







网络子系统
1 ISO/OSI和TCP/IP参考模型
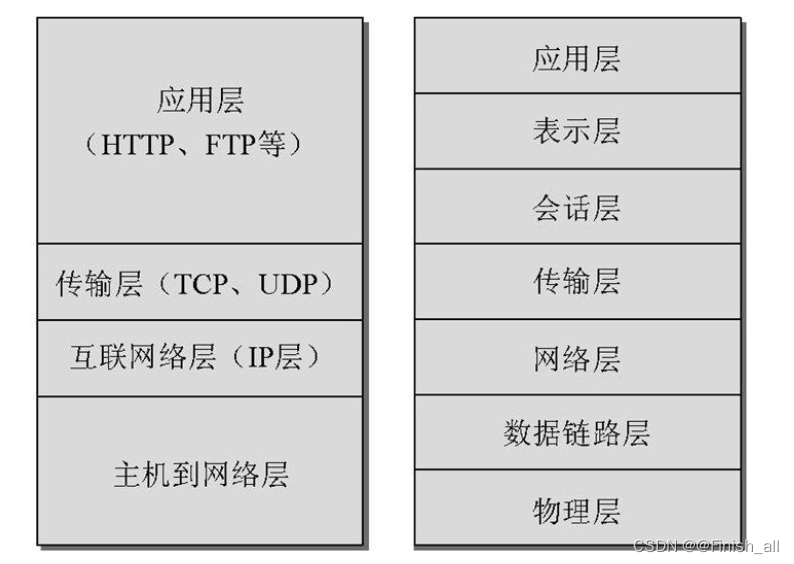
国际标准化组织)设计了一种参考模型,定义了组成网络的各个层。该模型由7层组成,称为OSI(Open Systems Interconnection,开放系统互连)模型,如图所示。其中将ISO/OSI模型的一些层合并为新层。该模型只有4层,因此其结构更为简单。这种模型称为TCP/IP**参考模型**,IP表示Internet Protocol(网际协议),而TCP表示Transmission Control Protocol(传输控制协议)。
2 通过套接字通信
外部设备在Linux(和UNIX)中不过是普通的文件,通过正常的读写操作即可访问,对网卡而言,情况有点复杂,网卡的运作方式与普通的块设备和字符设备完全不同,使得经典的UNIX箴言“万物皆文件”不再完全适用。当然,内核必须提供一个尽可能通用的接口,供程序访问网络功能,套接字现在用于定义和建立网络连接,以便可以用操作inode的普通方法(特别是读写操作)来访问网络。从程序员的角度来看,创建套接字的最终结果是一个文件描述符,它不仅提供所有的标准函数,还包括几个增强的函数。用于实际数据交换的接口对所有的协议和地址族都是同样的。
2.1 创建套接字
在创建套接字时,必须指定所需要的地址和协议类型的组合。不仅要区分地址和协议族,还要区分基于流的通信和数据报的通信。
套接字是使用socket 库函数生成的,除了地址族和通信类型(流或数据报)之外,可使用第三个参数来选择协议。因为前两个参数已经唯一地定义了协议。将第三个参数指定为0,即通知函数使用适当的默认协议。在调用socket函数后,套接字地址的格式(或它属于哪个地址族)已经很清楚,但尚未给套接字分配本地地址。
bind 函数用于该目的,必须向该函数传递一个sockaddr_type 结构作为参数。该结构定义了本地地址。因为不同地址族的地址类型也不同,所以该结构对每个地址族都有一个不同的版本,以便满足各种不同的要求。type 指定了所需的地址类型。
struct sockaddr_in {
sa_family_t sin_family; /* 地址族 */
__be16 sin_port; /* 端口号 */
struct in_addr sin_addr; /* 因特网地址 */
...
}3 网络实现的分层模型
相关的C语言代码划分为不同层次,各层次都有明确定义的任务,各个层次只能通过明确定义的接口与上下紧邻的层次通信。这种做法的好处在于,可以组合使用各种设备、传输机制和协议。例如,通常的以太网卡不仅可用于建立因特网(IP)连接,还可以在其上传输其他类型的协议,如Appletalk或IPX,而无须对网卡的设备驱动程序做任何类型的修改。
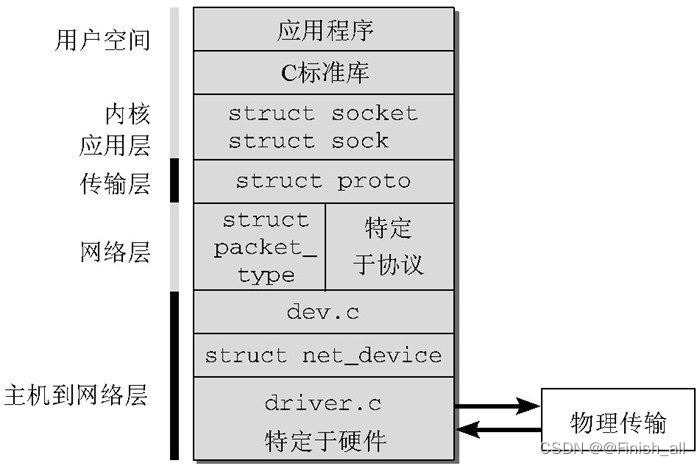
上图说明了内核对这个分层模型的实现。
分层模型不仅反映在网络子系统的设计上,而且也反映在数据传输的方式上(或更精确地说,对各层产生和传输的数据进行封装的方式)。通常,各层的数据都由首部和数据两部分组成(如下图所示)。

各协议层的数据划分为首部和数据两部分,首部部分包含了与数据部分有关的元数据(目标地址、长度、传输协议类型等),数据部分包含有用数据(或净荷)。传输的基本单位是(以太网)帧,网卡以帧为单位发送数据。帧首部部分的主数据项是目标系统的硬件地址,这是数据传输的目的地,通过电缆传输数据时也需要该数据项。
高层协议的数据在封装到以太网帧时,将协议产生的首部和数据二元组封装到帧的数据部分。在因特网网络上,这是互联网络层数据。

上图是在以太网帧中通过TCP/IP传输HTTP数据,清楚地说明了为容纳控制信息所牺牲的部分带宽。
4 网络命名空间
内核的许多部分包含在命名空间中。这可以建立系统的多个虚拟视图,并彼此分隔开来。每个实例看起来像是一台运行Linux的独立机器,但在一台物理机器上,可以同时运行许多这样的实例。在内核版本2.6.24开发期间,内核也开始对网络子系统采用命名空间。这对该子系统增加了一些额外的复杂性,因为该子系统的所有属性在此前的版本中都是“全局”的,而现在需要按命名空间来管理,例如,可用网卡的数量。对特定的网络设备来说,如果它在一个命名空间中可见,在另一个命名空间中就不一定是可见的。
照例需要一个中枢结构来跟踪所有可用的命名空间。其定义如下:
//include/net/net_namespace.h
struct net {
atomic_t count; /* 用于判断何时释放网络命名空间 */
...
struct list_head list; /* 网络命名空间的链表 */
...
struct proc_dir_entry *proc_net;
struct proc_dir_entry *proc_net_stat;
struct proc_dir_entry *proc_net_root;
struct net_device *loopback_dev; /* 环回接口设备 */
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
};count 是一个标准的使用计数器,在使用特定的net 实例前后,需要分别调用辅助函数get_net 和put_net 。在count 降低到0时,将释放该命名空间,并将其从系统中删除。所有可用的命名空间都保存在一个双链表上,表头是net_namespace_list 。list 用作链表元素。copy_net_ns函数向该链表添加一个新的命名空间。在用create_new_namespace 创建一组新的命名空间时,会自动调用该函数。每个命名空间都可以有一个不同的环回设备,而loopback_dev指向履行该职责的(虚拟)网络设备。网络设备由struct net_device 表示。与特定命名空间关联的所有设备都保存在一个双链表上,表头为dev_base_head 。各个设备还通过另外两个双链表维护:一个将设备名用作散列键(dev_name_head ),另一个将接口索引用作散列键(dev_index_head )。
5 套接字缓冲区
在内核分析(收到的)网络分组时,底层协议的数据将传递到更高的层。发送数据时顺序相反,各种协议产生的数据(首部和净荷)依次向更低的层传递,直至最终发送。这些操作的速度对网络子系统的性能有决定性的影响,因此内核使用了一种特殊的结构,称为套接字缓冲区 (socket buffer),定义如下:
struct sk_buff {
/* 这两个成员必须在最前面*/
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
ktime_t tstamp;
struct net_device *dev;
struct dst_entry *dst;
char cb[48];
unsigned int len,
data_len;
__u16 mac_len,
hdr_len;
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
__u8 pkt_type:3,
fclone:2,
ipvs_property:1;
nf_trace:1;__be16 protocol;
...
void (*destructor)(struct sk_buff *skb);
...
int iif;
...
sk_buff_data_t transport_header;
sk_buff_data_t network_header;
sk_buff_data_t mac_header;
/* 这些成员必须在末尾,详见alloc_skb()*/
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
atomic_t users;
};
套接字缓冲区用于在网络实现的各个层次之间交换数据,而无须来回复制分组数据,对性能的提高很可观。因为在产生和分析分组时,在各个协议层次上都需要处理该结构。
5.1 使用套接字缓冲区管理数据
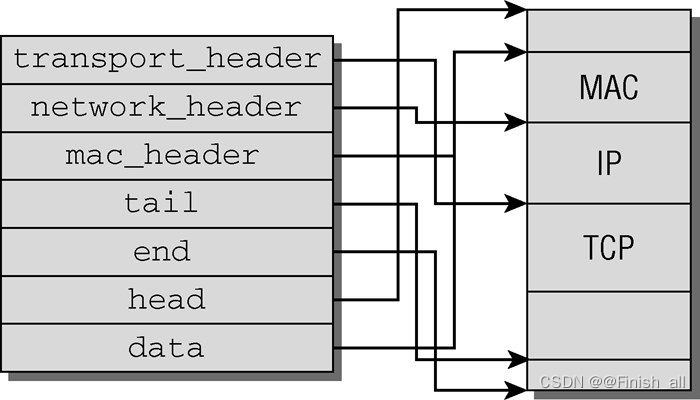
如图所示, 套接字缓冲区通过其中包含的各种指针与一个内存区域相关联,网络分组的数据就位于该区域中。这使得内核可以将套接字缓冲区用于所有协议类型。套接字缓冲区在各个协议层之间传递。
在一个新分组产生时,TCP层首先在用户空间中分配内存来容纳该分组数据(首部和净荷)。分配的空间大于数据实际需要的长度,因此较低的协议层可以进一步增加首部。分配一个套接字缓冲区,使得head 和end 分别指向上述内存区的起始和结束地址,而TCP数据位于data 和tail 之间。
在套接字缓冲区传递到互联网络层时,必须增加一个新层。只需要向已经分配但尚未占用的那部分内存空间写入数据即可,除了data 之外所有的指针都不变,data 现在指向IP首部的起始处。下面的各层会重复同样的操作,直至分组完成,即将通过网络发送。
5.2 管理套接字缓冲区数据
套接字缓冲区结构不仅包含上述指针,还包括用于处理相关的数据和管理套接字缓冲区自身的其他成员。
使用了一个表头来实现套接字缓冲区的等待队列。其结构定义如下:
//<skbuff.h>
struct sk_buff_head {
/* 这两个成员必须在最前面*/
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen;
spinlock_t lock;
};len 指定了等待队列的长度,即队列中成员的数目。sk_buff_head 和sk_buff 的next 和prev 用于创建一个循环双链表,套接字缓冲区的list 成员指回到表头,如下图所示。
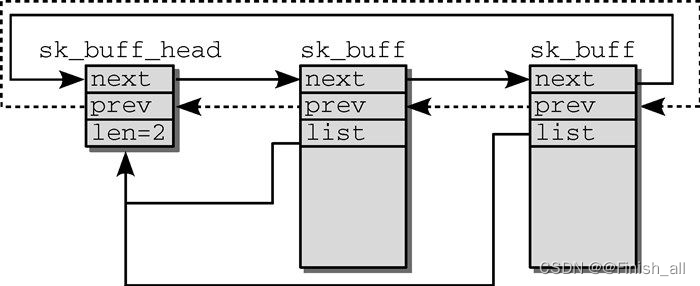
通过双链表管理套接字缓冲区,分组通常放置在等待队列中,例如分组等待处理时,或需要重新组合已经分析过的分组时。
6 网络访问层
网络实现的第一层,即网络访问层。该层主要负责在计算机之间传输信息,与网卡的设备驱动程序直接协作。
6.1 网络设备的表示
在内核中,每个网络设备都表示为net_device 结构的一个实例。在分配并填充该结构的一个实例之后,必须用net/core/dev.c 中的register_netdev 函数将其注册到内核。该函数完成一些初始化任务,并将该设备注册到通用设备机制内。
在详细讨论struct net_device 的内容之前,先阐述一下内核如何跟踪可用的网络设备,以及如何查找特定的网络设备。照例,这些设备不是全局的,而是按命名空间进行管理的。回想一下,每个命名空间(net 实例)中有如下3个机制可用。
- 所有的网络设备都保存在一个单链表中,表头为dev_base 。
- 按设备名散列。辅助函数dev_get_by_name(struct net * net, const char * name) 根据设备名在该散列表上查找网络设备。
- 按接口索引散列。辅助函数dev_get_by_index(struct net * net, int ifindex) 根据给定的接口索引查找net_device 实例。
在内核中,每个网卡都有唯一索引号,在注册时动态分配保存在ifindex 成员中。我们知道内核提供了dev_get_by_name 和dev_get_by_index 函数,用于根据网卡的名称或索引号来查找其net_device 实例。
net_device结构我就不展示出来了,一些结构成员定义了与网络层和网络访问层相关的设备属性
。
- mtu (maximum transfer unit,最大传输单位 )指定一个传输帧的最大长度。网络层的协议必须遵守该值的限制,可能需要将分组拆分为更小的单位。
- type 保存设备的硬件类型,它使用的是<if_arp.h> 中定义的常数。例如,ARPHRD_ETHER 和ARPHDR_IEEE802 分别表示10兆以太网和802.2以太网,ARPHRD_APPLETLK 表示AppleTalk,而ARPHRD_LOOPBACK 表示环回设备。
- dev_addr 存储设备的硬件地址(如以太网卡的MAC地址),而addr_len 指定该地址的长度。broadcast 是用于向附接的所有站点发送消息的广播地址。
- ip_ptr 、ip6_ptr 、atalk_ptr 等指针指向特定于协议的数据,通用代码不会操作这些数据。
net_device 结构的大多数成员都是函数指针,执行与网卡相关的典型任务。尽管不同适配器的实现各有不同,但调用的语法(和执行的任务)总是相同的。因而这些成员表示了与下一个协议层次的抽象接口。这些接口使得内核能够用同一组接口函数来访问所有的网卡,而网卡的驱动程序负责实现细节。
6.2 注册网络设备
每个网络设备都按照如下过程注册。
- alloc_netdev 分配一个新的struct net_device 实例,一个特定于协议的函数用典型值填充该结构。对于以太网设备,该函数是ether_setup 。其他的协议(这里不详细介绍)会使用形如XXX_setup 的函数,其中XXX 可以是fddi (fiber distributed data interface,光纤分布式数据接口)、tr (token ring,令牌环网)、ltalk (指Apple LocalTalk)、hippi (high-performance parallel interface,高性能并行接口)或fc (fiber channel,光纤通道)。
- 在struct net_device 填充完毕后,需要用register_netdev 或register_netdevice 注册。这两个函数的区别在于,register_netdev 可处理用作接口名称的格式串(有限)。在net_device->dev 中给出的名称可以包含格式说明符%d 。在设备注册时,内核会选择一个唯一的数字来代替%d 。例如,以太网设备可以指定eth%d ,而内核随后会创建设备eth0 、eth1 ……
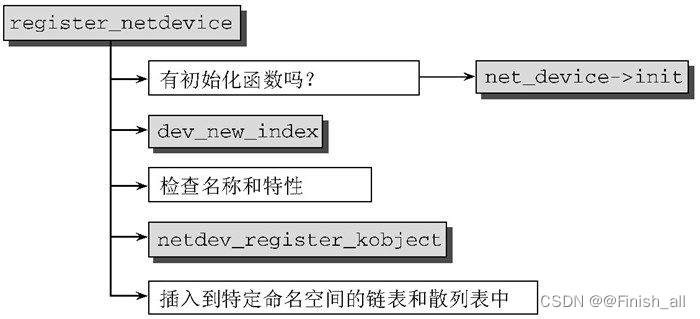
上图为register_netdevice 的代码流程图
6.3 接收分组
所有现代的设备驱动程序都使用中断来通知内核(或系统)有分组到达。网络驱动程序对特定于设备的中断设置了一个处理例程,因此每当该中断被引发时(即分组到达),内核都调用该处理程序,将数据从网卡传输到物理内存,或通知内核在一定时间后进行处理。
几乎所有的网卡都支持DMA模式,能够自行将数据传输到物理内存。而不需经过操作系统,不需要中断。
传统方法:
下图给出了在一个分组到达网络适配器之后,该分组穿过内核到达网络层函数的路径。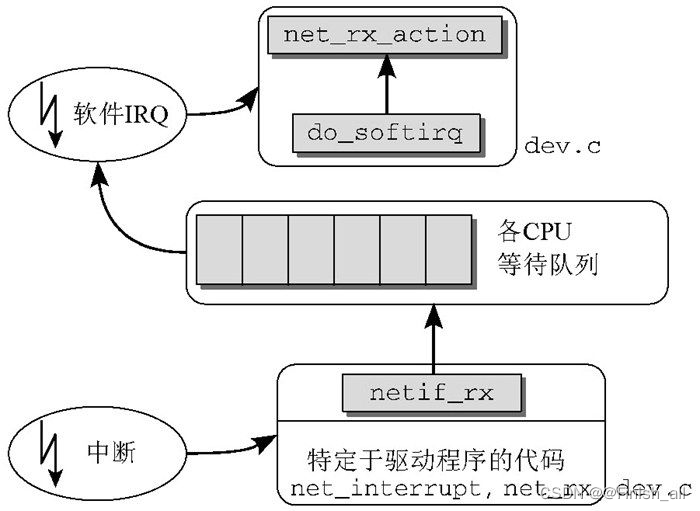
- net_interrupt 是由设备驱动程序设置的中断处理程序。它将确定该中断是否真的是由接收到的分组引发的(也存在其他的可能性,例如,报告错误或确认某些适配器执行的传输任务)。如果确实如此,则控制将转移到net_rx 。
- net_rx 函数也是特定于网卡的,首先创建一个新的套接字缓冲区。分组的内容接下来从网卡传输到缓冲区(也就是进入了物理内存),然后使用内核源代码中针对各种传输类型的库函数来分析首部数据。这项分析将确定分组数据所使用的网络层协议,例如IP协议。
- 与上述两个方法不同,netif_rx 函数不是特定于网络驱动程序的,该函数位于net/core/dev.c 。调用该函数,标志着控制由特定于网卡的代码转移到了网络层的通用接口部分。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











