的高效性使其成为生物医学研究、环境研究和技术等文献数量庞大且增长迅速的领域的宝贵资产。这些领域的研究人员可以更有效地掌握最新的发展动态,确保他们的工作以最新、最全面的数据为依据。
在跨学科研究领域,我们的模型可以促进不同领域信息的综合,从而可能带来新的见解和创新。通过有效整理和分析不同的文献集,该工具可以帮助发现学科之间的联系,否则这些联系可能会被忽视。
根据用户反馈和技术进步对我们的模型进行长期调整,也将确保其持续的相关性。持续更新将使模型能够融入最新的人工智能进步,进一步增强其能力,确保其继续成为可持续土地利用研究的前沿工具。此外,该模型的定制潜力将使其能够满足不同研究领域的特定需求。这种定制方法意味着
6 Limitation
本研究为 SE 领域提供了宝贵的见解。但是,也存在一些局限性,需要在今后的研究中加以注意。首先,最初为确定相关文献而采用的搜索策略不够理想。由于没有全面使用布尔运算符,特别是搜索字符串中缺少 “AND”,可能会影响文献搜索的具体性和彻底性,从而导致现有证据的不完整。这一问题突出表明,有必要制定更加严格的搜索策略,以提高检索文献的准确性和相关性。
此外,该方法在文献筛选方面也存在重大缺陷,其特点是缺乏明确界定的主要和次要排除标准。这一疏忽很可能导致筛选过程不够严格,削弱了该研究系统性地排除不相关或低质量研究的能力。在论文的后续版本中,实施明确的纳入和排除标准对于提高文献综述的可靠性和有效性至关重要。
观察到的另一个重要限制是在数据提取阶段。虽然数据是根据预先确定的研究问题提取的,但由于缺乏可靠的分析算法,提取信息的可靠性值得怀疑。目前的方法不能充分确保提取数据的准确性和相关性,而这是得出可靠结论的基石。整合能够进行更高级数据分析的先进分析算法,将使本研究在未来的迭代中受益匪浅。这种算法不仅能更高效地提取数据,还能根据研究目标评估信息的质量和适用性。
解决这些局限性对于推动研究对该领域的贡献至关重要。加强搜索策略、文献筛选和数据分析不仅能完善研究方法,还能提高研究的整体可信度和影响力。今后的工作将重点解决这些问题,以建立一个更可靠、更全面的研究框架。
7 Future Work
解决已发现的局限性为我们在未来的迭代中提高研究的全面性提供了一条途径。本文即将推出的版本将致力于实施几项关键改进。
改进搜索策略: 为了克服搜索字符串不足所带来的局限性,未来的工作将包括开发一种更复杂的搜索策略。这将包括布尔运算符的全面使用,特别是 "AND "的加入,以确保文献检索的具体性和彻底性。将采用系统的方法来定义搜索字符串,以提高检索文件的准确性和相关性。
实施明确的排除和纳入标准: 认识到缺乏明确界定的一级和二级文献排除标准是一个重大缺陷,今后的工作重点将是制定明确的纳入和排除标准。这一改进将促进更加严格和系统的筛选过程,从而提高研究系统性地排除不相关或低质量研究的能力,确保文献综述更加可靠和有效。
改进数据提取方法: 初步阶段的工作凸显了建立更可靠的数据提取机制的必要性。为此,今后的工作将采用先进的分析算法,以确保提取数据的准确性和相关性。这些算法不仅能提高数据提取的效率,还能提供一种方法来严格评估与研究目标相关的信息的质量和适用性。将探索机器学习和自然语言处理技术的整合,以实现数据提取和分析过程的自动化并提高其效率。
加强分析框架: 认识到初步数据分析的局限性,今后的研究将致力于开发和实施一个更强大的分析框 架。该框架将用于全面分析提取的数据,并酌情纳入定性和定量方法。重点是通过严格的统计测试和敏感性分析,确保研究结果的可靠性和有效性。
扩大文献范围: 为了消除因最初的搜索限制而导致的文献综述中可能出现的偏差或空白,今后的研究将扩大范围,纳入更广泛的数据库和灰色文献。这一扩展将确保更全面地覆盖主题事项,包括不同的观点和新出现的研究趋势。
利益相关者的参与: 认识到利益相关者的见解在完善研究方法方面的价值,未来的迭代将涉及与领域专家、研究人员和从业人员的接触。这种参与将为研究设计、方法和结果提供重要的反馈意见,有助于取得更细致、更有影响力的研究成果。
通过系统地解决这些局限性,未来的工作将大大提高本研究对该领域的贡献,为理解研究课题提供一个更强大、更全面、更可靠的基础。这些改进不仅能解决当前研究的不足之处,还将为类似研究工作的方法论严谨性开创先例。
8 Conclusions
我们的多人工智能代理模型的开发和实施代表了 SLR 领域的重大进展。通过整合 LLM 的能力,这项研究展示了一种自动化和优化 SLR 流程的新方法。我们的模型解决了传统 SLR 方法所面临的主要挑战:过程耗时以及在文献选择和分析中可能出现的人为错误或偏差。通过自动完成初始搜索、筛选、汇总和分析阶段,该模型大大减少了所需的人工工作量和时间,同时还提高了结果的准确性和一致性。
使用简单的用户界面进行主题输入和随后生成定制的搜索字符串,说明该模型采用了用户友好型方法,使更多研究人员可以使用复杂的 SLR 流程。包容性和排他性过滤机制确保了文献综述的重点和相关性,直接与指定的研究问题保持一致。对摘要的自主总结和最后的分析阶段突出了该模型将海量数据提取为清晰、相关信息的能力,如果没有先进的人工智能辅助,这项任务将具有挑战性。
这项研究为人工智能在学术研究中的应用这一日益增长的领域做出了贡献,展示了如何有效利用 LLM 来增强研究方法。虽然该模型大大提高了效率和准确性,但必须承认人类在指导和解释结果方面的监督作用,以确保最终产出保持学术研究所需的深度。


















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









